Introduction
In the dynamic world of machine learning, one constant challenge is harnessing the full potential of limited labeled data. Enter the realm of semi-supervised learning—an ingenious approach that harmonizes a small batch of labeled data with a trove of unlabeled data. In this article, we explore a game-changing strategy: leveraging generative models, specifically Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs). By the end of this captivating journey, you’ll understand how these generative models can profoundly enhance the performance of semi-supervised learning algorithms, like a masterful twist in a gripping narrative.
Learning Objectives
- We’ll start by diving into semi-supervised learning, understanding why it matters, and seeing how it’s used in real-life machine-learning scenarios.
- Next, we’ll introduce you to the fascinating world of generative models, focusing on VAEs and GANs. We’ll find out how they supercharge semi-supervised learning.
- Get ready to roll up your sleeves as we guide you through the practical side. You’ll learn how to integrate these generative models into real-world machine-learning projects, from data prep to model training.
- We’ll highlight the perks, like improved model generalization and cost savings. Plus, we’ll showcase how this approach applies across different fields.
- Every journey has its challenges, and we’ll navigate those. We will also see the important ethical considerations, ensuring you’re well-equipped to responsibly use generative models in semi-supervised learning.
This article was published as a part of the Data Science Blogathon.
Table of contents
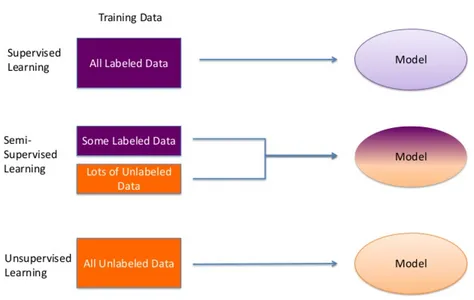
Introduction to Semi-Supervised Learning
In the large landscape of machine learning, acquiring labeled data can be daunting. It often involves time-consuming and costly efforts to annotate data, which can limit the scalability of supervised learning. Enter semi-supervised learning, a clever approach that bridges the gap between the labeled and unlabeled data realms. It recognizes that while labeled data is very important, vast pools of unlabeled data often lie dormant, ready to be harnessed.
Imagine you’re tasked with teaching a computer to recognize various animals in images but labeling each one is a Herculean effort. That’s where semi-supervised learning comes in. It suggests mixing a small batch of labeled images with a large pool of unlabeled ones for training machine learning models.This approach lets the model tap into the untapped potential of unlabeled data, improving its performance and adaptability. It’s like having a handful of guiding stars to navigate through a galaxy of information.
In our journey through semi-supervised learning, we’ll explore its importance, fundamental principles, and innovative strategies, with a particular focus on how generative models like VAEs and GANs can amplify its capabilities. Let’s unlock the power of semi-supervised learning, hand in hand with generative models.
Generative Models: Enhancing Semi-Supervised Learning
In the captivating world of machine learning, generative models emerge as real game-changers, breathing new life into semi-supervised learning. These models possess a unique talent—they can not only take the intricacies of data but also conjure new data that mirrors what they’ve learned. Among the best performers in this arena are Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs). Let’s embark on a journey to find out how these generative models become catalysts, pushing the boundaries of semi-supervised learning.
VAEs excel at capturing the essence of data distributions. They do so by mapping input data into a hidden space and then meticulously reconstructing it. This ability finds a profound purpose in semi-supervised learning, where VAEs encourage models to distill meaningful and concise data representations. These representations, cultivated without the need for an abundance of labeled data, hold the key to improved generalization even when faced with limited labeled examples. On the other stage, GANs engage in an intriguing adversarial dance. Here, a generator strives to craft data virtually indistinguishable from real data, while a discriminator thinks the role of a vigilant critic. This dynamic duet results in data augmentation and paves the way for generating entirely new data values. It’s through these captivating performances that VAEs and GANs take the spotlight, ushering in a new era of semi-supervised learning.
Practical Implementation Steps
Now that we’ve explored the theoretical aspects, it’s time to roll up our sleeves and delve into the practical implementation of semi-supervised learning with generative models. This is where the magic happens, where we convert ideas into real-world solutions. Here are the needed steps to bring this synergy to life:

Step 1: Data Preparation – Setting the Stage
Like any well-executed production, we need a good and best foundation. Start by collecting your data. You should have a small set of labeled data and a substantial reservoir of unlabeled data. Ensure that your data is clean, well-organized, and ready for the limelight.
# Example code for data loading and preprocessing
import pandas as pd
from sklearn.model_selection import train_test_split
# Load labeled data
labeled_data = pd.read_csv('labeled_data.csv')
# Load unlabeled data
unlabeled_data = pd.read_csv('unlabeled_data.csv')
# Preprocess data (e.g., normalize, handle missing values)
labeled_data = preprocess_data(labeled_data)
unlabeled_data = preprocess_data(unlabeled_data)
# Split labeled data into train and validation sets
train_data, validation_data = train_test_split(labeled_data, test_size=0.2, random_state=42)
#import csvStep 2: Incorporating Generative Models – The Special Effects
Generative models, our stars of the show, take center stage. Integrate Variational Autoencoders (VAEs) or Generative Adversarial Networks (GANs) into your semi-supervised learning pipeline. You can choose to train a generative model on your unlabeled data or use it for data augmentation. These models add the special effects that make your semi-supervised learning shine.
# Example code for integrating VAE for data augmentation
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input, Lambda
from tensorflow.keras import Model
# Define VAE architecture (encoder and decoder)
# ... (Define encoder layers)
# ... (Define decoder layers)
# Create VAE model
vae = Model(inputs=input_layer, outputs=decoded)
# Compile VAE model
vae.compile(optimizer='adam', loss='mse')
# Pretrain VAE on unlabeled data
vae.fit(unlabeled_data, unlabeled_data, epochs=10, batch_size=64)
#import csvStep 3: Semi-Supervised Training – Rehearsing the Ensemble
Now, it’s time to train your semi-supervised learning model. Combine the labeled data with the augmented data generated by the generative models. This ensemble cast of data will empower your model to extract important features and generalize effectively, just like a seasoned actor nailing their role.
# Example code for semi-supervised learning using TensorFlow/Keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Create a semi-supervised model (e.g., neural network)
model = Sequential()
# Add layers (e.g., input layer, hidden layers, output layer)
model.add(Dense(128, activation='relu', input_dim=input_dim))
model.add(Dense(64, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model with both labeled and augmented data
model.fit(
x=train_data[['feature1', 'feature2']], # Use relevant features
y=train_data['label'], # Labeled data labels
epochs=50, # Adjust as needed
batch_size=32,
validation_data=(validation_data[['feature1', 'feature2']], validation_data['label'])
)Step 4: Evaluation and Fine-Tuning – The Dress Rehearsal
Once the model is trained, it’s time for the dress rehearsal. Evaluate its performance using a separate validation dataset. Fine-tune your model based on the results. Iterate and refine until you achieve optimal results, just as a director fine-tunes a performance until it’s flawless.
# Example code for model evaluation and fine-tuning
from sklearn.metrics import accuracy_score
# Predict on the validation set
y_pred = model.predict(validation_data[['feature1', 'feature2']])
# Calculate accuracy
accuracy = accuracy_score(validation_data['label'], y_pred.argmax(axis=1))
# Fine-tune hyperparameters or model architecture based on validation results
# Iterate until optimal performance is achievedIn these practical steps, we convert concepts into action, complete with code snippets to guide you. It’s where the script comes to life, and your semi-supervised learning model, powered by generative models, takes its place in the spotlight. So, let’s move forward and see this implementation in action.
Benefits and Real-world Applications
When we combine generative models with semi-supervised learning, the results are game-changing. Here’s why it matters:
1. Enhanced Generalization: By harnessing unlabeled data, models trained in this way perform exceptionally well on limited labeled examples, much like a talented actor who shines on stage even with minimal rehearsal.
2. Data Augmentation: Generative models,like VAEs and GANs, provide a rich source of augmented data. This boosts model robustness and prevents overfitting, like a unique prop department creating endless scene variations.
3. Reduced Annotation Costs: Labeling data can be expensive. Integrating generative models reduces the need for extensive data annotation, optimizing your production budget.
4. Domain Adaptation: This approach excels in adapting to new, unseen domains with minimal labeled data, similar to an actor seamlessly transitioning between different roles.
5. Real-World Applications: The possibilities are large. In natural language processing, it enhance sentiment analysis, language translation, and text generation. In computer vision, it elevates image classification, object detection, and facial recognition. It’s a valuable asset in healthcare for disease diagnosis, in finance for fraud detection, and in autonomous driving for improved perception.
This isn’t just theory—it’s a practical game-changer across diverse industries, promising captivating results and performance, much like a well-executed film that leaves a lasting impact.
Challenges and Ethical Considerations
In our journey through the exciting terrain of semi-supervised learning with generative models, it is needed to shed light on the challenges and ethical considerations that accompany this innovative approach.
- Data Quality and Distribution: One of the main challenges lies in ensuring the quality and representativeness of the data used for training generative models and subsequent semi-supervised learning. Biased or noisy data can lead to skewed results, much like a flawed script affecting the entire production.
- Complex Model Training: Integrating generative models can introduce complexity into the training process. It needs expertise in not only traditional machine learning but in the nuances of generative modeling.
- Data Privacy and Security: As we work with large amounts of data, ensuring data privacy and security becomes paramount. Handling sensitive or personal information requires strict protocols, similar to safeguarding confidential scripts in the entertainment industry.
- Bias and Fairness: The use of generative models must be compiled with vigilance to prevent biases from being perpetuated in the generated data or influencing the model’s decisions.
- Regulatory Compliance: Multiple industries, such as healthcare and finance, have stringent regulations governing data usage. Adhering to these regulations is compulsory, much like ensuring a production complies with industry standards.
- Ethical AI: There’s the overarching ethical consideration of the impact of AI and machine learning on society. Ensuring that the benefits of these technologies are accessible and equitable to all is akin to promoting diversity and inclusion in the entertainment world.
As we navigate these challenges and ethical considerations, it is necessary to approach the integration of generative models into semi-supervised learning with diligence and responsibility. Much like crafting a thought-provoking and socially conscious piece of art, this approach should aim to enrich society while minimizing harm.

Experimental Results and Case Studies
Now, let’s delve into the heart of the matter: experimental results that showcase the tangible impact of combining generative models with semi-supervised learning
- Improved Image Classification: In the realm of computer vision, researchers conducted experiments using generative models to augment limited labeled datasets for image classification. The results were remarkable; models trained with this approach demonstrated significantly higher accuracy compared to traditional supervised learning methods.
- Language Translation with Limited Data: In the field of natural language processing, case studies proved the effectiveness of semi-supervised learning with generative models for language translation. With only a minimal amount of labeled translation data and a large amount of monolingual data, the models were able to achieve impressive translation accuracy.
- Healthcare Diagnostics: Turning our attention to healthcare, experiments showcased the potential of this approach in medical diagnostics. With a shortage of labeled medical images, semi-supervised learning, boosted by generative models, allowed for accurate disease detection.
- Fraud Detection in Finance: In the finance industry, case studies showcased the prowess of generative models in semi-supervised learning for fraud detection. By augmenting labeled data with examples, models achieved high precision in identifying fraudulent transactions.
Semi-supervised learning illustrate how this synergy can lead to remarkable outcomes across diverse domains, much like the collaborative efforts of professionals in different fields coming together to create something great.
Conclusion
In this exploration between generative models and semi-supervised learning, we have uncovered a groundbreaking approach that holds the promise of revolutionizing ML. This powerful synergy addresses the perennial challenge of data scarcity, enabling models to thrive in domains where labeled data is scarce. As we conclude, it’s evident that this integration represents a paradigm shift, unlocking new possibilities and redefining the landscape of artificial intelligence.
Key Takeaways
1. Efficiency Through Fusion: Semi-supervised learning with generative models bridges the gap between labeled and unlabeled data, giving a more efficient and cost-effective path to machine learning.
2. Generative Model Stars: Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) play pivotal roles in augmenting the learning process, akin to talented co-stars elevating a performance.
3. Practical Implementation Blueprint: Implementation involves careful data preparation, seamless integration of generative models, rigorous training, iterative refinement, and vigilant ethical considerations, mirroring the meticulous planning of a major production.
4. Versatile Real-World Impact: The benefits extend across diverse domains, from healthcare to finance. Showing the adaptability and real-world applicability of this approach, much like a different and unique script that resonates with different audiences.
5. Ethical Responsibility: As with any tool, ethical considerations are at the forefront. Ensuring fairness, privacy, and responsible AI usage is paramount, similar to maintaining ethical standards in the arts and entertainment industry.
Frequently Asked Questions
Q1: What is semi-supervised learning, and why is it important?
A. It is a machine-learning approach that uses a limited set of labeled data in conjunction with a larger pool of unlabeled data. Its importance lies in its ability to improve learning in scenarios where there is limited labeled data available.
Q2: How do generative models like VAEs and GANs improve semi-supervised learning?
A. VAEs and GANs improve semi-supervised learning by generating meaningful data representations and augmenting labeled datasets, boosting model performance.
Q3: Can you provide a practical overview of implementing this approach?
A. Sure! Implementation involves data preparation, integrating generative models, semi-supervised training, and iterative model refinement, resembling a production process.
Q4: What real-world applications benefit from combining generative models with semi-supervised learning?
A. Multiple domains, such as healthcare, finance, and natural language processing, benefit from improved model generalization, reduced annotation costs, and improved performance, similar to diverse fields benefiting from different and unique scripts.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I have recently graduated aselectrical engineering at IIT Jodhpur. I am interested in software and data engineering domain. I am exploring the same . I am good at organizing skills and team management





