Have you ever been curious about what powers some of the best Search Applications such as Elasticsearch and Solr across use cases such e-commerce and several other document retrieval systems that are highly performant? Apache Lucene is a powerful search library in Java and performs super-fast searches on large volumes of data. The indexing and search capabilities of Lucene offer the best possible features for search engines.
By the end of this article, you will have mastered the fundamentals of Apache Lucene even if you are new to the field of Search Engineering.
Learning Objectives
- Learn the fundamental concepts of Apache Lucene.
- See how Lucene powers search applications like Elasticsearch, Solr etc.
- Understand how Indexing and Searching work in Lucene.
- Learn different types of Queries supported by Apache Lucene.
- Understand how to build a simple search application using Lucene and Java.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Apache Lucene?
To understand Lucene in depth, there are a few key terminologies and concepts. Let us look at each one of them in detail along with examples. Consider an example where we have the following information about three different products in our collection.
{
"product_id": "1",
"title": "Wireless Noise Cancelling Headphones",
"brand": "Bose",
"category": ["Electronics", "Audio", "Headphones"],
"price": 300
}
{
"product_id": "2",
"title": "Bluetooth Mouse",
"brand": "Jelly Comb",
"category": ["Electronics", "Computer Accessories", "Mouse"],
"price": 30
}
{
"product_id": "3",
"title": "Wireless Keyboard",
"brand": "iClever",
"category": ["Electronics", "Computer Accessories", "Keyboard"],
"price": 40
}Document
A document is a fundamental unit of indexing and search in Lucene. A document ID identifies each document. Lucene converts raw content into documents containing fields and values.
Field
A Lucene document contains multiple fields. Each field has a name and a value. See example below.
- product_id
- title
- brand
- category
- price
Term
A term is a unit of search in Lucene. Lucene does multiple pre-processing steps on raw content before creating terms such as tokenization etc.
| Document ID | Terms |
| 1 | title: wireless, noise, cancelling, headphonesbrand: bosecategory: electronics, audio, headphones |
| 2 | title: bluetooth, mousebrand: jelly, combcategory: electronics, computer, accessories |
| 3 | title: wireless, keyboard brand: iclevercategory: electronics, computer, accessories |
Inverted Index
The underlying data structure in Lucene that enables super fast searches is the Inverted Index. In an inverted index, each term maps to the documents that contain it, along with the position of the term in those documents. This is called a Postings List.
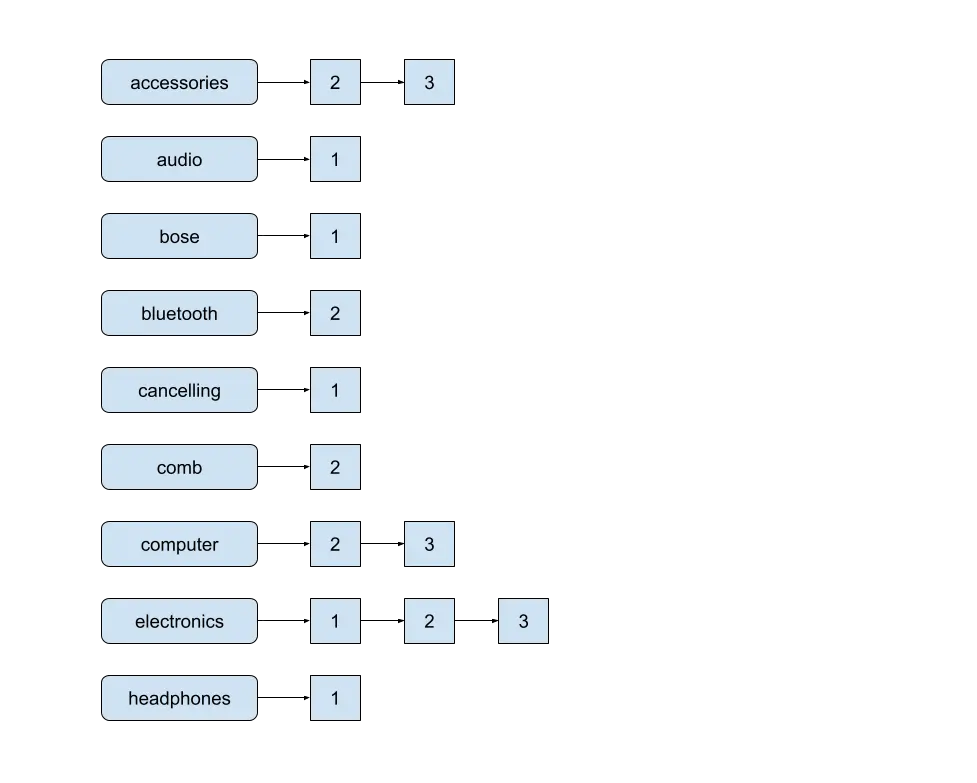
Segment
A index can be sub-divided by Lucene into multiple segments. Each segment is an index in itself. Segment searches are usually done serially.
Scoring
Lucene calculates the relevance of a document by scoring mechanisms such as Term Frequency Inverse Document Frequency (TF-IDF). There are also other scoring algorithms such as BM25 which improve upon TF-IDF.
Now let us understand how TF-IDF is calculated.
Term Frequency (TF)
Term frequency is the number of times a term t appears in a document.
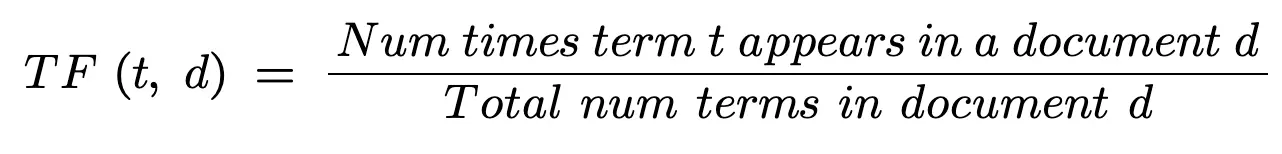
Document Frequency (DF)
Document frequency is the number of documents that contain a term t. Inverse Document Frequency divides the number of documents in the collection by the number of documents containing the term t. It measures the uniqueness of a particular term to prevent giving higher importance to repetitive terms like “a,” “the,” etc. The “1+” is added to the denominator when the number of documents containing the term t is 0.
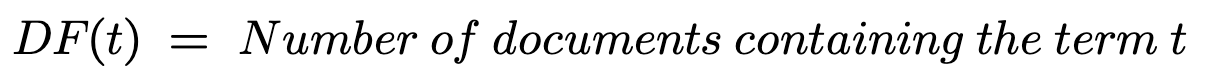

Term Frequency Inverse Document Frequency (TF-IDF)
The TF-IDF is the product of Term Frequency and Inverse Document Frequency. A higher value of TF-IDF means that the term is more distinguishing and unique in relevance to the whole collection.
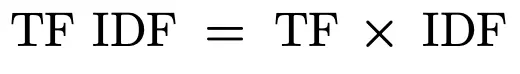
Components of a Lucene Search Application
Lucene contains two major components which are:
- Indexer – Lucene uses the IndexWriter class for indexing
- Searcher – Lucene uses the IndexSearcher class for searching.
Lucene Indexer
The Lucene Index is responsible for indexing documents for the search application. Lucene does several text processing and analysis steps such as tokenization before indexing the terms into an inverted index. Lucene uses the IndexWriter class for indexing.
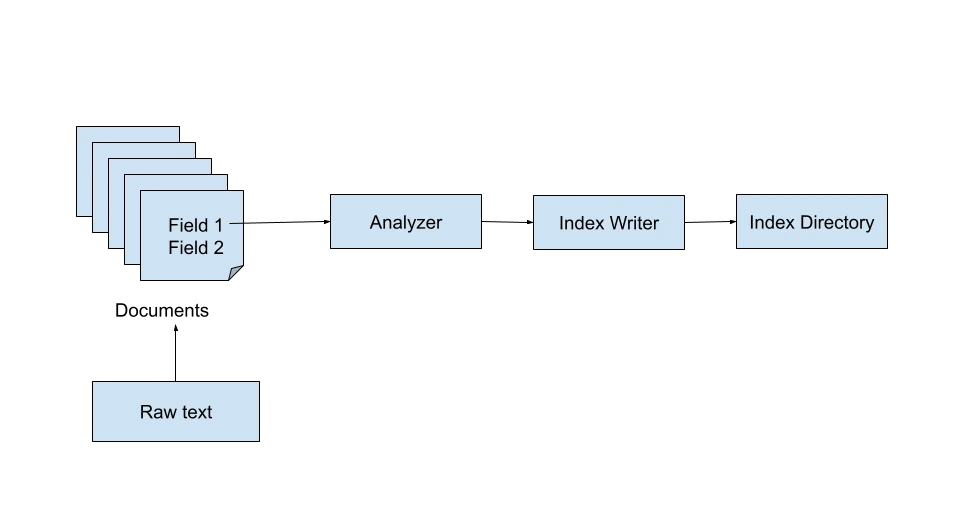
The IndexWriter requires the specification of a directory where the index will be stored as well an analyzer for the raw content. Although it is pretty simple to write your own custom analyzer, Lucene’s StandardAnalyzer does a great job at this.
Directory directory = FSDirectory.open(Paths.get(INDEX_DIR));
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);Lucene Searcher
Lucene does search using IndexSearcher class. The IndexSearcher class requires us to specify a valid Query object. A user query string can be converted into a valid Query object using the QueryParser class.
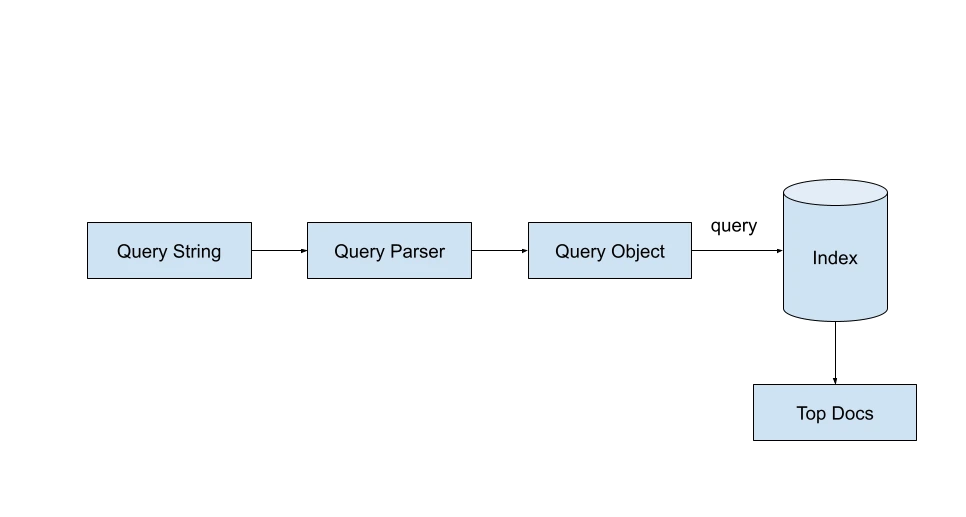
Upon specifying the maximum hits (aka search results) we want for the query, the Lucene searcher will return a TopDocs object which contains the top hits for the query. Each topDoc contains a score for each of the document IDs retrieved.
searcher = new IndexSearcher(directory);
parser = new QueryParser("query", new StandardAnalyzer());
Query query = parser.parse(searchString)
searcher.search(query, numHits)Types of Search Queries Supported by Lucene
Lucene supports several different query types. Let us look at five most commonly used queries along with examples.
Term Query
A term query matches documents that contain a particular term.
Query query = new TermQuery(new Term("brand", "jelly"));Boolean Query
Boolean queries match documents that hold true for a boolean combination of other queries.
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(new TermQuery(new Term("category", "Computer Accessories")), BooleanClause.Occur.SHOULD);
builder.add(new TermQuery(new Term("brand", "Jelly")), BooleanClause.Occur.SHOULD);
Query query = builder.build();Range Query
Range Queries match documents which contain field values within a range. The example below finds products where the price is between 30 and 50.
Query query = NumericRangeQuery.newIntRange("price", 30, 50, true, true);
Phrase Query
A phrase query matches documents containing a particular sequence of terms.
Query query = new PhraseQuery("title", "Noise", "Cancelling");
Function Query
Calculates scores for documents based on a function of the value of a field. Function Query can be used to boost the score of results based on a field in the document.
Query query = new FunctionQuery(new FloatFieldSource("price"));
Building a Simple Search Application with Lucene
So far, we have learned about Lucene fundamentals, indexing, searching, and the various query types you can use.
Let us now tie all these bits together into a practical example where we build a simple search application using the core parts of Lucene: Indexer and Searcher.
In the example below, we index 3 documents where each document contains the following fields.
- Name
Name is added as a text field and Email is added as a string field. String fields do not get tokenized by Lucene.
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import java.io.IOException;
public class MyIndexer {
private Directory indexDirectory;
private static final String NAME = "name";
private static final String EMAIL = "email";
private Analyzer analyzer;
public MyIndexer(Directory directory, Analyzer analyzer) {
this.indexDirectory = directory;
this.analyzer = analyzer;
}
public void indexDocuments() throws IOException {
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(indexDirectory, indexWriterConfig);
indexNewDocument(indexWriter, "john", "[email protected]");
indexNewDocument(indexWriter, "jane", "[email protected]");
indexNewDocument(indexWriter, "ana", "[email protected]");
indexWriter.close();
}
public void indexNewDocument(IndexWriter indexWriter, String name, String email) throws IOException {
Document document = new Document();
document.add(new TextField(NAME, name, Field.Store.YES));
document.add(new StringField(EMAIL, email, Field.Store.YES));
indexWriter.addDocument(document);
}
}Once the documents are indexed, we can query them using Lucene queries. In the example below, we use a simple TermQuery to find and print the documents that match the term “jane”.
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import java.io.IOException;
import java.nio.file.Paths;
public class SimpleSearchApplication {
public static void main(String[] args) throws IOException {
String INDEX_DIRECTORY = "directory";
Directory indexDirectory = FSDirectory.open(Paths.get(INDEX_DIRECTORY));
Analyzer analyzer = new StandardAnalyzer();
MyIndexer indexer = new MyIndexer(indexDirectory, analyzer);
indexer.indexDocuments();
// Search on the indexed documents
IndexReader indexReader = DirectoryReader.open(indexDirectory);
IndexSearcher searcher = new IndexSearcher(indexReader);
// Construct a Term query to search for the name "jane"
Query query = new TermQuery(new Term("name", "jane"));
int maxHits = 10;
TopDocs searchResults = searcher.search(query, maxHits);
System.out.println("Documents with name 'jane':");
for (ScoreDoc scoreDoc : searchResults.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("name: " + doc.get("name") + ", email: " + doc.get("email"));
}
indexReader.close();
}
}
The above code returns the following result:
Documents with name 'jane':
name: jane, email: [email protected]Conclusion
Apache Lucene is a robust search library that enables the development of high-performance search applications. With the introduction of Lucene 9.9, significant improvements in query evaluation, vector search, and other features have enhanced its capabilities. Throughout this guide, we’ve covered the fundamental components of Lucene, the workings of indexers and searchers, and how to build a simple search application in Java. Additionally, we explored the various types of search queries supported by Lucene. Armed with this knowledge, you should now feel confident in your understanding of Lucene and be ready to create more advanced search applications utilizing its powerful features.
Key Takeaways
- Apache Lucene is a powerful Java library that can perform super fast full-text searches.
- Lucene supports various query types that cater to different search use cases.
- Lucene forms the backbone of several high performance search applications such as Elasticsearch, Solr, Nrtsearch etc.
- Lucene IndexWriter and IndexSearcher are important classes that enable fast indexing and searching.
Frequently Asked Questions
Q1. Does Lucene support Python?
A. Yes Apache Lucene has a PyLucene project which supports Python search applications
Q2. What are the different open source search engines available?
A. Some open source search engines include Solr, Open Search, Meilisearch, Swirl etc.
Q3. Does Lucene support Semantic and Vector Search?
A. Yes it does. However the maximum dimensions for vector fields is limited to 1024 which is expected to be increased in the future.
Q4. What are the various relevance scoring algorithms?
A. Some of them include Term Frequency Inverse Document Frequency (TF-IDF), Best Matching 25 (BM25), Latent Semantic Analysis (LSA), Vector Space Models (VSM) etc.
Q5. What are some examples of complex queries supported by Lucene?
A. Some examples for complex queries include fuzzy queries, span queries, multi phrase query, regular expression query etc.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Backend Software Engineer working on Search and Ranking Infrastructure Technologies at Yelp Inc in Bay Area, California. I have a masters in Electrical and Computer Science Engineering from University of Washington, Seattle. I have been working on AI, Machine Learning, Backend Infrastructure and Search Relevance over the past several years.
My website: www.thatgirlcoder.com





