This article was published as a part of the Data Science Blogathon.
Introduction
Generative adversarial networks (GANs) are an innovative class of deep generative models that have been developed continuously over the past several years. It was first proposed in 2014 by Goodfellow as an alternative training methodology to the generative model [1]. Since their birth, GANs have been used in a broad range of applications for their great performance in dealing with complex and high-dimensional data, for instance, computer vision, natural language, or other academic domains such as music generation or security.
Generative Adversarial Networks (GANs) are a class of deep learning models that have the ability to generate new, previously unseen data. They have been used to generate realistic images, videos, and even audio and have the potential to revolutionize a wide range of applications, including computer graphics, video game design, medical imaging, and more. Despite their power, GANs can be difficult to train and stabilize, and much research is still being done to understand and improve their behavior.
In this blog post, we will explore the inner workings of GANs, the challenges of training them, and the most recent developments and breakthroughs in the field. Whether you’re a researcher, a developer, or just curious about GANs, this post will provide a comprehensive introduction to this exciting and rapidly evolving field of deep learning
Q1. Explain the GAN Architecture’s Operation & Its Difference From Other Models.
Generative Adversarial Networks (GANs) are a type of neural network designed to generate new, previously unseen data similar to some training data. They are made up of two parts: a generator network and a discriminator network.
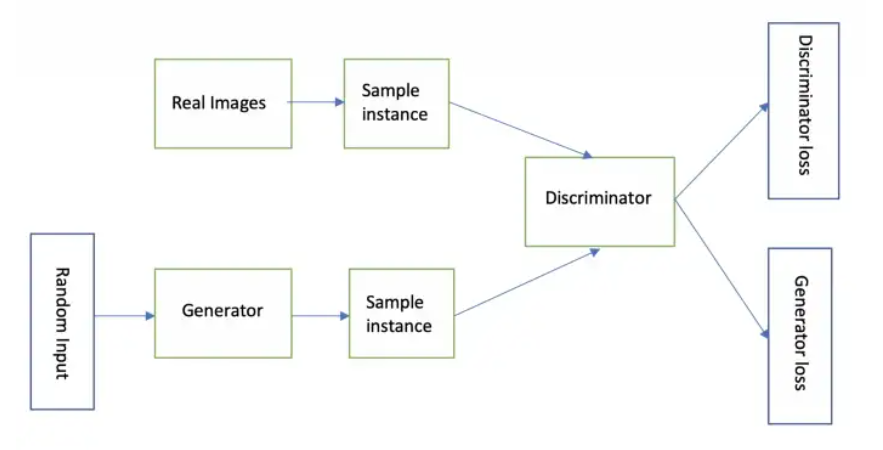
The generator network is trained to generate new data samples similar to the training data. It does this by taking in a random noise signal as input and transforming it through a series of mathematical operations implemented using neural networks into an output data sample.
The discriminator network is trained to take in data samples and predict whether each sample is a “real” sample from the training data or a “fake” sample generated by the generator network.
During training, the generator and discriminator networks are trained separately and alternately. The generator is trained to try to generate samples that the discriminator will classify as real. In contrast, the discriminator is trained to try to correctly classify the samples as either real or fake. This process is repeated many times, and through this adversarial process, the generator learns to generate data samples that are increasingly similar to the training data.
GANs are different from traditional machine learning models in that they are designed to generate new data rather than classify or predict values for a given input. They are also different in that they are trained using an adversarial process, with the generator and discriminator networks competing with each other to improve their performance.
Q2. Provide an Example of a Real-world Issue that GAN Was Used to Resolve.
There are many potential applications for GANs, including:
- Generating synthetic images (e.g., photographs of people, objects, landscapes, etc.) that are indistinguishable from real images
- Generating synthetic audio (e.g., speech, music, etc.) that is realistic and sounds like it was produced by a human or a musical instrument
- Generating synthetic text (e.g., news articles, social media posts, etc.) that is coherent and resembles human-written text
- Up-sampling low-resolution images or video to higher resolutions
- Translating images from one domain to another (e.g., converting a day-time image to a night-time image)
One example of a real-world problem that has been solved using GANs is the generation of synthetic training data for machine learning models. In some cases, it can be difficult or expensive to obtain large amounts of high-quality training data for a machine learning task. GANs can be used to generate synthetic data similar to real data, which can be used to train machine learning models. For example, GANs have been used to generate synthetic medical images that can be used to train machine-learning models to detect diseases or abnormalities in medical images.
Q3. List Some Difficulties in Training GAN and How to Get Around Them.
Several challenges can arise when training GANs:
Mode collapse: This occurs when the generator network becomes too good at generating fake samples, and the discriminator network cannot distinguish between real and fake samples. As a result, the generator ends up generating the same or similar samples repeatedly rather than generating a diverse range of samples. Mode collapse can be prevented by carefully designing the architecture of the generator and discriminator networks and by using techniques such as minibatch discrimination to encourage the generator to generate a diverse range of samples.Training instability: GANs can be difficult to train because the generator and discriminator networks are constantly adversarial, and small changes in one network can cause large changes in the other. This can make training unstable and lead to poor performance. To overcome this, it is important to carefully choose the learning rates and optimizers for the generator and discriminator networks and to monitor the training process to ensure that it is stable.
Lack of diversity in generated samples: In some cases, the generator network may not be able to generate a diverse range of samples and may only produce a limited range of similar samples. This can be caused by a lack of capacity in the generator network or by the generator network being too strongly influenced by the discriminator network. To overcome this, it may be necessary to increase the capacity of the generator network or to use techniques such as adding noise to the input of the generator network to encourage it to generate a more diverse range of samples.
Difficulty in evaluating the quality of generated samples: It can be difficult to evaluate the quality of generated samples, especially when the samples are highly realistic and it is difficult to distinguish them from real samples. One way to evaluate the quality of generated samples is to use a “human evaluation” approach, where real humans are shown samples and asked to classify them as real or fake. Another approach is to use an “automatic evaluation” method, where the samples are compared to real samples using some metric (e.g., mean squared error) to measure the similarity between the samples.
Q4. How Does GAN Handle Complex, Multi-modal Distribution?
GANs are capable of handling complex, multi-modal distributions, which are datasets that have multiple “modes” (i.e., multiple clusters or groups of data points) that are not well-separated. This is because GANs are designed to learn the statistical properties of a dataset rather than trying to fit the data to a pre-defined model or assumption.One example of a dataset where GANs have performed exceptionally well is the CelebA dataset, which consists of over 200,000 images of celebrities. This dataset is multi-modal because it contains images of a large number of different celebrities, each with their own unique appearance. GANs have been used to generate synthetic images of celebrities that are highly realistic and indistinguishable from real images.
In general, GANs tend to perform well on datasets that have a large amount of variability and complexity, such as image datasets or audio datasets. They are able to learn the statistical properties of the data and generate samples that capture the diversity and complexity of the dataset.
Q5. In your Experience, What Are Some of the Most Promising Areas of Research Related to GAN?
There are many promising areas of research related to GANs, including:
Improving the stability and reliability of GAN training: There is ongoing research on developing new training algorithms and techniques that can improve the stability and reliability of GAN training. This includes methods for avoiding mode collapse, balancing the training of the generator and discriminator networks, and adapting GANs to new tasks or datasets.Developing new GAN architectures and design patterns: There is a lot of interest in developing new GAN architectures that are more efficient, flexible, and powerful. This includes research on designing GANs for specific tasks (e.g., image generation, audio generation, etc.), designing GANs that can handle complex data distributions, and designing GANs that can learn from small amounts of data.
Applying GANs to new domains and tasks: GANs have already been applied to a wide range of domains and tasks, but there is still a lot of potential for using GANs in new areas. This includes using GANs for tasks such as natural language processing, data augmentation, and generating 3D models or scenes.
Exploring the ethical and societal implications of GANs: As GANs become more powerful and prevalent, there is a growing need to consider these models’ ethical and societal implications. This includes research on topics such as the potential for GANs to be used for nefarious purposes (e.g., generating fake news or propaganda), the impact of GANs on jobs and industries, and the role of GANs in shaping public perception and decision-making.
Q6. Compared to Other Generative Models like Variational Autoencoders (VAE), How do GAN Architectures Fare?
GANs and Variational Autoencoders (VAEs) are both generative models that can be used to generate new, previously unseen data samples. However, they work in somewhat different ways and have different strengths and weaknesses.One key difference between GANs and VAEs is the way they are trained. GANs are trained using an adversarial process, where a generator network competes with a discriminator network to generate realistic samples. VAEs, on the other hand, are trained using an optimization process, where the goal is to maximize the likelihood of the training data under the model.
Another difference is that GANs are generally more flexible and can generate samples from a wider range of distributions, while VAEs are more limited in the types of distributions they can model. GANs can generate highly realistic samples, but they can be difficult to train and may suffer from issues such as mode collapse. VAEs are generally easier to train and can generate more diverse samples, but the samples may not be as realistic as those generated by GANs.
In terms of when to choose one over the other, it really depends on the specific task and the requirements of the application. GANs may be a good choice when the goal is to generate highly realistic samples and when there is a large amount of training data available. VAEs may be a good choice when the goal is to generate a diverse range of samples or when there is limited training data available.
Q7. Can you Discuss Any Recent Developments or Breakthroughs in GANs?
There have been many recent developments and breakthroughs in the field of GANs. Some of the most significant developments include:Improved training algorithms and techniques: There have been a number of recent advances in training algorithms and techniques for GANs, including methods for improving the stability and reliability of training, balancing the training of the generator and discriminator networks, and adapting GANs to new tasks or datasets.
New GAN architectures and design patterns: Researchers have developed a wide range of new GAN architectures and design patterns that are more efficient, flexible, and powerful. These include architectures for specific tasks (e.g., image generation, audio generation, etc.), architectures for handling complex data distributions, and architectures that can learn from small amounts of data.
Applying GANs to new domains and tasks: GANs have been applied to a wide range of new domains and tasks, including natural language processing, data augmentation, and generating 3D models or scenes.
Exploration of the ethical and societal implications of GANs: There has been increasing attention on the ethical and societal implications of GANs, including the potential for GANs to be used for nefarious purposes, the impact of GANs on jobs and industries, and the role of GANs in shaping public perception and decision-making.
Q8. Can you Describe How a GAN’s Generator and Discriminator Cooperate to Enhance the Model’s Performance?
In a GAN, the generator and discriminator networks work together to improve the model’s performance by competing with each other in an adversarial process. The generator network is trained to generate new, synthetic data samples that are similar to the training data, while the discriminator network is trained to classify each sample as either real (from the training data) or fake (generated by the generator).During training, the generator and discriminator networks are trained alternately. First, the generator network is trained to generate a batch of samples, and these samples are passed to the discriminator network along with a batch of real samples from the training data. The discriminator network then tries to classify each sample as either real or fake. The generator network is updated based on how well it was able to fool the discriminator.
Next, the discriminator network is trained on a new batch of samples, and the generator network is updated based on the discriminator’s performance. This process is repeated many times, and through this adversarial process, the generator network learns to generate samples that are increasingly similar to the training data. In contrast, the discriminator network learns to classify the samples as either real or fake more accurately.
Overall, the generator and discriminator networks work together to improve the model’s performance by pushing each other to become more accurate and effective. The generator tries to generate indistinguishable samples from real samples, while the discriminator tries to identify which samples are real and which are fake correctly. Through this process, the GAN learns the statistical properties of the training data and is able to generate new, synthetic samples that are similar to the training data.
Q9. How Can GAN Architecture be Used for Unsupervised Learning?
GANs can be used for unsupervised learning, meaning they can learn to generate new data samples without needing labeled training examples. In a GAN, the generator network is trained to generate samples similar to the training data, while the discriminator network is trained to classify each sample as either real (from the training data) or fake (generated by the generator).During training, the generator network is provided with a random noise signal as input, generating a synthetic sample based on this input. The discriminator network then takes in this synthetic sample and real samples from the training data and tries to classify each sample as either real or fake. The generator network is updated based on how well it could fool the discriminator, and the process is repeated many times.
Through this adversarial process, the generator network learns to generate samples that are similar to the training data without the need for explicit labels or supervision. The generator is able to learn the statistical properties of the training data and generate new samples that are consistent with these properties.
For example, GANs have been used to generate synthetic images of celebrities that are highly realistic and indistinguishable from real images. In this case, the GAN was trained on a dataset of celebrity images and learned to generate new, synthetic images of celebrities without the need for explicit labels or supervision. The GAN was able to learn the statistical properties of the training data and generate new samples that captured the diversity and complexity of the dataset.
Q10. How Does GAN Architecture Handle High-dimensional Data?
GANs are capable of handling high-dimensional data, such as images or audio, by learning the statistical properties of the data and generating samples that are consistent with these properties. However, it can be more challenging to train GANs on high-dimensional data due to the complexity of the data and the larger number of parameters that need to be learned.One way to handle high-dimensional data in the context of GANs is to use techniques to reduce the dimensionality of the data. Several methods can be used for dimensionality reduction, including:
Principal Component Analysis (PCA): This linear dimensionality reduction technique projects the data onto a lower-dimensional space by finding the directions of maximum variance in the data.
t-SNE (t-Distributed Stochastic Neighbor Embedding): This is a non-linear dimensionality reduction technique that maps the data to a lower-dimensional space in a way that preserves the local structure of the data.
Autoencoders are neural networks trained to compress the data into a lower-dimensional representation and then reconstruct the original data from this representation. Autoencoders can be used as a preprocessing step to reduce the dimensionality of the data before training a GAN.
Using these or other dimensionality reduction techniques can help reduce the data’s complexity and make it easier to train a GAN on high-dimensional data. However, it is essential to be careful when using dimensionality reduction, as it can also introduce information loss and degrade the quality of the generated samples.
Q11. Can you Talk About Ethical Issues When Using GANs, Particularly When Creating Realistic Synthetic Data?
There are several ethical concerns surrounding using GANs, particularly in generating realistic synthetic data. Some of the main concerns include the following:Misuse of synthetic data: GANs can generate highly realistic synthetic data, such as images or audio, that are indistinguishable from real data. This raises concerns about the potential for synthetic data to be used for nefarious purposes, such as creating fake news or propaganda, impersonating individuals, or committing fraud.
Impact on jobs and industries: The use of GANs and other machine learning models to generate synthetic data can potentially disrupt industries that rely on the creation and distribution of real data, such as the media or entertainment industries. This could lead to job losses and other negative economic impacts.
Shaping public perception and decision-making: GANs and other machine learning models can be used to generate synthetic data that is highly realistic and influential, such as videos of politicians or celebrities saying or doing things that never actually happened. This can shape public perception and decision-making in unintended or harmful ways.
These concerns are similar to those of other machine learning models. Still, they may be more pronounced in the case of GANs due to their ability to generate highly realistic synthetic data. It is important for researchers, developers, and users of GANs to consider these ethical issues and take steps to mitigate any potential negative impacts. This may include developing guidelines or regulations for using GANs or engaging in dialogue with stakeholders to address concerns and find solutions.
Conclusion
GANs are a powerful class of deep learning models that have the ability to generate new, previously unseen data. They have been used in a wide range of applications and have the potential to revolutionize fields such as computer graphics, video game design, medical imaging, and more. However, GANs can be difficult to train and stabilize, and much research is still being done to understand and improve their behavior. This blog post has discussed the inner workings of GANs, the challenges of training them, and the most recent developments and breakthroughs in the field. GANs are a rapidly evolving field, and with new techniques and architectures being proposed, it holds a lot of promise in many different fields. Following are some salient takeaway points from our discussion of GANs:
- GANs are a generative model that can learn to generate new, synthetic data samples similar to a training dataset.
- GANs are trained using an adversarial process, where a generator network competes with a discriminator network to generate realistic samples.
- GANs have been applied to various tasks and domains, including image generation, audio generation, and natural language processing.
- GANs can be challenging to train due to issues such as mode collapse and training instability. There are a number of techniques that can be used to improve the stability and reliability of GAN training.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Premanand S is a dedicated academic with over a decade of research experience, specializing in Bio-signal Processing, Machine Learning, and Deep Learning. He completed his B.Tech in 2009 from Amrita Vishwa Vidyapeetham, Bangalore, and his M.E. in 2011 from Rajalakshmi Engineering College, Chennai, where his thesis focused on Deep Learning for ECG Signal Processing.
He is pursuing his Ph.D. at VIT-Chennai, with a tentative research title of "Deep Learning Approaches for Enhanced ECG Signal Processing and Arrhythmia Classification." His research aims to leverage cutting-edge deep learning techniques to improve the accuracy and efficiency of ECG signal analysis, contributing significantly to cardiac health monitoring.
A recipient of the prestigious TCS-RSP (Research Scholarship) in 2014, Cycle 9, Premanand has become a recognized figure in the academic community. He has delivered several invited talks on Data Science, Machine Learning, and Deep Learning at prominent institutions across India.
In his role as an Assistant Professor at VIT-Chennai, he continues to inspire the next generation of researchers while advancing the boundaries of knowledge in his field.








Very informative article. Thanks