Introduction
Vector databases are specialized databases that store data as high-dimensional vectors. These vectors serve as mathematical representations of features or attributes, with dimensions ranging from tens to thousands based on the complexity of the data. They are designed to manage high-dimensional data that traditional Database Management Systems (DBMS) struggle to handle effectively. Vector databases are crucial for applications involving natural language processing, computer vision, recommendation systems, and other fields requiring accurate similarity search and retrieval capabilities.
Vector databases excel in fast and accurate similarity search, surpassing traditional databases that rely on exact matches or predefined criteria. They support complex and unstructured data like text, images, audio, and video, transforming them into high-dimensional vectors to capture their attributes efficiently. In this article, we will discuss different indexing algorithms in vector databases.
Overview
- Vector databases use high-dimensional vectors for managing complex data types.
- Tree-based indexing improves search efficiency by partitioning vector space.
- Hashing-based indexing speeds up retrieval using hash functions.
- Graph-based indexing enhances similarity searches with node and edge relationships.
- Quantization-based indexing compresses vectors for faster retrieval.
- Future developments will focus on scalability, diverse data handling, and better model integration.
Table of contents
What is Tree-based Indexing?
Tree-based indexing methods, like k-d trees and ball trees, are used in vector databases to perform exact searches and group points in hyperspheres efficiently. These algorithms divide vector space into regions, allowing for systematic searches based on proximity and distance. Tree-based indexing enables quick retrieval of nearest neighbors by recursively partitioning the data space, improving search efficiency. The hierarchical structure of trees organizes data points, making it easier to locate similar points based on their dimensions.
Tree-based indexing in vector databases sets distance bounds to speed up data retrieval and enhance search efficiency. This approach optimizes retrieval by navigating the data space to find the nearest neighbors effectively. The main tree-based techniques used are:
Approximate Nearest Neighbors Oh Yeah (annoy)
It is a technique for fast and accurate similarity search in high-dimensional data using binary trees. Each tree splits the vector space with random hyperplanes, assigning vectors to leaf nodes. Annoy traverses each tree to collect candidate vectors from the same leaf nodes to find similar vectors, then calculates exact distances to return the top k nearest neighbors.

Best Bin First
This method finds a vector’s nearest neighbors by using a kd-tree to divide data into bins and searching the closest bin first. This method reduces search time and improves accuracy by focusing on promising bins and avoiding far-off points. Performance depends on factors like data dimensionality, number of bins, and distance methods, with challenges like handling noisy data and choosing good split points.
K-means tree
It is a method to group high-dimensional data into a tree structure, where each node is a cluster. It uses k-means clustering at each level and repeats until the tree reaches a certain depth or size. Assigning a point to a cluster uses the Euclidean norm. Points are assigned to leaf nodes if they belong to all ancestor nodes. The nearest neighbor search uses candidate points from tree branches. Fast and accurate similarity search by following tree branches. Supports adding and removing points by updating the tree.
What is Hashing-based Indexing?
Hashing-based indexing is utilized in vector databases to efficiently store and retrieve high-dimensional vectors, offering a faster alternative than traditional methods like B-trees or hash tables. Hashing reduces the complexity of searching high-dimensional vectors by transforming the vectors into hash keys, allowing for quicker retrieval based on similarity or distance metrics. Hash functions map vectors to specific index positions, enabling faster searches for approximate nearest neighbors (ANN), thus enhancing the search performance of the database.
Hashing techniques in vector databases provide flexibility to handle different types of vector data, including dense, sparse, and binary vectors, adapting to varied data characteristics and requirements. Hashing-based indexing supports scalability and efficiency by efficiently distributing workload and optimizing resource utilization across multiple machines or clusters, which is crucial for large-scale data analysis and real-time processing in AI applications. There are three hashing-based techniques mainly used in vector databases:
Local-sensitive Hashing
It is designed to maintain vector locality where similar vectors have higher chances of sharing similar hash codes. Different hash function families cater to various distance and similarity metrics, such as Euclidean distance and cosine similarity. LSH reduces memory usage and search time by comparing binary codes instead of original vectors, adapting well to dynamic datasets. LSH allows for the insertion and deletion of codes without affecting existing ones, offering scalability and flexibility in vector databases.
Spectral hashing
It is a technique used to find approximate nearest neighbors in large vector collections by employing spectral graph theory. It generates hash functions to minimize quantization error and maximize binary code variance, balancing even distribution and information richness. The algorithm aims to minimize the variance of each binary function and maximize mutual information among different functions, ensuring informative and discriminative codes. Spectral hashing solves an optimization problem with a trade-off parameter for variance and mutual information. Factors influencing spectral hashing, challenges, and extensions mirror those of local-sensitive hashing, including noise handling, graph Laplacian selection, and enhanced recall through multiple hash functions.
Deep hashing
Deep hashing uses neural networks to create compact binary codes from high-dimensional vectors, boosting retrieval efficiency. It balances reconstruction and quantization loss to maintain data fidelity and minimize code discrepancies. Hash functions convert vectors to binary codes, stored in a hash table for similarity-based retrieval. Success depends on neural network design, loss function, and code bit count. Challenges include handling noise, network initialization, and improving recall with multiple hash functions.
Here are some similar reads:
| Articles | Source |
| Top 15 Vector Databases 2024 | Links |
| How Do Vector Databases Shape the Future of Generative AI Solutions? | Links |
| What is a Vector Database? | Links |
| Vector Databases: 10+ Real-World Applications Transforming Industries | Links |
What is Graph-based Indexing?
Graph-based indexing in vector databases involves representing data as nodes and relationships as edges in a graph structure. This enables context-aware retrieval and more intelligent querying based on the relationships between data points. This approach helps vector databases capture semantic connections, making similarity searches more accurate by considering data meaning and context. Graph-based indexing improves querying by using graph traversal algorithms to navigate data efficiently, boosting search performance and handling complex queries on high-dimensional data. Storing relationships in the graph structure reveals hidden patterns and associations, benefiting applications like recommendation systems and graph analytics. Graph-based indexing provides a flexible method for representing diverse data types and complex relationships. There are two graph-based methods which are generally used in vector databases:
Navigable Small World
It is a graph-based technique used in vector databases to efficiently store and retrieve high-dimensional vectors based on their similarity or distance. The NSW algorithm builds a graph connecting each vector to its nearest neighbors, along with random long-range links that span different areas of the vector space. Long-range links created in NSW introduce shortcuts, enhancing traversal speed like social networks’ properties. NSW’s graph-based approach offers scalability advantages, making it suitable for handling large-scale and real-time data analysis in vector databases. The method balances accuracy and efficiency trade-offs, ensuring effective query processing and retrieval of high-dimensional vectors within the database.
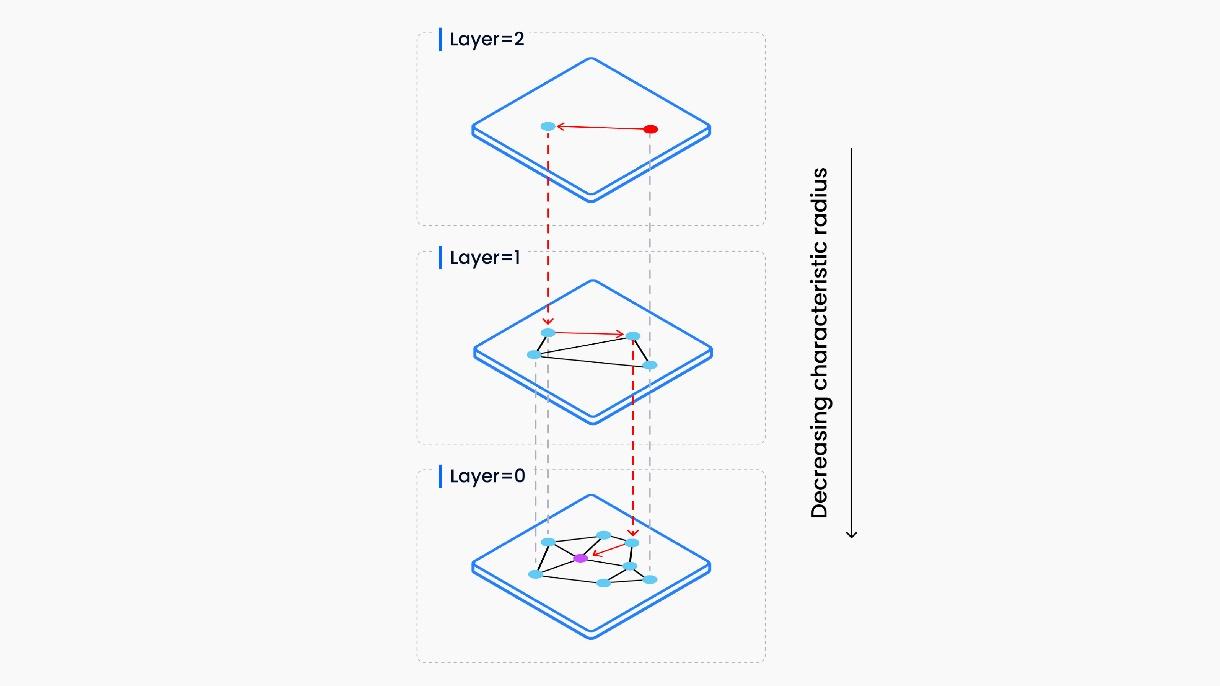
Hierarchical Navigable Small World
The HNSW method organizes vectors into different layers with varying probabilities, where higher layers include fewer points with longer edges, and lower layers have more points with shorter edges. The algorithm builds a hierarchical graph structure connecting vectors based on similarity or distance, utilizing a multi-layered approach to retrieve nearest neighbors efficiently. Each layer in HNSW has a controlled number of neighbors per point, influencing search performance within the database. HNSW uses an entry point in the highest layer for searches, with parameters like the maximum neighbors (M) controlling traversal and query operations.
Also Read: Introduction to HNSW: Hierarchical Navigable Small World
What is Quantization-based Indexing?
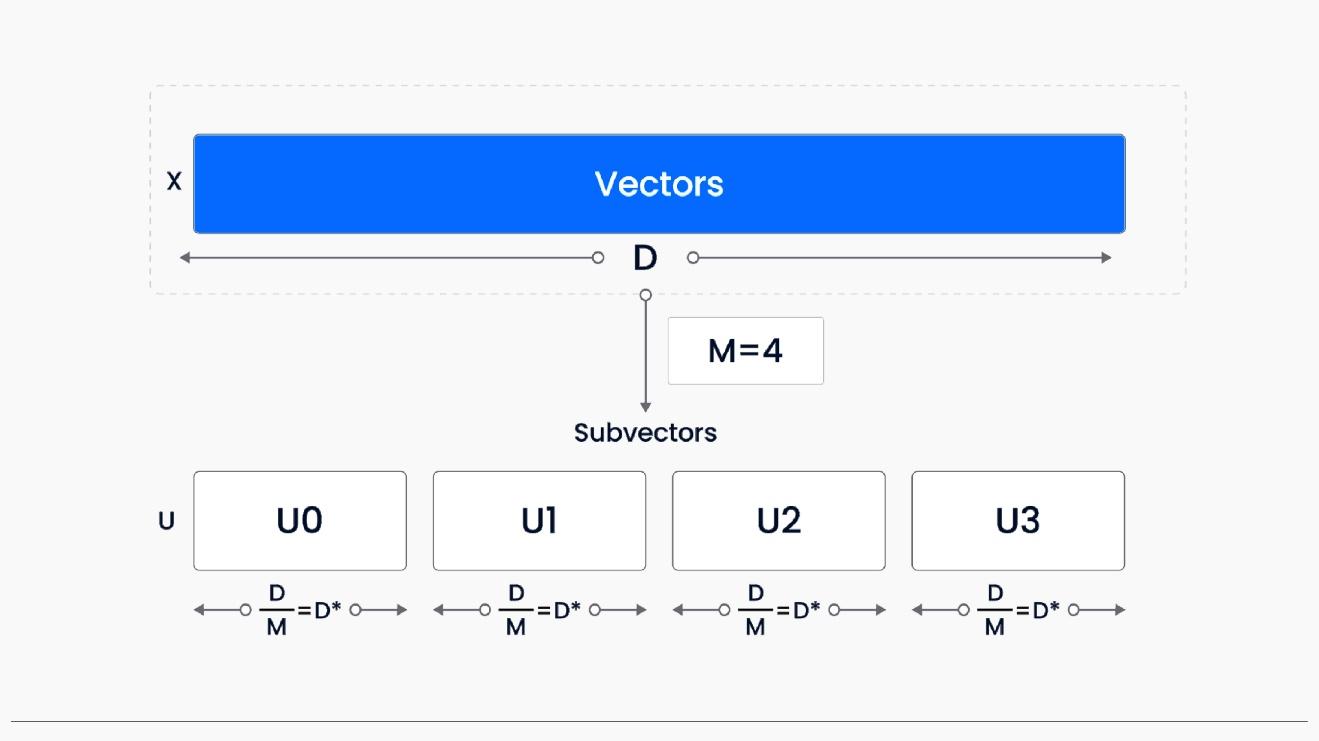
Quantization-based indexing compresses high-dimensional vectors into smaller, efficient representations, reducing storage and enhancing retrieval speed. This involves dividing vectors into subvectors, applying clustering algorithms like k-means, and creating compact codes. By minimizing storage space and simplifying vector comparisons, this technique enables faster and more scalable search operations, improving performance for approximate nearest-neighbor searches and similarity queries. Quantization techniques allow vector databases to handle large volumes of high-dimensional data efficiently, making them ideal for real-time processing and analysis. There are three main quantization based indexing techniques available:
Product Quantization
It is a technique for compressing high-dimensional vectors into more efficient representations. OPQ enhances PQ by optimizing space decomposition and codebooks to minimize quantization distortions.
Optimized Product Quantization
It is a variation of PQ, which focuses on minimizing quantization distortions by optimizing space decomposition and codebooks. It improves information loss and enhances code discriminability.
Online Product Quantization
This technique utilizes an online learning technique with parameters α (learning rate) and β (forgetting rate) to update codebooks and codes for subvectors. It ensures continuous improvement in encoding processes.
Below is a comparison of these indexing algorithms in vector databases based on their performance metrics like speed, accuracy, memory usage, etc., and also the Trade-offs between different algorithms we need to make before choosing these algorithms.
The Comparison Table
Here is the comparison of indexing algorithms in vector databases:
| Approach | Speed | Accuracy | Memory Usage | Trade-offs |
|---|---|---|---|---|
| Tree-Based | Efficient for low to moderately high-dimensional data; performance degrades in higher dimensions | High in lower dimensions; effectiveness diminishes in higher dimensions | Generally, fast for indexing and querying by hashing similar items into the same buckets | Accurate and efficient for low-dimensional data; less effective and more memory-intensive as dimensionality increases |
| Hash-Based | Generally fast for indexing and querying by hashing similar items into the same buckets | Lower accuracy due to possible hash collisions | Memory-efficient by storing only hash codes, not the original vectors | Fast query times but reduced accuracy due to hash collisions |
| Graph-Based | Fast search times by leveraging graph structures for efficient traversal | High accuracy using greedy search strategy to find most similar vectors | Memory-intensive due to storing graph structure; HNSW optimizes memory with hierarchical layers | High accuracy and fast search times but requires significant memory for storing graph structure |
| Quantization-Based | Fast search times by compressing vectors into smaller codes | High accuracy depends on codebook quality and number of centroids used | Highly memory-efficient by storing compact codes instead of original vectors | Significant memory savings and fast search times, but accuracy can be affected by the level of quantization |
Challenges and Future Directions in Vector Databases
Vector databases stand at the forefront of modern data management, offering powerful solutions for handling high-dimensional data. However, they face numerous challenges that push the boundaries of computational efficiency and data organization. One of the primary hurdles is the sheer complexity of indexing and searching billions of high-dimensional vectors. Traditional methods struggle with the curse of dimensionality, requiring specialized techniques like approximate nearest neighbor (ANN) search, hashing, and graph-based methods. These approaches balance speed and accuracy while evolving to meet the demands of data-intensive applications.
The diversity of vector data types presents another significant challenge. From dense to sparse to binary vectors, each type comes with its characteristics and requirements. Vector databases must adapt their indexing systems to handle this heterogeneity efficiently, ensuring optimal performance across various data landscapes. Scalability and performance loom large on the horizon of vector database development. As data analysis scales, systems must use sharding, partitioning, and replication techniques to overcome traditional database bottlenecks and ensure fast responses for AI and data science applications. Data quality and diversity also play crucial roles, particularly in training large language models (LLMs). Vector databases must rise to the challenge of supporting sophisticated data management techniques to ensure the reliability and robustness of these models.
In a nutshell, Future advancements in vector databases will enhance LLM integration, enable cross-modal searches, and improve real-time knowledge retrieval. Ongoing research focuses on adapting to dynamic data and optimizing memory and efficiency, promising transformative impacts across various industries.
Conclusion
Vector databases are pivotal in managing high-dimensional data, offering superior performance for similarity searches compared to traditional databases. By transforming complex data into high-dimensional vectors, they excel in handling unstructured data like text, images, and video. Various indexing techniques—tree-based, hashing-based, graph-based, and quantization-based—each offer unique advantages and trade-offs in speed, accuracy, and memory usage.
Despite their strengths, vector databases face challenges such as handling diverse data types, scaling efficiently, and maintaining high accuracy. We expect future developments to improve integration with large language models, enable cross-modal searches, and enhance real-time retrieval capabilities. These advancements will continue to drive the evolution of vector databases, making them increasingly essential for sophisticated data management and analysis across industries.
Frequently Asked Questions
Q1. What are indexing algorithms in vector databases?
Ans. Indexing algorithms are techniques used to organize and quickly retrieve vectors (data points) from a database based on similarity or distance metrics.
Q2. Why are indexing algorithms important for vector databases?
Ans. They improve the efficiency of querying large datasets by reducing search space and speeding up retrieval.
Q3. What are some common indexing algorithms used in vector databases?
Ans. Common algorithms include KD-Trees, R-Trees, Locality-Sensitive Hashing (LSH), and Approximate Nearest Neighbor (ANN) methods.
Q4. How do I choose the right indexing algorithm for my application?
Ans. The choice depends on factors like the type of data, the size of the dataset, query speed requirements, and the desired trade-off between accuracy and performance.





