Large-scale unsupervised language models have exhibited remarkable capabilities in acquiring broad world knowledge and reasoning skills from vast datasets. However, the unsupervised nature of their training makes it challenging to precisely control their behavior, leading to potential misalignments with desired outcomes. Traditional methods to enhance control over LMs involve reinforcement learning from human feedback (RLHF), a complex and often unstable process requiring the fitting of a reward model and fine-tuning the LM to align with human preferences.
This article introduces Direct Preference Optimization (DPO), a novel approach that simplifies this process by parameterizing the reward model in a way that enables the extraction of the optimal policy in closed form. DPO offers a stable, performant, and computationally efficient alternative to RLHF by eliminating the need for reinforcement learning and the extensive hyperparameter tuning that it entails. Through empirical evaluations, DPO demonstrates its effectiveness in fine-tuning LMs to align with human preferences, surpassing traditional RLHF approaches in various tasks, including sentiment control and summarization, while being significantly simpler to implement and train.
Take your AI innovations to the next level with GenAI Pinnacle. Fine-tune models like Gemini and unlock endless possibilities in NLP, image generation, and more. Dive in today! Explore Now
Table of contents
Understanding the Complexity of Traditional Language Models
Traditionally, the alignment of LMs with human preferences has been achieved through a complex process called Reinforcement Learning from Human Feedback (RLHF). This method involves a multi-stage process:
Supervised Fine-Tuning (SFT)
The RLHF process usually begins by fine-tuning a pre-trained language model on high-quality data for the specific downstream task(s) of interest, such as dialogue or summarization. This results in a model denoted as π^SFT.
Reward Modelling Phase
In this phase, the SFT model is used to generate pairs of responses (y_1, y_2) for given prompts x. Human labelers then express preferences between these responses, indicating which one they prefer (y_w ≻ y_l). These preferences are assumed to be generated by some latent reward model r*(y, x). The paper describes the Bradley-Terry (BT) model for modeling preferences:
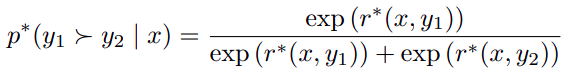
Given a dataset of comparisons:
D = {(x^(i), y^(i)_w, y^(i)_l)}^N_(i=1),
a reward model r^φ (x, y) is trained using maximum likelihood estimation.
The loss function for the reward model is:
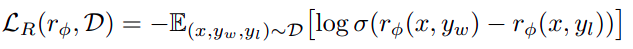
Where σ is the logistic function.
RL Fine-Tuning Phase
In this final phase, the learned reward function is used to provide feedback to the language model. The optimization is formulated as:
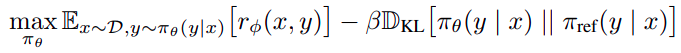
Where:
- π_θ is the policy being optimized
- r_φ is the learned reward function
- π_ref is the reference policy (usually the SFT model)
- β is a parameter controlling the deviation from the reference policy
This objective aims to maximize the expected reward while keeping the policy close to the reference policy, as measured by the KL divergence.
The paper notes that, due to the discrete nature of language generation, researchers typically optimize this objective using reinforcement learning techniques, commonly Proximal Policy Optimization (PPO). They usually construct the reward function as:
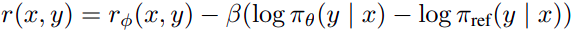
This reward function incorporates both the learned reward and the KL divergence term, which is then maximized using PPO.
What is Direct Preference Optimization (DPO)?
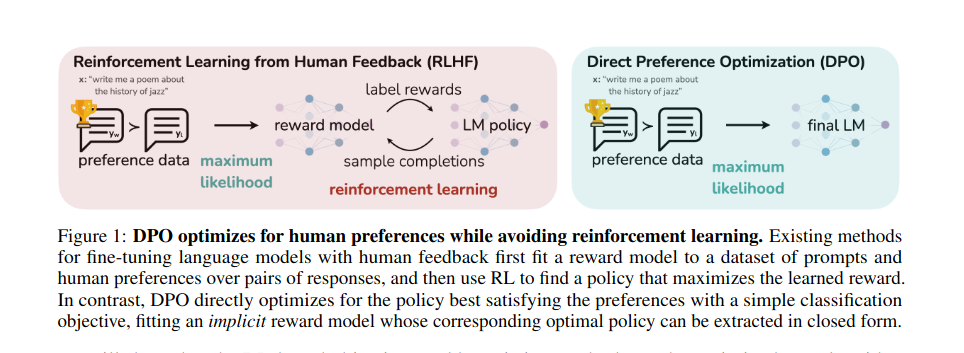
The paper introduces DPO, a new parameterization of the reward model in RLHF, which enables the extraction of the corresponding optimal policy in a closed form. This approach simplifies the RLHF problem to a simple classification loss, making the algorithm stable, performant, and computationally lightweight. DPO innovates by combining the reward function and language model into a single transformer network. This simplification means only the language model needs training, aligning it with human preferences more directly and efficiently. The elegance of DPO lies in its ability to deduce the reward function the language model is best at maximizing, thereby streamlining the entire process.
I asked ChatGPT to explain the above to a 5 year old and here is the result (hope you get a better understanding, let me know in comments):
“Imagine you have a big box of crayons to draw a picture, but you're not sure
which colors to choose to make the most beautiful picture. Before, you had
to try every single crayon one by one, which took a lot of time. But now,
with something called Direct Preference Optimization (DPO), it's like having
a magical crayon that already knows your favorite colors and how to make the
prettiest picture. So, instead of trying all the crayons,
you use this one
special crayon, and it helps you draw the perfect picture much faster and
easier. That's how DPO works; it helps computers learn what people like
quickly and easily, just like the magical crayon helps you make a beautiful
drawing.”
DPO is shown to fine-tune LMs to align with human preferences as well or better than existing methods, including PPO-based RLHF. It excels in controlling the sentiment of generations and matches or improves response quality in summarization and single-turn dialogue tasks. DPO is simpler to implement and train compared to traditional RLHF methods.
Technical Details
- DPO’s Mechanism: DPO directly optimizes for the policy that best satisfies the preferences using a simple binary cross-entropy objective, fitting an implicit reward model from which we can extract the corresponding optimal policy in closed form.
- Theoretical Framework: DPO relies on a theoretical preference model, like the Bradley-Terry model, that measures how well a given reward function aligns with empirical preference data. Unlike existing methods that train a policy to optimize a learned reward model, DPO defines the preference loss as a function of the policy directly.
- Advantages: DPO simplifies the preference learning pipeline significantly. It eliminates the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning.
Experimental Evaluation
- Performance on Tasks: Experiments demonstrate DPO’s effectiveness in tasks such as sentiment modulation, summarization, and dialogue. It shows comparable or superior performance to PPO-based RLHF while being substantially simpler.
- Theoretical Analysis: The paper also provides a theoretical analysis of DPO, relating it to issues with actor-critic algorithms used for RLHF and demonstrating its advantages.
DPO vs RLHF
Methodology
- DPO: Direct Preference Optimization focuses on directly optimizing language models to adhere to human preferences. It operates without explicit reward modeling or reinforcement learning, simplifying the training process. DPO optimizes the same objectives as RLHF but with a straightforward binary cross-entropy loss. It increases the relative log probability of preferred responses and uses a dynamic importance weight to prevent model degeneration.
- RLHF: Reinforcement Learning from Human Feedback typically involves a complex procedure that includes fitting a reward model based on human preferences and fine-tuning the language model using reinforcement learning to maximize this estimated reward. This process is more computationally intensive and can be unstable.
Implementation Complexity
- DPO: Easier to implement due to its simplicity and direct approach. It does not require significant hyperparameter tuning or sampling from the language model during fine-tuning.
- RLHF: Involves a more complex and often unstable training process with reinforcement learning, requiring careful hyperparameter tuning and potentially sampling from the language model.
Efficiency and Performance
- DPO: Demonstrates at least equal or superior performance to RLHF methods, including PPO-based RLHF, in tasks like sentiment modulation, summarization, and dialogue. It is also computationally lightweight and provides a stable training environment.
- RLHF: While effective in aligning language models with human preferences, it can be less efficient and stable compared to DPO, especially in large-scale implementations.
Theoretical Foundation
- DPO: Leverages an analytical mapping from reward functions to optimal policies, enabling a transformation of a loss function over reward functions into a loss function over policies. This avoids fitting an explicit standalone reward model while still optimizing under existing models of human preferences.
- RLHF: It typically uses a traditional reinforcement learning approach, training a reward model based on human preferences and then optimizing a policy to maximize this learned reward model.
Empirical Results
- DPO: In empirical evaluations, DPO has shown to produce more efficient frontiers in terms of reward/KL tradeoff compared to PPO, achieving higher rewards while maintaining low KL. It also demonstrates better performance in fine-tuning tasks like summarization and dialogue.
- RLHF: PPO and other RLHF methods, while effective, may not achieve as efficient a reward/KL tradeoff as DPO. They may require access to ground truth rewards for optimal performance, which is not always feasible.
Consequences of using DPO
First off, a reward model is not necessary for DPO! To make the model more accurate, all it needs is high-quality data that clearly indicates what is good and bad.
DPO is dynamic, too. Because of the way it determines which route to travel, it will instantly change each time you use new data. This is a huge win over PPO, where you have to retrain your reward model every time you get fresh data.
Third, DPO lets you train a model to steer clear of certain subjects while yet learning how to provide accurate responses for others. The new loss equation might be thought of as a signal that directs our training, for example. We are educating the model to avoid some answers just as much as we are telling them to go towards others by providing both a good and a negative example. This feature is highly helpful because fine-tuning entails the model disregarding some subjects to a considerable extent.
Final Thought
DPO presents a powerful and scalable framework for training language models aligned with human preferences, reducing the complexity associated with RLHF algorithms. Its emergence is a clear sign that the field of AI, particularly in language model development, is ripe for innovation and growth. With DPO, the future of language models seems poised for significant advancements, driven by insightful algorithmic and mathematical research.
Additional Helpful Links:
- Link to Andrew Ng’s Post: https://www.linkedin.com/posts/andrewyng_ai-discovers-new-antibiotics-openai-revamps-activity-7151282706947969025-WV2v/
- DPO Github Repository: https://github.com/eric-mitchell/direct-preference-optimization
- DPO Trainer: https://huggingface.co/docs/trl/main/en/dpo_trainer
- DPO Research Paper: https://arxiv.org/abs/2305.18290
Dive into the future of AI with GenAI Pinnacle. From training bespoke models to tackling real-world challenges like PII masking, empower your projects with cutting-edge capabilities. Start Exploring.
Frequently Asked Questions
Q1: What is Direct Preference Optimization (DPO)?
A: Direct Preference Optimization (DPO) is a popular training method used for the instruction fine-tuning of large language models (LLMs). It focuses on directly optimizing the language model to adhere to human preferences without the need for explicit reward modeling. Recent research explores the impact of DPO’s dependency on the reference model or policy used during training.
Q2: What are PPO and DPO in the context of LLMs?
A: Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) are both methods for aligning LLMs with human preferences. PPO is a reinforcement learning technique that is effective but complex and computationally intensive. DPO simplifies the process by directly optimizing the model based on human feedback, eliminating the need for explicit reward models.
Q3: What is preference optimization?
A: Preference optimization simplifies the training of models by comparing and ranking candidate answers instead of assigning fixed labels. It allows models to better capture the subtleties of human judgment, making it a useful technique for aligning AI behavior with human preferences.
I’m a data lover who enjoys finding hidden patterns and turning them into useful insights. As the Manager - Content and Growth at Analytics Vidhya, I help data enthusiasts learn, share, and grow together.
Thanks for stopping by my profile - hope you found something you liked :)





