
Introduction
Insurance is a document-heavy industry with numerous terms and conditions, making it challenging for policyholders to find accurate answers to their queries regarding policy details or the claims process. This often leads to higher customer churn due to frustration and misinformation. This article explores how to address this issue using Generative AI by building an end-to-end Retrieval-Augmented Generation (RAG) chatbot for insurance. We call it IVA(Insurance Virtual Agent), which is built over the robust AWS stack.
Learning Outcomes
- Learn how RAG enhances chatbot interactions, especially in document-heavy industries like insurance.
- Gain skills in integrating AWS services such as Bedrock, Lambda, and S3 for efficient document processing and retrieval.
- Explore the LangChain framework to improve the accuracy and flow of chatbot conversations.
- Learn how to deploy a user-friendly chatbot using Streamlit on an EC2 instance.
- Understand the process and limitations of building a prototype RAG chatbot for the insurance sector.
- Discover how advanced AI can significantly improve customer experience and operational efficiency in insurance.
- Building an End-to-End Gen AI RAG chatbot for insurance.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is a RAG Chatbot?
A Retrieval-Augmented Generation chatbot is a sophisticated AI tool that enhances user interactions by integrating document retrieval with natural language generation. Instead of solely generating responses from a pre-trained model, an RAG chatbot retrieves relevant information from a database or document set. It then uses this information to craft detailed and accurate answers. This dual approach ensures that users receive highly contextual and precise information tailored to their queries.
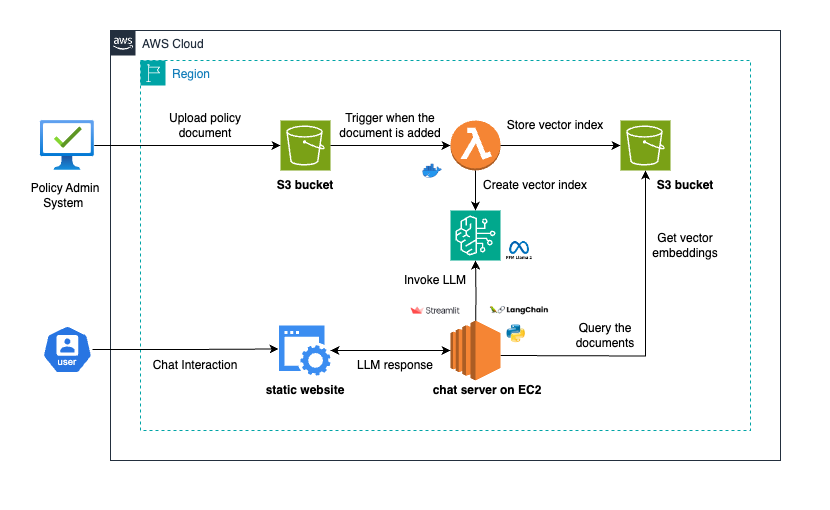
Solution Overview
- When a policy is issued, the policy document is stored in an S3 bucket.
- An S3 notification triggers a Lambda function upon document upload. This function tokenizes the document, generates vector embeddings via AWS Bedrock, and creates an index using FAISS, which is then saved back to S3.
- When a user queries the chatbot, it retrieves the relevant vector index based on the policy number. The chatbot then uses this index and the user’s query, processed through a Large Language Model (LLM) with AWS Bedrock and LangChain, to generate an accurate response.
Technical Overview
We can divide the solution into three modules to develop and explain it agilely rather than handle it all simultaneously.
Module1: Spin Up Required AWS Resources
This module will focus on setting up the necessary AWS infrastructure. We’ll use TypeScript to create the stack and develop a Lambda function using Python. To get started, clone the repository and review the stack. However, suppose you’re new to this process and want to gain a deeper understanding. In that case, I highly recommend initializing a blank TypeScript CDK project and adding the required resources step-by-step.
S3 Bucket for Static Website
Create an S3 bucket to host the static website, configure public read access, and deploy the website content. We will use this static page as a landing page for the insurance company and access the chatbot.
const siteBucket = new s3.Bucket(this, 'MyStaticSiteBucket', {
bucketName: "secure-insurance-website",
websiteIndexDocument: 'index.html',
autoDeleteObjects: true,
removalPolicy: cdk.RemovalPolicy.DESTROY,
blockPublicAccess: { /* ... */ }
});
siteBucket.addToResourcePolicy(new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ['s3:GetObject'],
principals: [new iam.AnyPrincipal()],
resources: [siteBucket.arnForObjects('*')],
}));
new s3deploy.BucketDeployment(this, 'DeployStaticSite', {
sources: [s3deploy.Source.asset('./website')],
destinationBucket: siteBucket,
});#import csvS3 Bucket for Document Storage
Create an S3 bucket to store policy documents and the vectors.
const sourceBucket = new s3.Bucket(this, 'RagSourceBucket', {
bucketName: 'rag-bot-source',
removalPolicy: cdk.RemovalPolicy.DESTROY,
});#import csvIAM Role for Lambda
Create an IAM role with permissions for S3 and AWS Bedrock operations
const lambdaRole = new iam.Role(this, 'LambdaRole', {
assumedBy: new iam.ServicePrincipal('lambda.amazonaws.com'),
});
lambdaRole.addToPolicy(new iam.PolicyStatement({
actions: ['s3:GetObject', 's3:PutObject'],
resources: [sourceBucket.bucketArn + '/*'],
}));
lambdaRole.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole'));
lambdaRole.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('AmazonBedrockFullAccess'));#import csvDocker-Based Lambda Function
Define a Lambda function using a Docker image that processes documents:
const dockerFunc = new lambda.DockerImageFunction(this, "DockerFunc", {
code: lambda.DockerImageCode.fromImageAsset("./image"),
memorySize: 1024,
timeout: cdk.Duration.seconds(20),
architecture: lambda.Architecture.X86_64,
role: lambdaRole,
});
sourceBucket.addEventNotification(s3.EventType.OBJECT_CREATED, new s3n.LambdaDestination(dockerFunc), {
prefix: 'docs/',
});#import csvDeploy the resources
Once the development is completed, the stack can be deployed to AWS using the below commands. ( Assuming the CDK is already configured)
npm install -g aws-cdk
cdk bootstrap aws://YOUR-AWS-ACCOUNT-ID/YOUR-AWS-REGION
cdk deploy#import csvPlease note - we will have to update the chat server URL in the index.html file once we deploy the chatbot to AWS (Module 3).
Before proceeding with Module 2, it’s crucial to note that access to the required foundational model in the AWS Bedrock console must be requested. Without this access, the chatbot won’t be able to utilize the bedrock models. Therefore, ensure that the necessary permissions are granted beforehand to ensure seamless integration with AWS Bedrock services.
Module2: Lambda Function for Generating the Vector Embeddings
This Lambda function plays a crucial role in generating vector embeddings for policy documents, a fundamental step in enabling the RAG chatbot to provide accurate responses. Let’s break down its functionality:
Configuration and Initialization
Before diving into the code, we configure connections to AWS services and initialize the Titan Embeddings Model, essential for generating vector embeddings:
bedrock = boto3.client(service_name="bedrock-runtime")
bedrock_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1", client=bedrock)
s3 = boto3.client("s3")#import csvHandler Function
The handler function is the entry point for the Lambda execution. Here, we extract the necessary information from the S3 event trigger and prepare for document processing:
def handler(event, context):
key = event['Records'][0]['s3']['object']['key']
key = key.replace('+', ' ')
policy_number = key.split('_')[-1].split('.')[0]
file_name_full = key.split("/")[-1]
s3.download_file(BUCKET_NAME, key, f"/tmp/{file_name_full}")#import csvDocument Processing
Once the document is downloaded, we proceed with document processing, which involves loading the policy document and splitting it into smaller, manageable chunks.
loader = PyPDFLoader(f"/tmp/{file_name_full}")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(docs)#import csvVector Embeddings Generation
With the documents split, we utilize the Titan Embeddings Model to generate vector embeddings for each document chunk:
vectorstore_faiss = FAISS.from_documents(docs, bedrock_embeddings)
file_path = f"/tmp/"
Path(file_path).mkdir(parents=True, exist_ok=True)
file_name = "faiss_index"
vectorstore_faiss.save_local(index_name=file_name, folder_path=file_path)#import csvSave and Upload
Finally, we save the generated vector embeddings locally and upload them to the specified S3 bucket for future retrieval:
s3_vector_faiss_key = f'vectors/policydoc/{policy_number}/policydoc_faiss.faiss'
s3.upload_file(Filename=f"{file_path}/{file_name}.faiss", Bucket=BUCKET_NAME, Key=s3_vector_faiss_key)#import csvModule3: Developing the Chatbot
Let’s dissect the key components that orchestrate this chatbot’s functionality:
Crafting Prompts and Integrating the LLM
The template variable establishes a structured format for feeding context and user queries to the LLM. This approach ensures the LLM remains focused on pertinent information while generating responses.
template = """Utilize the following contextual fragments to address the question at hand. Adhere to these guidelines:
1. If you're unsure of the answer, refrain from fabricating one.
2. Upon finding the answer, deliver it in a comprehensive manner, omitting references.
{context}
Question: {input}
Helpful Answer:"""#import csvget_llama2_llm function: This function establishes a connection to Bedrock, a managed LLM service offered by Amazon Web Services (AWS). It pinpoints the “meta.llama2-13b-chat-v1” model, renowned for its conversational capabilities.
def get_llama2_llm():
llm = Bedrock(model_id="meta.llama2-13b-chat-v1", client=bedrock,
model_kwargs={'max_gen_len': 512})
return llm
llm = get_llama2_llm()#import csvInformation Retrieval via FAISS
download_vectors function: This function retrieves pre-computed document vectors associated with a specific policy number from an S3 bucket (cloud storage). These vectors facilitate efficient document retrieval based on semantic similarity.
def download_vectors(policy_number):
s3_vector_faiss_key = 'vectors/policydoc/' + policy_number + '/' + 'policydoc_faiss.faiss'
s3_vector_pkl_key = 'vectors/policydoc/' + policy_number + '/' + 'policydoc_pkl.pkl'
Path(file_path).mkdir(parents=True, exist_ok=True)
s3.download_file(Bucket=BUCKET_NAME, Key=s3_vector_faiss_key, Filename=f"{file_path}/my_faiss.faiss")
s3.download_file(Bucket=BUCKET_NAME, Key=s3_vector_pkl_key, Filename=f"{file_path}/my_faiss.pkl")#import csvload_faiss_index function: This function leverages the FAISS library (a library for efficient similarity search) to load the downloaded vectors and construct an index. This index empowers the retrieval of relevant policy documents swiftly when a user poses a question.
def load_faiss_index():
faiss_index = FAISS.load_local(index_name="my_faiss", folder_path=file_path, embeddings=bedrock_embeddings, allow_dangerous_deserialization=True)
retriever = faiss_index.as_retriever()
document_chain = create_stuff_documents_chain(llm, prompt)
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
chain = create_retrieval_chain(retriever_chain, document_chain)
return chain#import csvConstructing the Retrieval-Augmented Chain
Now let’s understand the workings of the retreival augmented chain in detail. It consists of three parts
Document Processing Chain: This line initializes a chain dedicated to processing documents. The function create_stuff_documents_chain likely handles tasks such as tokenization, text generation, and other document-related operations.
document_chain = create_stuff_documents_chain(llm, prompt)#import csvRetrieval Chain: Here, a retrieval chain is created to fetch relevant documents. The function create_history_aware_retriever incorporates historical data to enhance the retrieval process.
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)#import csvCombining Chains: This line combines the retrieval and document processing chains into a single retrieval chain. The function create_retrieval_chain orchestrates this combination, ensuring seamless integration of retrieval and document processing tasks. The combined chain aims to provide accurate and contextually relevant responses based on the input prompt and historical context.
chain = create_retrieval_chain(retriever_chain, document_chain)Deploying the Chatbot in AWS
Let us now explore deploying the chatbot in AWS.
Step1: Initializing EC2 Instance
Launch an EC2 instance with Amazon Linux and configure security groups to permit traffic on port 8501.
Step2: Configure IAM Role
Configure an IAM Role with access to the S3 bucket and AWS Bedrock and attach it to the EC2 instance.
Step3: Connect to EC2 Server
Now you can connect to the EC2 server from the console and run the following scripts to get the application running.
#!/bin/bash
# Update package index
sudo yum update -y
# Install Git
sudo yum install git -y
# Install Docker
sudo yum install docker -y
# Start Docker service
sudo service docker start
# Enable Docker to start on boot
sudo chkconfig docker on
# Clone Streamlit app repository
git clone https://github.com/arpan65/Insurance-RAG-Chatbot.git
cd Insurance-RAG-Chatbot/ChatUI/ChatApp
# Build Docker image
sudo docker build -t chatApp .
# Run Docker container
sudo docker run -d -p 8501:8501 chatApp
echo "Streamlit app deployed. You can access it at http://$(curl -s http://169.254.169.254/latest/meta-data/public-ipv4):8501"#import csvStep4: Configure Nginx for HTTPS (optional)
If you need to secure your application with HTTPS, set up Nginx as a reverse proxy and configure SSL certificates. Being a POC application, we will skip this step in our context.
Once the chatbot is running, copy the public URL and update it in the index.html file under the website before deploying it to the AWS.
<div id="chat-widget" class="chat-widget">
<button id="chat-toggle-btn" class="chat-toggle-btn">Ask IVA</button>
<div id="chat-window" class="chat-window">
<iframe src="{your_bot_url}" frameborder="0" width="100%" height="100%"></iframe>
</div>
</div>Testing the Workflow
After completing the development and deployment of all required modules, you can test the chatbot using the following steps:
Step1: Access S3 in AWS Console
Navigate to the rag-source-bucket in the AWS S3 console.
Step2: Upload Sample Policy Document
- Create a folder named docs if not already present.
- Upload the sample policy document provided in the repository to this folder.
Step3: Trigger Lambda Function
- The Lambda function should be triggered automatically upon uploading the document.
- It will create a new folder named vectors inside which policy-specific vector indexes will be stored.
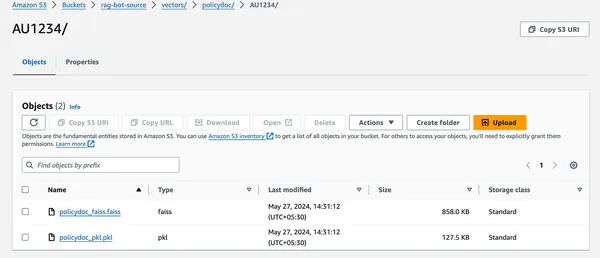
Step4: Access Website Bucket
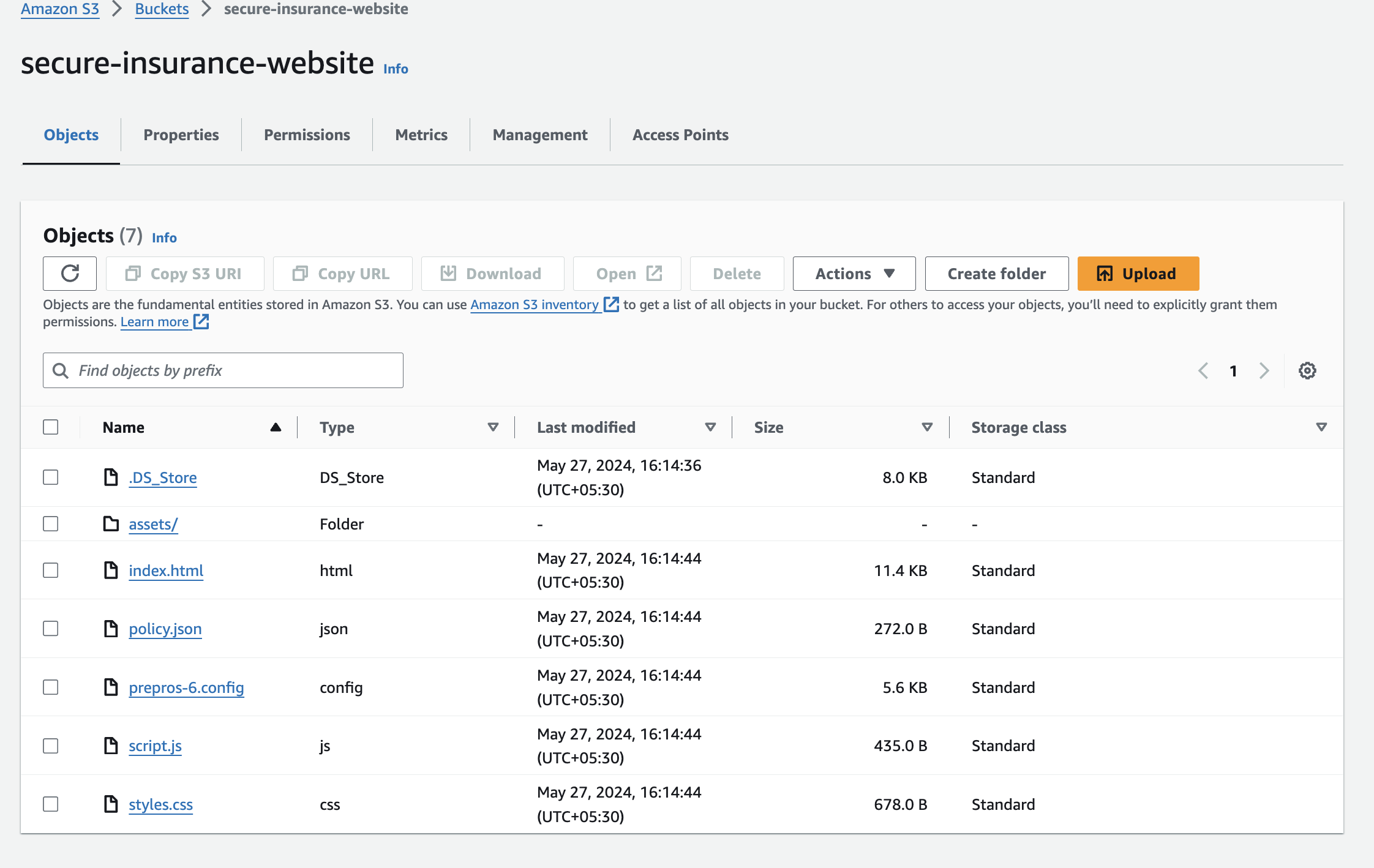
- Navigate to the secure-insurance-website bucket in the AWS S3 console.
- Browse the index.html object, which should open the website in a new window.
Step5: Access the Chatbot
- You can now access the chatbot from this landing page.
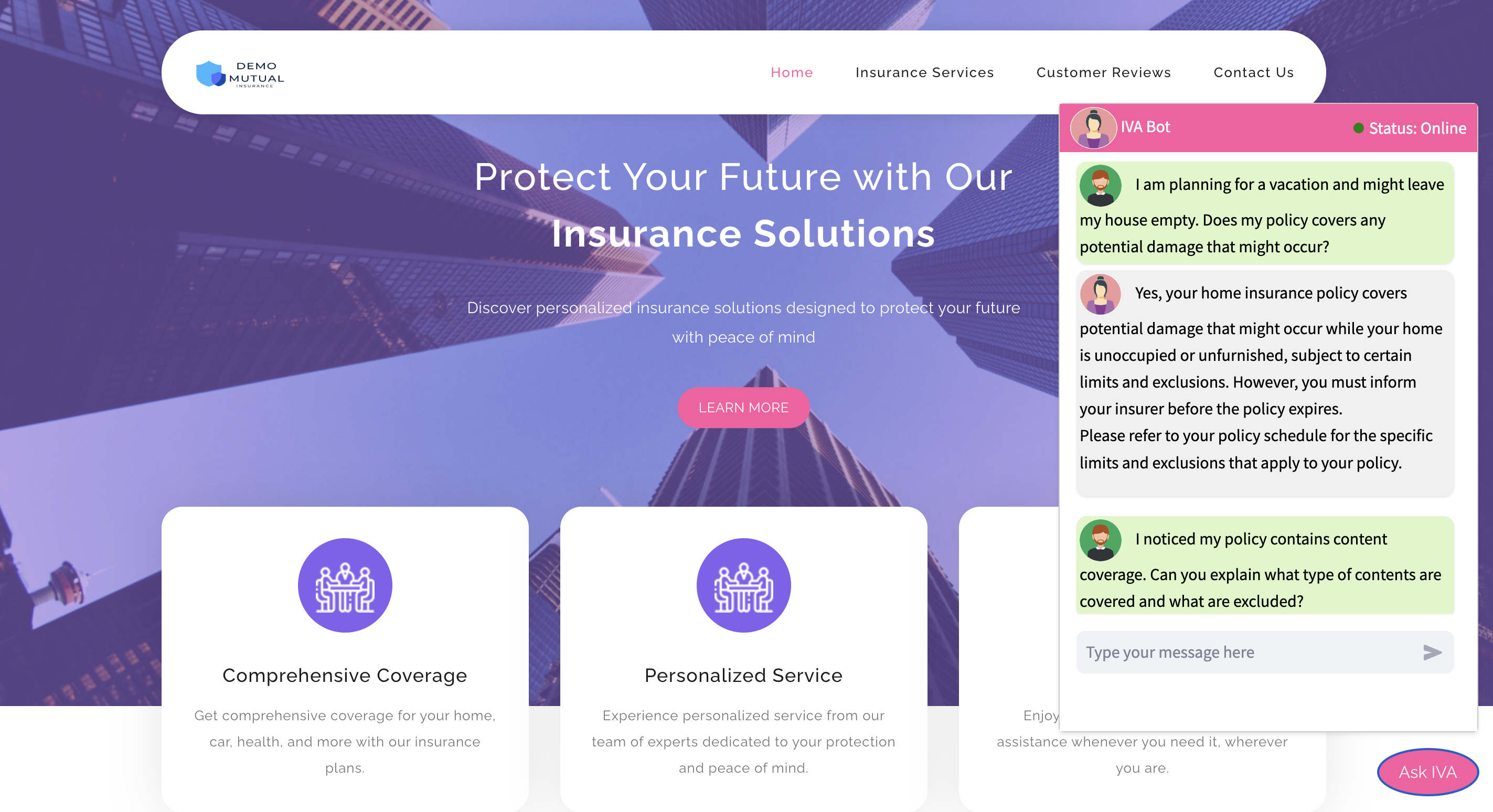
Please Note: Ensure mixed-mode hosting is allowed in the browser to test the chatbot. Otherwise, the browser may not allow the HTTP URL to run from the website.
By following these steps, you can effectively test the functionality of the chatbot and ensure that it retrieves and processes policy documents accurately.
Watch the demo here:
Conclusion
IVA (Insurance Virtual Agent) is a prototype dedicated to showcasing Retrieval-Augmented-Generation (RAG) capabilities within the insurance sector. By leveraging technologies such as AWS Bedrock, Lambda, and Streamlit, IVA efficiently retrieves and generates detailed responses based on policy documents. Although it is not a comprehensive support chatbot, IVA exemplifies how AI can significantly enhance customer experience and operational efficiency. Continued innovation could further streamline processes and provide personalized assistance to policyholders, marking a significant step forward in optimizing insurance services.
Key Takeaways
- Gained valuable insights into leveraging advanced AI and cloud technologies to enhance user experience in the insurance sector.
- Utilized the LangChain framework to streamline conversation flow and document retrieval, highlighting the potential of RAG technology.
- Efficiently integrated AWS services like Bedrock, Lambda, and S3 for document processing and retrieval.
- Demonstrated the practical applications of AI in real-world scenarios by deploying the chatbot on an EC2 instance with a user-friendly Streamlit interface.
- Highlighted the transformative potential of AI in streamlining insurance services and improving customer interactions.
- Recognized that IVA, while a prototype, showcases the capabilities of RAG technology in the insurance sector.
Important Links
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
Q1: What is a RAG Chatbot for Insurance?
A: A RAG Chatbot for Insurance uses Retrieval-Augmented Generation technology to provide accurate and detailed responses to policyholder queries by retrieving relevant information from insurance documents.
Q2. Which AWS services are integrated into IVA, and what are their roles?
A. IVA integrates AWS services such as Bedrock for generating embeddings, Lambda for executing code in response to events, and S3 for storing and retrieving documents. These services work together to process documents efficiently and retrieve relevant information in response to user queries.
Q3. How does LangChain improve the chatbot’s functionality?
A. LangChain is used to manage conversation flow and document retrieval within IVA. By leveraging LangChain, the chatbot can more accurately interpret user queries, retrieve pertinent information, and generate coherent and contextually appropriate responses.
Q4. What are the deployment requirements for running IVA?
A. IVA is deployed on an Amazon EC2 instance with a user-friendly Streamlit interface. The deployment process involves setting up the EC2 instance, configuring security groups, and running a Docker container that hosts the Streamlit app, making the chatbot accessible to users.
Q5. Is IVA a full-fledged support chatbot?
A. No, IVA is a prototype focused solely on demonstrating the capabilities of Retrieval-Augmented Generation (RAG) technology within the insurance sector. While it highlights the potential of AI to streamline customer service, it is not designed to be a comprehensive support chatbot.
I am a Software Engineer with over 6.5 years of experience developing scalable solutions for the insurance sector, specializing in cloud technologies and insurance tech products. I also have intermediate-level experience in analytics.
As an AWS and Duck Creek certified professional, I possess extensive expertise in a wide range of AWS services, including Lambda, API Gateway, CloudFormation, DynamoDB, Step Functions, EventBridge, SageMaker, Bedrock, Glue, SQS, SNS, and Kinesis. My background enables me to design and implement robust, efficient, and scalable systems tailored to meet the complex needs of the insurance industry.
Free Courses





