Customer support calls hold a wealth of information, but finding the time to manually comb through these recordings for insights isn’t easy. Imagine if you could instantly turn these long recordings into clear summaries, track how the sentiment shifts throughout the call, and even get tailored insights based on how you want to analyze the conversation. Sounds useful?
In this article, we’ll walk through creating a practical tool I built SnapSynapse (click here), to do exactly that! Using tools like pyannote.audio for speaker diarization(identification), Whisper for transcription, and Gemini-1.5 Pro for generating AI-driven summaries, I’ll show how you can automate the process of turning support call recordings into actionable insights. Along the way, you’ll see how to clean and refine transcriptions, generate custom summaries based on user input, and track sentiment trends—all with easy-to-follow code snippets. This is a hands-on guide to building a tool that goes beyond transcription to help you understand and improve your customer support experience.
Learning Objectives
- Understand how to use pyannote.audio for speaker diarization, separating different voices in customer support recordings.
- Learn to generate accurate transcriptions from audio files using Whisper and clean them by removing filler words and irrelevant text.
- Discover how to create tailored summaries using Gemini-1.5 Pro, with customizable prompts to fit different analysis needs.
- Explore techniques for performing sentiment analysis on conversations and visualizing sentiment trends throughout a call.
- Gain hands-on experience in building an automated pipeline that processes audio data into structured insights, making it easier to analyze and improve customer support interactions.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is SnapSynapse?
SnapSynapse is a handy tool for turning customer support calls into valuable insights. It breaks down conversations by speaker, transcribes everything, and highlights the overall mood and key points, so teams can quickly understand what customers need. Using models like Pyannote for diarization, Whisper for transcription, and Gemini for summaries, SnapSynapse delivers clear summaries and sentiment trends without any hassle. It’s designed to help support teams connect better with customers and improve service, one conversation at a time.
Key Features
Below are the important key features of SnapSynapse:
- Speaker diarization/identification
- Conversation transcript generation
- Time Stamps generation dialogue wise
- Use case based Summary generation
- Sentiment Analysis scores
- Sentiment Analysis through visualization
Building SnapSynapse: Core Features and Functionality
In this section, we’ll explore the core features that make SnapSynapse a powerful tool for customer support analysis. From automatically diarizing and transcribing calls to generating dynamic conversation summaries, these features are built to enhance support team efficiency. With its ability to detect sentiment trends and provide actionable insights, SnapSynapse simplifies the process of understanding customer interactions.
In case, if you want to check out the whole source code, refer to the files in the repo : repo_link
We’ll need OPEN AI API and GEMINI API to run this project. You can get the API’s here – Gemini API , OpenAI API
Project flow:
speaker diarization -> transcription -> time stamps -> cleaning -> summarization -> sentiment analysis
Step1: Speaker Diarization and Transcription Generation
In the first step, we’ll use a single script to take an audio file, separate the speakers (diarization), generate a transcription, and assign timestamps. Here’s how the script works, including a breakdown of the code and key functions:
Overview of the Script
This Python script performs three main tasks in one go:
- Speaker Diarization: Identifies different speakers in an audio file and separates their dialogue.
- Transcription: Converts each speaker’s separated audio segments into text.
- Timestamping: Adds timestamps for each spoken segment.
Imports and Setup
- We start by importing necessary libraries like pyannote.audio for speaker diarization, openai for transcription, and pydub to handle audio segments.
- Environment variables are loaded using dotenv, so we can securely store our OpenAI API key.
Main Function: Diarization + Transcription with Timestamps
The core function, transcribe_with_diarization(), combines all the steps:
- Diarization: Calls perform_diarization() to get speaker segments.
- Segment Extraction: Uses pydub to cut the audio file into chunks based on each segment’s start and end times.
- Transcription: For each chunk, it calls the Whisper model via OpenAI’s API to get text transcriptions.
- Timestamp and Speaker Info: Each transcription is saved with its corresponding start time, end time, and speaker label.
def transcribe_with_diarization(file_path):
diarization_result = perform_diarization(file_path)
audio = AudioSegment.from_file(file_path)
transcriptions = []
for segment, _, speaker in diarization_result.itertracks(yield_label=True):
start_time_ms = int(segment.start * 1000)
end_time_ms = int(segment.end * 1000)
chunk = audio[start_time_ms:end_time_ms]
chunk_filename = f"{speaker}_segment_{int(segment.start)}.wav"
chunk.export(chunk_filename, format="wav")
with open(chunk_filename, "rb") as audio_file:
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file,
response_format="json"
)
transcriptions.append({
"speaker": speaker,
"start_time": segment.start,
"end_time": segment.end,
"transcription": transcription.text
})
print(f"Transcription for {chunk_filename} by {speaker} completed.")
Saving the Output
- The final transcriptions, along with speaker labels and timestamps, are saved to diarized_transcriptions.json, creating a structured record of the conversation.
- Finally, we run the function on a test audio file, test_audio_1.wav, to see the full diarization and transcription process in action.
A Glimpse of the output generated and got saved in diarized_transcription.py file:
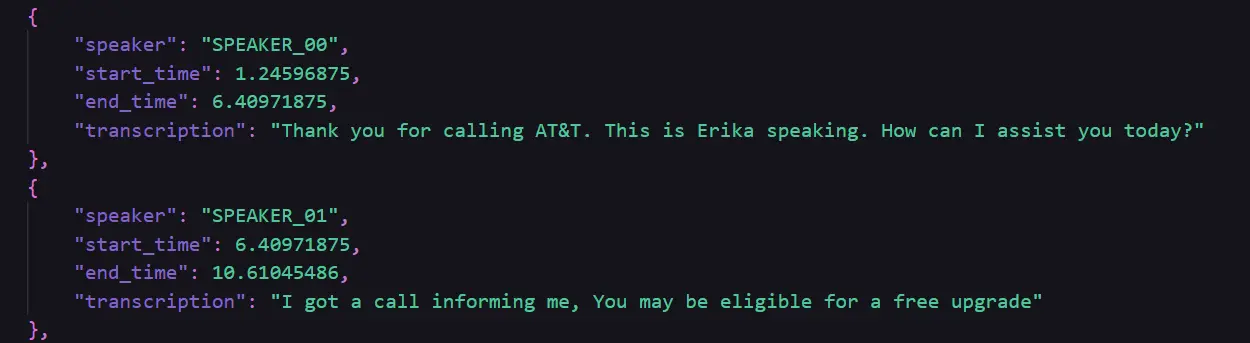
Step2: Cleaning of the Generated Transcription
- This file focuses on cleaning the transcriptions generated from the diarization and transcription process.
- It loads the diarized transcriptions from a JSON file and removes common filler words like “um,” “uh,” and “you know” to improve readability.
- Additionally, it eliminates extra white spaces and normalizes the text to make the transcription more concise and polished.
- After cleaning, the system saves the new transcriptions in a JSON file named cleaned_transcription.py, ensuring that the data is ready for further analysis or insight generation.
# function to clean the transcription text
def clean_transcription(text):
# List of common filler words
filler_words = [
"um", "uh", "like", "you know", "actually", "basically", "I mean",
"sort of", "kind of", "right", "okay", "so", "well", "just"
]
# regex pattern to match filler words (case insensitive)
filler_pattern = re.compile(r'\b(' + '|'.join(filler_words) + r')\b', re.IGNORECASE)
# Remove filler words
cleaned_text = filler_pattern.sub('', text)
# Remove extra whitespace
cleaned_text = re.sub(r'\s+', ' ', cleaned_text).strip()
return cleaned_textStep3: Generating Summary using GEMINI 1.5 pro
In the next step, we use the Gemini API to generate structured insights and summaries based on the cleaned transcriptions. We utilize the Gemini 1.5 pro model for natural language processing to analyze customer support calls and provide actionable summaries.
Here’s a breakdown of the functionality:
- Model Setup: The Gemini model is configured using the google.generativeai library, with the API key securely loaded. It supports generating insights based on different prompt formats.
- Prompts for Analysis: Several predefined prompts are designed to analyze various aspects of the support call, such as general call summaries, speaker exchanges, complaints and resolutions, escalation needs, and technical issue troubleshooting.
- Generate Structured Content: The function generate_analysis() takes the cleaned transcription text and processes it using one of the predefined prompts. It organizes the output into three sections: Summary, Action Items, and Keywords.
- User Interaction: The script allows the user to choose from multiple summary formats. The user’s choice determines which prompt is used to generate the insights from the transcription.
- Output Generation: After processing the transcription, the resulting insights—organized into a structured JSON format—are saved to a file. This structured data makes it easier for support teams to extract meaningful information from the call.
A short glimpse of different prompts used:

A glimpse of the output generated:
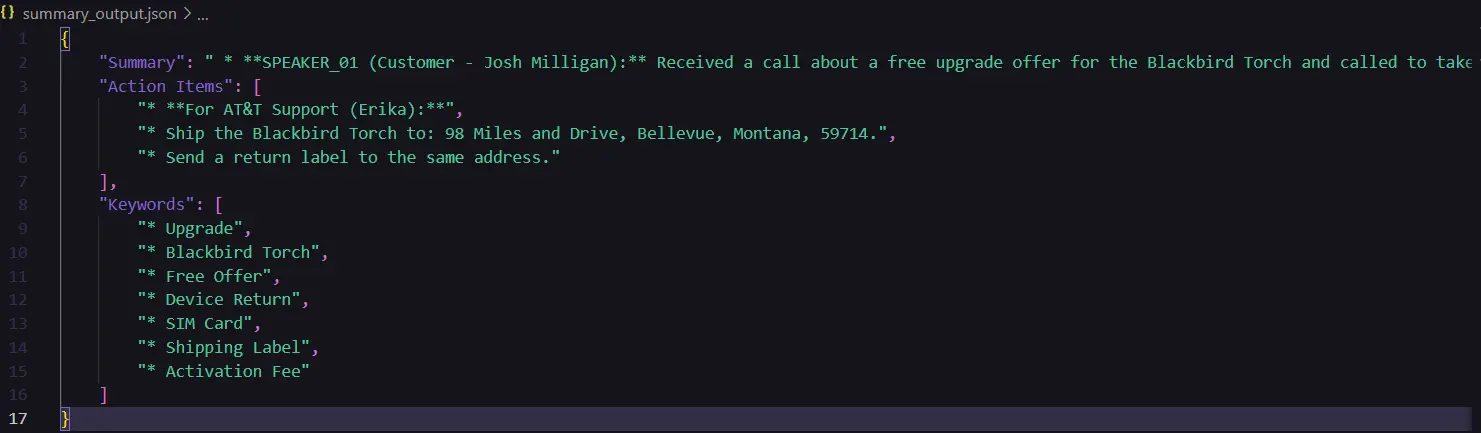
Step 4: Sentiment Analysis
Further, in the next step we perform sentiment analysis on customer support call transcriptions to assess the emotional tone throughout the conversation. It uses the VADER sentiment analysis tool from NLTK to determine sentiment scores for each segment of the conversation.
Here’s a breakdown of the process:
- Sentiment Analysis Using VADER: The script uses SentimentIntensityAnalyzer from the VADER (Valence Aware Dictionary and sEntiment Reasoner) lexicon. It assigns a sentiment score for each segment, which includes a compound score indicating the overall sentiment (positive, neutral, or negative).
- Processing Transcription: The cleaned transcription is loaded from a JSON file. Each entry in the transcription is evaluated for sentiment, and the results are stored with the speaker label and corresponding sentiment scores. The script calculates the total sentiment score, the average sentiment for the customer and support agent, and categorizes the overall sentiment as Positive, Neutral, or Negative.
- Sentiment Trend Visualization: Using Matplotlib, the script generates a line plot showing the trend of sentiment over time, with the x-axis representing the conversation segments and the y-axis showing the sentiment score.
- Output: The system saves the sentiment analysis results, including the scores and overall sentiment, to a JSON file for easy access and analysis later. It visualizes the sentiment trend in a plot to provide an overview of the emotional dynamics during the support call.
Code used for calculating the overall sentiment score
# Calculate the overall sentiment score
overall_sentiment_score = total_compound / len(sentiment_results)
# Calculate average sentiment for Customer and Agent
average_customer_sentiment = customer_sentiment / customer_count if customer_count else 0
average_agent_sentiment = agent_sentiment / agent_count if agent_count else 0
# Determine the overall sentiment as positive, neutral, or negative
if overall_sentiment_score > 0.05:
overall_sentiment = "Positive"
elif overall_sentiment_score < -0.05:
overall_sentiment = "Negative"
else:
overall_sentiment = "Neutral"Code used for generating the plot
def plot_sentiment_trend(sentiment_results):
# Extract compound sentiment scores for plotting
compound_scores = [entry['sentiment']['compound'] for entry in sentiment_results]
# Create a single line plot showing sentiment trend
plt.figure(figsize=(12, 6))
plt.plot(compound_scores, color='purple', linestyle='-', marker='o', markersize=5, label="Sentiment Trend")
plt.axhline(0, color='grey', linestyle='--') # Add a zero line for neutral sentiment
plt.title("Sentiment Trend Over the Customer Support Conversation", fontsize=16, fontweight='bold', color="darkblue")
plt.xlabel("Segment Index")
plt.ylabel("Compound Sentiment Score")
plt.grid(True, linestyle='--', alpha=0.5)
plt.legend()
plt.show()Sentiment Analysis Scores generated:

Sentiment Analysis Plot generated:
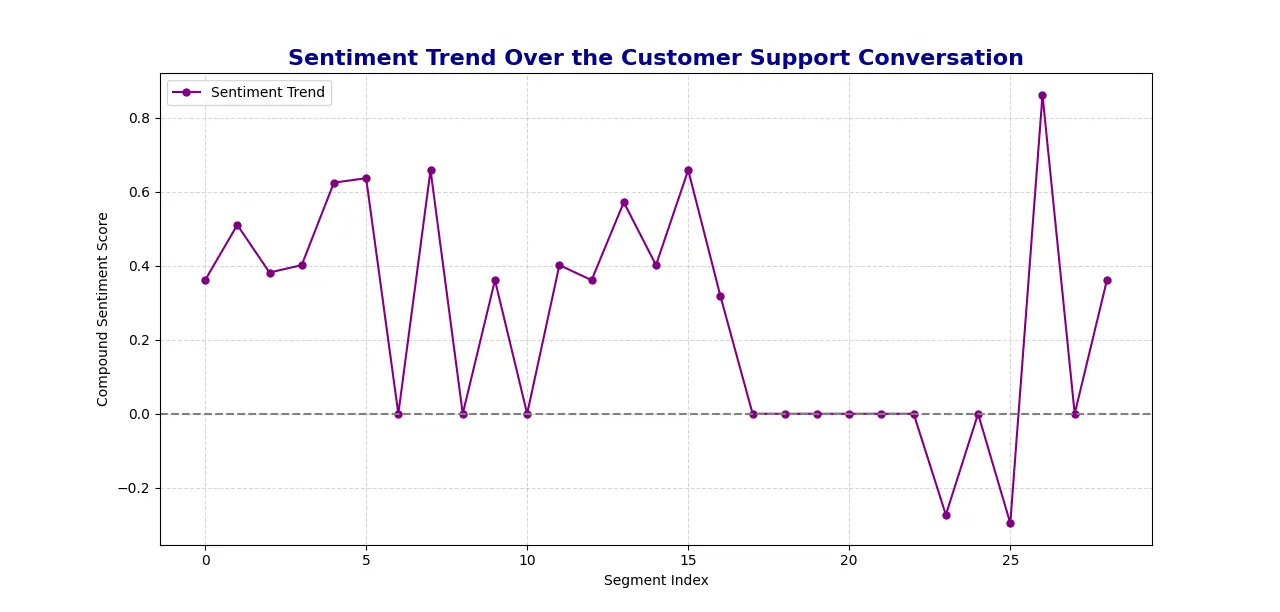
Setting Up SnapSynapse: A Step-by-Step Guide
You can find the code repository here – repo_link
Now, let’s walk through how to set up and run SnapSynapse on your local machine:
Step1: Clone the Repository
Start by cloning the project repository to your local machine to begin using SnapSynapse. This provides access to the application’s source code and all its essential components.
git clone https://github.com/Keerthanareddy95/SnapSynapse.git
cd SnapSynapseStep2: Setup the Virtual Environment
A virtual environment helps isolate dependencies and ensures your project runs smoothly. This step sets up an independent workspace for SnapSynapse to operate without interference from other packages.
# For Windows:
python -m venv venv
# For macOS and Linux:
python3 -m venv venvStep3: Activate the Virtual Environment
# For Windows:
.\venv\Scripts\activate
# For macOS and Linux:
source venv/bin/activateStep4: Install Required Dependencies
With the virtual environment in place, the next step is to install all necessary libraries and tools. These dependencies enable the core functionalities of SnapSynapse, including transcript generation, speaker diarization, time stamp generation, summary generation, sentiment analysis scores, visualization and more.
pip install -r requirements.txt Step5: Set up the Environment Variables
To leverage AI-driven insights, diarization, transcription and summarization and you’ll need to configure API keys for Google Gemini and OPEN AI Whisper.
Create a .env file in the root of the project and add your API keys for Google Gemini and OPEN AI Whisper.
GOOGLE_API_KEY="your_google_api_key"
OPENAI_API_KEY="your_open_ai_api_key"Step6: Run the Application
- Start by running the transcription.py file: This file performs the transcription generation, speaker diarization and time stamp generation. And it saves the output in a json file named diarized_transcriptions.json.
- Next, run the cleaning.py file: This file will take the diarized_transcriptions.py file as input and cleans the transcription and saves the results in cleaned_transcription.json file.
- Further, run the summary.py file: here you need to mention the GEMINI API key. This file will take the cleaned_transcription.py file as input and prompts the user to enter the style of summary they want to generate based on their use case. Based on the user input, the system passes the corresponding prompt to GEMINI, which generates the summary. The system then stores the generated summary in a JSON file named
summary_output.json. - Finally, run the sentiment_analysis.py file: Running this file will generate the overall sentiment scores and also a graphical representation of the sentiment analysis scores and how they progressed through the audio file.
Summary on Tools Used in Development of SnapSynapse
Let us now look onto the tools used in development for SnapSynapse below:
- pyannote.audio : Provides the Pipeline module for performing speaker diarization, which separates different speakers in an audio file.
- openai: Used to interact with OpenAI’s API for transcription via the Whisper model.
- pydub (AudioSegment): Processes audio files, allowing segmentation and export of audio chunks by speaker.
- google.generativeai: A library to access Google Gemini models, used here to generate structured summaries and insights from customer support transcriptions.
- NLTK (Natural Language Toolkit): A library for natural language processing, specifically used here to import the SentimentIntensityAnalyzer from VADER to analyze sentiment in the audio file.
- Matplotlib: A visualization library often used with plt, included here for visualization of the sentiment throughout the audio file.
Conclusion
In a nutshell, SnapSynapse revolutionizes customer support analysis by transforming raw call recordings into actionable insights. From speaker diarization and transcription to generating a structured summary and sentiment analysis, SnapSynapse streamlines every step to deliver a comprehensive view of customer interactions. With the power of the Gemini model’s tailored prompts and detailed sentiment tracking, users can easily obtain summaries and trends that highlight key insights and support outcomes.
A big shoutout to Google Gemini, Pyannote Audio, and Whisper for powering this project with their innovative tools!
You can check out the repo here.
Key Takeaways
- SnapSynapse enables users to process customer support calls end-to-end—from diarizing and transcribing to generating summaries.
- With five distinct prompt choices, users can tailor summaries to specific needs, whether focusing on issues, action items, or technical support. This feature helps learners explore prompt engineering and experiment with how different inputs impact AI-generated outputs.
- SnapSynapse tracks sentiment trends throughout conversations, providing a visual representation of tone shifts that help users better understand customer satisfaction. For learners, it’s a chance to apply NLP techniques and learn how to interpret sentiment data in real-world applications.
- SnapSynapse automates transcription cleanup and analysis, making customer support insights easily accessible for faster, data-driven decisions. Learners benefit from seeing how automation can streamline data processing, allowing them to focus on advanced insights rather than repetitive tasks.
Frequently Asked Questions
Q1. What types of data can SnapSynapse analyze?
A. SnapSynapse can handle audio files of the formats mp3 and wav.
Q2. How does SnapSynapse handle transcription accuracy and cleanup?
A. SnapSynapse uses Whisper for transcription, followed by a cleanup process that removes filler words, pauses, and irrelevant content.
Q3. Can I customize the summary format of the call analysis?
A. Yes! SnapSynapse offers five distinct prompt options, allowing you to choose a summary format tailored to your needs. These include focus areas like action items, escalation needs, and technical issues.
Q4. What insights does the sentiment analysis provide, and how is it displayed?
A. SnapSynapse’s sentiment analysis assesses the emotional tone of the conversation, providing a sentiment score and a trend graph.
Q5. What is Customer Call Analysis and how can it benefit businesses?
A. Customer Call Analysis uses AI-powered tools to transcribe, analyze, and extract valuable insights from customer interactions, helping businesses improve service, identify trends, and enhance customer satisfaction.
Q6. How can Customer Call Analysis improve customer support quality?
A. By customer call analysis, businesses can gain a deeper understanding of customer sentiment, common issues, and agent performance, leading to more informed decisions and improved customer service strategies.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi, I’m Katasani Keerthana Reddy, a passionate problem-solver at the intersection of data science and artificial intelligence. With a knack for transforming raw data into actionable insights, I'm currently dwelling into the world of AI. My journey has taken me from developing dynamic AIOps systems at ThoughtData to crafting insightful data tools like InsightMate and leading AI/ML initiatives as a Google DSC Lead. When I’m not diving into data, you’ll find me championing innovative projects or connecting with fellow tech enthusiasts. Let’s turn data challenges into opportunities!


