Introduction
The newest model collection from Microsoft’s Small Language Models (SLMs) family is called Phi-3. They surpass models of comparable and greater sizes on a variety of benchmarks in language, reasoning, coding, and math. They are made to be extremely powerful and economical. With Phi-3 models available, Azure clients have access to a wider range of excellent models, providing them with more useful options for creating and developing generative AI applications. Since the April 2024 launch, Azure has gathered a wealth of insightful input from users and community members regarding areas where the Phi-3 SLMs could use improvement.
They are now pleased to present Phi-3.5 SLMs – Phi-3.5-mini, Phi-3.5-vision, and Phi-3.5-MoE, a Mixture-of-Experts (MoE) model, as the newest members of the Phi family. Phi-3.5-mini adds a 128K context length to improve multilingual support. Phi-3.5-vision enhances the comprehension and reasoning of multi-frame images, improving performance on single-image benchmarks. Phi-3.5-MoE surpasses larger models while maintaining the efficacy of Phi models with its 16 experts, 6.6B active parameters, low latency, multilingual support, and strong safety features.

Table of contents
Phi-3.5-MoE: Mixture-of-Experts
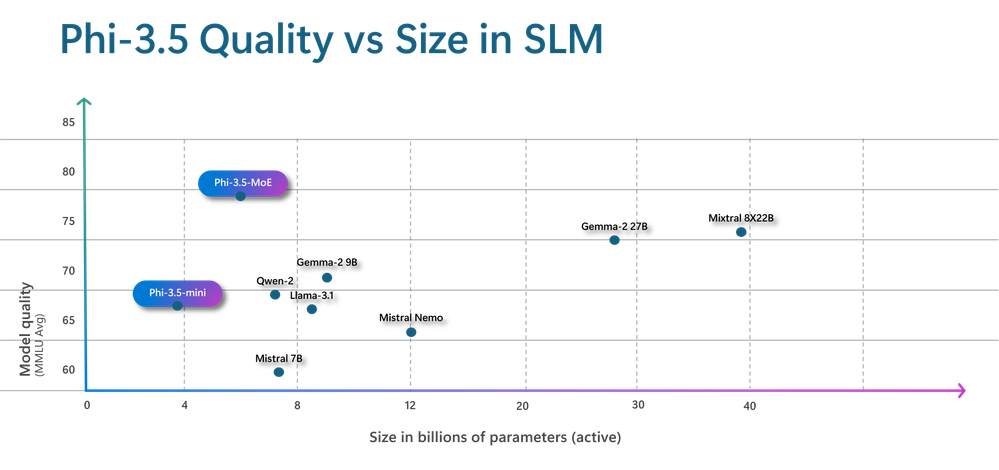
Phi-3.5-MoE is the largest and latest model among the latest Phi 3.5 SLMs releases. It comprises 16 experts, each containing 3.8B parameters. With a total model size of 42B parameters, it activates 6.6B parameters using two experts. This MoE model performs better than a dense model of a comparable size regarding quality and performance. More than 20 languages are supported. The MoE model, like its Phi-3 counterparts, uses a combination of proprietary and open-source synthetic instruction and preference datasets in its robust safety post-training technique. Using synthetic and human-labeled datasets, our post-training procedure combines Direct Preference Optimisation (DPO) with Supervised Fine-Tuning (SFT). These comprise several safety categories and datasets emphasizing harmlessness and helpfulness. Moreover, Phi-3.5-MoE can support a context length of up to 128K, which makes it capable of handling a variety of long-context workloads.
Also read: Microsoft Phi-3: From Language to Vision, this New AI Model is Transforming AI
Training Data of Phi 3.5 MoE
Training data of Phi 3.5 MoE includes a wide variety of sources, totaling 4.9 trillion tokens (including 10% multilingual), and is a combination of:
- Publicly available documents filtered rigorously for quality selected high-quality educational data and code;
- Newly created synthetic, “textbook-like” data to teach math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
- High-quality chat format supervised data covering various topics to reflect human preferences, such as instruct-following, truthfulness, honesty, and helpfulness.
Azure focuses on the quality of data that could potentially improve the model’s reasoning ability, and it filters the publicly available documents to contain the correct level of knowledge. For example, the result of a game in the Premier League on a particular day might be good training data for frontier models, but it needed to remove such information to leave more model capacity for reasoning for small-size models. More details about data can be found in the Phi-3 Technical Report.
Phi 3.5 MoE training takes 23 days and uses 4.9T tokens of training data. The supported languages are Arabic, Chinese, Czech, Danish, Dutch, English, Finnish, French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, Swedish, Thai, Turkish, and Ukrainian.
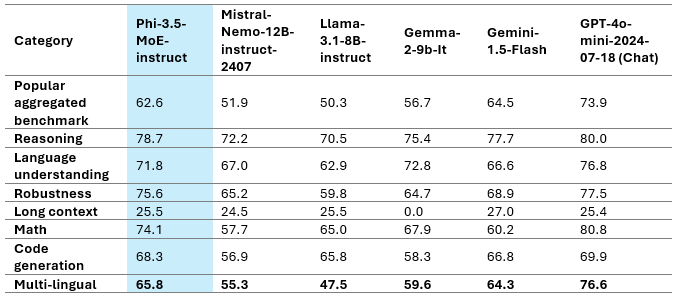
The above table represents Phi-3.5-MoE Model Quality on various capabilities. We can see that Phi 3.5 MoE is performing better than some larger models in various categories. Phi-3.5-MoE with only 6.6B active parameters achieves a similar level of language understanding and math as much larger models. Moreover, the model outperforms bigger models in reasoning capability. The model provides good capacity for finetuning for various tasks.
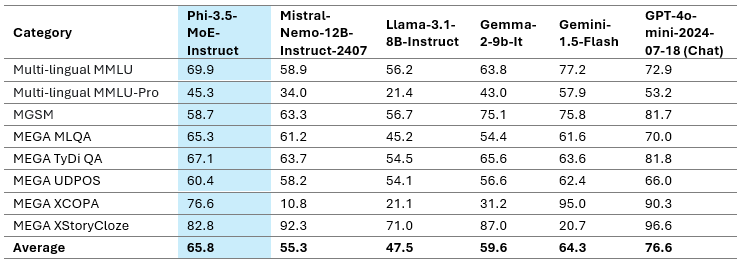
The multilingual MMLU, MEGA, and multilingual MMLU-pro datasets are used in the above table to demonstrate the Phi-3.5-MoE’s multilingual capacity. We found that the model outperforms competing models with substantially larger active parameters on multilingual tasks, even with only 6.6B active parameters.
Phi-3.5-mini
The Phi-3.5-mini model underwent additional pre-training using multilingual synthetic and high-quality filtered data. Subsequent post-training procedures, such as Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and Supervised Fine-Tuning (SFT), were then carried out. These procedures used synthetic, translated, and human-labeled datasets.
Training Data of Phi 3.5 Mini
Training data of Phi 3.5 Mini includes a wide variety of sources, totaling 3.4 trillion tokens, and is a combination of:
- Publicly available documents filtered rigorously for quality selected high-quality educational data and code;
- Newly created synthetic, “textbook-like” data to teach math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
- High-quality chat format supervised data covering various topics to reflect human preferences, such as instruct-following, truthfulness, honesty, and helpfulness.
Model Quality
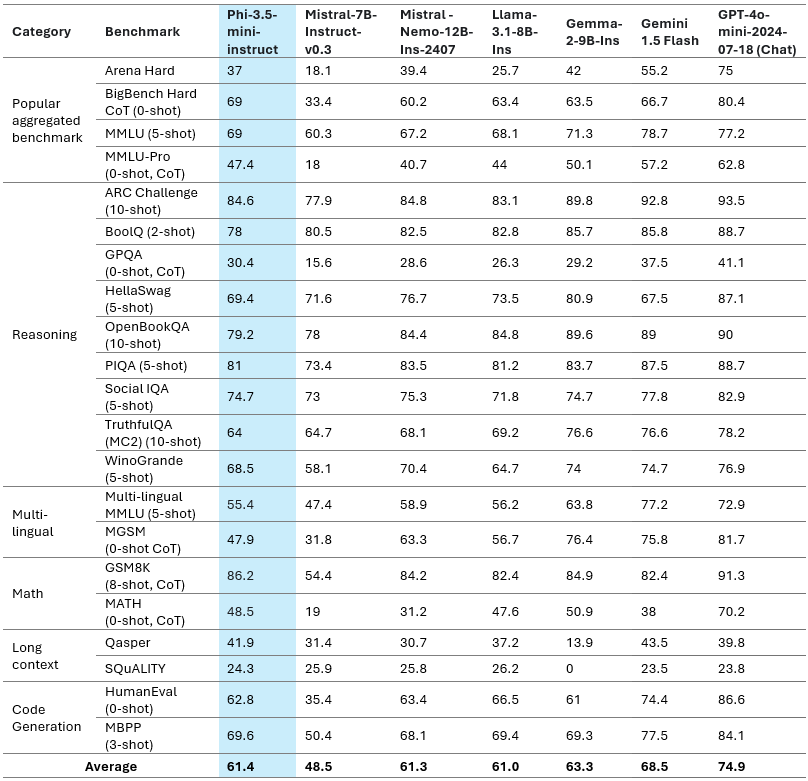
The above table gives a quick overview of the model quality on important benchmarks. This effective model meets, if not outperforms, other models with greater sizes despite having a compact size of only 3.8B parameters.
Also read: Microsoft Phi 3 Mini: The Tiny Model That Runs on Your Phone
Multi-lingual Capability
Our newest update to the 3.8B model is Phi-3.5-mini. The model significantly improved multilingualism, multiturn conversation quality, and reasoning capacity by incorporating additional continuous pre-training and post-training data.
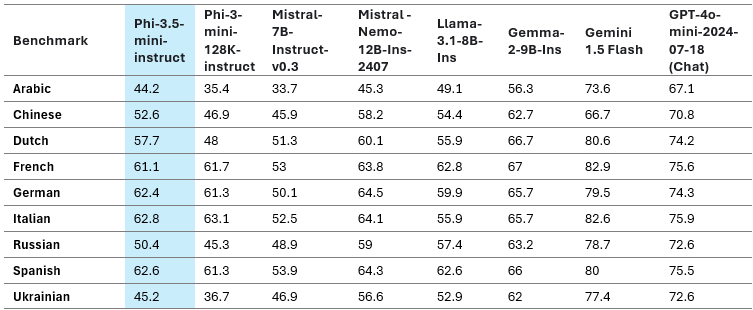
Multilingual support is a major advance over Phi-3-mini with Phi-3.5-mini. With 25–50% performance improvements, Arabic, Dutch, Finnish, Polish, Thai, and Ukrainian languages benefited the most from the new Phi 3.5 mini. Viewed in a broader context, Phi-3.5-mini demonstrates the best performance of any sub-8B model in multiple languages, including English. It should be noted that while the model has been optimized for higher resource languages and employs 32K vocabulary, it is not advised to use it for lower resource languages without additional fine-tuning.
Long Context

With a 128K context length support, Phi-3.5-mini is an excellent choice for applications like information retrieval, long document-based quality assurance, and summarising lengthy documents or meeting transcripts. Compared to the Gemma-2 family, which can only handle an 8K context length, Phi-3.5 performs better. Furthermore, Phi-3.5-mini has stiff competition from considerably larger open-weight models like Mistral-7B-instruct-v0.3, Llama-3.1-8B-instruct, and Mistral-Nemo-12B-instruct-2407. Phi-3.5-mini-instruct is the only model in this category, with just 3.8B parameters, 128K context length, and multi-lingual support. It’s important to note that Azure chose to support more languages while keeping English performance consistent for various tasks. Due to the model’s restricted capability, English knowledge may be superior to other languages. Azure suggests utilizing the model in the RAG setup for tasks requiring a high level of multilingual understanding.
Also read: Phi 3 – Small Yet Powerful Models from Microsoft
Phi-3.5-vision with Multi-frame Input
Training Data of 3.5 Vision
Azure’s training data includes a wide variety of sources and is a combination of:
- Publicly available documents filtered rigorously for quality selected high-quality educational data and code;
- Selected high-quality image-text interleave data;
- Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.), newly created image data, e.g., chart/table/diagram/slides, newly created multi-image and video data, e.g., short video clips/pair of two similar images;
- High-quality chat format supervised data covering various topics to reflect human preferences, such as instruct-following, truthfulness, honesty, and helpfulness.
The data collection process involved sourcing information from publicly available documents and meticulously filtering out undesirable documents and images. To safeguard privacy, we carefully filtered various image and text data sources to remove or scrub any potentially personal data from the training data.
Phi-3.5-vision delivers state-of-the-art multi-frame image understanding and reasoning capabilities thanks to essential user feedback. With a wide range of applications across multiple contexts, this breakthrough enables precise picture comparison, multi-image summarization/storytelling, and video summarisation.
Surprisingly, Phi-3.5-vision has shown notable gains in performance across multiple single-image benchmarks. For instance, it increased the MMBench performance from 80.5 to 81.9 and the MMMU performance from 40.4 to 43.0. Furthermore, the standard for document comprehension, TextVQA, increased from 70.9 to 72.0.
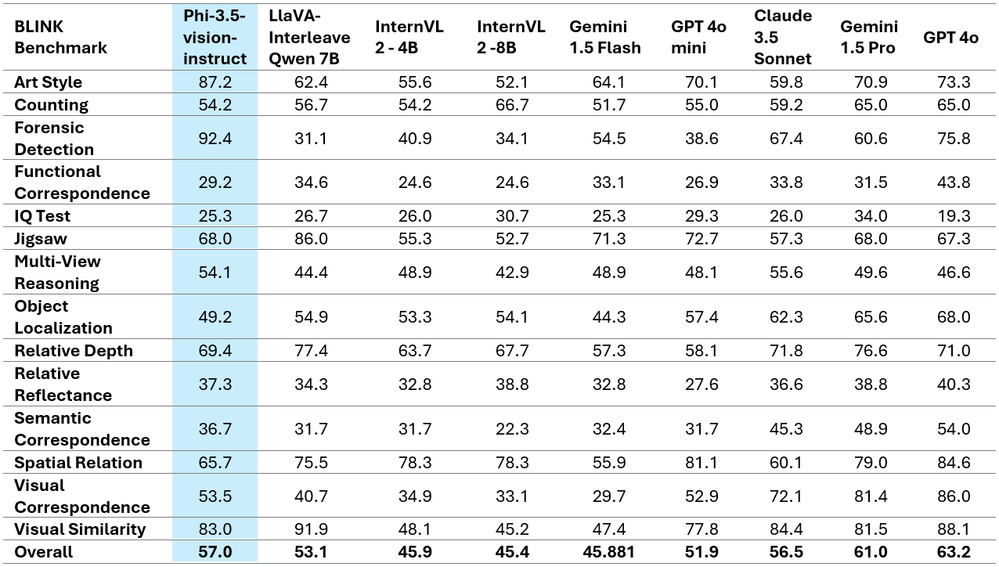
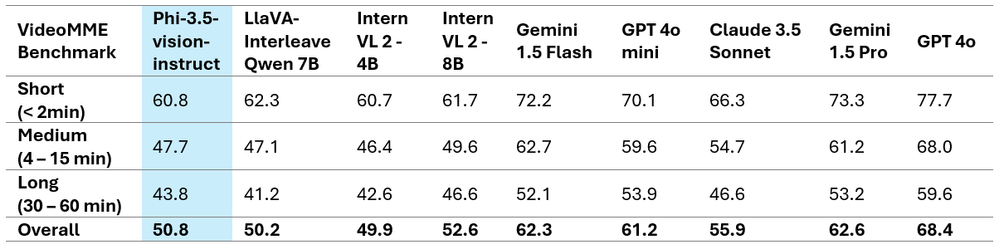
The tables above showcase the improved performance metrics and present the comprehensive comparative findings on two well-known multi-image/video benchmarks. It is important to note that Phi-3.5-Vision does not support multilingual use cases. Without additional fine-tuning, it is recommended against using it for multilingual scenarios.
Trying out Phi 3.5 Mini
Using Hugging Face
We will use kaggle notebook to implement Phi 3.5 Mini as it accommodates the Phi 3.5 mini model better than Google Colab. Note: Make sure to enable the accelerator to GPU T4x2.
1st Step: Importing necessary libraries
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)2nd Step: Loading the Model and Tokenizer
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3.5-mini-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3.5-mini-instruct")3rd Step: Preparing messages
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Tell me about microsoft"},
]“role”: “system”: Sets the behavior of the AI model (in this case, as a “helpful AI assistant”
“role”: “user”: Represents the user’s input.
Step 4: Creating the Pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)This creates a pipeline for text generation using the specified model and tokenizer. The pipeline abstracts the complexities of tokenization, model execution, and decoding, providing an easy interface for generating text.
Step 5: Setting Generation Arguments
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}These arguments control how the model generates text.
- max_new_tokens=500: The maximum number of tokens to generate.
- return_full_text=False: Only the generated text (not the input) will be returned.
- temperature=0.0: Controls randomness in the output. A value of 0.0 makes the model deterministic, producing the most likely output.
- do_sample=False: Disables sampling, making the model always choose the most probable next token.
Step 6: Generating Text
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
Using Azure AI Studio
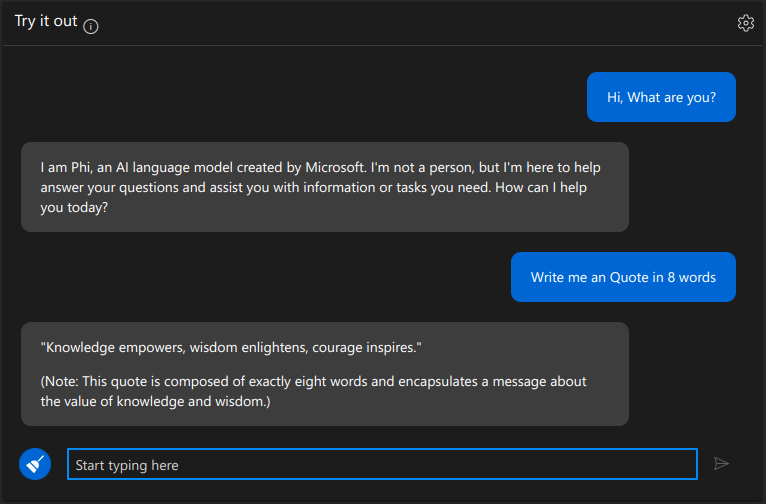
We can try Phi 3.5 Mini Instruct in Azure AI Studio using their Interface. There is a section called “Try it out” in the Azure AI Studio. Below is a snapshot of using Phi 3.5 Mini.
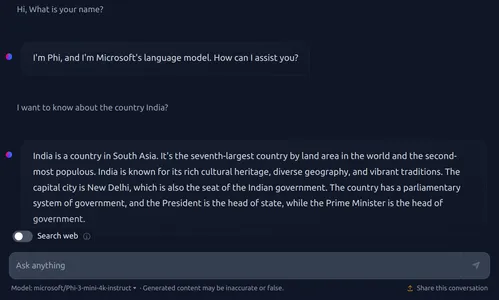
Using HuggingChat from Hugging Face
Here is the HuggingChat Link.
Trying Phi 3.5 Vision
Using Spaces from Hugging Face
Since Phi 3.5 Vision is a GPU-intensive model, we cannot use the model with a free tier of colab and kaggle. Hence, I have used hugging face spaces to try Phi 3.5 Vision.
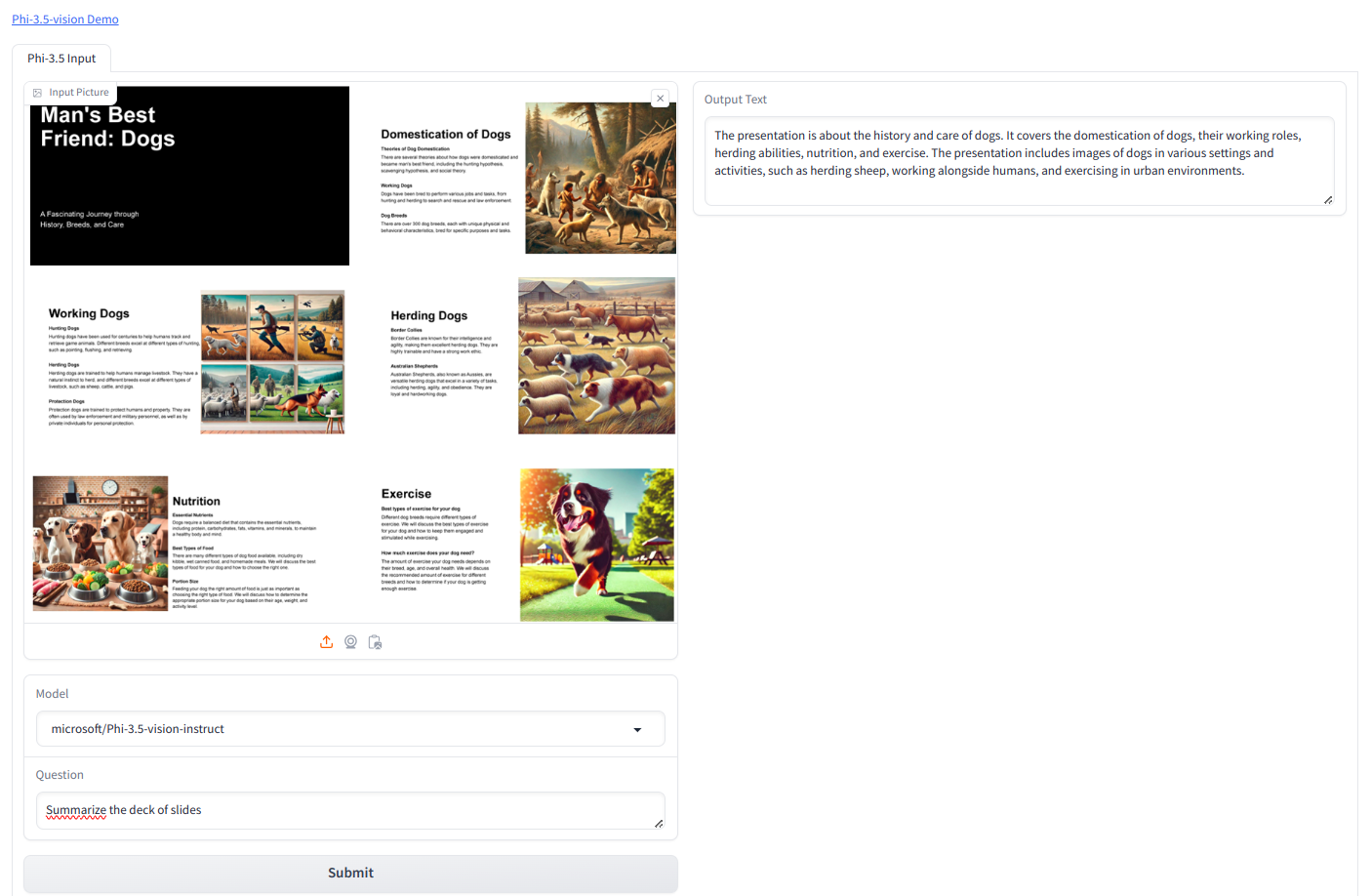
We will be using the below image.

Prompt we used is “Summarize the deck of slides”
Output
The presentation is about the history and care of dogs. It covers the domestication of dogs, their working roles, herding abilities, nutrition, and exercise. The presentation includes images of dogs in various settings and activities, such as herding sheep, working alongside humans, and exercising in urban environments.
Conclusion
The Phi-3.5-mini is a unique LLM with 3.8B parameters, 128K context length, and multi-lingual support. It balances broad language support with English knowledge density. It’s best used in a Retrieval-Augmented Generation setup for multilingual tasks. The Phi-3.5-MoE has 16 small experts, delivers high-quality performance, reduces latency, and supports 128k context length and multiple languages. It can be customized for various applications and has 6.6B active parameters. The Phi-3.5-vision enhances single-image benchmark performance. The Phi-3.5 SLMs family offers cost-effective, high-capability options for the open-source community and Azure customers.
If you are looking for a Generative AI course online, then explore today – GenAI Pinnacle Program
Frequently Asked Questions
Q1. What are the Phi-3.5 models?
Ans. Phi-3.5 models are the latest in Microsoft’s Small Language Models (SLMs) family, designed for high performance and efficiency in language, reasoning, coding, and math tasks.
Q2. What is Phi-3.5-MoE?
Ans. Phi-3.5-MoE is a Mixture-of-Experts model with 16 experts, supporting 20+ languages, 128K context length, and designed to outperform larger models in reasoning and multilingual tasks.
Q3. What makes Phi-3.5-mini unique?
Ans. Phi-3.5-mini is a compact model with 3.8B parameters, 128K context length, and improved multilingual support. It excels in English and several other languages.
Q4. Where can I try the Phi-3.5 SLMs?
Ans. You can try Phi-3.5 SLMs on platforms like Hugging Face and Azure AI Studio, where they are available for various AI applications.
Data science Trainee at Analytics Vidhya, specializing in ML, DL and Gen AI. Dedicated to sharing insights through articles on these subjects. Eager to learn and contribute to the field's advancements. Passionate about leveraging data to solve complex problems and drive innovation.





