Introduction
A highly effective method in machine learning and natural language processing is topic modeling. A corpus of text is an example of a collection of documents. This technique involves finding abstract subjects that appear there. This method highlights the underlying structure of a body of text, bringing to light themes and patterns that might not be instantly visible.

To analyze the content of massive collections of documents, such as thousands of tweets, topic modeling algorithms rely on statistical techniques to find patterns in text. These algorithms classify papers into a select few subjects after examining the frequency and word co-occurrence in the documents. Consequently, the content seems more arranged and understandable, making it more straightforward to recognize the underlying themes and patterns in the data.
Latent Dirichlet allocation (LDA), latent semantic analysis, and non-negative matrix factorization are a few conventional techniques for topic modeling. However, this blog article uses BERT for subject modeling.
New Feature
Get Personalized Learning Path! Set your goal and timeline. Get a path—under 2 mins.
Learn More: Topic Modeling Using Latent Dirichlet Allocation (LDA)
Learning Objective
Here is a learning objective for a topic modeling workshop using BERT, given as bullet points:
- Know the basics of topic modeling and how it’s used in NLP.
- Understand the basics of BERT and how it creates document embeddings.
- To get text data ready for the BERT model, preprocess it.
- Utilize the [CLS] token to extract document embeddings from the output of BERT.
- To group related materials and find latent subjects, use clustering methods (like K-means).
- Utilize the right metrics to assess the generated topics’ quality.
With the help of this learning goal, participants will obtain practical experience using BERT for topic modeling. Using this knowledge, they will prepare themselves to analyze and extract hidden themes from sizable collections of text data.
This article was published as a part of the Data Science Blogathon.
Table of contents
Load Data
This is content from the Australian Broadcasting Corporation made accessible on Kaggle over eight years. It contains two significant columns: publish_date: the article’s publication date, in the yyyyMMdd format. English translation of the headline’s text is headline_text. This is the knowledge that the topic model will use.
import pandas as pd
# Read the dataset
data = pd.read_csv('../input/abc-news-sample/abcnews_sample.csv')
data.head()
# Create a new column containing the length each headline text
data["headline_text_len"] = data["headline_text"].apply(lambda x : len(x.split()))
print("The longest headline has: {} words".format(data.headline_text_len.max()))
# Visualize the length distribution
import seaborn as sns
import matplotlib.pyplot as plt
sns.displot(data.headline_text_len, kde=False)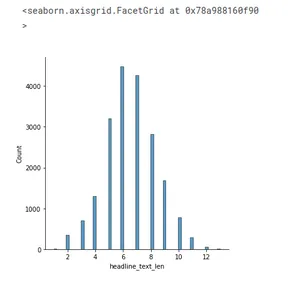
for idx in data.sample(3).index:
headline = data.iloc[idx]
print("Headline #{}:".format(idx))
print("Publication date: {}".format(headline.publish_date))
print("Text: {}\n".format(headline.headline_text))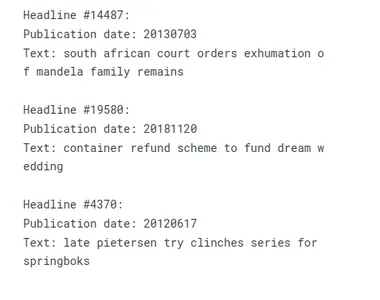
Topic Modeling
In this example, we’ll review BERT Topic’s key elements and the procedures needed to build a powerful topic model.
Learn More: Beginners Guide to Topic Modeling in Python
Training
Initiating BERT Topic comes first. Our documents are in English, so we have the language set to English. Use language=”multilingual” in place of “language” if you want to use a model that supports several languages.
The topic probabilities will be computed as well. However, this can drastically slow down the BERT topic when dealing with massive data sets (>100,000 documents). You can accelerate the model and also turn this off.
import warnings
warnings.filterwarnings("ignore")!pip install bertopic
%%time
from bertopic import BERTopic
model = BERTopic(verbose=True,embedding_model='paraphrase-MiniLM-L3-v2', min_topic_size= 7)
headline_topics, _ = model.fit_transform(data.headline_text)
To prevent messages from being displayed during model initialization, set Verbose to True. The sentence transformer model with the best speed and performance trade-off is paraphrase-MiniLM-L3-v2. We have set Min_topic_size to 7, though the default number is 10. The number of clusters or themes decreases as the value rises.
Topic Extraction and Representation
freq = model.get_topic_info()
print("Number of topics: {}".format( len(freq)))
freq.head()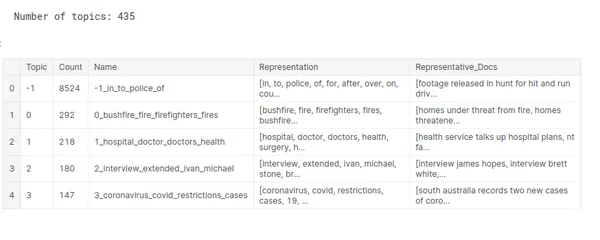
In the three primary columns of the table above, all 54 subjects are listed in decreasing order of size/count.
- The outliers are designated as -1 and identified by the subject number, which serves as an identifier. Because they contribute no value, those issues ought to be avoided.
- The term “count” refers to the topic’s word count.
- The topic is known by its given name, name.
We can get each topic’s top terms and their accompanying c-TF-IDF scores. The more significant the score, the more relevant the time is to the case.
a_topic = freq.iloc[1]["Topic"] # Select the 1st topic
model.get_topic(a_topic) # Show the words and their c-TF-IDF scores

We can see from this topic that all the terms make sense about the underlying subject, which appears to be firefighters.
Topics Visualization
Using the topic visualization, you may learn more about each topic. We will concentrate on the visualization options referenced from BERTopic, which include terms visualization, an intertropical distance map, and topic hierarchy clustering, to name just a few.
1. Topic Terms
You can use the c-TF-IDF score to create a bar chart of the essential terms for each topic, which provides an exciting way to compare issues graphically. Below is the related visualization for topic six.
model.visualize_barchart(top_n_topics=6)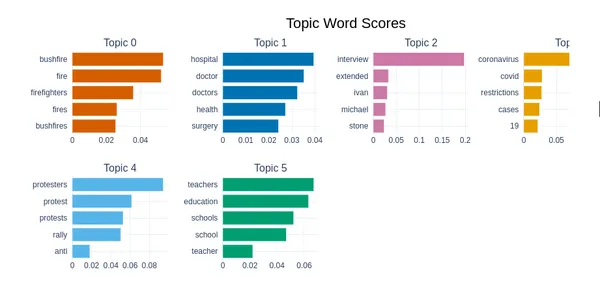
issue 1 is crime-related because the top phrases are “man, charged murder jail over.” Each of the subsequent subjects can easily lead to the same analysis. The horizontal bar is more pertinent to the subject the longer it is.
2. Intertopic Distance Map
For people who are familiar with the LDAvis library for Latent Dirichlet Allocation. The user of this library receives access to an interactive dashboard that displays the words and scores related to each topic. With its visualize_topics() method, BERTopic accomplishes the same thing and even goes further by providing the distance between cases (the shorter the length, the more related the topics are).
model.visualize_topics()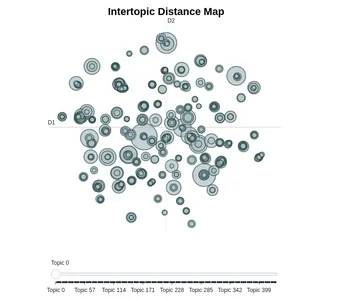
3. Visualize Topic Hierarchy
Some topics are near, as seen in the Interdistance topic dashboard. One thing that can cross your thoughts is how I can reduce the number of issues. The good news is that you can arrange those themes hierarchically, allowing you to choose the correct number of issues. The visualization flavor makes it easier to understand how they connect.
model.visualize_hierarchy(top_n_topics=30)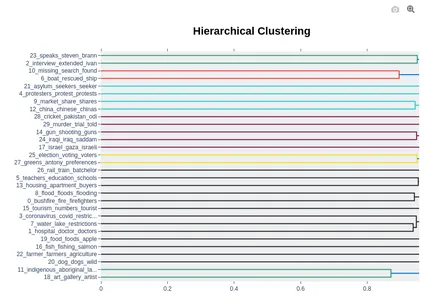
We can observe that themes with similar colors have been grouped by looking at the dendrogram’s first level (level 0). For illustration
- Topics 7 (health, a hospital, mental) and 14 (died, collapse killed) have been combined due to their proximity.
- Topics 6 (farmers, farms, and farmers) and 16 (cattle, sheep, and meat) must be classified similarly.
- These details can help the user understand why the subjects have been compared to one another.
Search Topics
Once we have trained the topic model, we can use the find_topics method to search for semantically related topics to a given input query word or phrase. For example, we may look for the top 3 subjects associated with the word “politics.”
# Select most 3 similar topics
similar_topics, similarity = model.find_topics("politics", top_n = 3)
- The subjects index in similar_topics is listed from most similar to least similar.
- Similarity ratings are shown in descending order within similarity.
similar_topics
most_similar = similar_topics[0]
print("Most Similar Topic Info: \n{}".format(model.get_topic(most_similar)))
print("Similarity Score: {}".format(similarity[0]))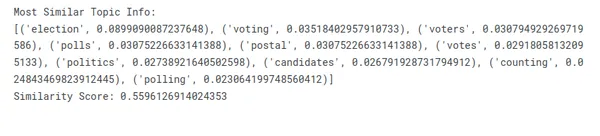
It is clear that phrases like “election,” “Trump,” and “Obama,” which unmistakably pertain to politics, represent the most comparable topics.
Model Serialization & Loading
When you are happy with the outcome of your model, you may store it for additional analysis by following these instructions:
%%bash
mkdir './model_dir
# Save the model in the previously created folder with the name 'my_best_model'
model.save("./model_dir/my_best_model")
# Load the serialized model
my_best_model = BERTopic.load("./model_dir/my_best_model")
my_best_model

Conclusion
Finally, topic modeling using BERT gives an effective method for locating hidden topics in textual data. Even though BERT was first developed for various natural language processing applications, one can use it for topic modeling by employing document embeddings and clustering approaches. Here are the key points from this article:
- The importance of topic modeling is that it enables businesses to get insightful information and make informed decisions by helping them to comprehend the underlying themes and patterns in massive volumes of unstructured text data.
- Although BERT is not the conventional approach for topic modeling, it can still offer insightful document embeddings essential for spotting latent themes.
- BERT creates document embeddings by removing semantic data from the [CLS] token’s output. These embeddings provide the documents with a dense vector space representation.
- Topic modeling with BERT is an area that is constantly developing as new research and technological developments improve its performance.
Overall, developing a mastery of topic modeling using BERT allows data scientists, researchers, and analysts to extract and analyze the underlying themes in sizable text corpora, producing insightful conclusions and well-informed decision-making.
Frequently Questions And Answer
Q1: What is BERT, and how is it related to topic modeling?
A1: Google developed BERT (Bidirectional Encoder Representations from Transformers), a pre-trained language model. It finds application in natural language processing tasks such as text classification and question-answering. In topic modeling, researchers use BERT to create document embeddings, which represent the semantic meaning of documents. They then cluster these embeddings to uncover latent topics within the corpus.
Q2: How is BERT different from traditional topic modeling algorithms like LDA or NMF?
A2: BERT differs from traditional algorithms like LDA (Latent Dirichlet Allocation) or NMF (Non-Negative Matrix Factorization) because it was not specifically designed for topic modeling. LDA and NMF explicitly model the generative process of documents based on topics. At the same time, BERT learns word representations in a context-rich manner through unsupervised training on a massive amount of text data.
Q3: Is BERT the best model for topic modeling?
A3: Depending on the use case, one can use BERT for topic modeling, but it may not always be the best choice. The choice of the best model depends on factors such as the size of the dataset, computational resources, and the specific objectives of the analysis.
Q4: What are document embeddings, and why are they essential in topic modeling with BERT?
A4: Document embeddings are dense vector representations that capture the semantic meaning of a document. In topic modeling with BERT, document embeddings are generated by extracting the vector representation of the [CLS] token’s output, which encodes the overall meaning of the entire document. These embeddings are crucial for clustering similar documents together to reveal latent topics.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi, I am Kajal Kumari. have completed my Master’s from IIT(ISM) Dhanbad in Computer Science & Engineering. As of now, I am working as Machine Learning Engineer in Hyderabad.
hope that you have enjoyed the article. If you like it, share it with your friends also. Please feel free to comment if you have any thoughts that can improve my article writing.
If you want to read my previous blogs, you can read Previous Data Science Blog posts here. Connect with me





