Introduction
Text summarization is an essential part of natural language processing (NLP) that tries to shorten enormous amounts of text and make more readable summaries while retaining crucial information. Given the expansion of internet material, good summarizing techniques are essential for various applications, such as academic research, content generation, and news summaries. This article will explain how to build a text summarization using the T5-base transformer model on the CNN/DailyMail dataset. Furthermore, it includes pre-processing the data, loading the model, fine-tuning it, and evaluating it.
Learning Objectives
- Understand text summarization’s key concepts and their applications in NLP.
- Learn about the features and architecture of the T5 model.
- Find out how text summarizing tasks are performed with this dataset.
- Discover how to prepare text data for the T5 model.
- Understand how to fine-tune a T5-base model already trained on a dataset.
- Examine ways to assess model performance and produce summaries on unseen data, our test data.
Table of contents
What Approach Are We Taking?
Let us look at our approach for text summarization using T5-base on the CNN/DailyMail dataset.
New Feature
Get Personalized Learning Path! Set your goal and timeline. Get a path—under 2 mins.
T5 Model and Tokenizer
The T5 model and tokenizer are critical components for text summarization. The tokenizer converts text into token sequences, which are numerical representations the model can process. The T5 model then uses these token sequences to generate summaries. In this project, we utilize the t5-base variant of the model, which balances performance and computational efficiency.
Also Read: What are Large Language Models(LLMs)?
Dataset
The CNN/DailyMail dataset is a widely used benchmark for summarization tasks. It contains news articles and corresponding summaries (highlights), making it ideal for training and evaluating summarization models. The dataset is divided into training, validation, and test sets, ensuring robust model evaluation.
Preprocessing
Preprocessing involves tokenizing the articles and summaries to prepare them for input into the T5 model. This step includes truncating text to fit within model constraints and padding sequences to ensure uniform input lengths. The preprocess_function handles these tasks, creating model inputs and corresponding labels.
Training and Evaluation
Fine-tuning the T5 model involves training it on the preprocessed dataset. We set up training arguments to control various aspects of the training process, such as learning rate, batch size, and the number of epochs. The Trainer class from the Transformers library simplifies this process, seamlessly handling model training and evaluation.
Inference
After fine-tuning, the model is evaluated on the test set to assess its performance. We then generate summaries for unseen data using the fine-tuned model. The generate_summary function encodes input articles, generates summaries, and decodes the output to readable text.
What is the T-5 Model?
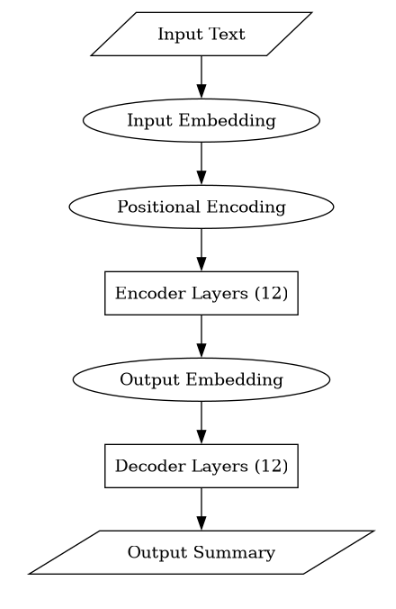
The T5 architecture comprises a stack of transformer encoder-decoder layers, each layer iteratively processing input text to capture contextual information and provide meaningful representations. These interconnected layers allow for efficient information flow and hierarchical representation learning. T5 delivers cutting-edge performance across several NLP benchmarks while preserving a simple and scalable architecture.
T-5 base Architecture
Let us now look at the architecture of the T-5 base.
Comparison with Other T-5 Models
Let us now compare it with other T-5 models.

Code for Text Summarization Using T5-base
Here is the code that will help us implement the text summarization using T5-base on CNN/DailyMail dataset.
Installation and Setup
First, we install the necessary libraries and import the required modules:
Before we begin, ensure to install the following:
!pip install transformers datasets
!pip install accelerate -U
!pip install transformers[torch]
from transformers import T5ForConditionalGeneration, T5Tokenizer, Trainer, TrainingArguments
from datasets import load_datasetLoading the Dataset
We load the CNN/DailyMail dataset:
dataset = load_dataset("cnn_dailymail", "3.0.0")
Model and Tokenizer
We load the pre-trained T5 model and tokenizer:
model_name = "t5-base"
model = T5ForConditionalGeneration.from_pretrained(model_name)
tokenizer = T5Tokenizer.from_pretrained(model_name)Preprocessing the Data
The preprocess_function prepares the data for the model:
def preprocess_function(examples):
inputs = [doc for doc in examples['article']]
model_inputs = tokenizer(inputs, max_length=512, truncation=True, padding="max_length")
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples['highlights'], max_length=128, truncation=True, padding="max_length")
model_inputs["labels"] = labels["input_ids"]
return model_inputs
encoded_dataset = dataset.map(preprocess_function, batched=True)Splitting the Dataset
We split the dataset into training and test sets:
train_dataset = encoded_dataset["train"].shuffle(seed=42).select(range(2000))
test_dataset = encoded_dataset["validation"].shuffle(seed=42).select(range(1000))Training the Model
We set up training arguments and fine-tuned the model:
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=3e-4,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=3,
weight_decay=0.01,
save_total_limit=3,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
trainer.train()Evaluating the Model
We evaluate the fine-tuned model:
trainer.evaluate()Generating Summaries
Finally, we generate summaries for the test set:
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
def generate_summary(example):
input_ids = tokenizer.encode(example["article"], return_tensors="pt", max_length=512, truncation=True).to(device)
output = model.generate(input_ids)
summary = tokenizer.decode(output[0], skip_special_tokens=True)
return {"summary": summary}
summaries = test_dataset.map(generate_summary, batched=False)Displaying Examples
We display a few examples to compare reference and generated summaries (using the unseen test dataset):
for i in range(3):
print("Article:", test_dataset[i]["article"])
print("\nReference Summary:", test_dataset[i]["highlights"])
print("\nGenerated Summary:", summaries[i]["summary"])
print("\n")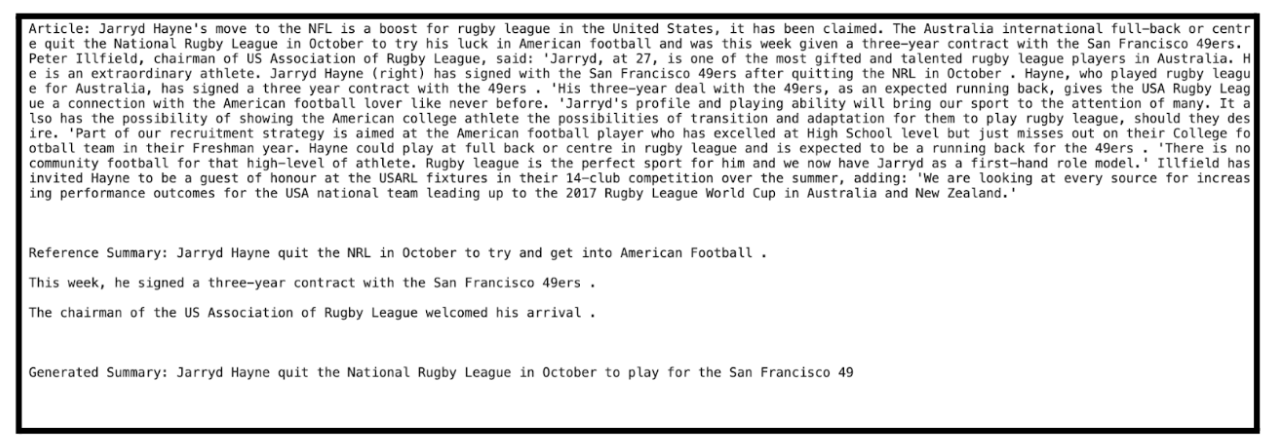
The current text summarization output captures the essence of the original text. However, we can try a few things for the summary to have more depth and coherence. To improve performance, different fine-tuning and hyperparameter tuning procedures can be investigated. This includes fine-tuning with a larger and more diverse dataset and altering learning rates, batch sizes, and the number of training epochs to improve model convergence and generalization.
Furthermore, experimenting with other transformer models and architecture adjustments, such as adding layers or attention heads, could help to improve the summarization process. The text summarising system can create more comprehensive and informative summaries by iteratively refining the model and experimenting with different hyperparameters.
Evaluation of Summary
We’ll use rouge for our evaluation; let’s first ensure the installation by running ‘pip install rouge.’
from rouge import Rouge
def calculate_rouge(reference_list, generated_list):
rouge = Rouge()
scores = rouge.get_scores(generated_list, reference_list)
rouge_1 = sum(score['rouge-1']['f'] for score in scores) / len(scores)
rouge_2 = sum(score['rouge-2']['f'] for score in scores) / len(scores)
rouge_l = sum(score['rouge-l']['f'] for score in scores) / len(scores)
return rouge_1, rouge_2, rouge_l
# Initialize lists to store reference and generated summaries
reference_summaries = [example["highlights"] for example in test_dataset]
generated_summaries = [example["summary"] for example in summaries]
# Calculate ROUGE scores
rouge_1, rouge_2, rouge_l = calculate_rouge(reference_summaries, generated_summaries)
print("Average ROUGE-1:", rouge_1)
print("Average ROUGE-2:", rouge_2)
print("Average ROUGE-L:", rouge_l)
These average ROUGE scores indicate the quality of the generated summaries compared to the reference summaries across your dataset. ROUGE uses both precision and recall to compare model-generated summaries. Here’s what each score means:
ROUGE-1 gauges how closely the generated and reference summaries coincide regarding unigrams or individual words. The generated summaries’ average ROUGE-1 score of 0.2347 shows that, on average, 23.47% of the unigrams match those in the reference summaries.
ROUGE-2 gauges how closely the generated and reference summaries overlap in bigrams or pairs of neighboring words. According to an average ROUGE-2 score of 0.0959, about 9.59% of the bigrams in the generated summaries match those in the reference summaries.
ROUGE-L counts the number of words shared the longest between the reference and generated summaries. According to an average ROUGE-L score of 0.2238, about 22.38% of the longest common subsequence of terms in the generated summaries matches that in the reference summaries.
Conclusion
Therefore, text summarization with the T5-base model on the CNN/DailyMail dataset highlights the efficiency of transformer-based architectures for compressing big texts into short summaries. We can produce high-quality summarization results by taking an organized strategy, beginning with dataset loading and preprocessing and ending with model fine-tuning and evaluation. This method demonstrates the T5 model’s adaptability and the significance of rigorous preprocessing and meticulous model training.
Frequently Asked Questions
Q1. What distinguishes the T5 model from other transformer models in text summarization?
A. The T5 model is unusual because it treats all NLP jobs as text-to-text problems. Translation, summarization, and question answering are all viewed as text creation tasks. This makes it a very adaptable model that can be fine-tuned for multiple tasks using the same architecture, unlike the other transformer models that may require task-specific structures or adjustments.
Q2. How does the Trainer class streamline model training and evaluation?
A. The Trainer class in the Transformers library makes model training and assessment easier by providing a high-level interface for specifying training parameters, handling datasets, and running the training loop. It automates procedures like gradient buildup and checkpoints like saving and evaluation metrics calculation, making it easier to fine-tune and assess transformer models without extensive boilerplate code.
Q3. What are some of the most commonly used evaluation metrics for the summary models?
A. ROUGE (Recall-Oriented Understudy for Gisting assessment) scores are common assessment metrics for summarization models. They show the overlap of n-grams, word sequences, and word pairs between the article and the generated summary. A few common evaluation measures include ROUGE-1, ROUGE-2, and ROUGE-L. These metrics help quantitatively evaluate the model’s generated summaries’ quality and relevancy. Human evaluation can also help determine the summaries’ quality and the model’s performance.
Passionate about technology and innovation, a graduate of Vellore Institute of Technology. Currently working as a Data Science Trainee, focusing on Data Science. Deeply interested in Deep Learning and Generative AI, eager to explore cutting-edge techniques to solve complex problems and create impactful solutions.





