Introduction
Retrieval-Augmented Generation systems are innovative models within the fields of natural language processing since they integrate the components of both retrieval and generation models. In this respect, RAG systems prove to be versatile when the size and variety of tasks that are being executed by LLMs increase, LLMs provide more efficient solutions to fine-tune by use case. Hence, when the RAG systems re-iterate an externally indexed information during the generation process, it is capable of generating more accurate contextual and relevant fresh information response. Nevertheless, real-world applications of RAG systems offer some difficulties, which might affect their performances, although the potentials are evident. This article focuses on these key challenges and discusses measures which can be taken to improve performance of RAG systems. This is based on a recent talk given by Dipanjan (DJ) on Improving Real-World RAG Systems: Key Challenges & Practical Solutions, in the DataHack Summit 2024.
Table of contents
Understanding RAG Systems
RAG systems combine retrieval mechanisms with large language models to generate responses leveraging external data.

The core components of a RAG system include:
- Retrieval: This component involves use of one or several queries to search for documents, or pieces of information in a database, or any other source of knowledge outside the system. Retrieval is the process by which an appropriate amount of relevant information is fetched so as to help in the formulation of a more accurate and contextually relevant response.
- LLM Response Generation: Once the relevant documents are retrieved, they are fed into a large language model (LLM). The LLM then uses this information to generate a response that is not only coherent but also informed by the retrieved data. This external information integration allows the LLM to provide answers grounded in real-time data, rather than relying solely on pre-existing knowledge.
- Fusion Mechanism: In some advanced RAG systems, a fusion mechanism may be used to combine multiple retrieved documents before generating a response. This mechanism ensures that the LLM has access to a more comprehensive context, enabling it to produce more accurate and nuanced answers.
- Feedback Loop: Modern RAG systems often include a feedback loop where the quality of the generated responses is assessed and used to improve the system over time. This iterative process can involve fine-tuning the retriever, adjusting the LLM, or refining the retrieval and generation strategies.
Benefits of RAG Systems
RAG systems offer several advantages over traditional methods like fine-tuning language models. Fine-tuning involves adjusting a model’s parameters based on a specific dataset, which can be resource-intensive and limit the model’s ability to adapt to new information without additional retraining. In contrast, RAG systems offer:
- Dynamic Adaptation: RAG systems allow models to dynamically access and incorporate up-to-date information from external sources, avoiding the need for frequent retraining. This means that the model can remain relevant and accurate even as new information emerges.
- Broad Knowledge Access: By retrieving information from a wide array of sources, RAG systems can handle a broader range of topics and questions without requiring extensive modifications to the model itself.
- Efficiency: Leveraging external retrieval mechanisms can be more efficient than fine-tuning because it reduces the need for large-scale model updates and retraining, focusing instead on integrating current and relevant information into the response generation process.
Typical Workflow of a RAG System
A typical RAG system operates through the following workflow:

- Query Generation: The process begins with the generation of a query based on the user’s input or context. This query is crafted to elicit relevant information that will aid in crafting a response.
- Retrieval: The generated query is then used to search external databases or knowledge sources. The retrieval component identifies and fetches documents or data that are most relevant to the query.
- Context Generation: The retrieved documents are processed to create a coherent context. This context provides the necessary background and details that will inform the language model’s response.
- LLM Response: Finally, the language model uses the context generated from the retrieved documents to produce a response. This response is expected to be well-informed, relevant, and accurate, leveraging the latest information retrieved.

Key Challenges in Real-World RAG Systems
Let us now look into the key challenges in real-world systems. This is inspired by the famous paper “Seven Failure Points When Engineering a Retrieval Augmented Generation System” by Barnett et al. as depicted in the following figure. We will dive into each of these problems in more detail in the following section with practical solutions to tackle these challenges.
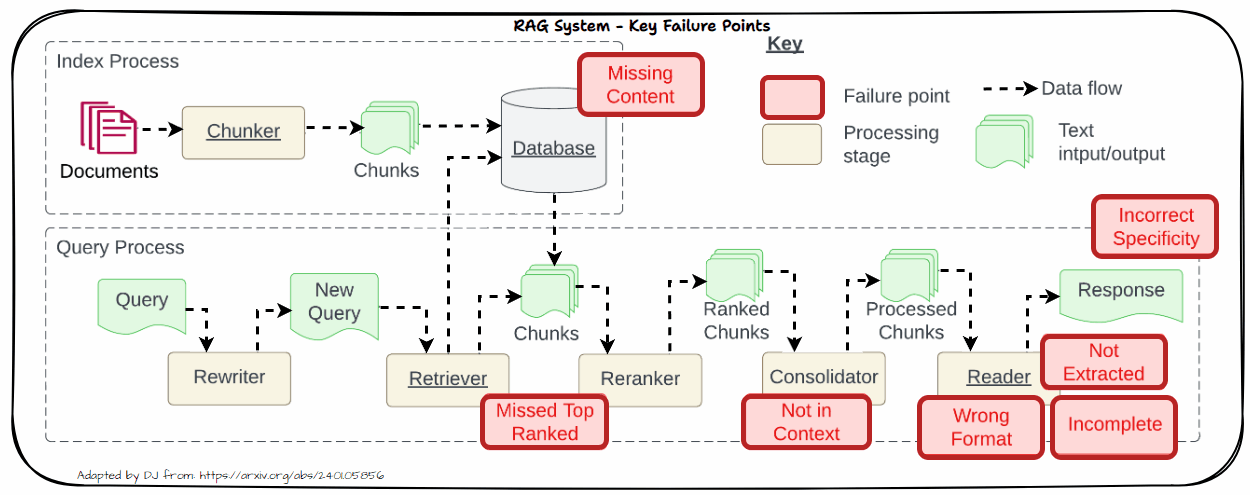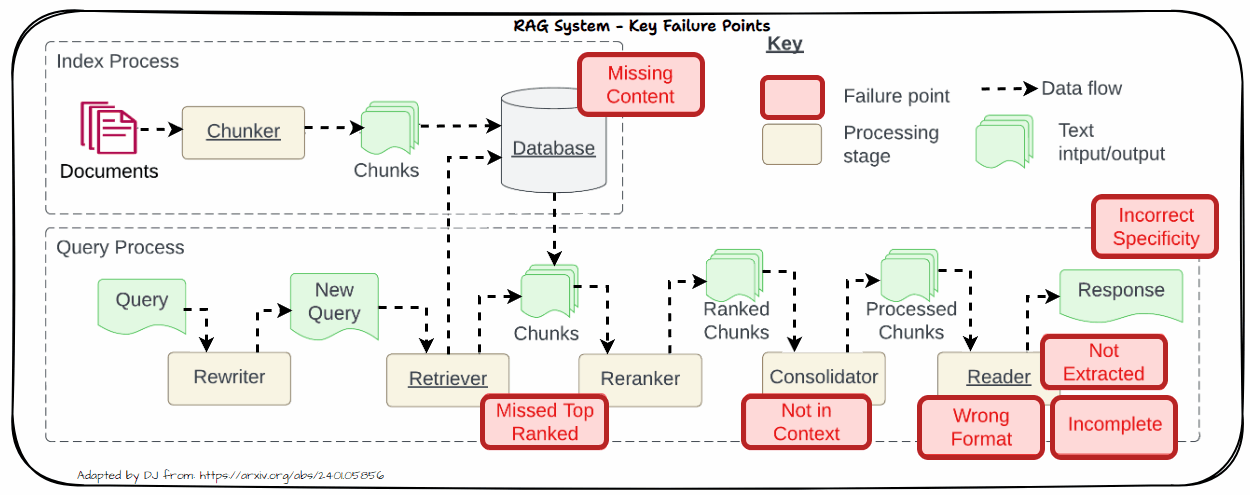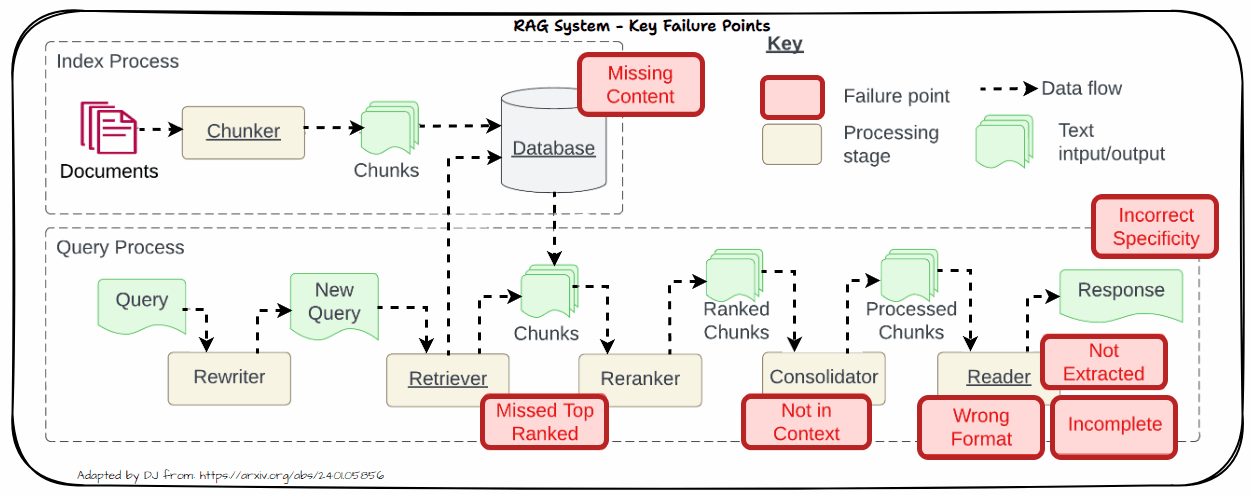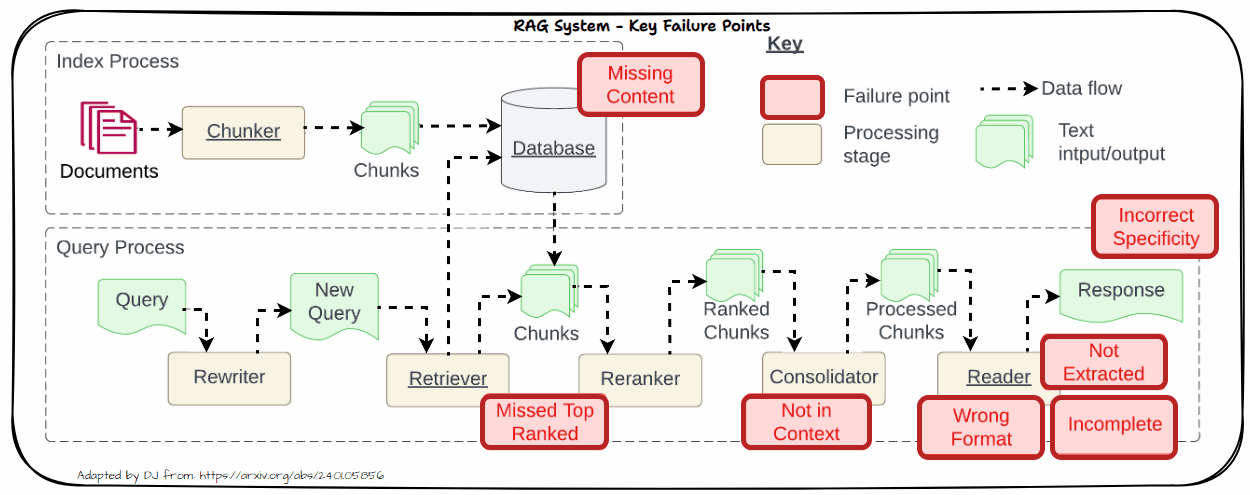
Missing Content
One significant challenge in RAG systems is dealing with missing content. This problem arises when the retrieved documents do not contain sufficient or relevant information to adequately address the user’s query. When relevant information is absent from the retrieved documents, it can lead to several issues like Impact on Accuracy and Relevance.

The absence of crucial content can severely impact the accuracy and relevance of the language model’s response. Without the necessary information, the model may generate answers that are incomplete, incorrect, or lack depth. This not only affects the quality of the responses but also diminishes the overall reliability of the RAG system.
Solutions for Missing Content

These are the approaches we can take to tackle challenges with missing content.
- Regularly updating and maintaining the knowledge base ensures that it contains accurate and comprehensive information. This can reduce the likelihood of missing content by providing the retrieval component with a richer set of documents.
- Crafting specific and assertive prompts with clear constraints can guide the language model to generate more precise and relevant responses. This helps in narrowing down the focus and improving the response’s accuracy.
- Implementing RAG systems with agentic capabilities allows the system to actively search and incorporate external sources of information. This approach helps address missing content by expanding the range of sources and improving the relevance of the retrieved data.
You can check out this notebook for more details with hands-on examples!
Missed Top Ranked
When documents that should be top-ranked fail to appear in the retrieval results, the system struggles to provide accurate responses. This problem, known as “Missed Top Ranked,” occurs when important context documents are not prioritized in the retrieval process. As a result, the model may not have access to crucial information needed to answer the question effectively.
Despite the presence of relevant documents, poor retrieval strategies can prevent these documents from being retrieved. Consequently, the model may generate responses that are incomplete or inaccurate due to the lack of critical context. Addressing this issue involves improving the retrieval strategy to ensure that the most relevant documents are identified and included in the context.

Not in Context
The “Not in Context” issue arises when documents containing the answer are present during the initial retrieval but do not make it into the final context used for generating a response. This problem often results from ineffective retrieval, reranking, or consolidation strategies. Despite the presence of relevant documents, flaws in these processes can prevent the documents from being included in the final context.
Consequently, the model may lack the necessary information to generate a precise and accurate answer. Improving retrieval algorithms, reranking methods, and consolidation techniques is essential to ensure that all pertinent documents are properly integrated into the context, thereby enhancing the quality of the generated responses.

Not Extracted
The “Not Extracted” issue occurs when the LLM struggles to extract the correct answer from the provided context, even though the answer is present. This problem arises when the context contains too much unnecessary information, noise, or contradictory details. The abundance of irrelevant or conflicting information can overwhelm the model, making it difficult to pinpoint the accurate answer.
To address this issue, it’s crucial to improve context management by reducing noise and ensuring that the information provided is relevant and consistent. This will help the LLM focus on extracting precise answers from the context.

Incorrect Specificity
When the output response is too vague and lacks detail or specificity, it often results from vague or generic queries that fail to retrieve the right context. Additionally, issues with chunking or poor retrieval strategies can exacerbate this problem. Vague queries might not provide enough direction for the retrieval system to fetch the most relevant documents, while improper chunking can dilute the context, making it challenging for the LLM to generate a detailed response. To address this, refine queries to be more specific and improve chunking and retrieval methods to ensure that the context provided is both relevant and comprehensive.

Solutions for Missed Top Ranked, Not in Context, Not Extracted and Incorrect Specificity
- Use Better Chunking Strategies
- Hyperparameter Tuning – Chunking & Retrieval
- Use Better Embedder Models
- Use Advanced Retrieval Strategies
- Use Context Compression Strategies
- Use Better Reranker Models
You can check out this notebook for more details with hands-on examples!
Experiment with various Chunking Strategies
You can explore and experiment with various chunking strategies in the given table:

Hyperparameter Tuning – Chunking & Retrieval
Hyperparameter tuning plays a critical role in optimizing RAG systems for better performance. Two key areas where hyperparameter tuning can make a significant impact are chunking and retrieval.

Chunking
In the context of RAG systems, chunking refers to the process of dividing large documents into smaller, more manageable segments. This allows the retriever to focus on more relevant sections of the document, improving the quality of the retrieved context. However, determining the optimal chunk size is a delicate balance—chunks that are too small might miss important context, while chunks that are too large might dilute relevance. Hyperparameter tuning helps in finding the right chunk size that maximizes retrieval accuracy without overwhelming the LLM.
Retrieval
The retrieval component involves several hyperparameters that can influence the effectiveness of the retrieval process. For instance, you can fine-tune the number of retrieved documents, the threshold for relevance scoring, and the embedding model used to improve the quality of the context provided to the LLM. Hyperparameter tuning in retrieval ensures that the system is consistently fetching the most relevant documents, thus enhancing the overall performance of the RAG system.
Better Embedder Models
Embedder models help in converting your text into vectors which are using during retrieval and search. Do not ignore embedder models as using the wrong one can cost your RAG System’s performance dearly.

Newer Embedder Models will be trained on more data and often better. Don’t just go by benchmarks, use and experiment on your data. Do not use commercial models if data privacy is important. There are a variety of embedder models available, do check out the Massive Text Embedding Benchmark (MTEB) leaderboard to get an idea of the potentially good and current embedder models out there.

Better Reranker Models
Rerankers are fine-tuned cross-encoder transformer models. These models take in a pair of documents (Query, Document) and return back a relevance score.

Models fine-tuned on more pairs and released recently will usually be better so do check out for the latest reranker models and experiment with them.
Advanced Retrieval Strategies
To address the limitations and pain points in traditional RAG systems, researchers and developers are increasingly implementing advanced retrieval strategies. These strategies aim to enhance the accuracy and relevance of the retrieved documents, thereby improving the overall system performance.
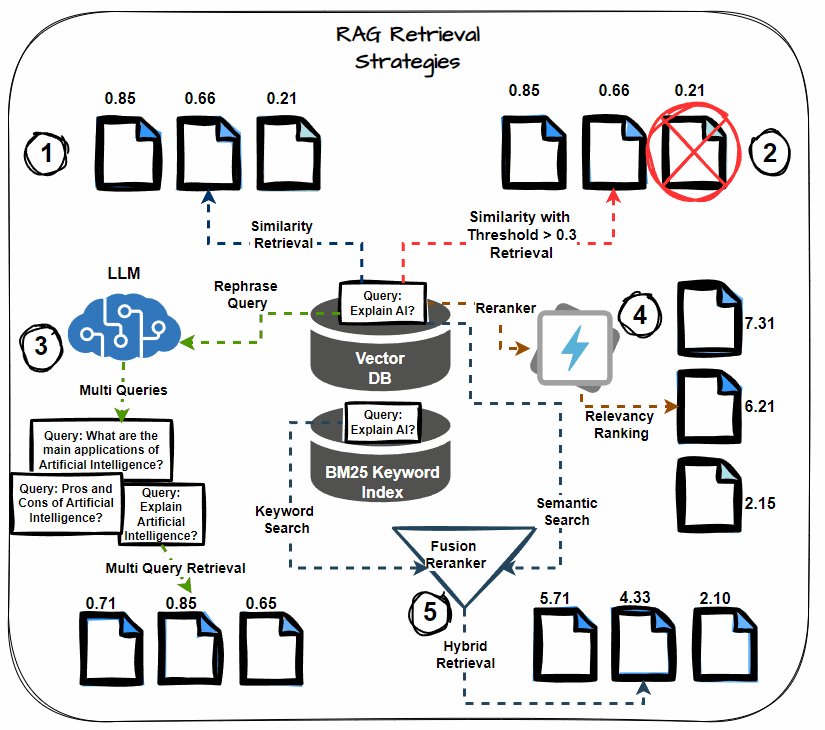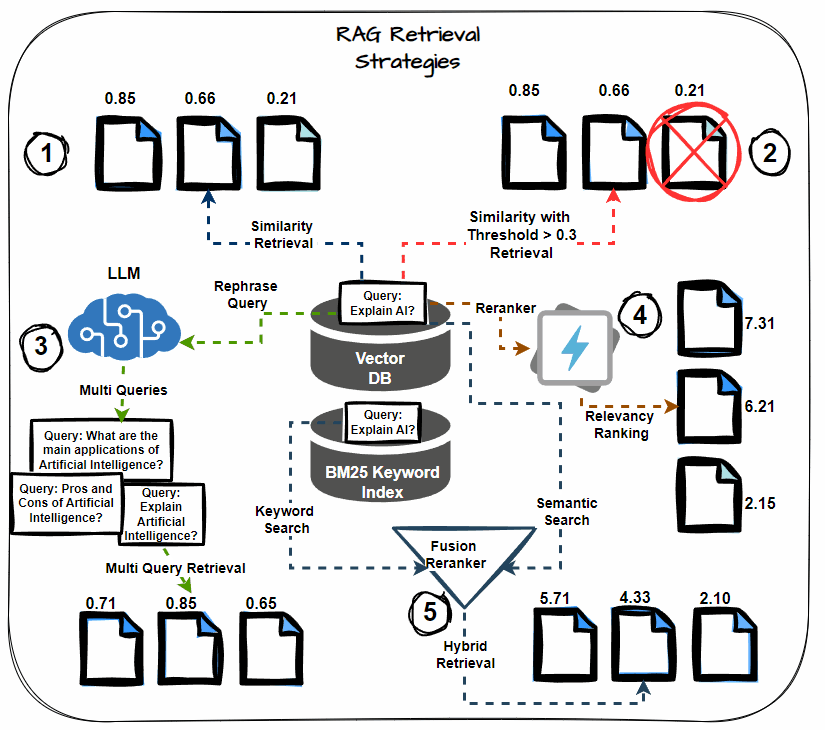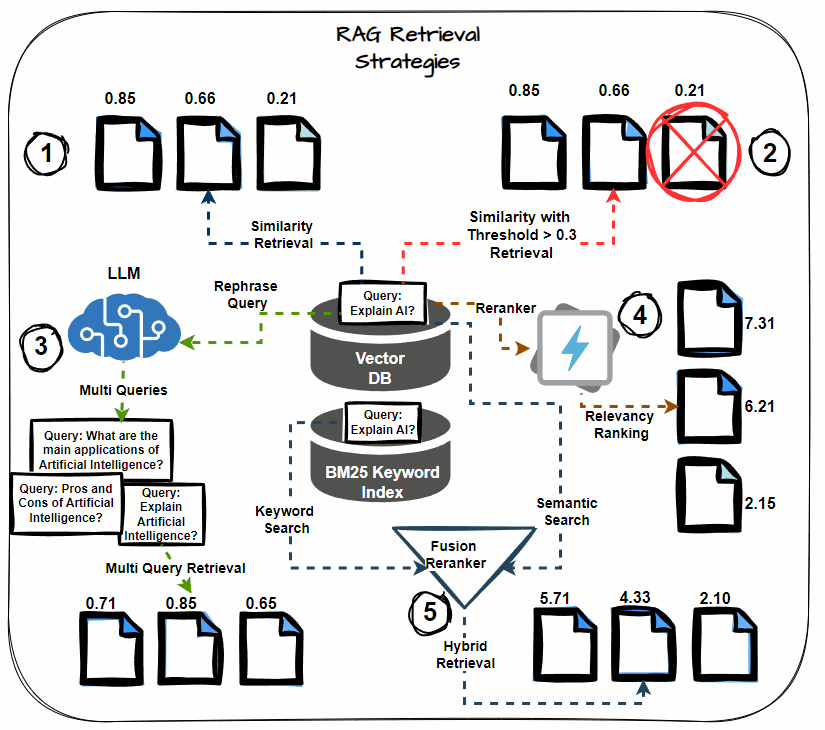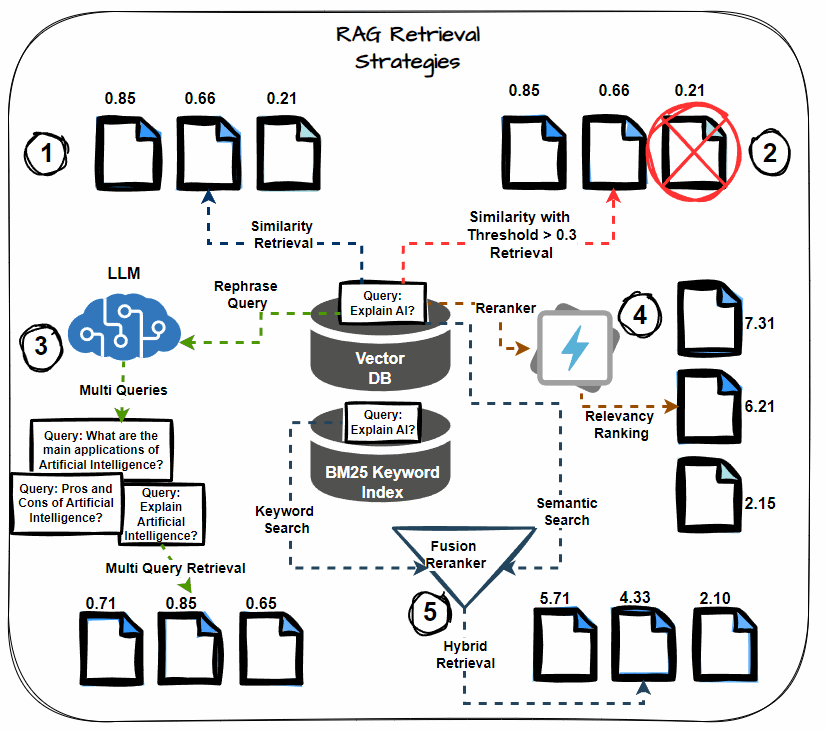
Semantic Similarity Thresholding
This technique involves setting a threshold for the semantic similarity score during the retrieval process. Consider only documents that exceed this threshold as relevant, including them in the context for LLM processing. Prioritize the most semantically relevant documents, reducing noise in the retrieved context.
Multi-query Retrieval
Instead of relying on a single query to retrieve documents, multi-query retrieval generates multiple variations of the query. Each variation targets different aspects of the information need, thereby increasing the likelihood of retrieving all relevant documents. This strategy helps mitigate the risk of missing critical information.
Hybrid Search (Keyword + Semantic)
A hybrid search approach combines keyword-based retrieval with semantic search. Keyword-based search retrieves documents containing specific terms, while semantic search captures documents contextually related to the query. This dual approach maximizes the chances of retrieving all relevant information.
Reranking
After retrieving the initial set of documents, apply reranking techniques to reorder them based on their relevance to the query. Use more sophisticated models or additional features to refine the order, ensuring that the most relevant documents receive higher priority.
Chained Retrieval
Chained retrieval breaks down the retrieval process into multiple stages, with each stage further refining the results. The initial retrieval fetches a broad set of documents. Then, subsequent stages refine these documents based on additional criteria, such as relevance or specificity. This method allows for more targeted and accurate document retrieval.
Context Compression Techniques
Context compression is a crucial technique for refining RAG systems. It ensures that the most relevant information is prioritized, leading to accurate and concise responses. In this section, we’ll explore two primary methods of context compression: prompt-based compression and filtering. We will also examine their impact on enhancing the performance of real-world RAG systems.

Prompt-Based Compression
Prompt-based compression involves using language models to identify and summarize the most relevant parts of retrieved documents. This technique aims to distill the essential information and present it in a concise format that is most useful for generating a response. Benefits of this approach include:
- Improved Relevance: By focusing on the most pertinent information, prompt-based compression enhances the relevance of the generated response.
- Limitations: However, this method may also have limitations, such as the risk of oversimplifying complex information or losing important nuances during summarization.
Filtering
Filtering involves removing entire documents from the context based on their relevance scores or other criteria. This technique helps manage the volume of information and ensure that only the most relevant documents are considered. Potential trade-offs include:
- Reduced Context Volume: Filtering can lead to a reduction in the amount of context available, which might affect the model’s ability to generate detailed responses.
- Increased Focus: On the other hand, filtering helps maintain focus on the most relevant information, improving the overall quality and relevance of the response.
Wrong Format
The “Wrong Format” problem occurs when an LLM fails to return a response in the specified format, such as JSON. This issue arises when the model deviates from the required structure, producing output that is improperly formatted or unusable. For instance, if you expect a JSON format but the LLM provides plain text or another format, it disrupts downstream processing and integration. This problem highlights the need for careful instruction and validation to ensure that the LLM’s output meets the specified formatting requirements.

Solutions for Wrong Format
- Powerful LLMs have native support for response formats e.g OpenAI supports JSON outputs.
- Better Prompting and Output Parsers
- Structured Output Frameworks
You can check out this notebook for more details with hands-on examples!
For example models like GPT-4o have native output parsing support like JSON which you can enable as shown in the following code snapshot.

Incomplete
The “Incomplete” problem arises when the generated response lacks critical information, making it incomplete. This issue often results from poorly worded questions that do not clearly convey the required information, inadequate context retrieved for the response, or ineffective reasoning by the model.
Incomplete responses can stem from a variety of sources, including ambiguous queries that fail to specify the necessary details, retrieval mechanisms that do not fetch comprehensive information, or reasoning processes that miss key elements. Addressing this problem involves refining question formulation, improving context retrieval strategies, and enhancing the model’s reasoning capabilities to ensure that responses are both complete and informative.

Solution for Incomplete
- Use Better LLMs like GPT-4o, Claude 3.5 or Gemini 1.5
- Use Advanced Prompting Techniques like Chain-of-Thought, Self-Consistency
- Build Agentic Systems with Tool Use if necessary
- Rewrite User Query and Improve Retrieval – HyDE
HyDE is an interesting approach where the idea is to generate a Hypothetical answer to the given question which may not be factually totally correct but would have relevant text elements which can help retrieve the more relevant documents from the vector database as compared to retrieving using just the question as depicted in the following workflow.

Other Enhancements from Recent Research Papers
Let us now look onto few enhancements from recent research papers which have actually worked.
RAG vs. Long Context LLMs
Long-context LLMs often deliver superior performance compared to Retrieval-Augmented Generation (RAG) systems due to their ability to handle really long documents and generate detailed responses without worrying about all the data pre-processing needed for RAG systems. However, they come with high computing and cost demands, making them less practical for some applications. A hybrid approach offers a solution by leveraging the strengths of both models. In this strategy, you first use a RAG system to provide a response based on the retrieved context. Then, you can employ a long-context LLM to review and refine the RAG-generated answer if needed. This method allows you to balance efficiency and cost while ensuring high-quality, detailed responses when necessary as mentioned in the paper, Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach, Zhuowan Li et al.

RAG vs Long Context LLMs – Self-Router RAG
Let’s look at a practical workflow of how to implement the solution proposed in the above paper. In a standard RAG flow, the process begins with retrieving context documents from a vector database based on a user query. The RAG system then uses these documents to generate an answer while adhering to the provided information. If the answerability of the query is uncertain, an LLM judge prompt determines if the query is answerable or unanswerable based on the context. For cases where the query cannot be answered satisfactorily with the retrieved context, the system employs a long-context LLM. This LLM uses the complete context documents to provide a detailed response, ensuring that the answer is based solely on the provided information.

Agentic Corrective RAG
Agentic Corrective RAG draws inspiration from the paper, Corrective Retrieval Augmented Generation, Shi-Qi Yan et al. where the idea is to first do a normal retrieval from a vector database for your context documents based on a user query. Then instead of the standard RAG flow, we assess how relevant are the retrieved documents to answer the user query using an LLM-as-Judge flow and if there are some irrelevant documents or no relevant documents, we do a web search to get live information from the web for the user query before following the normal RAG flow as depicted in the following figure.

First, retrieve context documents from the vector database based on the input query. Then, use an LLM to assess the relevance of these documents to the question. If all documents are relevant, proceed without further action. If some documents are ambiguous or incorrect, rephrase the query and search the web for better context. Finally, send the rephrased query along with the updated context to the LLM for generating the response. This is shown in detail in the following practical workflow illustration.

Agentic Self-Reflection RAG
Agentic Self-Reflection RAG (SELF-RAG) introduces a novel approach that enhances large language models (LLMs) by integrating retrieval with self-reflection. This framework allows LLMs to dynamically retrieve relevant passages and reflect on their own responses using special reflection tokens, improving accuracy and adaptability. Experiments demonstrate that SELF-RAG surpasses traditional models like ChatGPT and Llama2-chat in tasks such as open-domain QA and fact verification, significantly boosting factuality and citation precision. This was proposed in the paper Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection, Akari Asai et al.

A practical implementation of this workflow is depicted in the following illustration where we do a normal RAG retrieval, then use an LLM-as-Judge grader to assess document relevant, do web searches or query rewriting and retrieval if needed to get more relevant context documents. The next step involves generating the response and again using LLM-as-Judge to reflect on the generated answer and make sure it answers the question and is not having any hallucinations.

Conclusion
Improving real-world RAG systems requires addressing several key challenges, including missing content, retrieval problems, and response generation issues. Implementing practical solutions, such as enriching the knowledge base and employing advanced retrieval techniques, can significantly enhance the performance of RAG systems. Additionally, refining context compression methods further contributes to improving system effectiveness. Continuous improvement and adaptation are crucial as these systems evolve to meet the growing demands of various applications. Key takeaways from the talk can be summarized in the following figure.

Future research and development efforts should focus on improving retrieval systems, explore the above mentioned methodologies. Additionally, exploring new approaches like Agentic AI can help optimize RAG systems for even greater efficiency and accuracy.
You can also refer to the GitHub link to know more.
Frequently Asked Questions
Q1. What are Retrieval-Augmented Generation (RAG) systems?
A. RAG systems combine retrieval mechanisms with large language models to generate responses based on external data.
Q2. What is the main benefit of using RAG systems?
A. They allow models to dynamically incorporate up-to-date information from external sources without frequent retraining.
Q3. What are common challenges in RAG systems?
A. Common challenges include missing content, retrieval problems, response specificity, context overload, and system latency.
Q4. How can missing content issues be addressed in RAG systems?
A. Solutions include better data cleaning, assertive prompting, and leveraging agentic RAG systems for live information.
Q5. What are some advanced retrieval strategies for RAG systems?
A. Strategies include semantic similarity thresholding, multi-query retrieval, hybrid search, reranking, and chained retrieval.
My name is Ayushi Trivedi. I am a B. Tech graduate. I have 3 years of experience working as an educator and content editor. I have worked with various python libraries, like numpy, pandas, seaborn, matplotlib, scikit, imblearn, linear regression and many more. I am also an author. My first book named #turning25 has been published and is available on amazon and flipkart. Here, I am technical content editor at Analytics Vidhya. I feel proud and happy to be AVian. I have a great team to work with. I love building the bridge between the technology and the learner.





