Introduction
When attending a job interview or hiring for a large company, reviewing every CV in detail is often impractical due to the high volume of applicants. Instead, leveraging CV data extraction to focus on how well key job requirements align with a candidate’s CV can lead to a successful match for both the employer and the candidate.
Imagine having your profile label checked—no need to worry! It’s now easy to assess your fit for a position and identify any gaps in your qualifications relative to job requirements.
For example, if a job posting highlights experience in project management and proficiency in a specific software, the candidate should ensure these skills are clearly visible on their CV. This targeted approach helps hiring managers quickly identify qualified applicants and ensures the candidate is considered for positions where they can thrive.
By emphasizing the most relevant qualifications, the hiring process becomes more efficient, and both parties can benefit from a good fit. The company finds the right talent more quickly, and the candidate is more likely to land a role that matches their skills and experience.
Learning Outcomes
- Understand the importance of data extraction from CVs for automation and analysis.
- Gain proficiency in using Python libraries for text extraction from various file formats.
- Learn how to preprocess images to enhance text extraction accuracy.
- Explore techniques for handling case sensitivity and normalizing tokens in extracted text.
- Identify key tools and libraries essential for effective CV data extraction.
- Develop practical skills in extracting text from both images and PDF files.
- Recognize the challenges involved in CV data extraction and effective solutions.
This article was published as a part of the Data Science Blogathon.
Table of contents
Essential Tools for CV Data Extraction
To effectively extract data from resumes and CVs, leveraging the right tools is essential for streamlining the process and ensuring accuracy. This section will highlight key libraries and technologies that enhance the efficiency of CV data extraction, enabling better analysis and insights from candidate profiles.
Python
It has a library or method that can split sentences or paragraph into words. In Python, you can achieve word tokenization using different libraries and methods, such as split() (basic tokenization) or the Natural Language Toolkit (NLTK) and spaCy libraries for more advanced tokenization.
Simple tokenization( split of sentences) don’t recognize punctuations and other special characters.
sentences="Today is a beautiful day!."
sentences.split()
['Today', 'is', 'a', 'beautiful', 'day!.']Libraries: NLTK and SpaCy
Python has more powerful tool for tokenization (Natural Language Toolkit (NLTK).
In NLTK (Natural Language Toolkit), the punkt tokenizer actively tokenizes text by using a pre-trained model for unsupervised sentence splitting and word tokenization.
import nltk
nltk.download('punkt')
from nltk import word_tokenize
sentences="Today is a beautiful day!."
sentences.split()
print(sentences)
words= word_tokenize(sentences)
print(words)
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\ss529\AppData\Roaming\nltk_data...
Today is a beautiful day!.
['Today', 'is', 'a', 'beautiful', 'day', '!', '.']
[nltk_data] Package punkt is already up-to-date!Key Features of punkt:
- It can tokenize a given text into sentences and words without needing any prior information about the language’s grammar or syntax.
- It uses machine learning models to detect sentence boundaries, which is useful in languages where punctuation doesn’t strictly separate sentences.
SpaCy is advanced NLP library that gives accurate tokenization and other language processing features.
Regular Expressions: Custom tokenization based on patterns, but requires manual set.
import re
regular= "[A-za-z]+[\W]?"
re.findall(regular, sentences)
['Today ', 'is ', 'a ', 'beautiful ', 'day!']Pytesseract
It is a python based optical character recognition tool used for reading text in images.
Pillow Library
An open-source library for handling various image formats, useful for image manipulation.
Images or PDF Files
Resumes may be in PDF or image formats.
PDFPlumber or PyPDF2
To extract text from a PDF and tokenize it into words, you can follow these steps in Python:
- Extract text from a PDF using a library like PyPDF2 or pdfplumber.
- Tokenize the extracted text using any tokenization method, such as split(), NLTK, or spaCy.
Getting Words from PDF Files or Images
For pdf files we will need Pdf Plumber and for images OCR.
If you want to extract text from an image (instead of a PDF) and then tokenize and score based on predefined words for different fields, you can achieve this by following these steps:
Install pytesseract OCR Machine.
It will help to extract text from images
pip install pytesseract Pillow nltkInstall library Pillow
It will help to handle various images.
When it comes to image processing and manipulation in Python—such as resizing, cropping, or converting between different formats—the open-source library that often comes to mind is Pillow.
Let’s see how the pillow works, to see the image in Jupyter Notebook I have to use the display and inside brackets have to store the variable holding the image.
from PIL import Image
image = Image.open('art.jfif')
display(image)
To resize and save the image, the resize and saved method is used, the width is set to 400 and the height to 450.
Key Features of Pillow:
- Image Formats- Support different formats
- Image Manipulation Functions – One can resize, crop images, convert color images to gray, etc.
Install nltk for tokenization (or spaCy)
Discover how to enhance your text processing capabilities by installing NLTK or spaCy, two powerful libraries for tokenization in natural language processing.
Download Tesseract and Configure Path
Learn how to download Tesseract from GitHub and seamlessly integrate it into your script by adding the necessary path for optimized OCR functionality.
pytesseract.pytesseract.tesseract_cmd = 'C:\Program Files\Tesseract-OCR\tesseract.exe''- macOS: brew install tesseract
- Linux: Install via package manager (e.g., sudo apt install tesseract-ocr).
- pip install pytesseract Pillow
There are several tools among them one is the Google-developed, open-source library Tesseract which has supported many languages and OCR.
Pytesseract is used for Python-based projects, that act as a wrapper for Tesseract OCR engine.
Image and PDF Text Extraction Techniques
In the digital age, extracting text from images and PDF files has become essential for various applications, including data analysis and document processing. This article explores effective techniques for preprocessing images and leveraging powerful libraries to enhance optical character recognition (OCR) and streamline text extraction from diverse file formats.
Preprocessing Images for Enhanced OCR Performance
Preprocessing images can improve the OCR performance by following the steps mentioned below.
- Images to Grayscale: Images are converted into grayscale to reduce noisy background and have a firm focus on the text itself, and is useful for images with varying lighting conditions.
- from PIL import ImageOps
- image = ImageOps.grayscale(image)
- Thresholding : Apply binary thresholding to make the text stand out by converting the image into a black-and-white format.
- Resizing : Upscale smaller images for better text recognition.
- Noise Removal : Remove noise or artifacts in the image using filters (e.g., Gaussian blur).
import nltk
import pytesseract
from PIL import Image
import cv2
from nltk.tokenize import word_tokenize
nltk.download('punkt')
pytesseract.pytesseract.tesseract_cmd = r'C:\Users\ss529\anaconda3\Tesseract-OCR\tesseract.exe'
image = input("Name of the file: ")
imag=cv2.imread(image)
#convert to grayscale image
gray=cv2.cvtColor(images, cv2.COLOR_BGR2GRAY)
from nltk.tokenize import word_tokenize
def text_from_image(image):
img = Image.open(imag)
text = pytesseract.image_to_string(img)
return text
image = 'CV1.png'
text1 = text_from_image(image)
# Tokenize the extracted text
tokens = word_tokenize(text1)
print(tokens)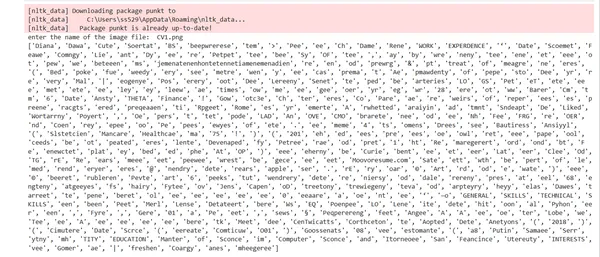
To know how many words match the requirements we will compare and give points to every matching word as 10.
# Comparing tokens with specific words, ignore duplicates, and calculate score
def compare_tokens_and_score(tokens, specific_words, score_per_match=10):
match_words = set(word.lower() for word in tokens if word.lower() in specific_words)
total_score = len(fields_keywords) * score_per_match
return total_score
# Fields with differents skills
fields_keywords = {
"Data_Science_Carrier": { 'supervised machine learning', 'Unsupervised machine learning', 'data','analysis', 'statistics','Python'},
}
# Score based on specific words for that field
def process_image_for_field(image, field):
if field not in fields_keywords:
print(f"Field '{field}' is not defined.")
return
# Extract text from the image
text = text_from_image(image)
# Tokenize the extracted text
tokens = tokenize_text(text)
# Compare tokens with specific words for the selected field
specific_words = fields_keywords[field]
total_score = compare_tokens_and_score(tokens, specific_words)
print(f"Field: {field}")
print("Total Score:", total_score)
image = 'CV1.png'
field = 'Data_Science_Carrier' To handle case sensitivity e.g., “Data Science” vs. “data science”, we can convert all tokens and keywords to lowercase.
tokens = word_tokenize(extracted_text.lower())With the use of lemmatization with NLP libraries like NLTK or stemming with spaCy to reduce words (e.g., “running” to “run”)
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def normalize_tokens(tokens):
return [lemmatizer.lemmatize(token.lower()) for token in tokens]
Getting Text from PDF Files
Let us now explore the actions required to get text from pdf files.
Install Required Libraries
You will need the following libraries:
- PyPDF2
- pdfplumber
- spacy
- nltk
Using pip
pip install PyPDF2 pdfplumber nltk spacy
python -m spacy download en_core_web_smExtraction of text with the PyDF2
import PyPDF2
def text_from_pdf(pdf_file):
with open(pdf_file, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text() + "\n"
return textExtraction of Text from pdfplumber
import pdfplumber
def text_from_pdf(pdf_file):
with pdfplumber.open(pdf_file) as pdf:
text = ""
for page in pdf.pages:
text += page.extract_text() + "\n"
return text
pdf_file = 'SoniaSingla-DataScience-Bio.pdf'
# Extract text from the PDF
text = text_from_pdf(pdf_file)
# Tokenize the extracted text
tokens = word_tokenize(text)
print(tokens) Normalizing Tokens for Consistency
To handle the PDF file instead of an image and ensure that repeated words do not receive multiple scores, modify the previous code. We will extract text from the PDF file, tokenize it, and compare the tokens against specific words from different fields. The code will calculate the score based on unique matched words.
import pdfplumber
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')
def extract_text_from_pdf(pdf_file):
with pdfplumber.open(pdf_file) as pdf:
text = ""
for page in pdf.pages:
text += page.extract_text() + "\n"
return text
def tokenize_text(text):
tokens = word_tokenize(text)
return tokens
def compare_tokens_and_score(tokens, specific_words, score_per_match=10):
# Use a set to store unique matched words to prevent duplicates
unique_matched_words = set(word.lower() for word in tokens if word.lower() in specific_words)
# Calculate total score based on unique matches
total_score = len(unique_matched_words) * score_per_match
return unique_matched_words, total_score
# Define sets of specific words for different fields
fields_keywords = {
"Data_Science_Carrier": { 'supervised machine learning', 'Unsupervised machine learning', 'data','analysis', 'statistics','Python'},
# Add more fields and keywords here
}
# Step 4: Select the field and calculate the score based on specific words for that field
def process_pdf_for_field(pdf_file, field):
if field not in fields_keywords:
print(f"Field '{field}' is not defined.")
return
text = extract_text_from_pdf(pdf_file)
tokens = tokenize_text(text)
specific_words = fields_keywords[field]
unique_matched_words, total_score = compare_tokens_and_score(tokens, specific_words)
print(f"Field: {field}")
print("Unique matched words:", unique_matched_words)
print("Total Score:", total_score)
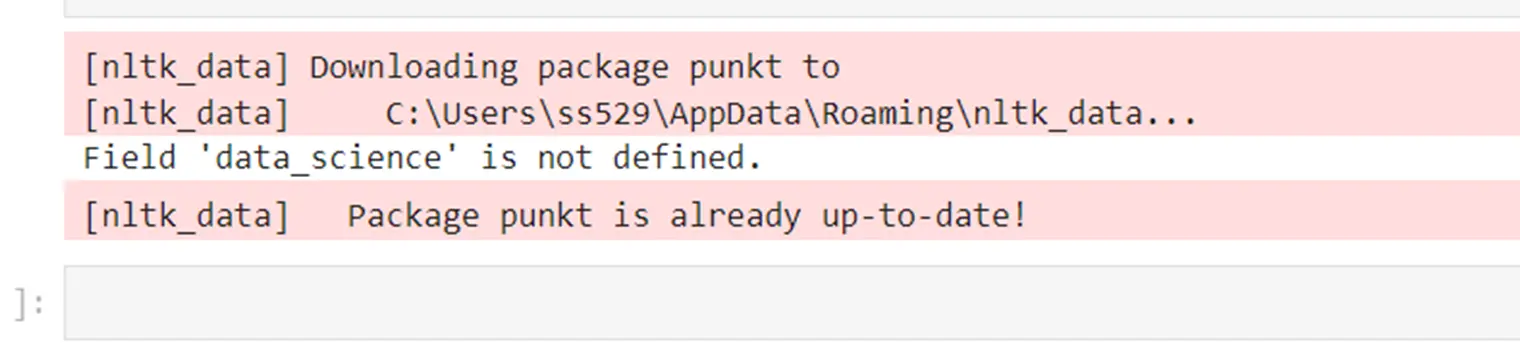
pdf_file = 'SoniaSingla-DataScience-Bio.pdf'
field = 'data_science'
process_pdf_for_field(pdf_file, fieIt will produce an error message as data_science field is not defined.
When the error is removed, it works fine.
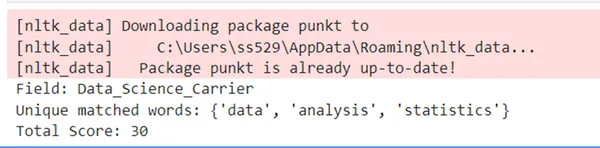
To handle case sensitivity properly and ensure that words like “data” and “Data” are considered the same word while still scoring it only once (even if it appears multiple times with different cases), you can normalize the case of both the tokens and the specific words. We can do this by converting both the tokens and the specific words to lowercase during the comparison but still preserve the original casing for the final output of matched words.
Key Points on Text Extraction
- Using pdfplumber to extract the text from the pdf file.
- Using OCR to convert image into machine code.
- Using pytesseract for converting python wrap codes into text.
Conclusion
We explored the crucial process of extracting and analyzing data from CVs, focusing on automation techniques using Python. We learned how to utilize essential libraries like NLTK, SpaCy, Pytesseract, and Pillow for effective text extraction from various file formats, including PDFs and images. By applying methods for tokenization, text normalization, and scoring, we gained insights into how to align candidates’ qualifications with job requirements efficiently. This systematic approach not only streamlines the hiring process for employers but also enhances candidates’ chances of securing positions that match their skills.
Key Takeaways
- Efficient data extraction from CVs is vital for automating the hiring process.
- Tools like NLTK, SpaCy, Pytesseract, and Pillow are essential for text extraction and processing.
- Proper tokenization methods help in accurately analyzing the content of CVs.
- Implementing a scoring mechanism based on keywords enhances the matching process between candidates and job requirements.
- Normalizing tokens through techniques like lemmatization improves text analysis accuracy.
Frequently Asked Questions
Q1. How one can get text extracted from pdf?
A. PyPDF2 or pdfplumber libraries to extract text from pdf.
Q2. How to extract text from CV in image format?
A. If the CV is in image format (scanned document or photo), you can use OCR (Optical Character Recognition) to extract text from the image. The most commonly used tool for this in Python is pytesseract, which is a wrapper for Tesseract OCR.
Q3. How do I handle poor quality images in OCR?
A. Improving the quality of images before feeding them into OCR can significantly increase text extraction accuracy. Techniques like grayscale conversion, thresholding, and noise reduction using tools like OpenCV can help.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I have done my Master Of Science in Biotechnology and Master of Science in Bioinformatics from reputed Universities. I have written a few research papers, reviewed them, and am currently an Advisory Editorial Board Member at IJPBS.
I Look forward to the opportunities in IT to utilize my skills gained during work and Internship.
https://aster28.github.io/SoniaSinglaBio/site/





