Introduction
In the ever-evolving landscape of data processing, extracting structured information from PDFs remains a formidable challenge, even in 2024. While numerous models excel at question-answering tasks, the real complexity lies in transforming unstructured PDF content into organized, actionable data. Let’s explore this challenge and discover how Indexify and PaddleOCR can be the tools we need for seamlessly extracting text from PDFs.
Spoiler: We actually did solve it! Hit cmd/ctrl+F and search for the term spotlight to check out how!
Table of contents
PDF Extraction Challenge
PDF extraction is crucial across various domains. Let’s look at some common use cases:
- Invoices and Receipts: These documents vary widely in format, containing complex layouts, tables, and sometimes handwritten notes. Accurate parsing is essential for automating accounting processes.
- Academic Papers and Theses: These often include a mix of text, graphs, tables, and formulas. The challenge lies in correctly converting not just text, but also mathematical equations and scientific notation.
- Legal Documents: Contracts and court filings are typically dense with formatting nuances. Maintaining the integrity of the original formatting while extracting text is crucial for legal reviews and compliance.
- Historical Archives and Manuscripts: These present unique challenges due to paper degradation, variations in historical handwriting, and archaic language. OCR technology must handle these variations for effective research and archival purposes.
- Medical Records and Prescriptions: These often contain critical handwritten notes and medical terminology. Accurate capture of this information is vital for patient care and medical research.
Enter Indexify: A Real-Time Data Extraction Engine
Certainly! Here is the revised text in active voice:
Indexify is an open-source data framework that tackles the complexities of unstructured data extraction from any source, as shown in Fig 1. Its architecture supports:
- Ingestion of millions of unstructured data points.
- Real-time extraction and indexing pipelines.
- Horizontal scaling to accommodate growing data volumes.
- Quick extraction times (within seconds of ingestion).
- Flexible deployment across various hardware platforms (GPUs, TPUs, and CPUs).

If you are interested in reading more about indexify and how you can set it up for extraction, skim through our 2 minute ‘getting-started’ guide.
Indexify Extractors: The Building Blocks

At the heart of Indexify are its Extractors (as shown in Fig 2) – compute functions that transform unstructured data or extract information from it. These Extractors can be implemented to run on any hardware, with a single Indexify deployment supporting tens of thousands of Extractors in a cluster.
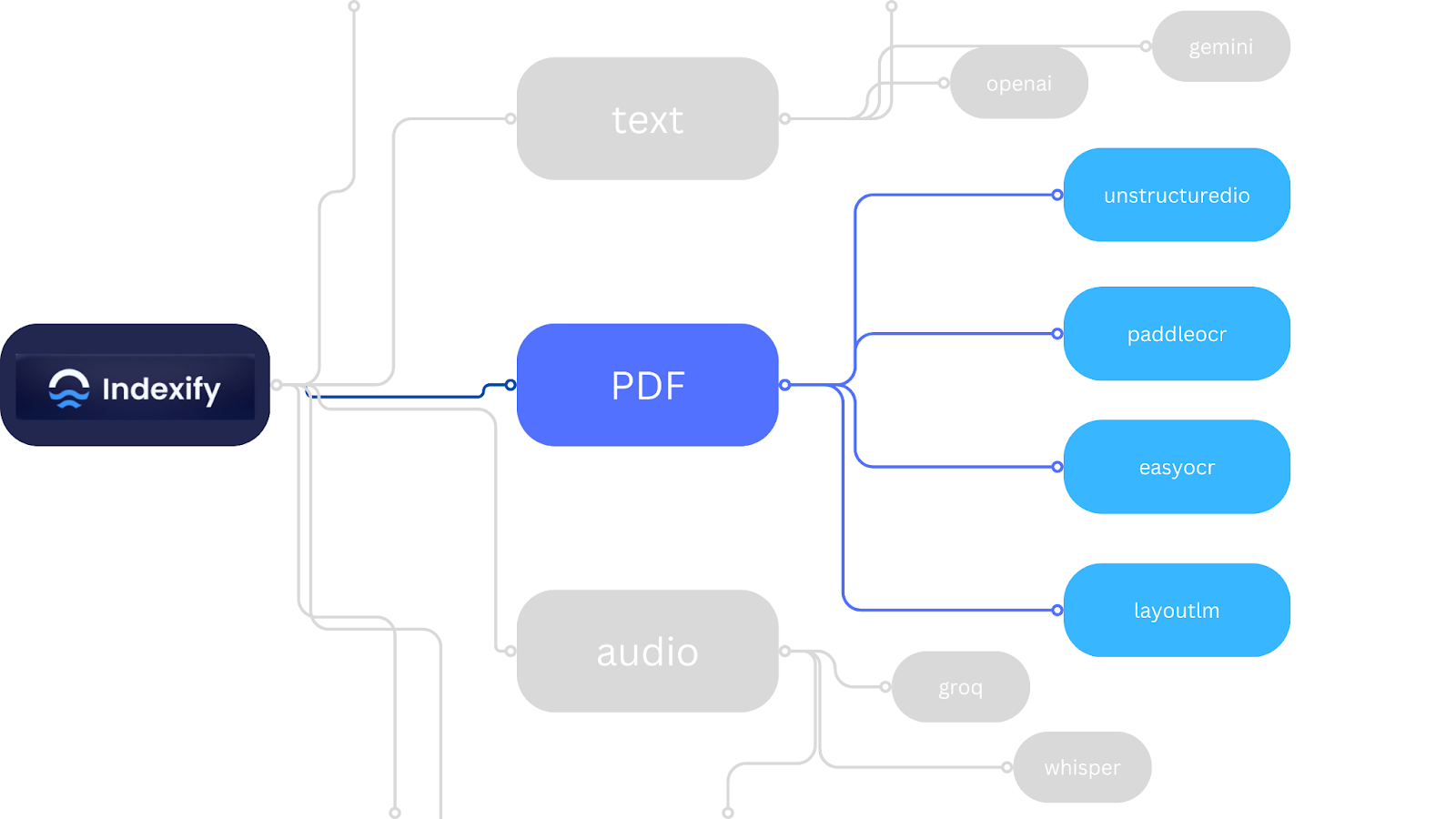
As it stands indexify supports multiple extractor for multiple modalities (as shown in Fig 3). The full list of indexify extractors along with their use cases can be found in the documentation.
How to use PaddleOCR Extractor?
The PaddleOCR PDF Extractor, based on the PaddleOCR library, is a powerful tool in the Indexify ecosystem. It integrates various OCR algorithms for text detection (DB, EAST, SAST) and recognition (CRNN, RARE, StarNet, Rosetta, SRN).
Let’s walk through setting up and using the PaddleOCR Extractor:
Here is an example of creating a pipeline that extracts text, tables, and images from a PDF document.
You’ll need three different terminals open to complete this tutorial:
- Terminal 1 to download and run the Indexify Server.
- Terminal 2 to run our Indexify extractors which will handle structured extraction, chunking and embedding of ingested pages.
- Terminal 3 to run our python scripts to help load and query data from our Indexify server.
Step 1: Start the Indexify Server
Let’s first start by downloading the Indexify server and running it.
Terminal 1
curl https://getindexify.ai | sh
./indexify server -dStep 2: Start a PDF Extractor server
Let’s start by creating a new virtual environment before installing the required packages in our virtual environment.
Terminal 2
python3 -m venv venv
source venv/bin/activate
pip3 install indexify-extractor-sdk indexifyWe can then run all available extractors using the command below.
!indexify-extractor download tensorlake/paddleocr_extractor
!indexify-extractor join-serverStep 3: Create an Extraction Graph
Terminal 3
!python3 -m venv venv
!source venv/bin/activateCreate a python script defining the extraction graph and run it. Steps 3-5 in this sub-section should be part of the same python file that should be run after activating the venv in Terminal 3.
from indexify import IndexifyClient, ExtractionGraph
client = IndexifyClient()
extraction_graph_spec = """
name: 'pdflearner'
extraction_policies:
- extractor: 'tensorlake/paddleocr_extractor'
name: 'pdf_to_text'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
client.create_extraction_graph(extraction_graph)This code sets up an extraction graph named ‘pdflearner’ that uses the PaddleOCR extractor to convert PDFs to text.
Step 4: Upload PDFs from your application
content_id = client.upload_file("pdflearner", "/path/to/pdf.file")Step 5: Inspect the extracted content
client.wait_for_extraction(content_id)
extracted_content = client.get_extracted_content(content_id=content_id, graph_name="pdflearner", policy_name="pdf_to_text")
print(extracted_content)This snippet uploads a PDF, waits for the extraction to complete, and then retrieves and prints the extracted content.
We did not believe that it could be a simple few-step process to extract all the textual information meaningfully. So we tested it out with a real-world tax invoice ( as shown in Figure 4).
[Content(content_type='text/plain', data=b"Form 1040\nForms W-2 & W-2G
Summary\n2023\nKeep for your records\n Name(s) Shown on Return\nSocial
Security Number\nJohn H & Jane K Doe\n321-12-3456\nEmployer\nSP\nFederal
Tax\nState Wages\nState Tax\nForm W-2\nWages\nAcmeware
Employer\n143,433.\n143,433.\n1,000.\nTotals.\n143,433.\n143,433.\n1,000.\nFo
rm W-2 Summary\nBox No.\nDescription\nTaxpayer\nSpouse\nTotal\nTotal wages,
tips and compensation:\n1\na\nW2 box 1 statutory wages reported on Sch C\nW2
box 1 inmate or halfway house wages .\n6\nc\nAll other W2 box 1
wages\n143,433.\n143,433.\nd\nForeign wages included in total
wages\ne\n0.\n0.\n2\nTotal federal tax withheld\n 3 & 7 Total social security
wages/tips .\n143,566.\n143,566.\n4\nTotal social security tax
withheld\n8,901.\n8,901.\n5\nTotal Medicare wages and
tips\n143,566.\n143,566.\n6\nTotal Medicare tax withheld .
:\n2,082.\n2,082.\n8\nTotal allocated tips .\n9\nNot used\n10 a\nTotal
dependent care benefits\nb\nOffsite dependent care benefits\nc\nOnsite
dependent care benefits\n11\n Total distributions from nonqualified plans\n12
a\nTotal from Box 12\n3,732.\n3,732.\nElective deferrals to qualified
plans\n133.\n133.\nc\nRoth contrib. to 401(k), 403(b), 457(b) plans .\n.\n1
Elective deferrals to government 457 plans\n2 Non-elective deferrals to gov't
457 plans .\ne\nDeferrals to non-government 457 plans\nf\nDeferrals 409A
nonqual deferred comp plan .\n6\nIncome 409A nonqual deferred comp plan
.\nh\nUncollected Medicare tax :\nUncollected social security and RRTA tier
1\nj\nUncollected RRTA tier 2 . . .\nk\nIncome from nonstatutory stock
options\nNon-taxable combat pay\nm\nQSEHRA benefits\nTotal other items from
box 12 .\nn\n3,599.\n3,599.\n14 a\n Total deductible mandatory state tax
.\nb\nTotal deductible charitable contributions\nc\nTotal state deductible
employee expenses .\nd\n Total RR Compensation .\ne\nTotal RR Tier 1 tax
.\nf\nTotal RR Tier 2 tax . -\nTotal RR Medicare tax .\ng\nh\nTotal RR
Additional Medicare tax .\ni\nTotal RRTA tips. : :\nj\nTotal other items from
box 14\nk\nTotal sick leave subject to $511 limit\nTotal sick leave subject
to $200 limit\nm\nTotal emergency family leave wages\n16\nTotal state wages
and tips .\n143,433.\n143,433.\n17\nTotal state tax
withheld\n1,000.\n1,000.\n19\nTotal local tax withheld .", features=
[Feature(feature_type='metadata', name='metadata', value={'type': 'text'},
comment=None)], labels={})]Advanced Usage: Structured Information Extraction

While extracting text is useful, often we need to parse this text into structured data. Here’s how you can use Indexify to extract specific fields from your PDFs (the entire workflow is shown in Figure 5).
from indexify import IndexifyClient, ExtractionGraph, SchemaExtractorConfig, Content, SchemaExtractor
client = IndexifyClient()
schema = {
'properties': {
'invoice_number': {'title': 'Invoice Number', 'type': 'string'},
'date': {'title': 'Date', 'type': 'string'},
'account_number': {'title': 'Account Number', 'type': 'string'},
'owner': {'title': 'Owner', 'type': 'string'},
'address': {'title': 'Address', 'type': 'string'},
'last_month_balance': {'title': 'Last Month Balance', 'type': 'string'},
'current_amount_due': {'title': 'Current Amount Due', 'type': 'string'},
'registration_key': {'title': 'Registration Key', 'type': 'string'},
'due_date': {'title': 'Due Date', 'type': 'string'}
},
'required': ['invoice_number', 'date', 'account_number', 'owner', 'address', 'last_month_balance', 'current_amount_due', 'registration_key', 'due_date']
'title': 'User',
'type': 'object'
}
examples = str([
{
"type": "object",
"properties": {
"employer_name": {"type": "string", "title": "Employer Name"},
"employee_name": {"type": "string", "title": "Employee Name"},
"wages": {"type": "number", "title": "Wages"},
"federal_tax_withheld": {"type": "number", "title": "Federal Tax
Withheld"},
"state_wages": {"type": "number", "title": "State Wages"},
"state_tax": {"type": "number", "title": "State Tax"}
},
"required": ["employer_name", "employee_name", "wages",
"federal_tax_withheld", "state_wages", "state_tax"]
},
{
"type": "object",
"properties": {
"booking_reference": {"type": "string", "title": "Booking Reference"},
"passenger_name": {"type": "string", "title": "Passenger Name"},
"flight_number": {"type": "string", "title": "Flight Number"},
"departure_airport": {"type": "string", "title": "Departure Airport"},
"arrival_airport": {"type": "string", "title": "Arrival Airport"},
"departure_time": {"type": "string", "title": "Departure Time"},
"arrival_time": {"type": "string", "title": "Arrival Time"} },
"required": ["booking_reference", "passenger_name", "flight_number","departure_airport", "arrival_airport", "departure_time", "arrival_time"]
}
])
extraction_graph_spec = """
name: 'invoice-learner'
extraction_policies:
- extractor: 'tensorlake/paddleocr_extractor'
name: 'pdf-extraction'
- extractor: 'schema_extractor'
name: 'text_to_json'
input_params:
service: 'openai'
example_text: {examples}
content_source: 'invoice-learner'
"""
extraction_graph = ExtractionGraph.from_yaml(extraction_graph_spec)
client.create_extraction_graph(extraction_graph)
content_id = client.upload_file("invoice-learner", "/path/to/pdf.pdf")
print(content_id)
client.wait_for_extraction(content_id)
extracted_content = client.get_extracted_content(content_id=content_id, graph_name="invoice-learner", policy_name="text_to_json")
print(extracted_content)This advanced example demonstrates how to chain multiple extractors. It first uses PaddleOCR to extract text from the PDF, then applies a schema extractor to parse the text into structured JSON data based on the defined schema.
The schema extractor is interesting since it allows you to use both the schema as well as infer the schema from the Language Model of choice using few-shot learning.
We do this by passing few examples of how the schema should look through the parameter example_text. The cleaner and more verbose the examples are, the better the inferred schema.
Let us investigate the output from this design:
[Content(content_type='text/plain', data=b'{"Form":"1040","Forms W-2 & W-2G Summary":{"Year":2023,"Keep for your records":true,"Name(s) Shown on Return":"John H & Jane K Doe","Social Security Number":"321-12-3456","Employer":{"Name":"Acmeware Employer","Federal Tax":"SP","State Wages":143433,"State Tax":1000},"Totals":{"Wages":143433,"State Wages":143433,"State Tax":1000}},"Form W-2 Summary":{"Box No.":{"Description":{"Taxpayer":"John H Doe","Spouse":"Jane K Doe","Total":"John H & Jane K Doe"}},"Total wages, tips and compensation":{"W2 box 1 statutory wages reported on Sch C":143433,"W2 box 1 inmate or halfway house wages":0,"All other W2 box 1 wages":143433,"Foreign wages included in total wages":0},"Total federal tax withheld":0,"Total social security wages/tips":143566,"Total social security tax withheld":8901,"Total Medicare wages and tips":143566,"Total Medicare tax withheld":2082,"Total allocated tips":0,"Total dependent care benefits":{"Offsite dependent care benefits":0,"Onsite dependent care benefits":0},"Total distributions from nonqualified plans":0,"Total from Box 12":{"Elective deferrals to qualified plans":3732,"Roth contrib. to 401(k), 403(b), 457(b) plans":133,"Elective deferrals to government 457 plans":0,"Non-elective deferrals to gov't 457 plans":0,"Deferrals to non-government 457 plans":0,"Deferrals 409A nonqual deferred comp plan":0,"Income 409A nonqual deferred comp plan":0,"Uncollected Medicare tax":0,"Uncollected social security and RRTA tier 1":0,"Uncollected RRTA tier 2":0,"Income from nonstatutory stock options":0,"Non-taxable combat pay":0,"QSEHRA benefits":0,"Total other items from box 12":3599},"Total deductible mandatory state tax":0,"Total deductible charitable contributions":0,"Total state deductible employee expenses":0,"Total RR Compensation":0,"Total RR Tier 1 tax":0,"Total RR Tier 2 tax":0,"Total RR Medicare tax":0,"Total RR Additional Medicare tax":0,"Total RRTA tips":0,"Total other items from box 14":0,"Total sick leave subject to $511 limit":0,"Total sick leave subject to $200 limit":0,"Total emergency family leave wages":0,"Total state wages and tips":143433,"Total state tax withheld":1000,"Total local tax withheld":0}}, features=[Feature(feature_type='metadata', name='text', value={'model': 'gpt-3.5-turbo-0125', 'completion_tokens': 204, 'prompt_tokens': 692}, comment=None)], labels={})]Yes, that is difficult to read so let us expand that for you in Figure 6.

This means that after this step, our textual data is successfully extracted into a structured JSON format. The data might be complexly laid out, spaced unevenly, horizontally oriented, vertically oriented, diagonally oriented, large fonts, small fonts, no matter the design, it just works!
Well, that all but solves the problem that we initially set out to do. We can finally scream Mission Accomplished, Tom Cruise style!
Why use Another Extractor?
While the PaddleOCR extractor is powerful for text extraction from PDFs, the true strength of Indexify lies in its ability to chain multiple extractors together, creating sophisticated data processing pipelines. Let’s delve deeper into why you might want to use additional extractors and how Indexify makes this process seamless and efficient.
Extraction Graphs: The Power of Chaining
Indexify’s Extraction Graphs allow you to apply a sequence of extractors on ingested content in a streaming manner. Each step in an Extraction Graph is known as an Extraction Policy. This approach offers several advantages:
- Modular Processing: Break down complex extraction tasks into smaller, manageable steps.
- Flexibility: Easily modify or replace individual extractors without affecting the entire pipeline.
- Efficiency: Process data in a streaming fashion, reducing latency and resource usage.
Lineage Tracking
Indexify tracks the lineage of transformed content and extracted features from the source. This feature is crucial for:
- Data Governance: Understand how your data has been processed and transformed.
- Debugging: Easily trace issues back to their source.
- Compliance: Meet regulatory requirements by maintaining a clear audit trail of data transformations.
Complementary Extractors
While PaddleOCR excels at text extraction, other extractors can add significant value to your data processing pipeline.
Why Choose Indexify?
Indexify shines in scenarios where:
- You’re dealing with a large volume of documents (>1000s).
- Your data volume grows over time.
- You need reliable and available ingestion pipelines.
- You’re working with multi-modal data or combining multiple models in a single pipeline.
- Your application’s user experience depends on up-to-date data.
Conclusion
Extracting structured data from PDFs doesn’t have to be a headache. With Indexify and an array of powerful extractors like PaddleOCR, you can streamline your workflow, handle large volumes of documents, and extract meaningful, structured data with ease. Whether you’re processing invoices, academic papers, or any other type of PDF document, Indexify provides the tools you need to turn unstructured data into valuable insights.
Ready to streamline your PDF extraction process? Give Indexify a try and experience the ease of intelligent, scalable data extraction!







