Organizing a vast dataset into an easily accessible structure is crucial. The Star schema provides an effective approach, comprising two key elements: fact table and dimension tables. Dimension tables encircle a central fact table, creating the star or snowflake shape. Clear distinctions between these components, especially in the context of fact table vs dimension table, require a comprehensive grasp of their individual concepts and roles, ensuring a solid understanding of their specific purposes. Let’s explore the difference between these two data models now!
Table of contents
- What is a Fact Table?
- What is Dimension Table?
- Fact Table vs Dimension Table
- Characteristics of Fact Table and Dimension Table
- Types: Fact vs Dimension Table
- Example: Fact vs Dimension Table
- Limitations of Fact Table and Dimension Table
- What are fact and dimension tables in a data warehouse?
- Conclusion
- Frequently Asked Questions
What is a Fact Table?
The fact table is a comprehensive collection of attributes derived from the dimension table. It contains quantitative data where dimension table attributes influence the values. This table holds denormalized data for analysis. Comprising two columns, one column stores foreign keys, while the other stores corresponding data or values. The foreign key column is linked with dimension table attributes, while the second column contains numerical values. Vertical expansion in the fact table is more pronounced, reflecting a growing number of records, as opposed to horizontal expansion with fewer attributes.
What is Dimension Table?
The dimension table is the significant part of the Star schema that provides measurable dimensional modeling for fact tables. The table witnesses horizontal expansion with thousands of rows with non-frequent updates. It is curated hierarchically and comprises quantitative data. The dimension table also contains two keys, primary and surrogate keys. The primary key concerns the presence of a unique identity in each row or record. The system-generated surrogate key is associated with row identification in the table.
Fact Table vs Dimension Table
| Parameters | Fact Table | Dimension Table |
|---|---|---|
| Basic | Contains quantitative data concerning business events | Provides descriptive context and attributes for the data in the fact table |
| Sequence of creation | Made after dimension table | Created first |
| Components | Facts, metrics and measurements | Descriptive attributes |
| Quantity of components | Fewer attributes and more records | Fewer records and more attributes |
| Marked by | Grain or atomic level | Words, completeness, level of detail |
| Hierarchy | Absent | Present |
| Location in Star schema | Middle | Edges |
| Purpose | Analysis and decision making | Data and process storage |
| Growth | Vertical | Horizontal |
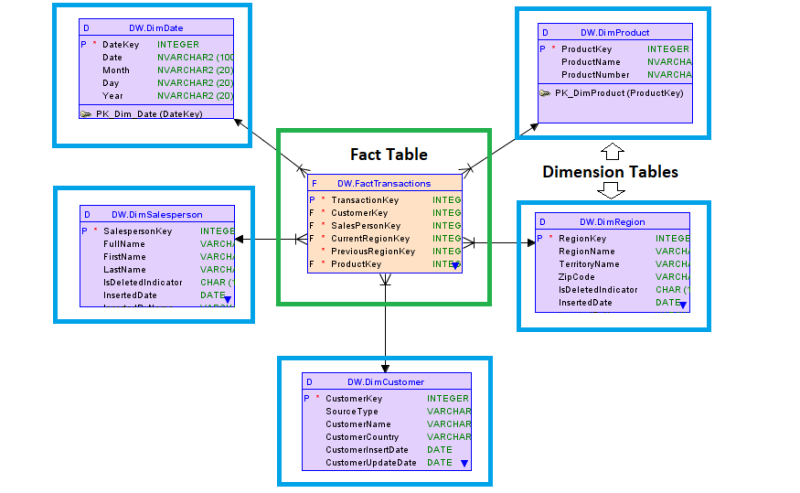
Characteristics of Fact Table and Dimension Table
The characteristics of the fact table and dimension table are as follows:
Characteristics of Fact Table:
- Comprises data from various dimension tables.
- Contains primary or foreign keys, including concatenated keys for row identification.
- A high-quality fact table holds detailed information at the highest level, with the extent of information determined by the fact table grain.
- Data records within the fact table do not have null values.
- Non-additive dimensions can be present, reflecting dimensions that cannot be simply added together.
- Fact table attributes are categorized as fully additive, semi-additive, and non-additive, depending on their behavior across dimensions.
- Fully additive attributes have values across all dimensions. In contrast, semi-additive attributes have values in specific dimensions, and non-additive attributes represent the basic unit of measurement in the organizational process.
- Fact table dimensions serve as subdivisions of rows and columns based on base dimensions.
Characteristics of Dimension Table:
- Contains descriptive textual or categorical data that provides context to the fact table.
- Holds attributes support grouping, filtering, and categorizing the data in the fact table.
- Used to provide business context and details about specific aspects of data in the fact table.
- Typically have fewer records compared to the fact table.
- Enables querying and analyzing data from different perspectives, enhancing data insights.
- Used to define hierarchies that allow drilling down into data.
- Can contain redundant data due to data denormalization, improving query performance.
- Typically not directly connected but linked to the fact table via foreign keys.
- Often present in star schema or snowflake schema designs for efficient data organization.
Types: Fact vs Dimension Table
There are different types of facts and dimensions. Additionally, there are different types of fact table and dimension table.
Types of Fact Tables
Transaction Fact Tables
They capture the individual business or transaction events as soon as they occur. Order updates and discrete actions in sales operations is an example of this. Such tables also have a high level of detail and grow significantly in size. The usage of these tables is suitable for data analysis at a granular level. However, they may require complex queries for performance.
Periodic Snapshot Tables
These tables store aggregated data at predefined intervals. These tables are preferred for storing the summarized data of specific times and periods. It is of importance when required to analyze trends and changes over time without affecting the individual transactions.
Accumulating Snapshot Tables
These tables are significant for tracking the progress of a process or workflow over time. Holding more superficial information, it covers the milestones or stages of different processes. In such tables, rows represent the progression of the entity through various stages, which further helps in easy tracking and analysis of the process. The application is seen in project management, order fulfillment and production cycles.
Factless Fact Tables
These tables lack measurable numerical facts or data. They are used to capture relationships between dimensions crucial for contextual analysis. The application is seen in tracking occurrences, events or associations significant to the business process. Users use these for insights into patterns and trends.

Types of Facts
- Summative facts These are used with aggregation functions such as average(), sum() and others.
- Semi-summative facts: They require a few aggregation functions like minimum() and maximum().
- Additive facts: These facts can be summed across the dimensions and are used with aggregation functions.
- Non-additive facts: They encompass the usage of facts, percentages or ratios where aggregation functions do not work.
Types of Dimension Tables
The type of dimension table varies with the dimension. Here, there are common types of both as enlisted:
Slowly Changing Dimensions or SCD
Here, the dimensions witness slow changes rather than periodic changes. Change in tables can be done in three ways, type 1, type 2 and type 3.
- Type 1 includes overwriting the previous value and hence is cost-efficient. However, it also does not account for the history of the data.
- Type 2 includes adding a new row and, subsequently, the value. Here the history remains but consumes space and hence does not prevent additional expenditure. Also, the information details are repeated as all the entities remain the same, but only a few values change
- Type 3 includes adding a column that provides history as well as prevents excess cost loss.
Degenerate Dimension
Here, the dimension or attribute is stored in the fact table rather than in a separate dimension table. For example, invoice or transaction numbers are degenerate dimensions.
Junk Dimension
The junk dimension table comprises a mixture of unrelated and different attributes. Thus the table is less complex and is often suited for rapidly changing dimensions.
Role Play Dimensions
The table comprises numerous valid relationships with the fact table. It involves the usage of specific attributes for different and multiple attributes. For instance, the Date dimension will be used for both ‘order date’ and ‘shipment date’.
Conformed Dimension
The attribute is used in multiple locations in fact tables in the data warehouse. It maintains consistency and avoids discrepancy.
Example: Fact vs Dimension Table
Let us understand the fact and dimension table with certain examples. Suppose there is production of noodles in an industry. Fact table involves organized data on food processing, storage and delivery information. The fact table can be structured like:
| Serial Number | Scheduled Measures |
|---|---|
| 1 | Processing_Data |
| 2 | Packaging_Data |
| 3 | Storage_Data |
| 4 | Delivery_Data |
The fact table organized a structure of the scheduled measures of the overall processing of the product. The dimension table will be made using the fact table like the following.
Processing_Data
Detailed information about the processing will be reported in the table.
| Processing Material | Supplier | Date of Expiry |
|---|---|---|
| White_flour | Supplier A | xx-xx-yy |
| Salt | Supplier B | xx-xx-yy |
| Oil | Supplier C | xx-xx-yy |
Packaging_Data
Packaging involved structured information specifically of the packaging.
| Packaging Material ID | Supplier | Material Type | Unit Price |
|---|---|---|---|
| 111 | Supplier K | Plastic | $10 |
| 112 | Supplier L | Cardboard | $9.5 |
| 113 | Supplier M | Wrapping_tissue | $7.2 |
Storage_Data
Storage information is prepared via a dimension table, where detailed analyses have been done on each product stored.
| Product Number | Supervision | Hall no. | Shelf no. |
|---|---|---|---|
| 51 | Officer A | B1 | B-B2 |
| 52 | Officer B | C2 | C-H13 |
| 53 | Officer C | H1 | H-Y2 |
Delivery_Data
The dimension table represents organised observation on delivery data.
| Trunk code | Supervision | Delivered City | Date of Delivery |
|---|---|---|---|
| AA2 | Agent X | Atlanta | xx-xx-yy |
| AA53 | Agent Y | Albany | xx-xx-yy |
| BC1 | Agent Z | Homerville | xx-xx-yy |
Limitations of Fact Table and Dimension Table
The limitations of fact and dimension tables are enlisted individually as follows:
Fact Table
- The fact tables are prepared to contain data to a certain limit, exceeding which it does not support and requires additional modifications like restructuring of tables and processing of data.
- In case of specific alterations in the data source, the table must be reaccumulated.
- A thorough explanation is not achieved using a fact table. The greater the information, the more complex the query performance.
- In real-time analysis or modifications, we cannot be sure of the data integrity of the fact table.
- Higher the scale, the more difficult to maintain the performance in the fact table.
Dimension Table
There are certain limitations in the dimensions tables
- Data redundancy issues occur when values get repeated. Resolving the issue by denormalization can worsen the problem.
- Historical data and data integrity is quite tough when there are timely alterations in dimension attributes. Thus, to maintain accuracy, types of slow-changing dimensions (SCDs) are required.
- Dimension tables are specific for pre-accumulated information covering every important aspect of analytical requirements. Thus, due to limited flexibility, additional processing may need a customized accumulation of data.
- Efficiency performance is not compatible with increasing scalability. Therefore, efficient strategies are required to maintain the analysis speed and responsiveness.
- Data integrity could be hampered by inaccurate data, leading to errors in analysis.
What are fact and dimension tables in a data warehouse?
In a data warehouse, fact tables and dimension tables work together to store and analyze business data. They form the foundation of a data warehouse schema, typically designed in a star schema or snowflake schema.
Fact tables store quantitative data, also known as measures or facts. This is the numerical data you use to analyze trends, comparisons, and other metrics. Examples of facts include sales figures, website clicks, or inventory levels. Fact tables tend to have fewer attributes but many rows, with each row representing a single event or transaction.
Dimension tables provide context and descriptive details about the facts in the fact table. They contain non-numerical attributes that categorize and define the measures. Think of them as providing the “who, what, when, where, why, and how” behind the numbers in the fact table. Examples of dimensions include customer information (customer dimension), product details (product dimension), dates, or locations. Dimension tables tend to have more attributes but fewer rows.
When designing a data warehouse, it’s crucial to consider various aspects like Power BI integration for visualizations, the structure of your data mart, and potential interview questions about your design choices. Effective design helps ensure your data tables are optimized for performance and easy to query.
Conclusion
In conclusion, understanding the roles of dimension and fact tables within data warehousing and business intelligence systems is paramount for effective data analysis. With their widespread applications, accurate differentiation is crucial for seamless operations. Fact tables hold numerical data, whereas dimension tables provide descriptive context to the information stored in fact tables. When tackling queries related to ‘what’ and ‘how much,’ refer to the fact table. For insights into ‘who,’ ‘where,’ ‘when,’ and ‘why,’ turn to the dimension table. This foundational understanding enables optimal utilization of these tables for enhanced decision-making and analytical capabilities.So, with this tutorial hope you understand the difference between fact table and dimension table.
Ready to deepen your understanding of data analysis? Take your skills to the next level with Analytics Vidhya’s Blackbelt program and excel in the world of data-driven insights.
Frequently Asked Questions
Q1. What is a fact table and dimension table?
A. Fact table stores quantitative data representing business events or transactions. The dimension table contains descriptive attributes for the fact table data.
Q2. What is an example of a fact table?
A. Consider a sales fact table of a business. The components of the fact table will be order data, product ID, customer ID and sales amount with vertical enlistments of multiple details
Q3. Which is the first dimension or fact table?
A. Dimension tables are designed before fact tables as they provide the context and description for the fact tables.
Q4. What are fact table types?
A. The fact tables are of four types, transaction fact, periodic snapshot fact, accumulating snapshot fact and factless fact tables.
Q5. What is the reason for the fact table being larger than the dimension table?
Fact tables are larger than dimension tables due to their distinct roles in storing and organizing data. Fact tables contain numerical data and may include multiple measures for each dimension combination, while dimension tables hold descriptive attributes. Additionally, fact tables may be denormalized to enhance query performance, further increasing their size.







