Having the right dictionary is at the heart of any text mining analysis.
Dictionary for text mining can be compared to maps while travelling in a new city. The more precise and accurate maps you use, the faster you reach to the destination. On the other hand, a wrong or incomplete map can end up confusing the traveler.
Use of dictionary helps us convert unstructured text into structured data. The more precise dictionary you have for the analysis, the more accurate will be the analysis or prediction. Imagine, you are doing a sentiment analysis on twitter and you wish to find how positive or negative are the tweets for a subject. Many tweets contain the word “awsum” and few of the tweets contain the word “awful”. Hence, in totality, the sentiment is positive about the subject. But, if our dictionary does not contain the word “awsum”, the sentences with the word “awsum” will not be tagged. Hence, our sentiment analysis will tell that the sentiment is negative instead of positive. The inaccuracy in results is caused due to incomplete dictionary.

Source: Stoogles.com
Many times dictionary for the analysis are available on the web world. For instance, many dictionaries are available for sentiment analysis. But for niche analysis, we need to build a dictionary. One alternate to build a dictionary is to go through each of the millions of transactions. However, we are smart enough to structure this exercise and save most of the labor. This article will be focused to build such dictionaries. We will assume that you have read the articles to understand the framework of the text mining analysis and how to clean text data. We will start with the frequency word table, which you get after doing basic cleaning on the text. I will continue with the case study we discussed before.
Business Problem
You are the owner of Metrro cash n carry. Metrro has a tie up with Barcllays bank to launch co-branded cards. Metrro and Barcllay have recently entered into an agreement to share transaction data. Barcllays will share all transaction data done with their credit card at any retail store. Metrro will share all transaction made by any credit card on their stores. You wish to use this data to track where are your high value customers shopping other than Metrro.
To do this you need to fetch out information from the free transactions text available on Barcllays transaction data. For instance, a transaction with free text “Payment made to Messy” should be tagged as transaction made to the retail store “Messy”. Once we have the tags of retail store and the frequency of transactions at these stores for Metrro high value customers, you can analyze the reason of this customer outflow by comparing services between Metrro and the other retail store.
Quick Note
More time spent on perfecting the dictionary typically leads to higher accuracy in text mining. Text mining is typically done in two frameworks. Either we extract words or we extract complete sentences. Word based dictionaries are generally a quicker hit. For instance we have multiple transaction with the word “Macy’s”. For word mining we need to tag only one word but for sentence mining we need to tag all the sentences containing the word Macy’s. But in general, word mining has a prerequisite of deep business understanding. Following is a representation of the typical time-accuracy trade off in text mining :
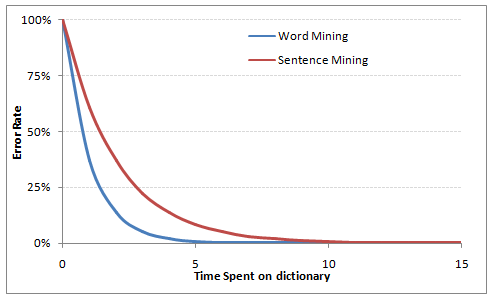 It is literally not possible to read each and every word occurring in billions of transactions. Hence we need to fix a cut off on the accuracy to restrict the time required to complete the analysis.
It is literally not possible to read each and every word occurring in billions of transactions. Hence we need to fix a cut off on the accuracy to restrict the time required to complete the analysis.
Starting Point
The initial steps of any text mining problem is always the same : Understand the data and Clean the data. After cleansing the data, we can find out which are the words which occur more frequent words. For this article we will start with a list of frequently occurring words which have come up after doing all the basic steps of text mining.
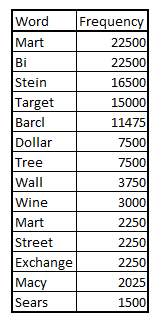
The figure above is a sample of the word list. We will refer to this list for making a framework to build a dictionary. The reason we sort these words by frequency is to find the most important characteristic words. Imagine a situation where you missed the word “Macy” which has occurred 100k times and a word “Getz’s” which occurs only 5 times. Obviously, you will not want the former to happen. However, loosing 5 transactions out of say a million transaction cannot change our results.
Framework
Once you have the list of words sorted by frequency, you need to follow the framework below to build a dictionary :
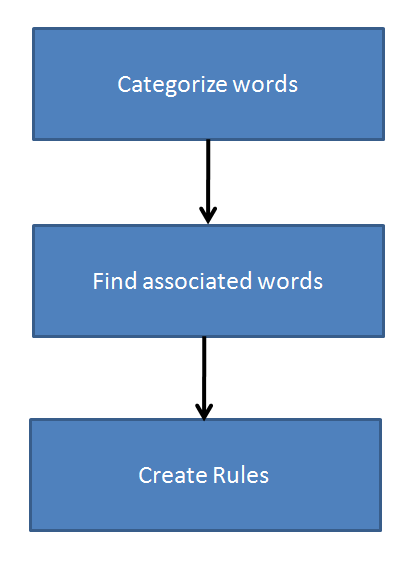
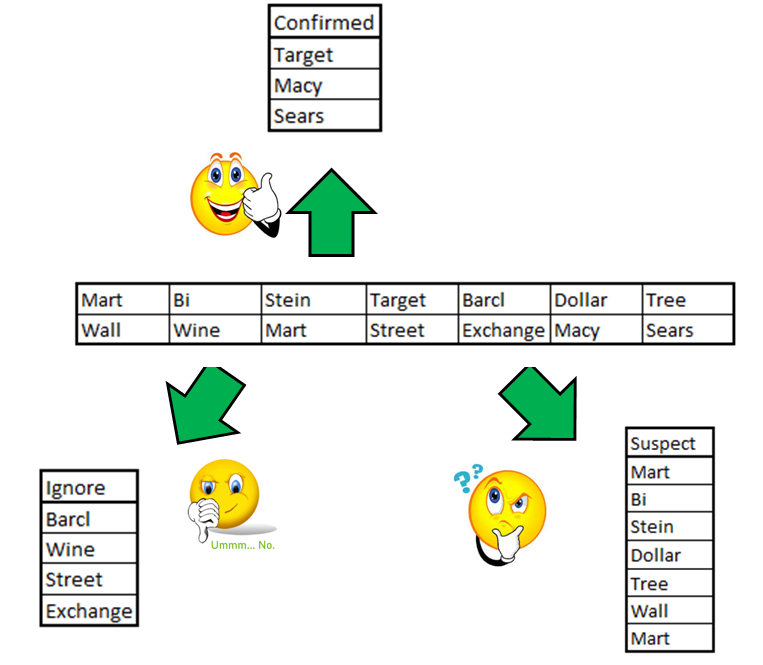
Step 1 : Categorize words
You need to put each frequently occurring word into one of the following three categories :
1. Confirm List : These words are the gold mines. For example, if a transaction detail has the word Macy, I already know that this transaction was done Macy’s. Such word reduce our labor as no more proof is required to categorize such transactions.
2. Suspect List : These words definitely raise eyebrows but do not give enough proof. For instance, the word “Wall”. Wall can mean “Wall Mart” or it can mean “Shop at Wall Street”. Such words need to be investigated further.
3. Ignore List : Such words can be conveniently ignored. You need be very careful before ignoring words as they might contain some hidden information. Hence, for high frequency words we will avoid putting a flag of ignore.
 Let’s divide our sample into these three categories with the rules mentioned above :
Let’s divide our sample into these three categories with the rules mentioned above :
 Why did we categorize the words into these categories?
Why did we categorize the words into these categories?
Initially we were dealing with huge number of frequently occurring words (in this case 13). To create a dictionary, we will need to investigate each of these words. But by classifying them into these three broad categories, we now simply need to investigate the suspect category (in this case 6 words). Hence, we have reduced our labor significantly (in this case by > 50%).
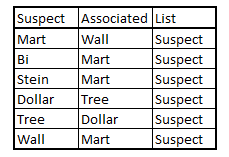
Step 2 : Find Associated words
For each of the suspect words you need to find the most associated word in the entire text. This will tell us which words come along with this suspect word and hence bring more confidence to the table to build rules from suspect words. There are three possibilities after you find the most associated word. The associated word can come from confirm list, suspect list or ignore list. For each of the types following is the action plan :
1. Confirm List : You can conveniently ignore such a suspect word because the transaction will anyway be tagged using the confirmed word. For instance, words – “Barneys” , “new” , “york” can be highly associated, but only “barney” can tell us the name of the store i.e. “Barneys New York” whereas finding only the word “new” or “york” can lead to error. Hence, we ignore all suspect words associated with a confirmed list word.
2. Suspect List : In such cases you need to build rules using both the words to get a confirmed phrase. For example, the word “Wall” and “Mart” individually can lead to errors because of the names “Wall Street” and “Bi Mart”, but found together probably means “Wall Mart”.
3. Ignore List : in such cases try finding the next best associated Suspect or Confirmed word. In case there are no such words associated, ignore this word as well.
Let us try finding out the associated words for our sample :
 Step 3 : Create rules
Step 3 : Create rules
After finding out the lists and associated words, we now create single or combination rules. For all the confirmed words, we have single rule. For instance, in our case we have three such rules,
[stextbox id=”grey”]
if description contains “sears” the store = “Sears”
if description contains “macy” the store = “Macy’s”
if description contains “target” the store = “Target”
[/stextbox]
The next set of rules come from suspect list. Such rules are combination rules. in our case we get 4 such rules,
[stextbox id=”grey”]
if description contains “Mart” and “Wall” the store = “Wall Mart”
if description contains “Dollar” and “Tree” the store = “Dollar Tree”
if description contains “Mart” and “Stein” the store = “Stein-Mart”
if description contains “Mart” and “Bi” the store = “Bi-Mart”
[/stextbox]
End Notes
After creating such rules, we implement the code on the entire transactions table.Such dictionary creation not only are more accurate, they are much faster than manual process. Imagine a scenario that Wall Mart is written in the transactions as Wall Mt. Now, if we are trying to search “Wall mart” we will get no matches. But in our framework, we will catch this fact in the association step. Creating dictionary is more of an art than science. The more efforts you put while creating the dictionary, better will be accuracy while scoring.
Have you made any dictionary before? Did you use any other approach or framework? Did you find the article useful? Did this article solve any of your existing dilemma?
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.







I am working on a similar type of work, i would like to know how do you identify the confirm,suspect and ignore list using R? or which method is ideal?
Hi Tavish, It would be of great help if you can put R code for above process. Thanks!
Can you please tell me the code for the above process in R .Thanks