Introduction
In Artificial Intelligence, Understanding the underlying workings of language models has proven to be significant and difficult. Google has made a significant step forward in tackling this issue by releasing Gemma Scope, a comprehensive package of tools to assist researchers in peering inside the “black box” of AI language models. This article will look at Gemma Scope, its significance, and how it intends to transform the field of mechanistic interpretability.

Overview
- Mechanistic interpretability helps researchers understand how AI models learn from data and make decisions without human intervention.
- Gemma Scope offers a set of tools, including sparse autoencoders, to help researchers analyze and understand the internal workings of AI language models like Gemma 2 9B and Gemma 2 2B.
- Gemma Scope dissects model activations using sparse autoencoders into distinct features, providing insights into how language models process and generate text.
- Implementing Gemma Scope involves loading the Gemma 2 model, running text inputs through it, and using sparse autoencoders to analyze activations, as demonstrated in the provided code examples.
- Gemma Scope advances AI research by offering tools for deeper understanding, improving model design, addressing safety concerns, and scaling interpretability techniques to larger models.
- Future research in mechanistic interpretability should focus on automating feature interpretation, ensuring scalability, generalizing insights across models, and addressing ethical considerations in AI development.
Table of contents
What is Gemma Scope?
Gemma Scope is a collection of hundreds of publicly available open sparse autoencoders (SAEs) for Google’s lightweight open model family, Gemma 2 9B and Gemma 2 2B. These technologies serve as a “microscope” for academics, allowing them to analyze the internal processes of language models and gain insights into how they work and decide.
The Importance of Mechanistic Interpretability
To realize Gemma Scope’s significance, you must first understand the concept of mechanical interpretability. When researchers design AI language models, they create systems that can learn from large volumes of data without human intervention. As a result, the inner workings of these models are frequently unknown, even to their authors.
Mechanistic interpretability is a research subject devoted to understanding these fundamental workings. By studying it, researchers can acquire a deeper knowledge of how language models function.
- Create more resilient systems.
- Improve precautions against model hallucinations.
- Protect against the hazards of autonomous AI agents, such as dishonesty or manipulation.
How Does Gemma Scope Work?
Gemma Scope uses sparse autoencoders to interpret a model’s activations while processing text input. Here’s a simple explanation of the process:
- Text Input: When you ask a language model a query, it converts your text into a set of ‘activations’.
- Activation Mapping: These activations represent word associations, allowing the model to create connections and provide answers.
- Feature Recognition: As the model processes text, activations at various layers in the neural network represent increasingly complex notions known as ‘features’.
- Sparse Autoencoder Analysis: Gemma Scope’s sparse autoencoders divide each activation into limited features, which may disclose the language model’s true underlying characteristics.
Also read: How to Use Gemma LLM?
Gemma Scope-Technical Details and Implementation
Let’s dive into the technical details of implementing Gemma Scope, using code examples to illustrate key concepts:
Loading the Model
First, we need to load the Gemma 2 model:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
from huggingface_hub import hf_hub_download, notebook_login
import numpy as np
import torchWe load Gemma 2 2B, the smallest model for which Gemma Scope works. We load the base model rather than the conversation model because that is where our SAEs are taught. The SAEs appear to transfer to these models.
To obtain the model weights, you first need to authenticate them with huggingface.
notebook_login()
torch.set_grad_enabled(False) # avoid blowing up mem
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2-2b",
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")Running the Model

Now we’ve loaded the model, let’s try running it! We give it the prompt
“Just a drop in the ocean A change in the weather,I was praying that you and me might end up together. Its like wiching for the rain as I stand in the desert.” and print the generated output
from IPython.display import display, Markdown
prompt = "Just a drop in the ocean A change in the weather,I was praying that you and me might end up together. Its like wiching for the rain as I stand in the desert."
# Use the tokenizer to convert it to tokens. Note that this implicitly adds a special "Beginning of Sequence" or <bos> token to the start
inputs = tokenizer.encode(prompt, return_tensors="pt", add_special_tokens=True).to("cuda")
display(Markdown(f"**Encoded inputs:**\n```\n{inputs}\n```"))
# Pass it in to the model and generate text
outputs = model.generate(input_ids=inputs, max_new_tokens=50)
generated_text = tokenizer.decode(outputs[0])
display(Markdown(f"**Generated text:**\n\n{generated_text}"))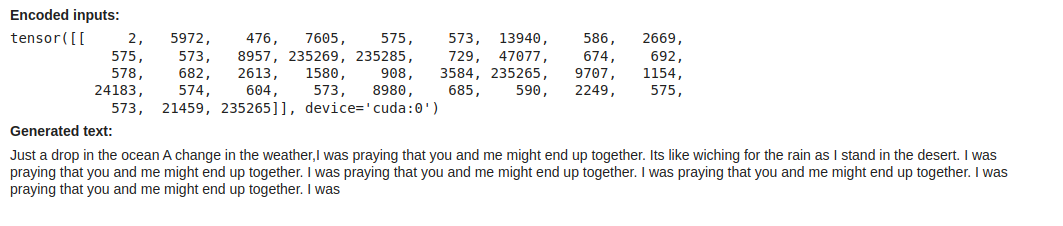
So we have Gemma 2 loaded and can sample from it to get sensible results.
Now, let’s load one of our SAE files.
GemmaScope has nearly four hundred SAEs, but for now, we’ll merely load one on the residual stream at the end of layer 20.
Loading the parameters of the model and moving them to GPU:
params = np.load(path_to_params)
pt_params = {k: torch.from_numpy(v).cuda() for k, v in params.items()}Implementing the Sparse-Auto-Encoder(SAE):
We now define the SAE’s forward pass for educational reasons.
Gemma Scope is a collection of JumpReLU SAEs, similar to a typical two-layer (one hidden layer) neural network but with a JumpReLU activation function: a ReLU with a discontinuous jump.
import torch.nn as nn
class JumpReLUSAE(nn.Module):
def __init__(self, d_model, d_sae):
# Note that we initialise these to zeros because we're loading in pre-trained weights.
# If you want to train your own SAEs then we recommend using blah
super().__init__()
self.W_enc = nn.Parameter(torch.zeros(d_model, d_sae))
self.W_dec = nn.Parameter(torch.zeros(d_sae, d_model))
self.threshold = nn.Parameter(torch.zeros(d_sae))
self.b_enc = nn.Parameter(torch.zeros(d_sae))
self.b_dec = nn.Parameter(torch.zeros(d_model))
def encode(self, input_acts):
pre_acts = input_acts @ self.W_enc + self.b_enc
mask = (pre_acts > self.threshold)
acts = mask * torch.nn.functional.relu(pre_acts)
return acts
def decode(self, acts):
return acts @ self.W_dec + self.b_dec
def forward(self, acts):
acts = self.encode(acts)
recon = self.decode(acts)
return recon
sae = JumpReLUSAE(params['W_enc'].shape[0], params['W_enc'].shape[1])
sae.load_state_dict(pt_params)First, let’s run some model activations at the SAE target site. We’ll start by demonstrating how to do this ‘ manually’ using Pytorch hooks. It should be noted that this is not especially good practice, and it is probably more practical to utilize a library like TransformerLens to handle plugging the SAE into a model’s forward pass. However, seeing how it’s done can be valuable for illustration.
We can collect activations at a place by registering a hook. To keep this local, we may wrap it in a function that registers a hook, runs the model while recording the intermediate activation, and then removes the hook.
def gather_residual_activations(model, target_layer, inputs):
target_act = None
def gather_target_act_hook(mod, inputs, outputs):
nonlocal target_act # make sure we can modify the target_act from the outer scope
target_act = outputs[0]
return outputs
handle = model.model.layers[target_layer].register_forward_hook(gather_target_act_hook)
_ = model.forward(inputs)
handle.remove()
return target_act
target_act = gather_residual_activations(model, 20, inputs)
sae.cuda()
sae_acts = sae.encode(target_act.to(torch.float32))
recon = sae.decode(sae_acts)Let’s just double-check that the model looks sensible by checking that we explain a decent chunk of the variance:
1 - torch.mean((recon[:, 1:] - target_act[:, 1:].to(torch.float32)) **2) / (target_act[:, 1:].to(torch.float32).var())
This probably appears fine. This SAE reportedly has an L0 of roughly 70, so let’s also check that.
(sae_acts > 1).sum(-1)
There is one catch: our SAEs are not trained on the BOS token because we discovered that it tended to be a huge outlier and cause training to fail. As a result, when we ask them to do something, they tend to say gibberish, and we must be careful not to do this by accident! As shown above, the BOS token is a huge outlier in terms of L0!
Let’s take a look at the most activating aspects in this input text at each token position.
values, inds = sae_acts.max(-1)
inds
So we notice that one of the max activation examples on this topic is which fires on notions connected to time travel!
Let’s visualize the features in a more interactive way by utilizing the Neuropedia dashboard.
from IPython.display import IFrame
html_template = "https://neuronpedia.org/{}/{}/{}?embed=true&embedexplanation=true&embedplots=true&embedtest=true&height=300"
def get_dashboard_html(sae_release = "gemma-2-2b", sae_id="20-gemmascope-res-16k", feature_idx=0):
return html_template.format(sae_release, sae_id, feature_idx)
html = get_dashboard_html(sae_release = "gemma-2-2b", sae_id="20-gemmascope-res-16k", feature_idx=10004)
IFrame(html, width=1200, height=600)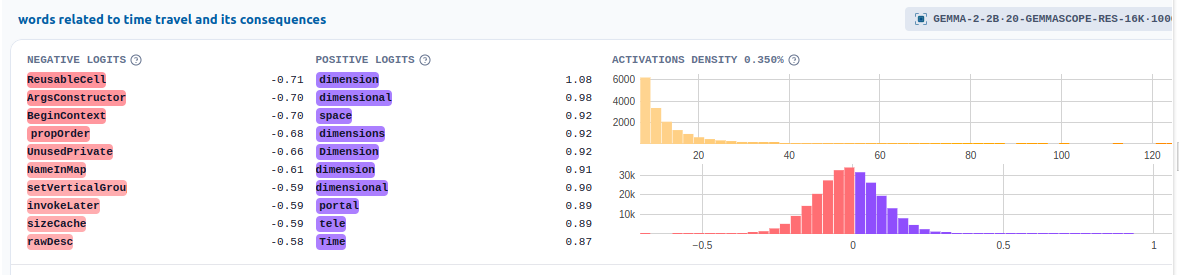
Also Read: Google Gemma, the Open-Source LLM Powerhouse
A Real-world Case Scenario
Consider examining and evaluating recent items to show Gemma Scope’s practical use. This example shows Gemma 2’s fundamental methods for handling various news content.
Setup and Implementation
First, we’ll prepare our environment by importing the necessary libraries and loading the Gemma 2 2B model and its tokenizer.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from huggingface_hub import hf_hub_download
import numpy as np
# Load Gemma 2 2B model and tokenizer
model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b", device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")Next, we’ll implement the JumpReLU Sparse Autoencoder (SAE) and load pre-trained parameters:
# Define JumpReLU SAE
class JumpReLUSAE(torch.nn.Module):
def __init__(self, d_model, d_sae):
super().__init__()
self.W_enc = torch.nn.Parameter(torch.zeros(d_model, d_sae))
self.W_dec = torch.nn.Parameter(torch.zeros(d_sae, d_model))
self.threshold = torch.nn.Parameter(torch.zeros(d_sae))
self.b_enc = torch.nn.Parameter(torch.zeros(d_sae))
self.b_dec = torch.nn.Parameter(torch.zeros(d_model))
def encode(self, input_acts):
pre_acts = input_acts @ self.W_enc + self.b_enc
mask = (pre_acts > self.threshold)
acts = mask * torch.nn.functional.relu(pre_acts)
return acts
def decode(self, acts):
return acts @ self.W_dec + self.b_dec
# Load pre-trained SAE parameters
path_to_params = hf_hub_download(
repo_id="google/gemma-scope-2b-pt-res",
filename="layer_20/width_16k/average_l0_71/params.npz",
)
params = np.load(path_to_params)
pt_params = {k: torch.from_numpy(v).cuda() for k, v in params.items()}
# Initialize and load SAE
sae = JumpReLUSAE(params['W_enc'].shape[0], params['W_enc'].shape[1])
sae.load_state_dict(pt_params)
sae.cuda()
# Function to gather activations
def gather_residual_activations(model, target_layer, inputs):
target_act = None
def gather_target_act_hook(mod, inputs, outputs):
nonlocal target_act
target_act = outputs[0]
handle = model.model.layers[target_layer].register_forward_hook(gather_target_act_hook)
_ = model(inputs)
handle.remove()
return target_actAnalysis Function
We’ll create a function to analyze headlines using Gemma Scope:
# Analyze headline with Gemma Scope
def analyze_headline(headline, top_k=5):
inputs = tokenizer.encode(headline, return_tensors="pt", add_special_tokens=True).to("cuda")
# Gather activations
target_act = gather_residual_activations(model, 20, inputs)
# Apply SAE
sae_acts = sae.encode(target_act.to(torch.float32))
# Get top activated features
values, indices = torch.topk(sae_acts.sum(dim=1), k=top_k)
return indices[0].tolist()Sample Headlines
For our analysis, we’ll use a diverse set of news headlines:
# Sample news headlines
headlines = [
"Global temperatures reach record high in 2024",
"Tech giant unveils revolutionary quantum computer",
"Historic peace treaty signed in Middle East",
"Breakthrough in renewable energy storage announced",
"Major cybersecurity attack affects millions worldwide"
]Feature Categorization
To make our analysis more interpretable, we’ll categorize the activated features into broad topics:
# Predefined feature categories (for demonstration purposes)
feature_categories = {
1000: "Climate and Environment",
2000: "Technology and Innovation",
3000: "Global Politics",
4000: "Energy and Sustainability",
5000: "Cybersecurity and Digital Threats"
}
def categorize_feature(feature_id):
category_id = (feature_id // 1000) * 1000
return feature_categories.get(category_id, "Uncategorized")Results and Interpretation
Now, let’s analyze each headline and interpret the results:
# Analyze headlines
for headline in headlines:
print(f"\nHeadline: {headline}")
top_features = analyze_headline(headline)
print("Top activated feature categories:")
for feature in top_features:
category = categorize_feature(feature)
print(f"- Feature {feature}: {category}")
print(f"For detailed feature interpretation, visit: https://neuronpedia.org/gemma-2-2b/20-gemmascope-res-16k/{top_features[0]}")
# Generate a summary report
print("\n--- Summary Report ---")
print("This analysis demonstrates how Gemma Scope can be used to understand the underlying concepts")
print("that the model activates when processing different types of news headlines.")
print("By examining the activated features, we can gain insights into the model's interpretation")
print("of various news topics and potentially identify biases or focus areas in its training data.")
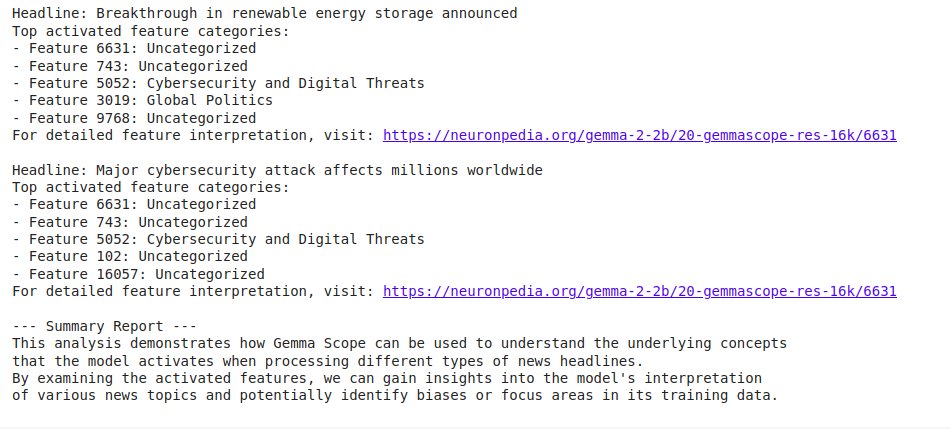
This investigation sheds light on how the Gemma 2 model reads different news subjects. For example, we may see that headlines regarding climate change frequently activate features in the “Climate and Environment” category, whereas tech news activates features in “Technology and Innovation”.
Also read: Gemma 2: Successor to Google Gemma Family of Large Language Models.
Gemma Scope: Impact on AI Research and Development
Gemma Scope is an important achievement in the realm of mechanistic interpretability. Its potential impact on AI research and development is extensive:
- Increased understanding of model behavior: Gemma Scope gives researchers a thorough perspective of a model’s internal processes, allowing them to understand better how language models make decisions and respond.
- Improved model design: Researchers who better understand model internals can create more efficient and effective language models, perhaps leading to breakthroughs in AI capabilities.
- Responding to AI Safety Concerns: Gemma Scope’s capacity to show the inner workings of language models can help identify and mitigate potential AI system hazards such as biases, hallucinations, or unexpected actions.
- Advancing Interpretability Research: Google hopes to expedite progress in this crucial field by establishing Gemma 2 as the finest model family for open mechanistic interpretability research.
- Scaling Techniques to Modern Models: With Gemma Scope, researchers can apply interpretability techniques developed for simpler models to larger, more complicated systems such as Gemma 2 9B.
- Understanding Complex Capabilities: Researchers can now use Gemma Scope’s extensive toolbox to investigate more advanced language model capabilities, such as chain-of-thought reasoning.
- Real-World Applications: Gemma Scope’s discoveries have the ability to address real AI deployment difficulties, such as minimizing hallucinations and preventing jailbreaks in larger models.
Challenges and Future Directions
While Gemma Scope offers a huge step forward in language model interpretability, there are still various obstacles and topics for future research.
- Feature interpretation: Although Gemma Scope may recognize features, evaluating their meaning and relevance requires human intervention. Developing automated methods for feature interpretation is a critical subject for future research.
- Scalability: As language models grow in size and complexity, ensuring that interpretability tools like Gemma Scope can keep up will be critical.
- Generalizing Insights: The insights gained via Gemma Scope will be translated to other language models and AI systems so that they are more widely applicable.
- Ethical considerations: As we get greater insights into AI systems, addressing ethical concerns about privacy, bias, and responsible AI development becomes increasingly important.
Conclusion
Gemma Scope is a big step forward in the field of mechanical interpretability for language models. Google has opened up new paths for studying, enhancing, and protecting these increasingly essential technologies by offering academics powerful tools to examine the inner workings of AI systems.
Frequently Asked Questions
Q1. What is Gemma Scope?
Ans. Gemma Scope is a collection of open sparse autoencoders (SAEs) for Google’s lightweight open model family, Gemma 2 9B and Gemma 2 2B, which allows researchers to analyze the internal processes of language models and gain insights into their workings.
Q2. Why is mechanistic interpretability important?
Ans. Mechanistic interpretability helps researchers understand the fundamental workings of AI models, enabling the creation of more resilient systems, improving model safeguards against hallucinations, and protecting against risks like dishonesty or manipulation by autonomous AI agents.
Q3. What are sparse autoencoders (SAEs)?
Ans. SAEs are a type of neural network used in Gemma Scope to decompose activations into limited features, revealing the underlying characteristics of the language model.
Q4. Can you provide a basic implementation of Gemma Scope?
Ans. Yes, the implementation involves loading the Gemma 2 model, running it with specific text input, and analyzing activations using sparse autoencoders. The article provides sample code for detailed steps.
I'm Sahitya Arya, a seasoned Deep Learning Engineer with one year of hands-on experience in both Deep Learning and Machine Learning. Throughout my career, I've authored more than three research papers and have gained a profound understanding of Deep Learning techniques. Additionally, I possess expertise in Large Language Models (LLMs), contributing to my comprehensive skill set in cutting-edge technologies for artificial intelligence.





