Introduction
The landscape of artificial intelligence has been dramatically reshaped over the past few years by the advent of Large Language Models (LLMs). These powerful tools have evolved from simple text processors to complex systems capable of understanding and generating human-like text, making significant strides in both capabilities and applications. At the forefront of this evolution is Meta’s latest offering, Llama 3, which promises to push the boundaries of what open models can achieve in terms of accessibility and performance.
Table of contents
- Introduction
- Brief Introduction to Meta Llama 3
- Model Architecture and Improvements from Llama 2
- Benchmarking Results Compared to Other Models
- Evaluation on Standard and Custom Test Sets
- Training Data and Scaling Strategies
- Instruction of Fine-Tuning
- Deployment of Llama3
- Enhancements and Safety Features in Llama 3
- Future Developments for Llama 3
- Impact and Endorsement of Llama 3
- Conclusion
Key Features of Llama 3
- Llama 3 maintains a decoder-only transformer architecture with significant enhancements, including a tokenizer supporting 128,000 tokens, improving language encoding efficiency.
- Integrated across both 8 billion and 70 billion parameter models, enhancing inference efficiency for focused and effective processing.
- Llama 3 outperforms its predecessors and competitors across various benchmarks, excelling in tasks such as MMLU and HumanEval.
- Trained on over 15 trillion tokens dataset, seven times larger than Llama 2‘s dataset, incorporating diverse linguistic representation and non-English data from over 30 languages.
- Detailed scaling laws optimize data mix and computational resources, ensuring robust performance across diverse applications while tripling the training process’s efficiency compared to Llama 2.
- An enhanced post-training phase combines supervised fine-tuning, rejection sampling, and policy optimization to improve model quality and decision-making capabilities.
- Available across major platforms, it features enhanced tokenizer efficiency and safety features, empowering developers to tailor applications and ensure responsible AI deployment.
Talk of the AI Town
Clement Delangue, Co-founder & CEO at HuggingFace
Yann LeCun, Professor at NYU | Chief AI Scientist at Meta | Researcher in AI, Machine Learning, Robotics, etc. | ACM Turing Award Laureate.
New Feature
Get Personalized Learning Path! Set your goal and timeline. Get a path—under 2 mins.
Andrej Karpathy, Founding Team at OpenAI
Brief Introduction to Meta Llama 3
Meta Llama 3 represents the latest advancement in Meta’s series of language models, marking a significant step forward in the evolution of generative AI. Available now, this new generation includes models with 8 billion and 70 billion parameters, each designed to excel across a diverse range of applications. From engaging in everyday conversations to tackling complex reasoning tasks, Llama 3 sets a new standard in performance, outshining its predecessors on numerous industry benchmarks. Llama 3 is freely accessible, empowering the community to drive innovation in AI, from developing applications to enhancing developer tools and beyond.
Model Architecture and Improvements from Llama 2
Llama 3 maintains the proven decoder-only transformer architecture while incorporating significant enhancements that elevate its functionality beyond that of Llama 2. Adhering to a coherent design philosophy, Llama 3 includes a tokenizer that supports an extensive vocabulary of 128,000 tokens, greatly enhancing the model’s efficiency in encoding language. This development translates into markedly improved overall performance. Moreover, to boost inference efficiency, Llama 3 integrates Grouped Query Attention (GQA) across both its 8 billion and 70 billion parameter models. This model also employs sequences of 8,192 tokens with a masking technique that prevents self-attention from extending across document boundaries, ensuring more focused and effective processing. These improvements collectively enhance Llama 3’s capability to handle a broader array of tasks with increased accuracy and efficiency.
| Feature | Llama 2 | Llama 3 |
| Parameter Range | 7B to 70B parameters | 8B and 70B parameters, with plans for 400B+ |
| Model Architecture | Based on the transformer architecture | Standard decoder-only transformer architecture |
| Tokenization Efficiency | Context length up to 4096 tokens | Uses a tokenizer with a vocabulary of 128K tokens |
| Training Data | 2 trillion tokens from publicly available sources | Over 15T tokens from publicly available sources |
| Inference Efficiency | Improvements like GQA for the 70B model | Grouped Query Attention (GQA) for improved efficiency |
| Fine-tuning Methods | Supervised fine-tuning and RLHF | Supervised fine-tuning (SFT), rejection sampling, PPO, DPO |
| Safety and Ethical Considerations | Safe according to adversarial prompt testing | Extensive red-teaming for safety |
| Open Source and Accessibility | Community license with certain restrictions | Aims for an open approach to foster an AI ecosystem |
| Use Cases | Optimized for chat and code generation | Broad use across multiple domains with a focus on instruction-following |
Benchmarking Results Compared to Other Models
Llama 3 has raised the bar in generative AI, surpassing its predecessors and competitors across a variety of benchmarks. It has excelled particularly in tests such as MMLU, which evaluates knowledge in diverse areas, and HumanEval, focused on coding skills. Moreover, Llama 3 has outperformed other high-parameter models like Google’s Gemini 1.5 Pro and Anthropic’s Claude 3 Sonnet, especially in complex reasoning and comprehension tasks.
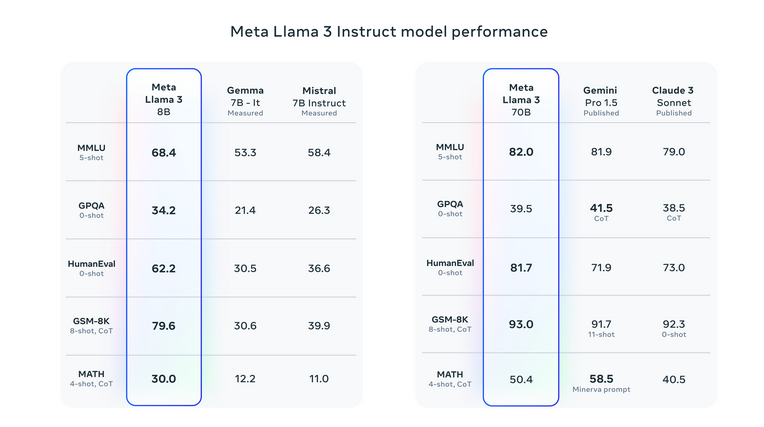
Please see evaluation details for setting and parameters with which these evaluations are calculated.
Evaluation on Standard and Custom Test Sets
Meta has created unique evaluation sets beyond traditional benchmarks to test Llama 3 across various real-world applications. This tailored evaluation framework includes 1,800 prompts covering 12 critical use cases: giving advice, brainstorming, classifying, answering both closed and open questions, coding, creative composition, data extraction, role-playing, logical reasoning, text rewriting, and summarizing. Restricting access to this specific set, even for Meta’s modeling teams, safeguards against potential overfitting of the model. This rigorous testing approach has proven Llama 3’s superior performance, frequently outshining other models. Thus underscoring its adaptability and proficiency.
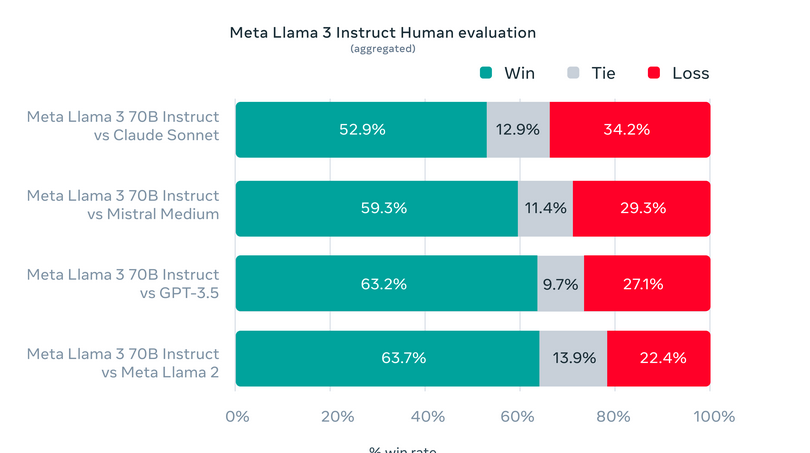
Please see evaluation details for setting and parameters with which these evaluations are calculated.
Training Data and Scaling Strategies
Let us now explore training data and scaling strategies:
Training Data
- Llama 3’s training dataset, over 15 trillion tokens, is a seven-fold increase from Llama 2.
- The dataset encompasses four times more code and over 5% of high-quality non-English data from 30 languages. Ensuring diverse linguistic representation for multilingual applications.
- To maintain data quality, Meta employs sophisticated data-filtering pipelines, including heuristic filters, NSFW filters, semantic deduplication, and text classifiers.
- Leveraging insights from previous Llama models, these systems enhance the training of Llama 3 by identifying and incorporating quality data.
Scaling Strategies
- Meta focused on maximizing the utility of Llama 3’s dataset by developing detailed scaling laws.
- Optimization of data mix and computational resources facilitated accurate predictions of model performance across various tasks.
- Strategic foresight ensures robust performance across diverse applications like trivia, STEM, coding, and historical knowledge.
- Insights revealed the Chinchilla-optimal amount of training compute for the 8B parameter model, around 200 billion tokens.
- Both the 8B and 70B models continue to improve performance log-linearly with up to 15 trillion tokens.
- Meta achieved over 400 TFLOPS per GPU using 16,000 GPUs simultaneously across custom-built 24,000 GPU clusters.
- Innovations in training infrastructure include automated error detection, system maintenance, and scalable storage solutions.
- These advancements tripled Llama 3’s training efficiency compared to Llama 2, achieving an effective training time of over 95%.
- These improvements set new standards for training large language models, pushing forward the boundaries of AI.
Instruction of Fine-Tuning
- Instruction-tuning enhances functionality of pretrained chat models.
- Process combines supervised fine-tuning, rejection sampling, PPO, and DPO.
- Prompts in SFT and preference rankings in PPO/DPO crucial for model performance.
- Meticulous data curation and quality assurance by human annotators.
- Preference rankings in PPO/DPO improve reasoning and coding task performance.
- Models capable of producing correct answers but may struggle with selection.
- Training with preference rankings enhances decision-making in complex tasks.
Deployment of Llama3
Llama 3 is set for widespread availability across major platforms, including cloud services and model API providers. It features enhanced tokenizer efficiency, reducing token use by up to 15% compared to Llama 2, and incorporates Group Query Attention (GQA) in the 8B model to maintain inference efficiency, even with an additional 1 billion parameters over Llama 2 7B. The open-source ‘Llama Recipes’ offers comprehensive resources for practical deployment and optimization strategies, supporting Llama 3’s versatile application.
Enhancements and Safety Features in Llama 3
Llama 3 is designed to empower developers with tools and flexibility to tailor applications according to specific needs. It enhance the open AI ecosystem. This version introduces new safety and trust tools includingLlama Guard 2, Cybersec Eval 2, and Code Shield, which help filter insecure code during inference. Llama 3 has been developed in partnership with torchtune, a PyTorch-native library that enables efficient, memory-friendly authoring, fine-tuning, and testing of LLMs. This library supports integration with platforms like Hugging Face and Weights & Biases. It also facilitates efficient inference on diverse devices through Executorch.
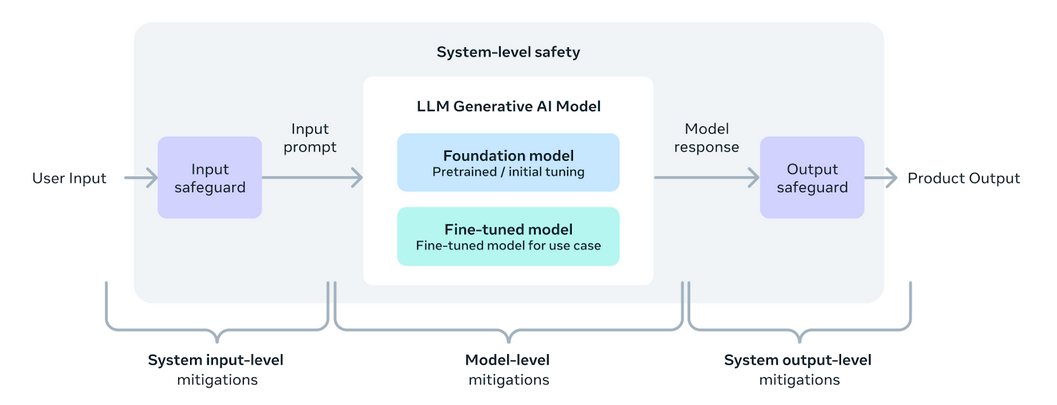
A systemic approach to responsible deployment ensures that Llama 3 models are not only useful but also safe. Instruction fine-tuning is a key component, significantly enhanced by red-teaming efforts that test for safety and robustness against potential misuse in areas such as cyber security. The introduction of Llama Guard 2 incorporates the MLCommons taxonomy to support setting industry standards, while CyberSecEval 2 improves security measures against code misuse.
The adoption of an open approach in developing Llama 3 aims to unite the AI community and address potential risks effectively. Meta’s updated Responsible Use Guide (RUG) outlines best practices for ensuring that all model inputs and outputs adhere to safety standards, complemented by content moderation tools offered by cloud providers. These collective efforts are directed towards fostering a safe, responsible, and innovative use of LLMs in various applications.
Future Developments for Llama 3
The initial release of the Llama 3 models, including the 8B and 70B versions. It is just the start of the planned developments for this series. Meta is currently training even larger models with over 400 billion parameters. These models will promise enhanced capabilities, such as multimodality, multilingual communication, extended context windows, and overall stronger performance. In the coming months, these advanced models will be introduced. Accompanied by a detailed research paper outlining the findings from the training of Llama 3. Meta has shared early snapshots from ongoing training of their largest LLM model, offering insights into future releases.
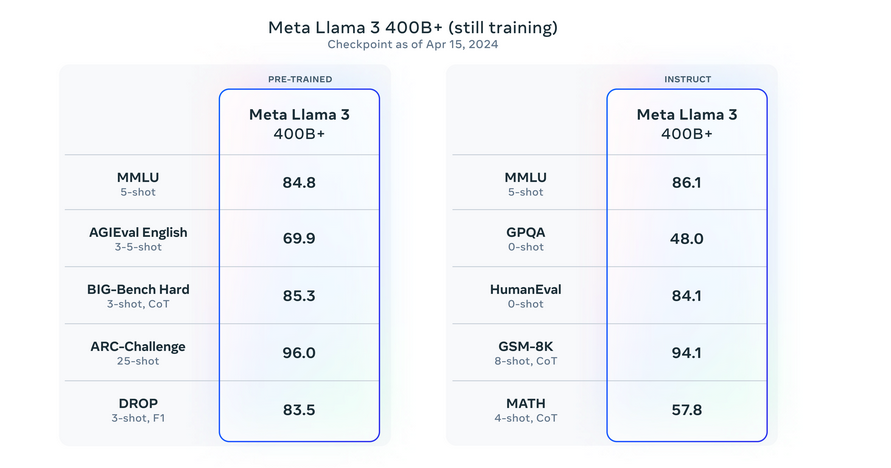
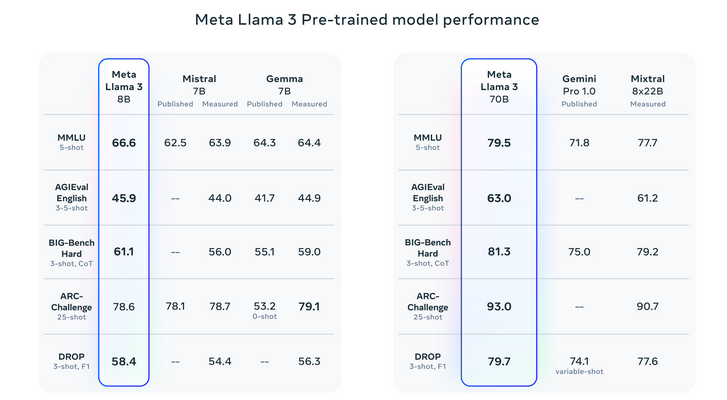
Please see evaluation details for setting and parameters with which these evaluations are calculated.
Impact and Endorsement of Llama 3
- Llama 3 quickly became the fastest model to reach the #1 trending spot on Hugging Face. Achieving this record within just a few hours of its release.
Click here to access the link.
- Following the development of 30,000 models from Llama 1 and 2, Llama 3 is poised to significantly impact the AI ecosystem.
- Major AI and cloud platforms like AWS, Microsoft Azure, Google Cloud, and Hugging Face promptly incorporated Llama 3.
- The model’s presence on Kaggle widens its accessibility, encouraging more hands-on exploration and development within the data science community.
- Available on LlamaIndex, this resource compiled by experts like @ravithejads and @LoganMarkewich provides detailed guidance on utilizing Llama 3 across a range of applications, from simple tasks to complex RAG pipelines. Click here to access link.
Conclusion
Llama 3 sets a new standard in the evolution of Large Language Models. They are enhancing AI capabilities across a range of tasks with its advanced architecture and efficiency. Its comprehensive testing demonstrates superior performance, outshining both predecessors and contemporary models. With robust training strategies and innovative safety measures like Llama Guard 2 and Cybersec Eval 2. Llama 3 underscores Meta’s commitment to responsible AI development. As Llama 3 becomes widely available, it promises to drive significant advancements in AI applications. Also offering developers a powerful tool to explore and expand technological frontiers.





