Introduction
In the fast-evolving world of AI, it’s crucial to keep track of your API costs, especially when building LLM-based applications such as Retrieval-Augmented Generation (RAG) pipelines in production. Experimenting with different LLMs to get the best results often involves making numerous API requests to the server, each request incurring a cost. Understanding and tracking where every dollar is spent is vital to managing these expenses effectively.
In this article, we will implement LLM observability with RAG using just 10-12 lines of code. Observability helps us monitor key metrics such as latency, the number of tokens, prompts, and the cost per request.
Learning Objectives
- Understand the Concept of LLM Observability and how it helps in monitoring and optimizing the performance and cost of LLMs in applications.
- Explore different key metrics to track and monitor such as token utilisation, latency, cost per request, and prompt experimentations.
- How to build Retrieval Augmented Generation pipeline along with Observability.
- How to use BeyondLLM to further evaluate the RAG pipeline using RAG triad metrics i.e., Context relevancy, Answer relevancy and Groundedness.
- Wisely adjusting chunk size and top-K values to reduce costs, use efficient number of tokens and improve latency.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is LLM Observability?
Think of LLM Observability just like you monitor your car’s performance or track your daily expenses, LLM Observability involves watching and understanding every detail of how these AI models operate. It helps you track usage by counting number of “tokens”—units of processing that each request to the model uses. This helps you stay within budget and avoid unexpected expenses.
Additionally, it monitors performance by logging how long each request takes, ensuring that no part of the process is unnecessarily slow. It provides valuable insights by showing patterns and trends, helping you identify inefficiencies and areas where you might be overspending. LLM Observability is a best practice to follow while building applications on production, as this can automate the action pipeline to send alerts if something goes wrong.
What is Retrieval Augmented Generation?
Retrieval Augmented Generation (RAG) is a concept where relevant document chunks are returned to a Large Language Model (LLM) as in-context learning (i.e., few-shot prompting) based on a user’s query. Simply put, RAG consists of two parts: the retriever and the generator.
When a user enters a query, it is first converted into embeddings. These query embeddings are then searched in a vector database by the retriever to return the most relevant or semantically similar documents. These documents are passed as in-context learning to the generator model, allowing the LLM to generate a reasonable response. RAG reduces the likelihood of hallucinations and provides domain-specific responses based on the given knowledge base.
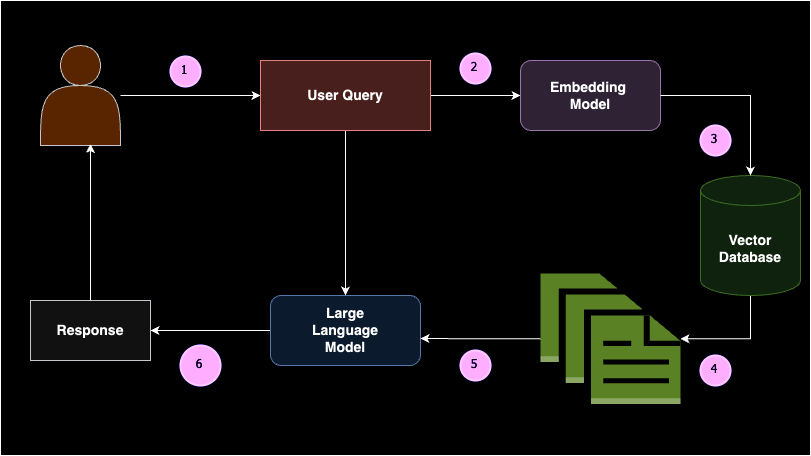
Building a RAG pipeline involves several key components: data source, text splitters, vector database, embedding models, and large language models. RAG is widely implemented when you need to connect a large language model to a custom data source. For example, if you want to create your own ChatGPT for your class notes, RAG would be the ideal solution. This approach ensures that the model can provide accurate and relevant responses based on your specific data, making it highly useful for personalized applications.
Why use Observability with RAG?
Building RAG application depends on different use cases. Each use case depends its own custom prompts for in-context learning. Custom prompts includes combination of both system prompt and user prompt, system prompt is the rules or instructions based on which LLM needs to behave and user prompt is the augmented prompt to the user query. Writing a good prompt is first attempt is a very rare case.
Using observability with Retrieval Augmented Generation (RAG) is crucial for ensuring efficient and cost-effective operations. Observability helps you monitor and understand every detail of your RAG pipeline, from tracking token usage to measuring latency, prompts and response times. By keeping a close watch on these metrics, you can identify and address inefficiencies, avoid unexpected expenses, and optimize your system’s performance. Essentially, observability provides the insights needed to fine-tune your RAG setup, ensuring it runs smoothly, stays within budget, and consistently delivers accurate, domain-specific responses.
Let’s take a practical example and understand why we need to use observability while using RAG. Suppose you built the app and now its on production
Chat with YouTube: Observability with RAG Implementation
Let us now look into the steps of Observability with RAG Implementation.
Step1: Installation
Before we proceed with the code implementation, you need to install a few libraries. These libraries include Beyond LLM, OpenAI, Phoenix, and YouTube Transcript API. Beyond LLM is a library that helps you build advanced RAG applications efficiently, incorporating observability, fine-tuning, embeddings, and model evaluation.
pip install beyondllm
pip install openai
pip install arize-phoenix[evals]
pip install youtube_transcript_api llama-index-readers-youtube-transcriptStep2: Setup OpenAI API Key
Set up the environment variable for the OpenAI API key, which is necessary to authenticate and access OpenAI’s services such as LLM and embedding.
import os, getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass("API:")
# import required libraries
from beyondllm import source,retrieve,generator, llms, embeddings
from beyondllm.observe import ObserverStep3: Setup Observability
Enabling observability should be the first step in your code to ensure all subsequent operations are tracked.
Observe = Observer()
Observe.run()Step4: Define LLM and Embedding
Since the OpenAI API key is already stored in environment variable, you can now define the LLM and embedding model to retrieve the document and generate the response accordingly.
llm=llms.ChatOpenAIModel()
embed_model = embeddings.OpenAIEmbeddings()Step5: RAG Part-1-Retriever
BeyondLLM is a native framework for Data Scientists. To ingest data, you can define the data source inside the `fit` function. Based on the data source, you can specify the `dtype` in our case, it’s YouTube. Additionally, we can chunk our data to avoid the context length issues of the model and return only the specific chunk. Chunk overlap defines the number of tokens that need to be repeated in the consecutive chunk.
The Auto retriever in BeyondLLM helps retrieve the relevant k number of documents based on the type. There are various retriever types such as Hybrid, Re-ranking, Flag embedding re-rankers, and more. In this use case, we will use a normal retriever, i.e., an in-memory retriever.
data = source.fit("https://www.youtube.com/watch?v=IhawEdplzkI",
dtype="youtube",
chunk_size=512,
chunk_overlap=50)
retriever = retrieve.auto_retriever(data,
embed_model,
type="normal",
top_k=4)
Step6: RAG Part-2-Generator
The generator model combines the user query and the relevant documents from the retriever class and passes them to the Large Language Model. To facilitate this, BeyondLLM supports a generator module that chains up this pipeline, allowing for further evaluation of the pipeline on the RAG triad.
user_query = "summarize simple task execution worflow?"
pipeline = generator.Generate(question=user_query,retriever=retriever,llm=llm)
print(pipeline.call())Output
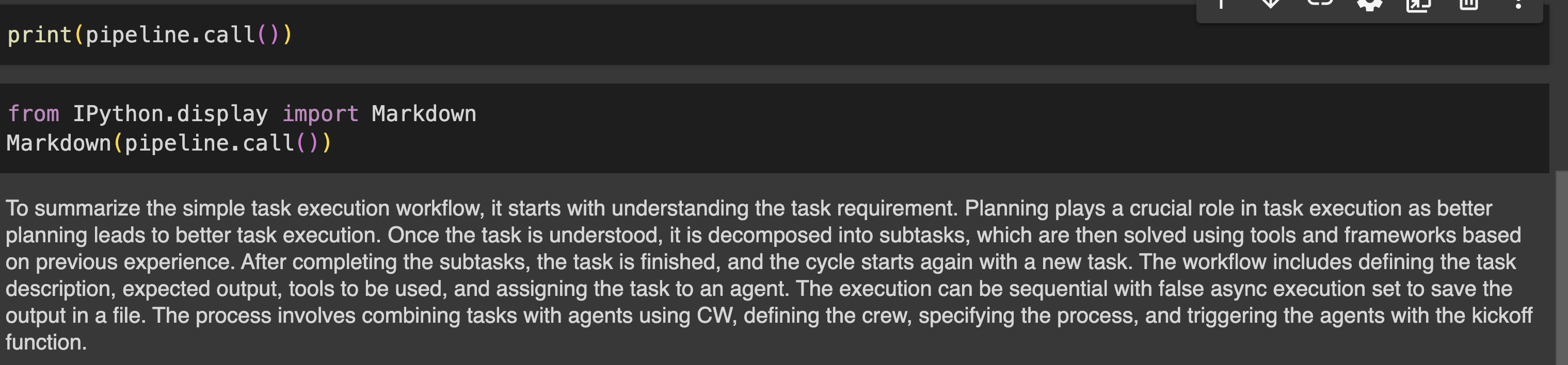
Step7: Evaluate the Pipeline
Evaluation of RAG pipeline can be performed using RAG triad metrics that includes Context relevancy, Answer relevancy and Groundness.
- Context relevancy : Measures the relevance of the chunks retrieved by the auto_retriever in relation to the user’s query. Determines the efficiency of the auto_retriever in fetching contextually relevant information, ensuring that the foundation for generating responses is solid.
- Answer relevancy : Evaluates the relevance of the LLM’s response to the user query.
- Groundedness : It determines how well the language model’s responses are grounded in the information retrieved by the auto_retriever, aiming to identify and eliminate any hallucinated content. This ensures that the outputs are based on accurate and factual information.
print(pipeline.get_rag_triad_evals())
#or
# run it individually
print(pipeline.get_context_relevancy()) # context relevancy
print(pipeline.get_answer_relevancy()) # answer relevancy
print(pipeline.get_groundedness()) # groundednessOutput:

Phoenix Dashboard: LLM Observability Analysis
Figure-1 denotes the main dashboard of the Phoenix, once you run the Observer.run(), it returns two links:
- Localhost: http://127.0.0.1:6006/
- If localhost is not running, you can choose, an alternative link to view the Phoenix app in your browser.
Since we are using two services from OpenAI, it will display both LLM and embeddings under the provider. It will show the number of tokens each provider utilized, along with the latency, start time, input given to the API request, and the output generated from the LLM.
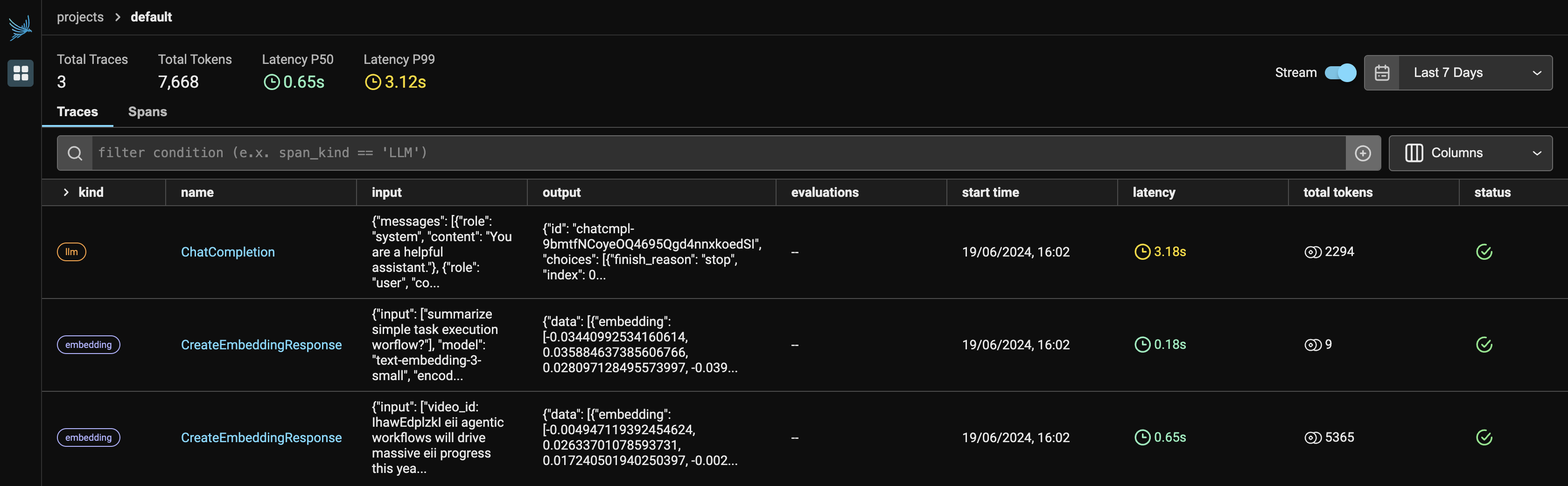
Figure 2 shows the trace details of the LLM. It includes latency, which is 1.53 seconds, the number of tokens, which is 2212, and information such as the system prompt, user prompt, and response.
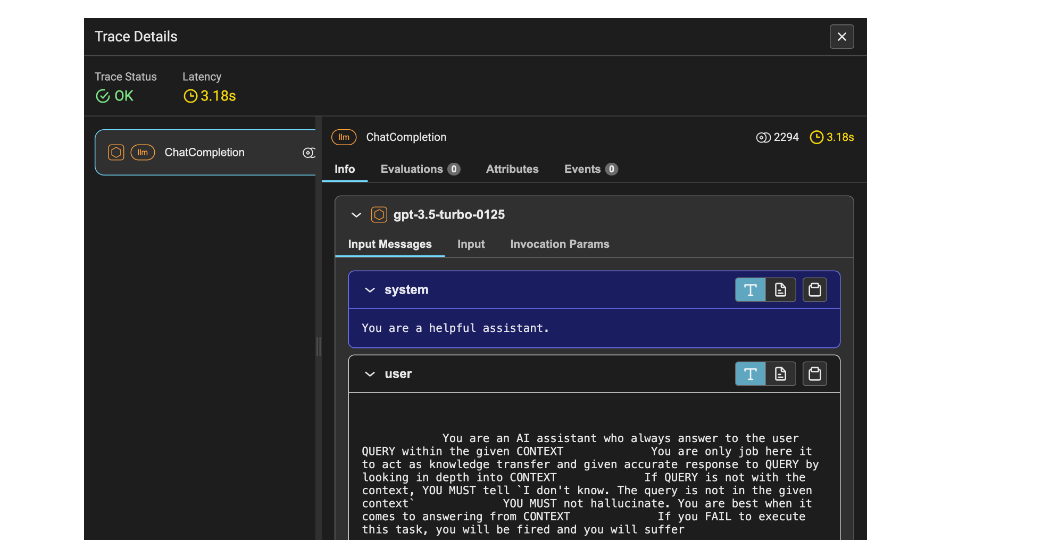
Figure-3 shows the trace details of the Embeddings for the user query asked, along with other metrics similar to Figure-2. Instead of prompting, you see the input query converted into embeddings.
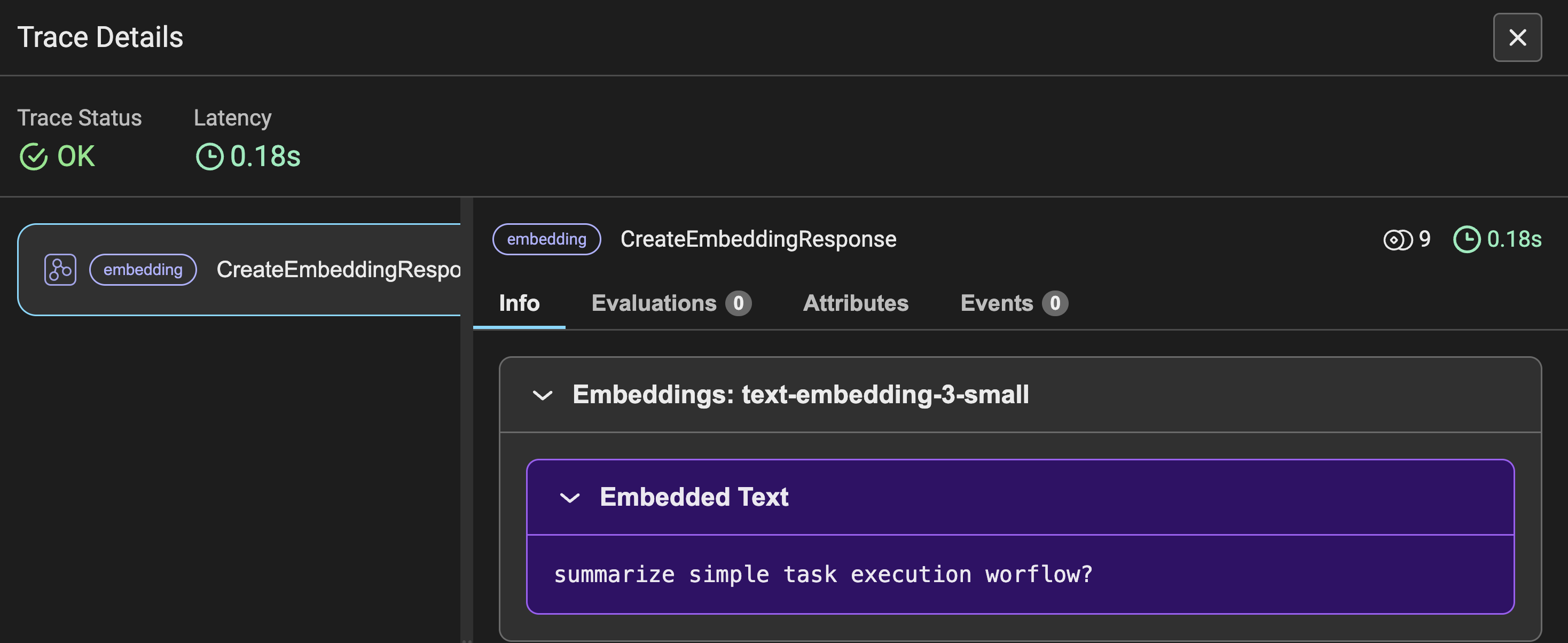
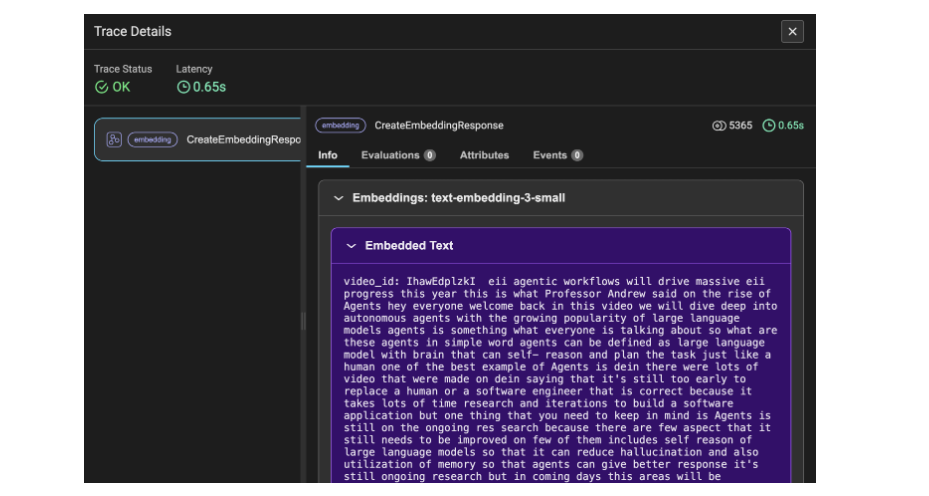
Figure 4 shows the trace details of the embeddings for the YouTube transcript data. Here, the data is converted into chunks and then into embeddings, which is why the utilized tokens amount to 5365. This trace detail denotes the transcript video data as the information.
Conclusion
To summarize, you have successfully built a Retrieval Augmented Generation (RAG) pipeline along with advanced concepts such as evaluation and observability. With this approach, you can further use this learning to automate and write scripts for alerts if something goes wrong, or use the requests to trace the logging details to get better insights into how the application is performing, and, of course, maintain the cost within the budget. Additionally, incorporating observability helps you optimize model usage and ensures efficient, cost-effective performance for your specific needs.
Key Takeaways
- Understanding the need of Observability while building LLM based application such as Retrieval Augmented generation.
- Key metrics to trace such as Number of tokens, Latency, prompts, and costs for each API request made.
- Implementation of RAG and triad evaluations using BeyondLLM with minimal lines of code.
- Monitoring and tracking LLM observability using BeyondLLM and Phoenix.
- Few snapshots insights on trace details of LLM and embeddings that needs to be automated to improve the performance of application.
Frequently Asked Questions
Q1. Which models can be observed using Phoenix?
A. When it comes to observability, it is useful to track closed-source models like GPT, Gemini, Claude, and others. Phoenix supports direct integrations with Langchain, LLamaIndex, and the DSPY framework, as well as independent LLM providers such as OpenAI, Bedrock, and others.
Q2. How do we evaluate RAG using Open Source LLMs?
A. BeyondLLM supports evaluating the Retrieval Augmented Generation (RAG) pipeline using the LLMs it supports. You can easily evaluate RAG on BeyondLLM with Ollama and HuggingFace models. The evaluation metrics include context relevancy, answer relevancy, groundedness, and ground truth.
Q3. How can observability help save OpenAI API costs?
A. OpenAI API cost is spent on the number of tokens you utilise. This is where observability can help you keep monitoring and trace of Tokens per request, Overall tokens, Costs per request, latency. This metrics really help to trigger a function to alert the cost to the user.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Scientist at AI Planet || YouTube- AIWithTarun || Google Developer Expert in ML || Won 5 AI hackathons || Co-organizer of TensorFlow User Group Bangalore || Pie & AI Ambassador at DeepLearningAI





