Introduction
In today’s rapidly growing landscape, the sheer volume of data generated every second is staggering. Businesses seek efficient data storage solutions to manage this deluge effectively. Data storage is paramount, as data collection efforts would only be futile with a robust system. Data lake and data warehouse emerge as two prominent options for storing big data, but they are not interchangeable terms. While both serve the overarching purpose of data storage, they differ significantly in their approach. In this article, we delve into the distinctions between Data Lake vs Data Warehouse, enabling you to make an informed choice that aligns perfectly with your business needs.
Learning Objectives
- Understanding the difference between Data Lake and Data Warehouse
- Use cases of Data Lake and Data Warehouse
- Advantages and disadvantages of Data Lake and Data Warehouse
This article was published as a part of the Data Science Blogathon.
Table of contents
Data Lake vs Data Warehouse – Overview
Explore the overview of difference between data lake and data warehouse in the table below:
| Feature | Data Lake | Data Warehouse |
|---|---|---|
| Data Type | Stores raw, unstructured, semi-structured, and structured data. | Stores structured and pre-processed data. |
| Schema | Schema-on-read; flexible schema, no predefined structure. | Schema-on-write; rigid schema, predefined structure. |
| Data Volume | Scales horizontally to handle massive data volumes. | Scales vertically to accommodate structured data. |
| Data Processing | On-demand processing of data as and when needed. | Batch processing of structured data for insights. |
| Data Agility | Accommodates diverse data formats without prior transformation. | Requires data transformation before storage. |
| Data Insights | Enables discovering new insights from raw, unprocessed data. | Offers insights from processed, organized data. |
| Use Case | Ideal for exploratory analysis, big data, and real-time processing. | Suitable for business intelligence and reporting. |
| End-Users | Data scientists and analysts; supports flexible ad-hoc queries. | Business analysts and decision-makers; structured queries. |
| Storage Cost | Cost-effective due to no upfront structuring and compression. | Relatively higher storage costs for structured data. |
| Scalability | Horizontally scalable for distributed storage and processing. | Vertically scalable for increased processing power. |
| Data Governance | Requires robust governance to prevent data chaos and duplication. | Offers established governance for structured data. |
| Real-Time Processing | Supports real-time data streams for immediate analysis. | Limited real-time capabilities due to structured data. |
| Examples | Hadoop, Apache Spark; suited for big data scenarios. | Amazon Redshift, Google BigQuery; BI and analytics. |
What is Data Lake?
A data lake is a vast, highly scalable storage repository with raw, unstructured, semi-structured, and structured data in its native format. Unlike traditional data warehouses, data lakes have no fixed schema, allowing businesses to collect and store massive volumes of diverse data from various sources. This reservoir is a foundation for data-driven insights, enabling organizations to analyze and process the information on-demand, gaining valuable business insights and uncovering hidden patterns. With its flexibility, cost-effectiveness, and ability to accommodate real-time data streams, data lakes empower data scientists and analysts to extract meaningful knowledge, facilitating informed decision-making and fostering innovation in today’s data-centric world.

What is Data Warehouse?
Data Warehouse is a large repository of organizational data which collects and manages data from varied sources(operational and external data sources) to provide meaningful business insights.
We can understand it as a process of transforming raw data into information because data is first processed and then organized into sections.

Data in a warehouse is structured, filtered, already processed, and ready for use to support historical analysis and advanced querying.
They store information about products, orders, customers, employees, inventory, etc., and used by businesses to share data and content across department-specific databases. Entrepreneurs and Business users are the end-users of a data warehouse.
Data Lake vs Data Warehouse
Data Storage
Data lakes store raw, unprocessed data sourced from IoT devices, user data, real-time social media streams, and web application transactions.
Regardless of structure or source, all data finds a home in the data lake, necessitating substantial storage capacity. The versatility of raw data allows quick analysis for various purposes, making it ideal for machine learning. However, data lakes can become swamps without proper quality and governance measures.
Conversely, data warehouses exclusively store structured data extracted from value-based frameworks and subjected to prior processing and refinement. Past data undergoes cleaning to conform to relational schemas, making it suitable for strategic analysis based on predefined business requirements. Data warehouses prioritize efficient storage by excluding non-traditional data sources like web server logs, sensor data, social media activity, text, and images.
Users
Data lakes attract extensive usage from Data Scientists, Big Data Engineers, and Machine Learning Engineers, drawn to the repository’s raw and unstructured nature, facilitating in-depth analysis and unique business insights.
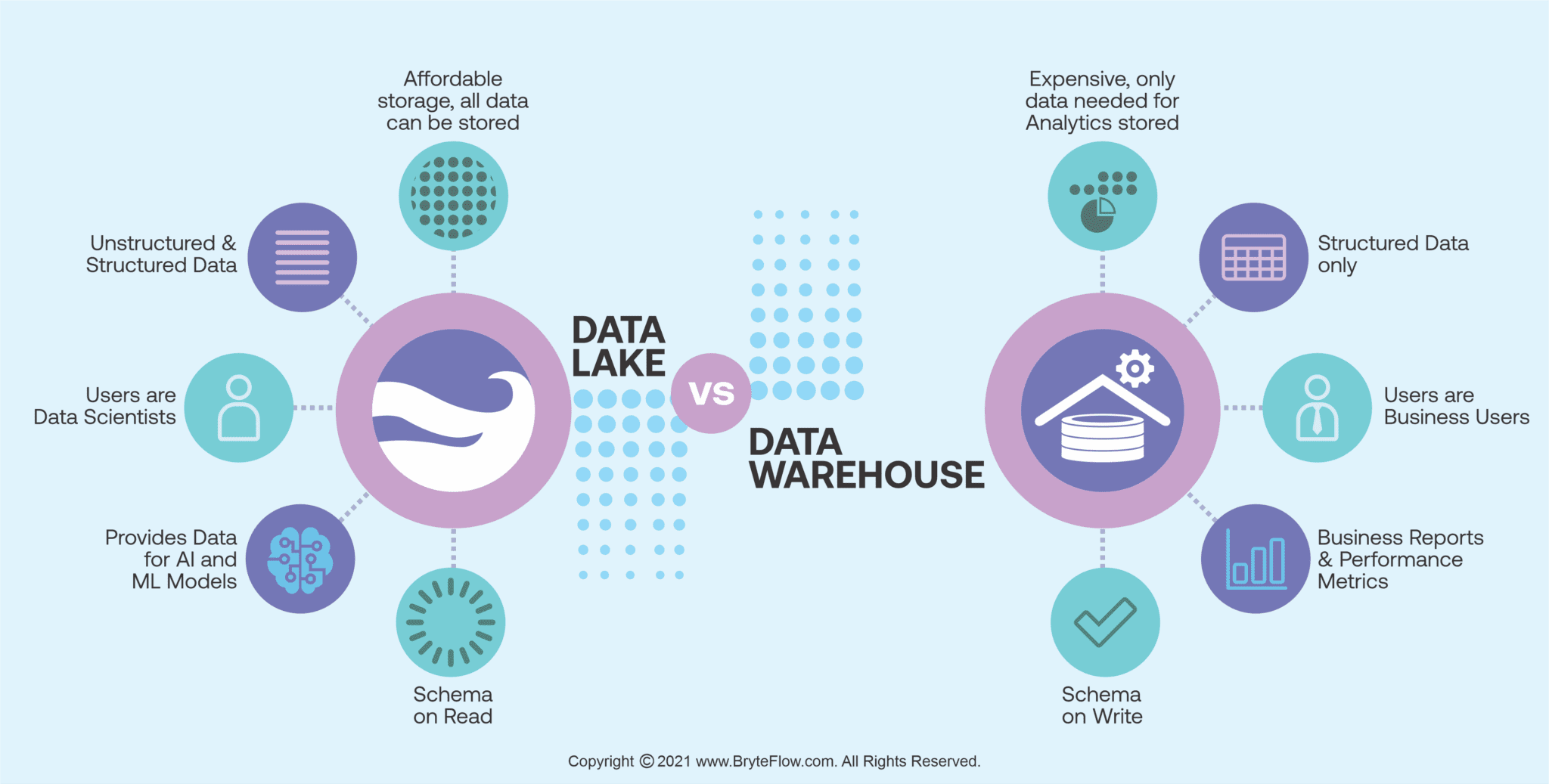
On the other hand, Data Warehouses cater to Business Analysts, Operational Clients, Managers, Business Professionals, and end-users familiar with processed data representations. These users derive insights from Business Key Performance Indicators (KPIs), benefiting from the data’s pre-processing, designed to address specific analysis questions.
Analysis
Data engineers often use the flexible and scalable unstructured data stored in data lakes for big data analytics. However, we can use services like Apache Spark and Hadoop to run Big data analytics on data lakes. It offers predictive analytics, data visualization, machine learning, BI, and Big data analytics.
The cleaned and archival data stored in data warehouses are typically set to read-only for analyst users. It usually offers data visualization, BI, and data analytics.
Schema
In a data lake, the schema is defined after the data is stored; this makes the process of capturing and storing the data faster. Also, a data lake uses the schema-on-read approach to process the data.
In a data warehouse, the schema is defined before the data is stored; this increases the time it takes to process the data.
But once the data is processed and stored in a warehouse, it is ready for consistent, confident use across the industry. Also, the data warehouse uses a schema-on-write approach to process the data and provide its shape and structure.
Processing
Data lake uses ELT (Extract Load Transform) process where the data is extracted from its source and directly loaded in the data lake without any transformation. The data will only be processed when required.
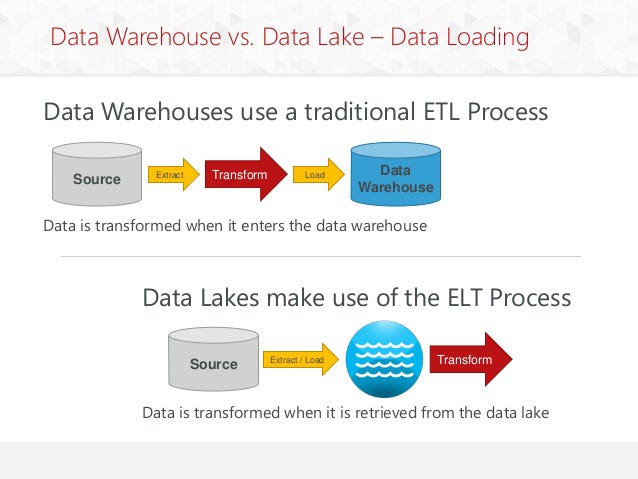
Data Warehouses use the ETL (Extract Transform Load) process, where the data is extracted from its source, cleaned or structured, and finally loaded into the warehouse.
Cost
Data lakes are low-cost data storage, as the data storage is unprocessed. Also, they consume much less time to manage data, reducing operational costs.
On the other hand, data warehouses cost more than data lakes as the data stored in a warehouse is cleaned and highly structured. Also, they need more time to manage data which increases operational costs.
Data Lake vs Data Warehouse: When to Use Which?
Both the data lake and data warehouse have their significance and purpose of use, but still, people get confused about which to use where. To understand this better, organizations must first understand their business model and its requirements. Suppose the organization’s goal is to understand its business patterns and analytics or to launch something new based on its previous customer insights. In that case, the warehouse can be the best choice.
On the other hand, if the requirement is to study a huge volume of raw, granular, structured, and unstructured data especially required for machine learning and deep learning data, then a data lake will be the best choice for storage.

Some points organizations can consider while choosing the right data storage are.
Data lakes can be the right choice when:
- You are unaware of the data types that must be stored in advance.
- The data is messy and difficult to fit into a tabular or relational model.
- Datasets are constantly increasing in volume, and storage cost is a concern.
- You are not aware of the relationships between data elements in advance
- The project demands a complete raw dataset, especially used for data exploration, predictive analytics, and machine learning projects
Data warehouse can be the right choice when:
- You know the data types that need to be stored in advance, and companies are uncomfortable with duplicate or additional data.
- Changes are very rare in data formats, and companies demand standard sets of reports for accurate results.
- The project demands highly structured datasets, especially those used for marketing, banking, and government-related projects.
Application of Data Lake vs Data Warehouse
In this section, we will be discussing the real word examples of data lake and data warehouse.
Use Cases for Data Lake
Cybersecurity
Nowadays, online scams are becoming a new trend; no matter how large or small a firm you’re running, the fear of cyber attacks with phishing emails, ransomware, viruses, or DDoS attacks is constant. You have to be proactive instead of reactive to minimize the effects of cyberattacks. You must collect a huge volume of information to detect hacking patterns and easily protect your firm from these hackers. Data Lake is the best pool to store this massive information and works as a safeguard even if you get hacked by storing your data safely.

Education
Like all other industries, Educational organizations are also competing to generate enormous amounts of data. Organizations are using the data lakes to store critical student data, including grades, attendance, etc., which help students get back on track but can also help predict potential issues before they occur in real-time. The flexibility of data lakes also helps educational organizations streamline billing, improve fundraising, etc.

Government
India is becoming a hub of governments, political parties, and non-profit organizations. All have one common motive of making our country smart, and even the smart city projects are already live in various states. We want to improve law enforcement practices, optimize waterways, enhance education systems, automate hospitals, and a lot more to make our country smart. Now, to implement these processes, all our government needs is unthinkable amounts of data from multiple sources like vehicles and citizens. The government uses data lakes to initiate the smart city project by dumping all the unexpected data into it.
Healthcare
For many years, we have been using data warehouses to store the critically large amount of data generated by the healthcare industries. But we lacked real-time insights from that because the highest part of data is unstructured data in the healthcare industry (i.e., physicians’ notes, clinical data, etc.). So, using data lakes capable of storing both structured and unstructured data tends to be a better fit for healthcare industries.

Transportation
The ability of data lakes to make predictions helps various industries by providing a great source of insights. In the transportation industry(especially in supply chain management), predictions can help companies reduce costs by examining data from forms within the transport pipeline and improving predictive maintenance.
Genetics
Genetics in itself is the branch of science that deals with the abundance of human body patterns, and it needs immense amounts of data to be taken to further steps. Every human body generates tons of information that can be used to identify correlations and discoveries. Data scientists use Data lakes to collect massive amounts of human data; they need to understand better the human genome, which in turn makes revolutionary improvements to our lives.
Use Cases for Data warehouse
Finance and Banking
A data warehouse is often the best storage model in the finance and banking industries, as it allows structured access by the entire organization rather than an individual data scientist. It plays a vital role in investment due to the significant amounts of money at stake. When it comes to money, a single point difference can result in devastating financial losses for millions of people. Data warehouses act as smart storage in such cases by storing only relevant data to make precise forecasts.

Hospitality Industry
In the hospitality industry, data warehouses play a major role in advertising and promotion campaigns targeting users based on their feedback and travel patterns. With the help of structured data stored in data warehouses, we can easily track the inventory, analyze promotions and pricing policies, and closely monitor the customer’s purchasing behavior. This information is very crucial and helps a lot when it comes to business intelligence systems and marketing strategies.
Public Sector
When it comes to the public sector, where reports play a major role, data warehouses help firms to analyze and maintain tax records, insurance policies, etc., building both personal profiles and group records.

Laboratory
When we talk about medical reports, a single mistake can lead to disastrous outcomes, which means a difference between life and death. Data warehouses store the medical reports carefully, which helps in making accurate predictions, creating treatment reports, exchanging data with insurance agencies, etc.
Conclusion
In today’s dynamic landscape, finding the right data storage solution is paramount for efficient project and business management. The differences outlined above serve as valuable guidance, enabling firms to make informed decisions tailored to their specific needs. Additionally, it’s important to note that a combination of both storage solutions, known as a data lakehouse, merges the flexibility of a data lake with the data management capabilities of a data warehouse, proving highly advantageous in building robust data pipelines.
Key Takeaways
- Data lakes excel in collecting large volumes of heterogeneous data for generating fresh data patterns and insights, primarily leveraged by data scientists.
- Data warehouses are preferred for analyzing structured data and understanding customer behavior, relying on previous data from the same firm.
- While data lakes and data warehouses are often considered similar due to their storage function, they significantly differ in user profiles, schema, processing approaches, and cost considerations.
By grasping these distinctions, organizations can strategically align their data storage approach to optimize efficiency, save time, and enhance cost-effectiveness, ensuring seamless data management and successful business outcomes.
Frequently Asked Questions
Q1. Is Azure a data lake or data warehouse?
A. Azure helps create both data lakes and data warehouses. It offers services like Azure Data Lake Storage for data lake capabilities and Azure Synapse Analytics for data warehousing.
Q2. What is the main difference between a data lake and a data warehouse Mcq?
A. The main difference between a data lake and a data warehouse lies in their approach to data storage. A data lake stores raw, unstructured data, while a data warehouse stores structured, processed data.
Q3. What is the difference between data lake and data warehouse and Delta Lake?
A. Data lake and data warehouse differ in handling data storage and processing. Data lake stores raw data, while data warehouse stores structured, processed data. Delta Lake is an extension of data lakes that adds transactional capabilities.
Q4. Is Snowflake a warehouse or lake?
A. Snowflake is a data warehouse providing cloud-based data storage and analytics capabilities. It offers a fully-managed platform for data warehousing, easily handling structured and semi-structured data.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a tech enthusiast, a student, and a learner. I am a critical reader and a lover of words who finds writing blogs interesting. I possess the capability to research and learn new technologies quickly.





