If you meet 10 people who have been in data science for more than 5 years, chances are that all of them would know of or would have used SQL at some time in some form! Such is the extent of influence SQL has had on any thing to do with structured data.
In this article, we will learn basics of SQL and focus on SQL for RDBMS. As you will see, SQL is quite easy to learn and understand.
What is SQL?
SQL stands for Structured Query Language. It is a standard programming language for accessing a relational database. It has been designed for managing data in Relational Database Management Systems (RDBMS) like Oracle, MySQL, MS SQL Server, IBM DB2.
SQL is one of the first commercial languages used for Edgar F. Codd’s relational model, also described in his influential 1970 paper, “A Relational Model of Data for Large Shared Data Banks.”
Earlier, SQL was a de facto language for the generation of information technology professionals. This was due to the fact that data warehouses consisted of one or the other RDBMS. The simplicity and beauty of the language enabled data warehousing professionals to query data and provide it to business analysts.
However, the trouble with RDBMS is that they are often suitable only for structured information. For unstructured information, newer databases like MongoDB and HBase (from Hadoop) prove to be a better fit. Part of this is a trade-off in databases, which is due to the CAP theorem.
What is CAP Theorem?
CAP theorem states that at best we can aim for two of three following properties. CAP stands for:
Consistency – This means that data in the database remains consistent after the execution of an operation.
Availability – This means that the database system is always on to ensure availability.
Partition Tolerance – This means that the system continues to function even if the transfer of information amongst the servers is unreliable.
The various databases and their relations with CAP theorem is shown below:
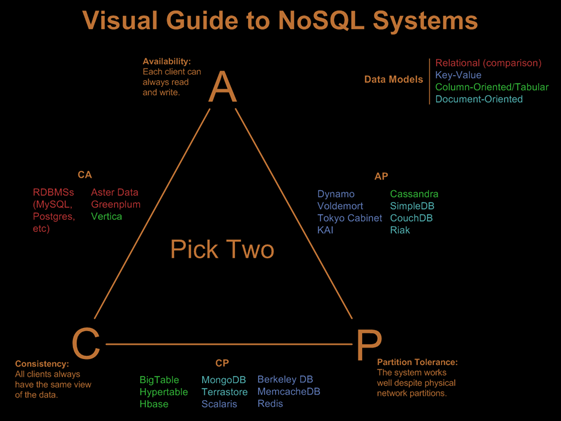
Properties of Databases:
A database transaction, however, must be ACID compliant. ACID stands for Atomic, Consistent, Isolated and Durable as explained below:
Atomic : A transaction must be either completed with all of its data modifications, or may not.
Consistent : At the end of the transaction, all data must be left consistent.
Isolated : Data modifications performed by a transaction must be independent of other transactions.
Durable : At the end of transaction, effects of modifications performed by the transaction must be permanent in system.
To counter ACID, the consistent services provide BASE (Basically Available, Soft state, Eventual consistency) features .
Set of Commands in SQL
SELECT- The following is an example of a SELECT query that returns a list of inexpensive books. The query retrieves all rows from the Library table in which the price column contains a value lesser than 10.00. The result is sorted in ascending order by price. The asterisk (*) in the select list indicates that all columns of the Book table should be included in the result set.
SELECT * FROM Library WHERE price < 10.00 ORDER BY price;
UPDATE – This query helps in updating tables in a database. One can also combine SELECT query with the GROUP BY operator for aggregating statistics for a numeric variable by a categoric variable.
JOINS- SQL is thus heavily used not only for querying data but also for joining the data returned by such queries or tables. Merging data in SQL is done using ‘joins’. The following infographic often used for explaining SQL Joins:
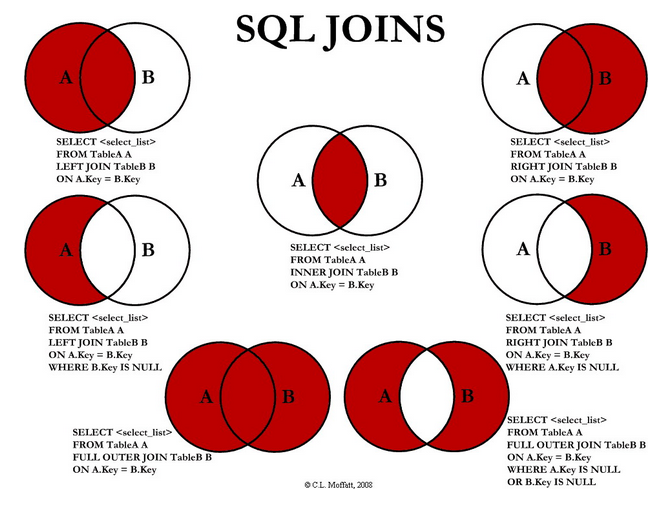
CASE- We have case/when/then/else/end operator in SQL. It works like else if in other programming languages:
CASE WHEN n > 0 THEN 'positive' WHEN n < 0 THEN 'negative' ELSE 'zero' END
Nested Sub Queries– Queries can be nested such that the results of one query can be used in another query via a relational operator or aggregation function. A nested query is also known as a subquery.
Where do we use SQL?
SQL has been widely used to retrieve data, merge data, perform group and nested case queries for decades. Even for data science, SQL has been widely adopted. Following are some examples of analytics specific use of SQL:
- In case of SAS language using PROC SQL we can write SQL queries to query, update and manipulate data.
- In R one can use the sqldf package for running sql queries on data frames.
- In Python pandasql library allows you to query pandas DataFrames using SQL syntax.
Does SQL influences other languages as well?
The drawback with relational databases is that they cannot handle unstructured data. To deal with the emergence, new databases have come up and they are given NoSQL as an alternative name to DBMS. But SQL is not dead yet.
Also See: A mapping of SQL to MongoDB
Below are some languages where SQL is found to have significant influence:
Hive – Apache Hive provides a mechanism to project structure onto the data in Hadoop and to query that data using a SQL-like language called HiveQL (HQL). It is a data warehouse infrastructure built on top of Apache™ Hadoop® for providing data summarization, ad hoc query, and analysis of large datasets. Even HQL, a language for querying used in Hadoop heavily uses influences of SQL. You can find out more here.
SQL-Mapreduce– Teradata uses Aster database that uses SQL with MapReduce for huge datasets in the Big Data era. SQL-MapReduce® is a framework created by Teradata Aster to allow developers to write powerful and highly expressive SQL-MapReduce functions in languages such as Java, C#, Python, C++, and R and push them into the discovery platform for high performance analytics. Analysts can then invoke SQL-MapReduce functions using standard SQL or R through Aster Database .
Spark SQL – Apache’s Spark project is for real-time, in-memory, parallelized processing of Hadoop data. Spark SQL builds on top of it to allow SQL queries to be written against data. In Cloudera’s Impala- Data stored in either HDFS or HBase can be queried, and the SQL syntax is the same as Apache Hive.
Also See: Find out more on ways to Query Hadoop using SQL here.
End Notes
In this article we discussed about SQL, its uses, CAP Theorem and influence of SQL on other languages. A basic knowledge of SQL is very relevant into today’s world where Python, R, SAS are dominant languages in data science. SQL remains relevant in the BIG DATA era. The beauty of the language remains its simplicty and elegant structure.
Thinkpot : Do you think SQL has become an inevitable weapon for data management? Would you recommend any other database language?
Share you views/opinion/comments with us in the comments section below. We would love to hear it from you!






Hi Ajay and Analytics Vidhya, This is very informative and useful article. Is it possible to provide a learning paths for SQL & RDMS and HBase (from Hadoop)? regards, Kaushal
Very Good content to present the purpose and few functions of SQL. Thanks for providing the SQL influences useful links.
Impressive- one query do a person need to learn SQL-HIVE-SQL(MAP REDUCE)-SPARK SQL to become Expert in SQL