In the dynamic world of artificial intelligence and super advancement of Generative AI, developers are constantly seeking innovative ways to extract meaningful insight from text. This blog post walks you through an exciting project that harnesses the power of Google’s Gemini AI to create an intelligent English Educator Application that analyzes text documents and provides difficult words, medium words, their synonyms, antonyms, use-cases and also provides the important questions with an answer from the text. I believe education is the sector that benefits most from the advancements of Generative AIs or LLMs and it is GREAT!
Learning Objectives
- Integrating Google Gemini AI models into Python-based APIs.
- Understand how to integrate and utilize the English Educator App API to enhance language learning applications with real-time data and interactive features.
- Learn how to leverage the English Educator App API to build customized educational tools, improving user engagement and optimizing language instruction.
- Implementation of intelligent text analysis using advanced AI prompting.
- Managing complex AI interaction error-free with error-handling techniques.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Learning Objectives
- What are APIs?
- What is REST API?
- Pydantic and FastAPI: A Perfect Pair
- A Brief on Google Gemini
- Project Setup and Environment Configuration
- Building the API: Code Implementation
- Service Module: Intelligent Text Processing
- API Endpoints: Connecting Users to AI
- Vocabulary Extraction
- Question Answer Extraction
- Testing Get Methods
- Further Development Opportunity
- Practical Considerations and Limitations
- Conclusion
- Frequently Asked Questions
What are APIs?
API (Application Programming Interfaces) serve as a digital bridge between different software applications. They are defined as a set of protocols and rules that enable seamless communication, allowing developers to access specific functionalities without diving into complex underlying implementation.
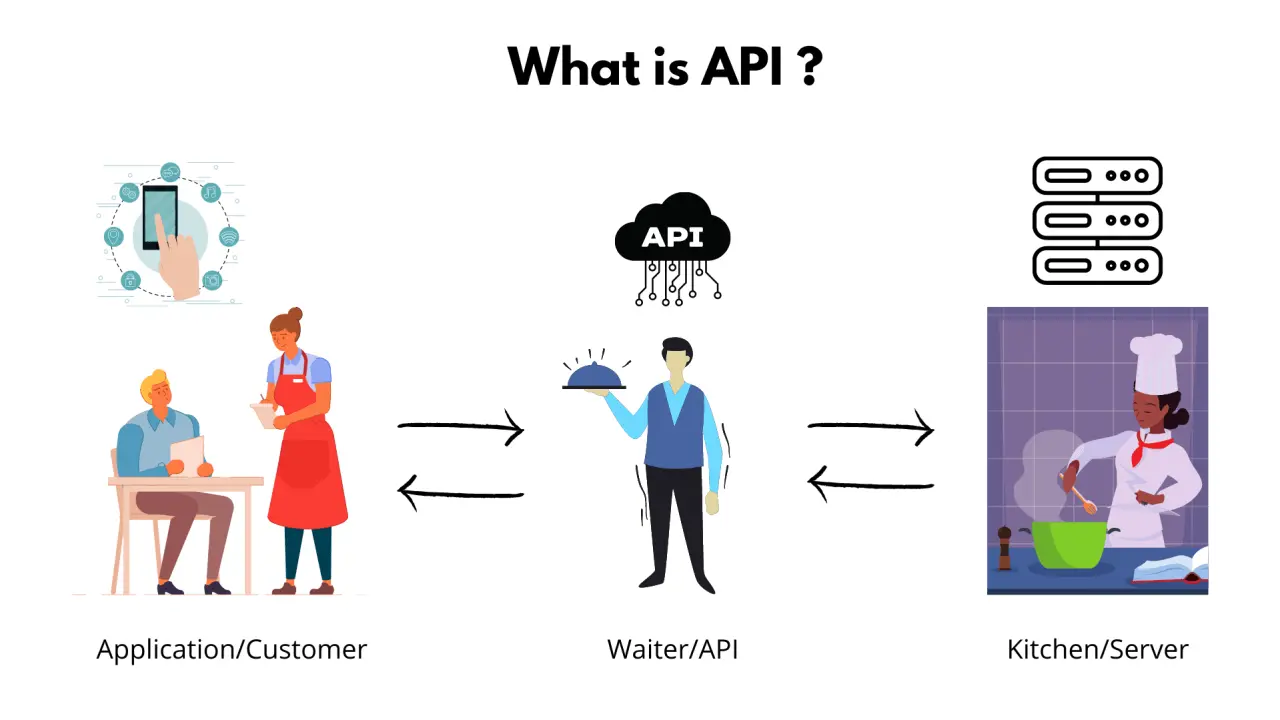
What is REST API?
REST (Representational State Transfer) is an architectural style for designing networked applications. It uses standard HTTP methods to perform operations on resources.
Important REST methods are:
- GET: Retrieve data from a server.
- POST: Create new resources.
- PUT: Update existing resources completely.
- PATCH: Partially update existing resources.
- DELETE: Remove resources.

Key characteristics include:
- Stateless communication
- Uniform interface
- Client-Serve architecture
- Cacheable resources
- Layered system design
REST APIs use URLs to identify resources and typically return data in JSON formats. They provide a standardized, scalable approach for different applications to communicate over the internet, making them fundamental in modern web and mobile development.
Pydantic and FastAPI: A Perfect Pair
Pydantic revolutionizes data validation in Python by allowing developers to create robust data models with type hints and validation rules. It ensures data integrity and provides crystal-clear interface definitions, catching potential errors before they propagate through the system.
FastAPI complements Pydantic beautifully, offering a modern, high-performance asynchronous web framework for building APIs.
Its key advantage of FastAPI:
- Automatic interactive API documentation
- High-speed performance
- Built-in support for Asynchronous Server Gateway Interface
- Intuitive data validation
- Clean and straightforward syntax
A Brief on Google Gemini
Google Gemini represents a breakthrough in multimodal AI models, capable of processing complex information across text, code, audio, and image. For this project, I leverage the ‘gemini-1.5-flash’ model, which provides:
- Rapid and intelligent text processing using prompts.
- Advanced natural language understanding.
- Flexible system instructions for customized outputs using prompts.
- Ability to generate a nuanced, context-aware response.
Project Setup and Environment Configuration
Setting up the development environment is crucial for a smooth implementation. We use Conda to create an isolated, reproducible environment
# Create a new conda environment
conda create -n educator-api-env python=3.11
# Activate the environment
conda activate educator-api-env
# Install required packages
pip install "fastapi[standard]" google-generativeai python-dotenvProject Architectural Components
Our API is structured into three primary components:
- models.py : Define data structures and validation
- services.py : Implements AI-powered text extractor services
- main.py : Create API endpoints and handles request routing
Building the API: Code Implementation
Getting Google Gemini API Key and Security setup for the project.
Create a .env file in the project root, Grab your Gemini API Key from here, and put your key in the .env file
GOOGLE_API_KEY="ABCDEFGH-67xGHtsf"This file will be securely accessed by the service module using os.getenv(“<google-api-key>”). So your important secret key will not be public.
Pydantic Models: Ensuring Data Integrity
We define structured models that guarantee data consistency for the Gemini response. We will implement two data models for each data extraction service from the text.
Vocabulary data extraction model:
- WordDetails: It will structure and validate the extracted word from the AI
from pydantic import BaseModel, Field
from typing import List, Optional
class WordDetails(BaseModel):
word: str = Field(..., description="Extracted vocabulary word")
synonyms: List[str] = Field(
default_factory=list, description="Synonyms of the word"
)
antonyms: List[str] = Field(
default_factory=list, description="Antonyms of the word"
)
usecase: Optional[str] = Field(None, description="Use case of the word")
example: Optional[str] = Field(None, description="Example sentence")- VocabularyResponse: It will structure and validate the extracted words into two categories very difficult words and medium difficult words.
class VocabularyResponse(BaseModel):
difficult_words: List[WordDetails] = Field(
..., description="List of difficult vocabulary words"
)
medium_words: List[WordDetails] = Field(
..., description="List of medium vocabulary words"
)Question and Answer extraction model
- QuestionAnswerModel: It will structure and validate the extracted questions and answers.
class QuestionAnswerModel(BaseModel):
question: str = Field(..., description="Question")
answer: str = Field(..., description="Answer")- QuestionAnswerResponse: It will structure and validate the extracted responses from the AI.
class QuestionAnswerResponse(BaseModel):
questions_and_answers: List[QuestionAnswerModel] = Field(
..., description="List of questions and answers"
)These models provide automatic validation, type checking, and clear interface definitions, preventing potential runtime errors.
Service Module: Intelligent Text Processing
The service module has two services:
Vocabulary Extraction Service
This service GeminiVocabularyService facilities:
- Utilizes Gemini to identify challenging words.
- Generates comprehensive word insights.
- Implement robust JSON parsing.
- Manages potential error scenarios.
First, we have to import all the necessary libraries and set up the logging and environment variables.
import os
import json
import logging
from fastapi import HTTPException
import google.generativeai as genai
from dotenv import load_dotenv
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Load environment variables
load_dotenv()This GeminiVocabularyService class has three method.
The __init__ Method has important Gemini configuration, Google API Key, Setting generative model, and prompt for the vocabulary extraction.
Prompt:
"""You are an expert vocabulary extractor.
For the given text:
1. Identify 3-5 challenging vocabulary words
2. Provide the following for EACH word in a STRICT JSON format:
- word: The exact word
- synonyms: List of 2-3 synonyms
- antonyms: List of 2-3 antonyms
- usecase: A brief explanation of the word's usage
- example: An example sentence using the word
IMPORTANT: Return ONLY a valid JSON that matches this structure:
{
"difficult_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"example": "string"
}
],
"medium_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"example": "string"
}
],
}
""" Code Implementation
class GeminiVocabularyService:
def __init__(self):
_google_api_key = os.getenv("GOOGLE_API_KEY")
# Retrieve API Key
self.api_key = _google_api_key
if not self.api_key:
raise ValueError(
"Google API Key is missing. Please set GOOGLE_API_KEY in .env file."
)
# Configure Gemini API
genai.configure(api_key=self.api_key)
# Generation Configuration
self.generation_config = {
"temperature": 0.7,
"top_p": 0.95,
"max_output_tokens": 8192,
}
# Create Generative Model
self.vocab_model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
generation_config=self.generation_config, # type: ignore
system_instruction="""
You are an expert vocabulary extractor.
For the given text:
1. Identify 3-5 challenging vocabulary words
2. Provide the following for EACH word in a STRICT JSON format:
- word: The exact word
- synonyms: List of 2-3 synonyms
- antonyms: List of 2-3 antonyms
- usecase: A brief explanation of the word's usage
- example: An example sentence using the word
IMPORTANT: Return ONLY a valid JSON that matches this structure:
{
"difficult_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"example": "string"
}
],
"medium_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"example": "string"
}
],
}
""",
)Vocabulary Extraction
The extracted_vocabulary method has the chat process, and response from the Gemini by sending text input using the sending_message_async() function. This method has one private utility function _parse_response(). This private utility function will validate the response from the Gemini, check the necessary parameters then parse the data to the extracted vocabulary function. It will also log the errors such as JSONDecodeError, and ValueError for better error management.
Code Implementation
The extracted_vocabulary method:
async def extract_vocabulary(self, text: str) -> dict:
try:
# Create a new chat session
chat_session = self.vocab_model.start_chat(history=[])
# Send message and await response
response = await chat_session.send_message_async(text)
# Extract and clean the text response
response_text = response.text.strip()
# Attempt to extract JSON
return self._parse_response(response_text)
except Exception as e:
logger.error(f"Vocabulary extraction error: {str(e)}")
logger.error(f"Full response: {response_text}")
raise HTTPException(
status_code=500, detail=f"Vocabulary extraction failed: {str(e)}"
)The _parsed_response method:
def _parse_response(self, response_text: str) -> dict:
# Remove markdown code blocks if present
response_text = response_text.replace("```json", "").replace("```", "").strip()
try:
# Attempt to parse JSON
parsed_data = json.loads(response_text)
# Validate the structure
if (
not isinstance(parsed_data, dict)
or "difficult_words" not in parsed_data
):
raise ValueError("Invalid JSON structure")
return parsed_data
except json.JSONDecodeError as json_err:
logger.error(f"JSON Decode Error: {json_err}")
logger.error(f"Problematic response: {response_text}")
raise HTTPException(
status_code=400, detail="Invalid JSON response from Gemini"
)
except ValueError as val_err:
logger.error(f"Validation Error: {val_err}")
raise HTTPException(
status_code=400, detail="Invalid vocabulary extraction response"
)The complete CODE of the GeminiVocabularyService module.
class GeminiVocabularyService:
def __init__(self):
_google_api_key = os.getenv("GOOGLE_API_KEY")
# Retrieve API Key
self.api_key = _google_api_key
if not self.api_key:
raise ValueError(
"Google API Key is missing. Please set GOOGLE_API_KEY in .env file."
)
# Configure Gemini API
genai.configure(api_key=self.api_key)
# Generation Configuration
self.generation_config = {
"temperature": 0.7,
"top_p": 0.95,
"max_output_tokens": 8192,
}
# Create Generative Model
self.vocab_model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
generation_config=self.generation_config, # type: ignore
system_instruction="""
You are an expert vocabulary extractor.
For the given text:
1. Identify 3-5 challenging vocabulary words
2. Provide the following for EACH word in a STRICT JSON format:
- word: The exact word
- synonyms: List of 2-3 synonyms
- antonyms: List of 2-3 antonyms
- usecase: A brief explanation of the word's usage
- example: An example sentence using the word
IMPORTANT: Return ONLY a valid JSON that matches this structure:
{
"difficult_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"example": "string"
}
],
"medium_words": [
{
"word": "string",
"synonyms": ["string1", "string2"],
"antonyms": ["string1", "string2"],
"usecase": "string",
"example": "string"
}
],
}
""",
)
async def extract_vocabulary(self, text: str) -> dict:
try:
# Create a new chat session
chat_session = self.vocab_model.start_chat(history=[])
# Send message and await response
response = await chat_session.send_message_async(text)
# Extract and clean the text response
response_text = response.text.strip()
# Attempt to extract JSON
return self._parse_response(response_text)
except Exception as e:
logger.error(f"Vocabulary extraction error: {str(e)}")
logger.error(f"Full response: {response_text}")
raise HTTPException(
status_code=500, detail=f"Vocabulary extraction failed: {str(e)}"
)
def _parse_response(self, response_text: str) -> dict:
# Remove markdown code blocks if present
response_text = response_text.replace("```json", "").replace("```", "").strip()
try:
# Attempt to parse JSON
parsed_data = json.loads(response_text)
# Validate the structure
if (
not isinstance(parsed_data, dict)
or "difficult_words" not in parsed_data
):
raise ValueError("Invalid JSON structure")
return parsed_data
except json.JSONDecodeError as json_err:
logger.error(f"JSON Decode Error: {json_err}")
logger.error(f"Problematic response: {response_text}")
raise HTTPException(
status_code=400, detail="Invalid JSON response from Gemini"
)
except ValueError as val_err:
logger.error(f"Validation Error: {val_err}")
raise HTTPException(
status_code=400, detail="Invalid vocabulary extraction response"
)
Question-Answer Generation Service
This Question Answer Service facilities:
- Creates contextually rich comprehension questions.
- Generates precise, informative answers.
- Handles complex text analysis requirement.
- JSON and Value error handling.
This QuestionAnswerService has three methods:
__init__ method
The __init__ method is mostly the same as the Vocabulary service class except for the prompt.
Prompt:
"""
You are an expert at creating comprehensive comprehension questions and answers.
For the given text:
1. Generate 8-10 diverse questions covering:
- Vocabulary meaning
- Literary devices
- Grammatical analysis
- Thematic insights
- Contextual understanding
IMPORTANT: Return ONLY a valid JSON in this EXACT format:
{
"questions_and_answers": [
{
"question": "string",
"answer": "string"
}
]
}
Guidelines:
- Questions should be clear and specific
- Answers should be concise and accurate
- Cover different levels of comprehension
- Avoid yes/no questions
""" Code Implementation:
The __init__ method of QuestionAnswerService class
def __init__(self):
_google_api_key = os.getenv("GOOGLE_API_KEY")
# Retrieve API Key
self.api_key = _google_api_key
if not self.api_key:
raise ValueError(
"Google API Key is missing. Please set GOOGLE_API_KEY in .env file."
)
# Configure Gemini API
genai.configure(api_key=self.api_key)
# Generation Configuration
self.generation_config = {
"temperature": 0.7,
"top_p": 0.95,
"max_output_tokens": 8192,
}
self.qa_model = genai.GenerativeModel(
model_name="gemini-1.5-flash",
generation_config=self.generation_config, # type: ignore
system_instruction="""
You are an expert at creating comprehensive comprehension questions and answers.
For the given text:
1. Generate 8-10 diverse questions covering:
- Vocabulary meaning
- Literary devices
- Grammatical analysis
- Thematic insights
- Contextual understanding
IMPORTANT: Return ONLY a valid JSON in this EXACT format:
{
"questions_and_answers": [
{
"question": "string",
"answer": "string"
}
]
}
Guidelines:
- Questions should be clear and specific
- Answers should be concise and accurate
- Cover different levels of comprehension
- Avoid yes/no questions
""",
)The Question and Answer Extraction
The extract_questions_and_answers method has a chat session with Gemini, a full prompt for better extraction of questions and answers from the input text, an asynchronous message sent to the Gemini API using send_message_async(full_prompt), and then stripping response data for clean data. This method also has a private utility function just like the previous one.
Code Implementation:
extract_questions_and_answers
async def extract_questions_and_answers(self, text: str) -> dict:
"""
Extracts questions and answers from the given text using the provided model.
"""
try:
# Create a new chat session
chat_session = self.qa_model.start_chat(history=[])
full_prompt = f"""
Analyze the following text and generate comprehensive comprehension questions and answers:
{text}
Ensure the questions and answers provide deep insights into the text's meaning, style, and context.
"""
# Send message and await response
response = await chat_session.send_message_async(full_prompt)
# Extract and clean the text response
response_text = response.text.strip()
# Attempt to parse and validate the response
return self._parse_response(response_text)
except Exception as e:
logger.error(f"Question and answer extraction error: {str(e)}")
logger.error(f"Full response: {response_text}")
raise HTTPException(
status_code=500, detail=f"Question-answer extraction failed: {str(e)}"
)_parse_response
def _parse_response(self, response_text: str) -> dict:
"""
Parses and validates the JSON response from the model.
"""
# Remove markdown code blocks if present
response_text = response_text.replace("```json", "").replace("```", "").strip()
try:
# Attempt to parse JSON
parsed_data = json.loads(response_text)
# Validate the structure
if (
not isinstance(parsed_data, dict)
or "questions_and_answers" not in parsed_data
):
raise ValueError("Response must be a list of questions and answers.")
return parsed_data
except json.JSONDecodeError as json_err:
logger.error(f"JSON Decode Error: {json_err}")
logger.error(f"Problematic response: {response_text}")
raise HTTPException(
status_code=400, detail="Invalid JSON response from the model"
)
except ValueError as val_err:
logger.error(f"Validation Error: {val_err}")
raise HTTPException(
status_code=400, detail="Invalid question-answer extraction response"
)API Endpoints: Connecting Users to AI
The main file defines two primary POST endpoint:
extract-vocabulary method
It is a post method that will primarily consume input data from the clients and send it to the AI APIs through the vocabulary Extraction Service. It will also check the input text for minimum word requirements and after all, it will validate the response data using the Pydantic model for consistency and store it in the storage.
@app.post("/extract-vocabulary/", response_model=VocabularyResponse)
async def extract_vocabulary(text: str):
# Validate input
if not text or len(text.strip()) < 10:
raise HTTPException(status_code=400, detail="Input text is too short")
# Extract vocabulary
result = await vocab_service.extract_vocabulary(text)
# Store vocabulary in memory
key = hash(text)
vocabulary_storage[key] = VocabularyResponse(**result)
return vocabulary_storage[key]extract-question-answer method
This post method, will have mostly the same as the previous POST method except it will use Question Answer Extraction Service.
@app.post("/extract-question-answer/", response_model=QuestionAnswerResponse)
async def extract_question_answer(text: str):
# Validate input
if not text or len(text.strip()) < 10:
raise HTTPException(status_code=400, detail="Input text is too short")
# Extract vocabulary
result = await qa_service.extract_questions_and_answers(text)
# Store result for retrieval (using hash of text as key for simplicity)
key = hash(text)
qa_storage[key] = QuestionAnswerResponse(**result)
return qa_storage[key]There are two primary GET method:
First, the get-vocabulary method will check the hash key with the clients’ text data, if the text data is present in the storage the vocabulary will be presented as JSON data. This method is used to show the data on the CLIENT SIDE UI on the web page.
@app.get("/get-vocabulary/", response_model=Optional[VocabularyResponse])
async def get_vocabulary(text: str):
"""
Retrieve the vocabulary response for a previously processed text.
"""
key = hash(text)
if key in vocabulary_storage:
return vocabulary_storage[key]
else:
raise HTTPException(
status_code=404, detail="Vocabulary result not found for the provided text"
)Second, the get-question-answer method will also check the hash key with the clients’ text data just like the previous method, and will produce the JSON response stored in the storage to the CLIENT SIDE UI.
@app.get("/get-question-answer/", response_model=Optional[QuestionAnswerResponse])
async def get_question_answer(text: str):
"""
Retrieve the question-answer response for a previously processed text.
"""
key = hash(text)
if key in qa_storage:
return qa_storage[key]
else:
raise HTTPException(
status_code=404,
detail="Question-answer result not found for the provided text",
)Key Implementation Feature
To run the application, we have to import the libraries and instantiate a FastAPI service.
Import Libraries
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from typing import Optional
from .models import VocabularyResponse, QuestionAnswerResponse
from .services import GeminiVocabularyService, QuestionAnswerServiceInstantiate FastAPI Application
# FastAPI Application
app = FastAPI(title="English Educator API")Cross-origin Resource Sharing (CORS) Support
Cross-origin resource sharing (CORS) is an HTTP-header-based mechanism that allows a server to indicate any origins such as domain, scheme, or port other than its own from which a browser should permit loading resources. For security reasons, the browser restricts CORS HTTP requests initiated from scripts.

# FastAPI Application
app = FastAPI(title="English Educator API")
# Add CORS middleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)In-memory validation mechanism: Simple Key Word Storage
We use simple key-value-based storage for the project but you can use MongoDB.
# Simple keyword storage
vocabulary_storage = {}
qa_storage = {}Input Validation mechanisms and Comprehensive error handling.
Now is the time to run the application.
To run the application in development mode, we have to use FasyAPI CLI which will installed with the FastAPI.
Type the code to your terminal in the application root.
$ fastapi dev main.pyOutput:
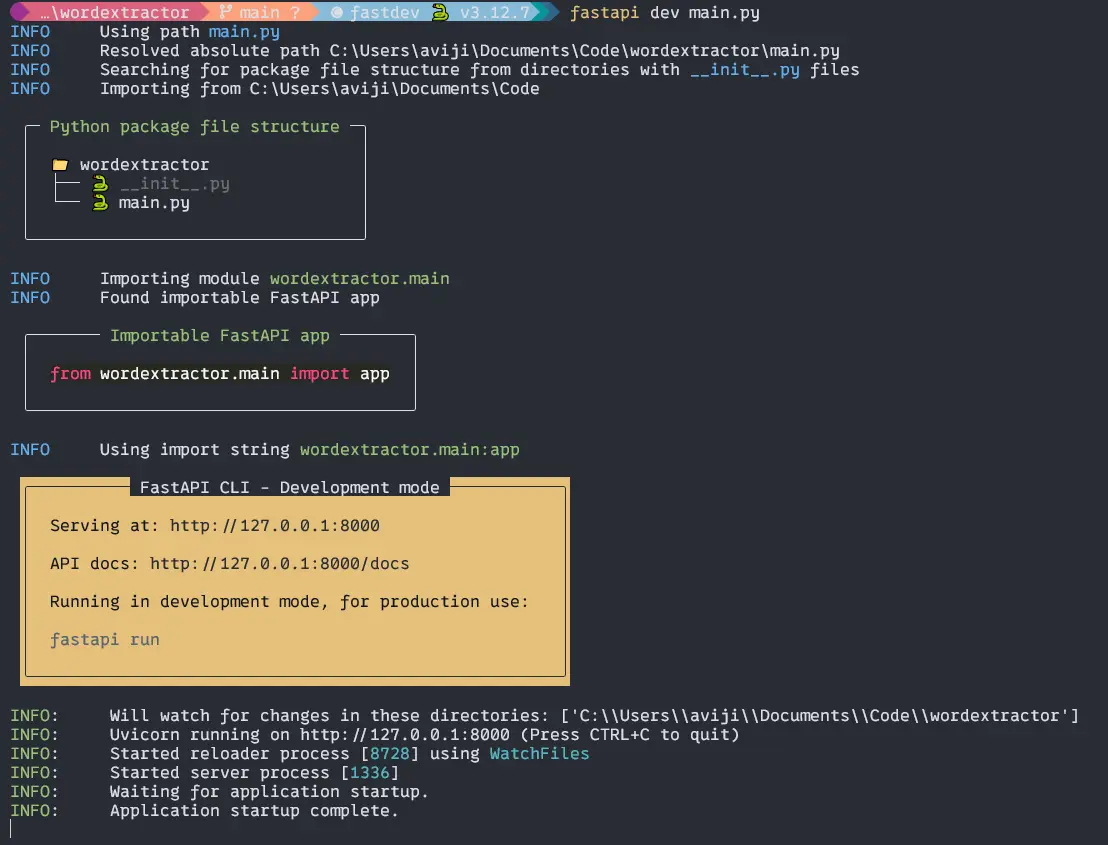
Then if you CTRL + Right Click on the link http://127.0.0.1:8000 you will get a welcome screen on the web browser.

To go to the docs page of FastAPI just click on the next URL or type http://127.0.0.1:8000/docs on your browser, and you will see all the HTTP methods on the page for testing.
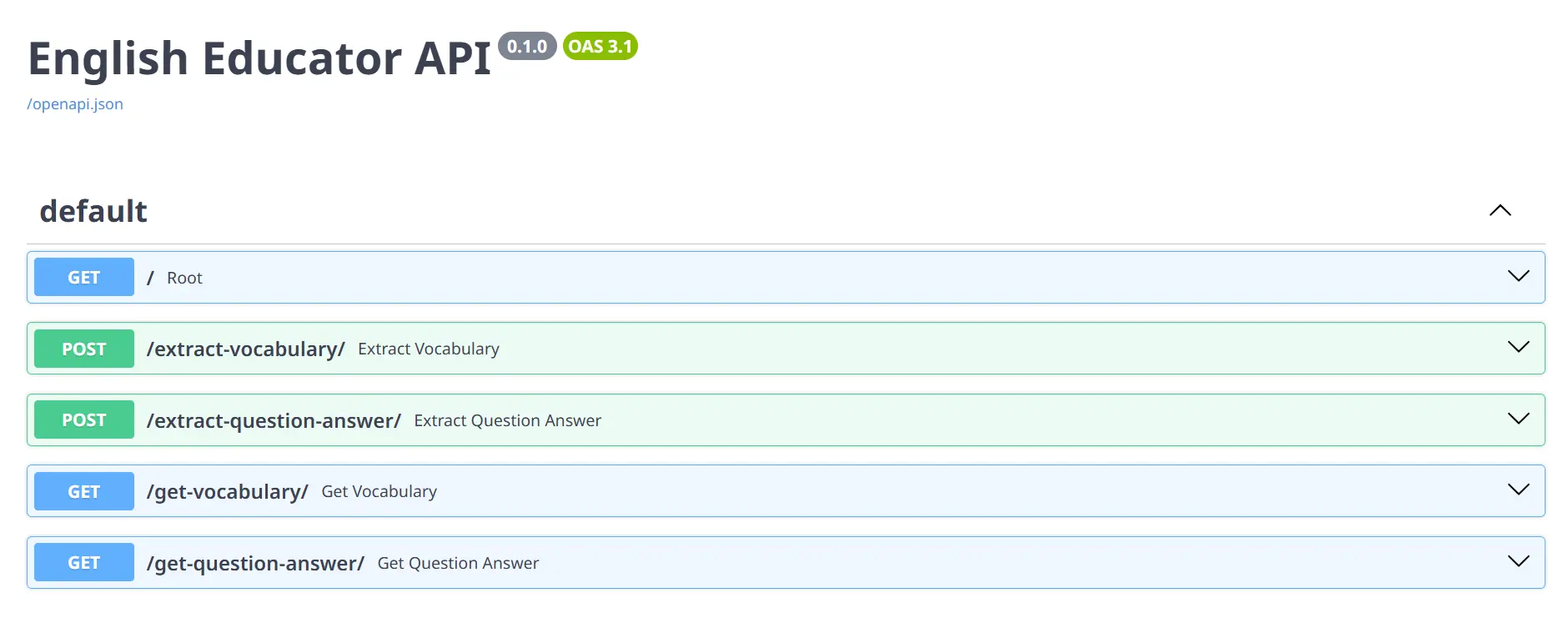
Now to test the API, Click on any of the POST methods and TRY IT OUT, put any text you want to in the input field, and execute. You will get the response according to the services such as vocabulary, and question answer.
Vocabulary Extraction
Execute:
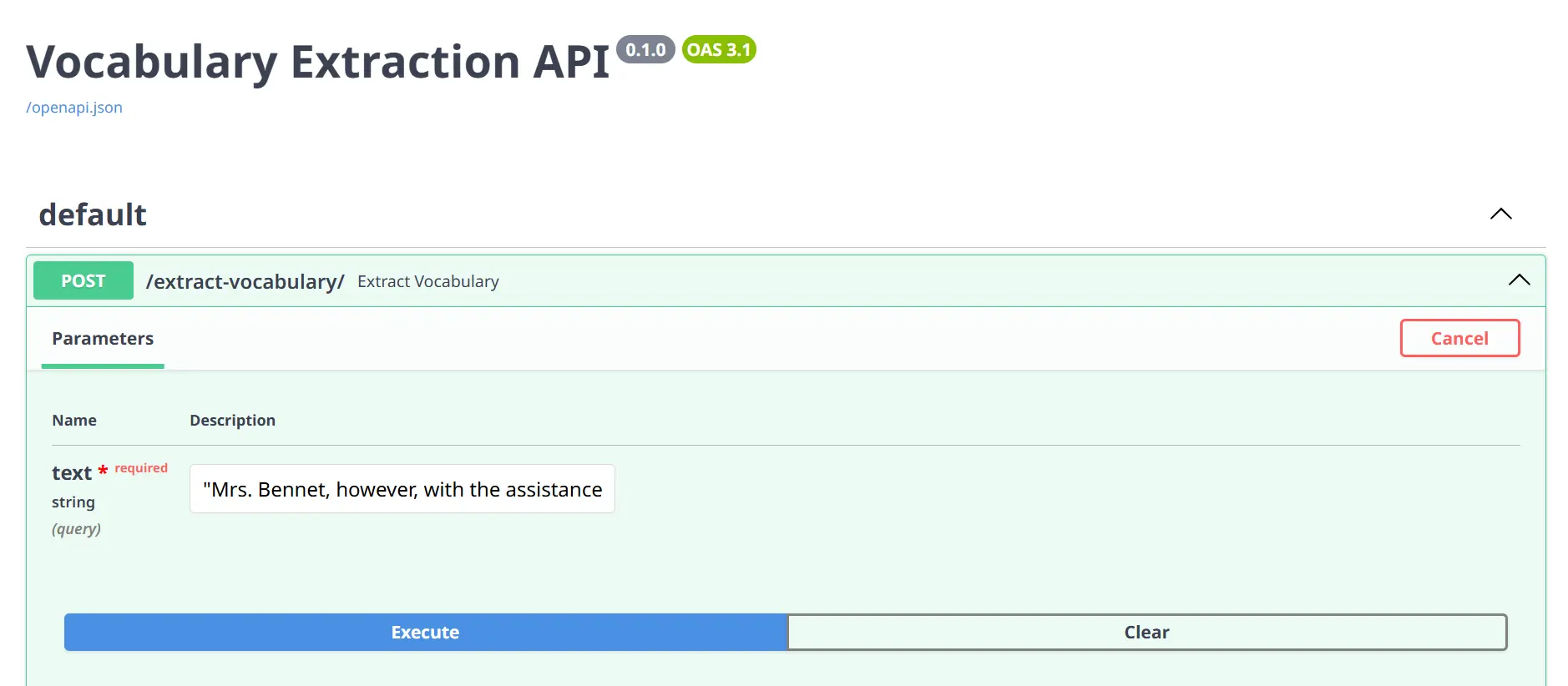
Response:
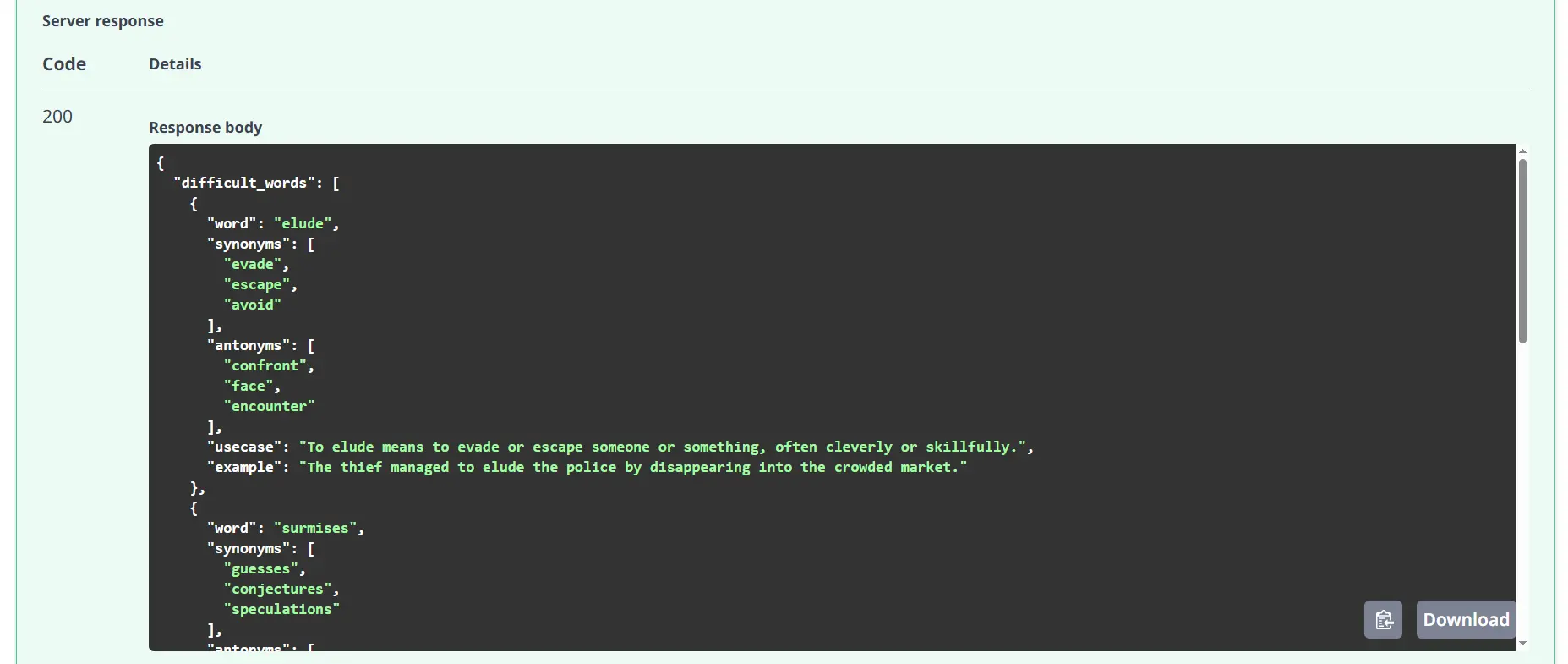
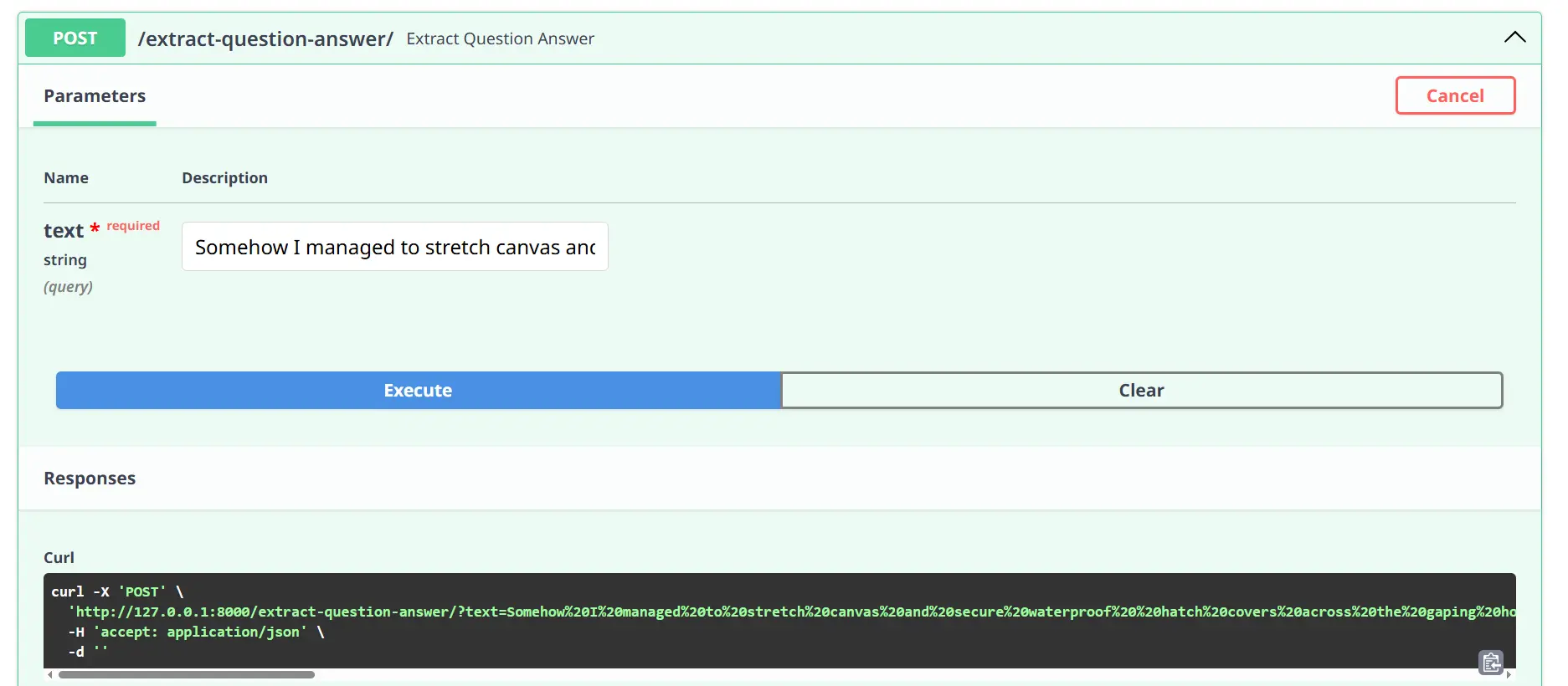
Question Answer Extraction
Execute:
Response:
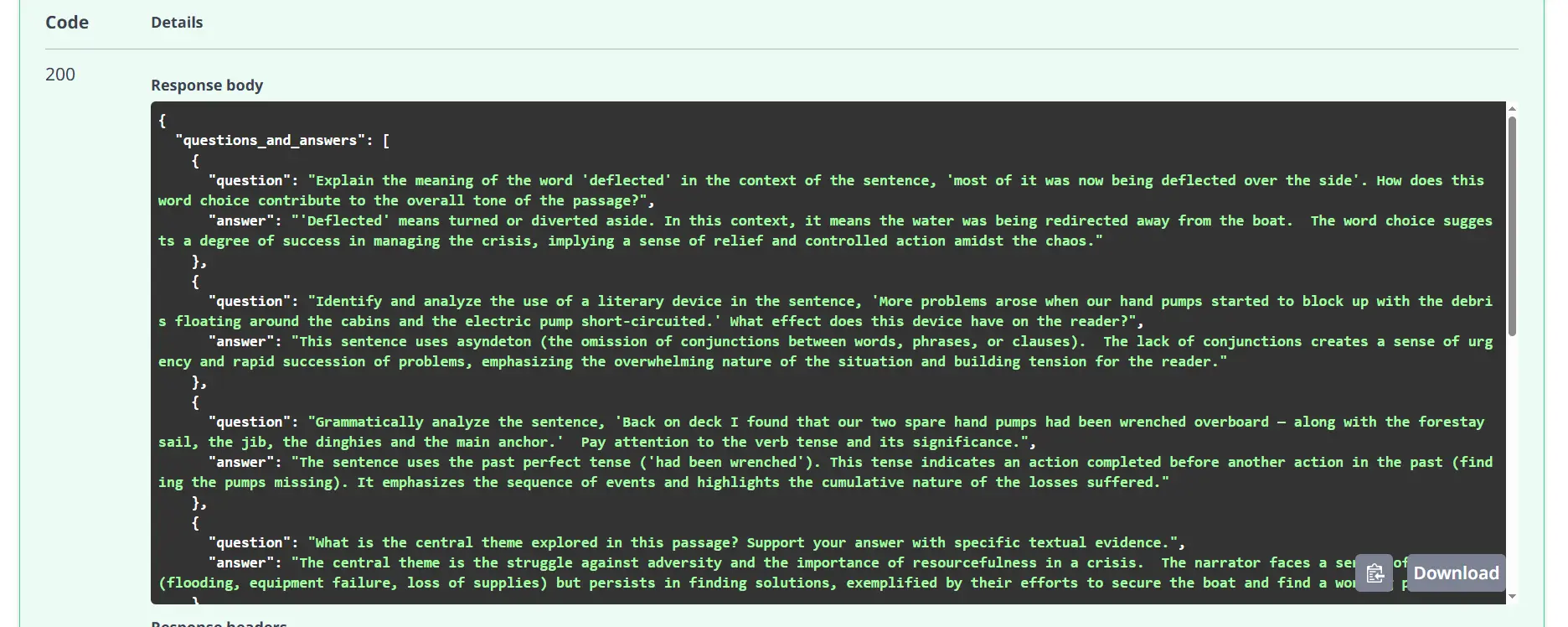
Testing Get Methods
Get vocabulary from the storage.
Execute:
Put the same text you put on the POST method on the input field.
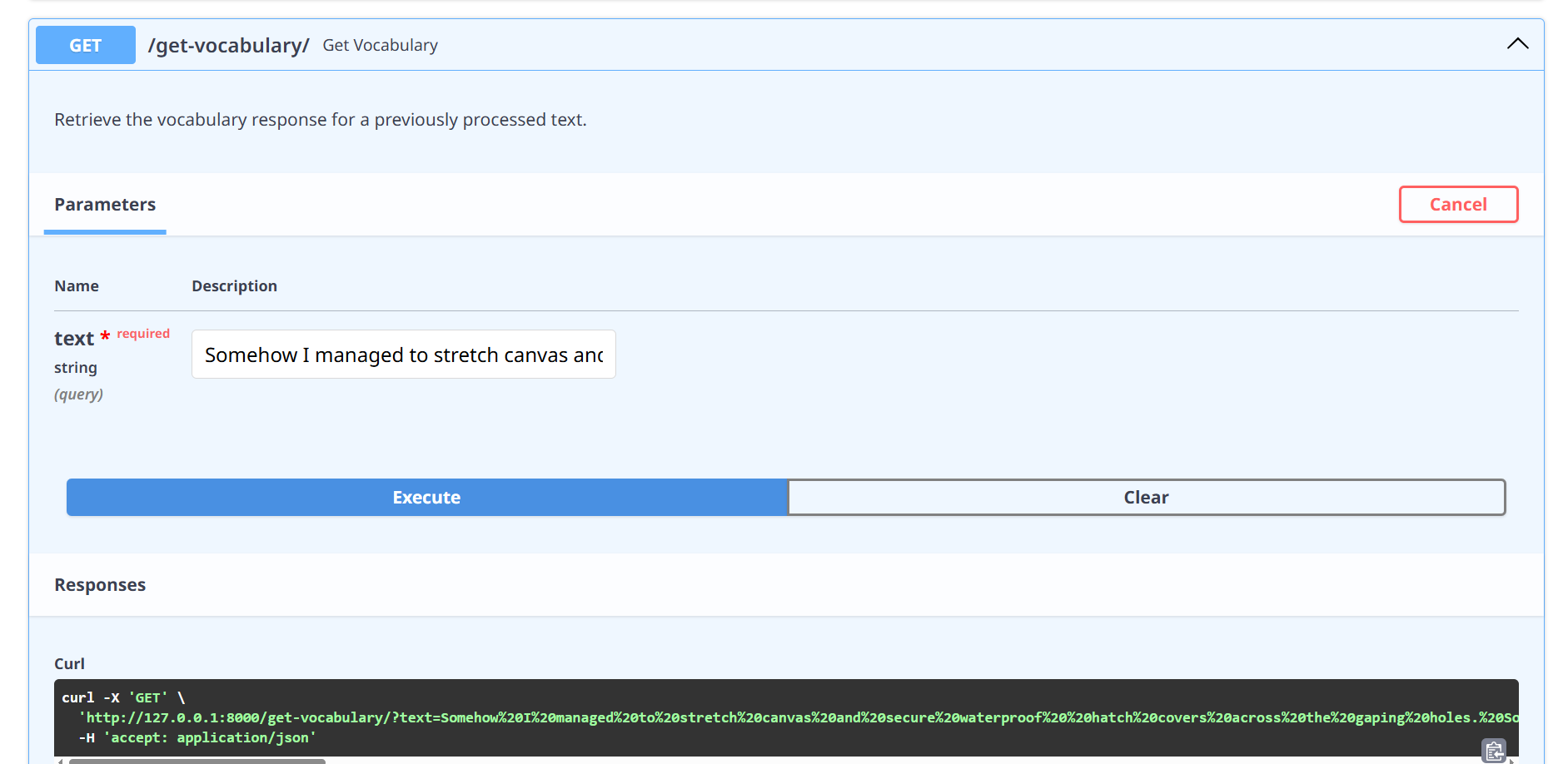
Response:
You will get the below output from the storage.
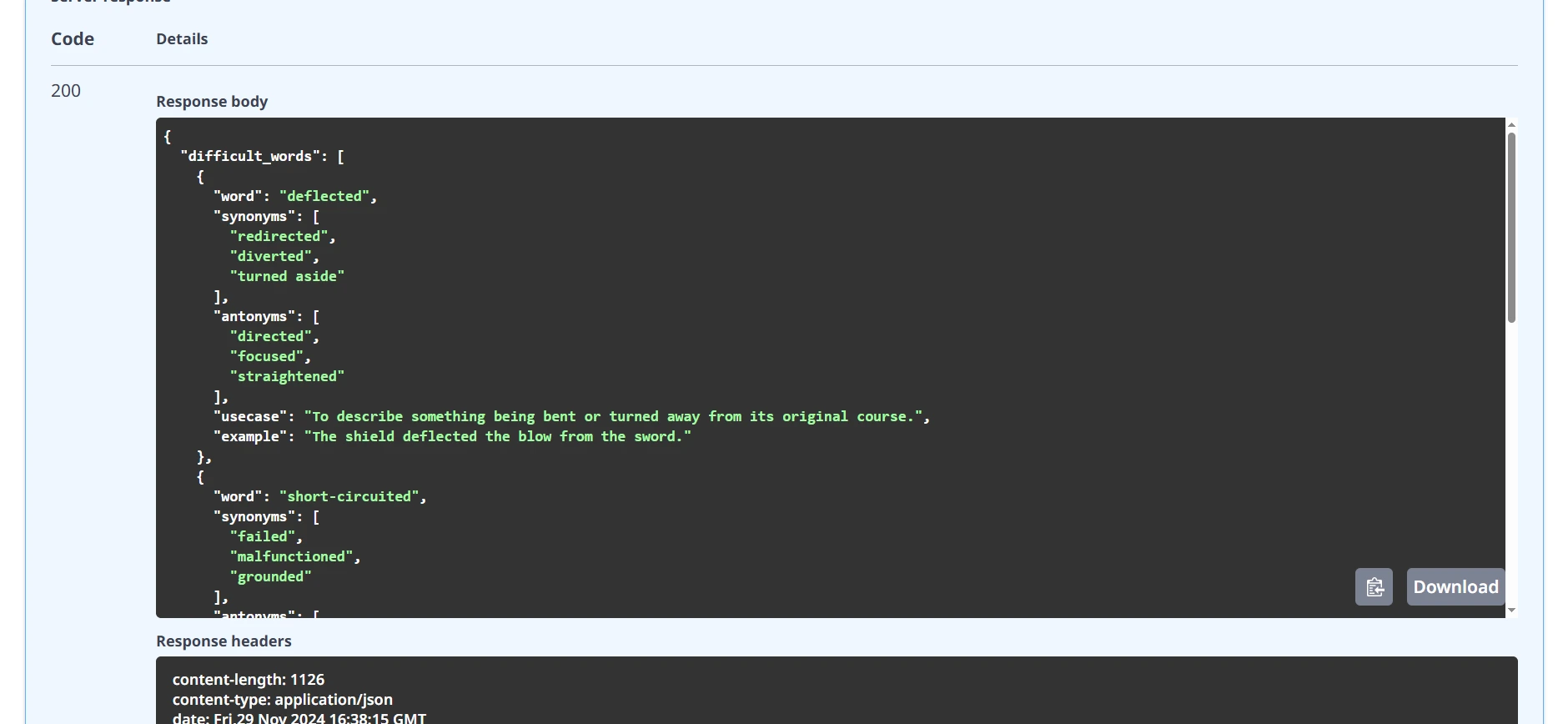
and also for question-and-answer
Execute:
Response:
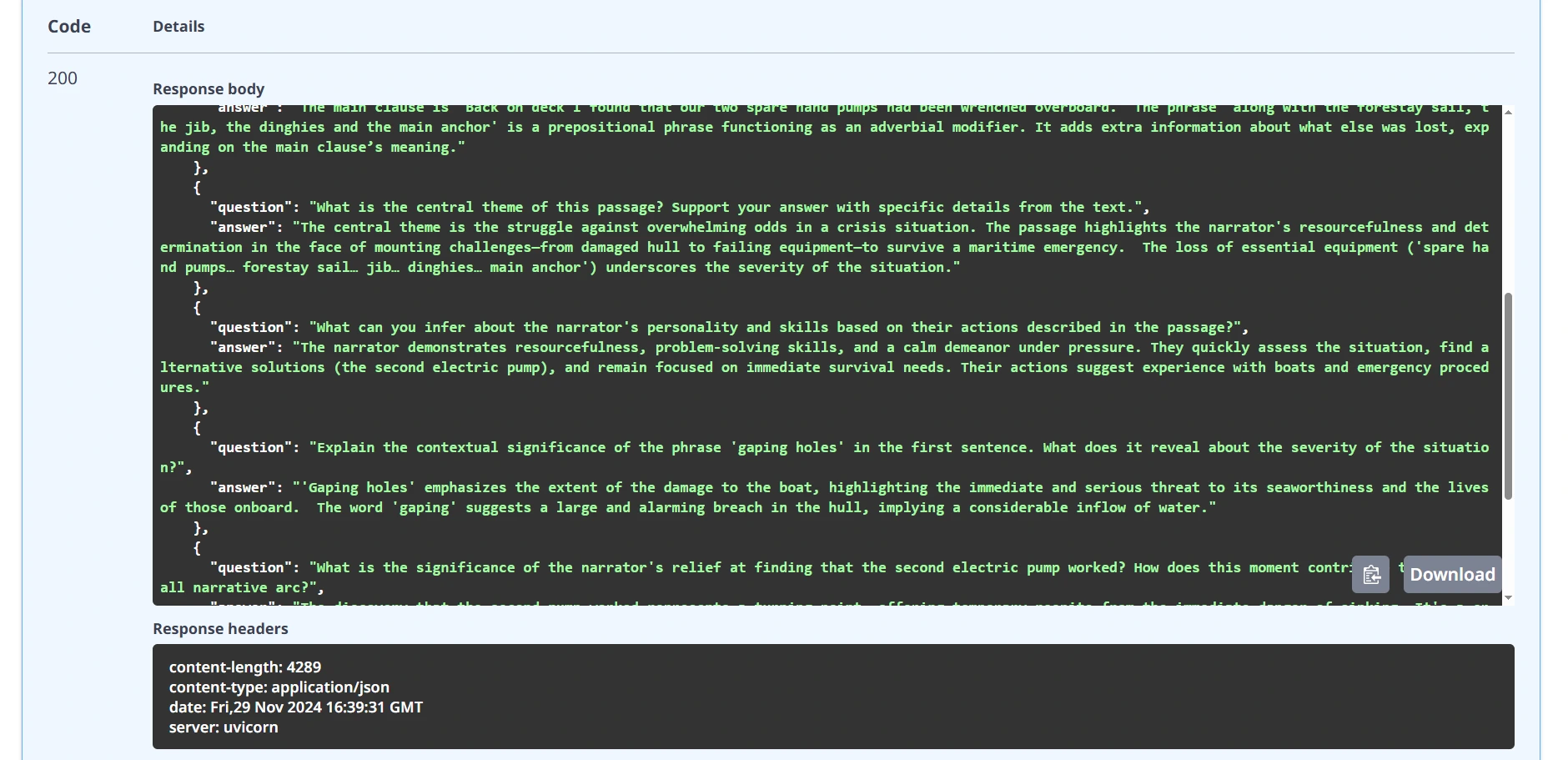
That will be fully running web server API for English educators using Google Gemini AI.
Further Development Opportunity
The current implementation opens doors to exciting future enhancements:
- Explore persistent storage solutions to retain data effectively across sessions.
- Integrate robust authentication mechanisms for enhanced security.
- Advance text analysis capabilities with more sophisticated features.
- Design and build an intuitive front-end interface for better user interaction.
- Implement efficient rate limiting and caching strategies to optimize performance.
Practical Considerations and Limitations
While our API demonstrates powerful capabilities, you should consider:
- Consider API usage costs and rate limits when planning usage to avoid unexpected charges and ensure scalability.
- Be mindful of processing time for complex texts, as longer or intricate inputs may result in slower response times.
- Prepare for continuous model updates from Google, which may impact the API’s performance or capabilities over time.
- Understand that AI-generated responses can vary, so it’s important to account for potential inconsistencies in output quality.
Conclusion
We have created a flexible, intelligent API that transforms text analysis through the synergy of Google Gemini, FastAPI, and Pydantic. This solution demonstrates how modern AI technologies can be leveraged to extract deep, meaningful insights from textual data.
You can get all the code of the project in the CODE REPO.
Key Takeaways
- AI-powered APIs can provide intelligent, context-aware text analysis.
- FastAPI simplifies complex API development with automatic documentation.
- The English Educator App API empowers developers to create interactive and personalized language learning experiences.
- Integrating the English Educator App API can streamline content delivery, improving both educational outcomes and user engagement.
Frequently Asked Questions
Q1. How secure is this API implementation?
A. The current version uses environment-based API key management and includes fundamental input validation. For production, additional security layers are recommended.
Q2. Can this API be used in commercial applications?
A. Always review Google Gemini’s current terms of service and licensing for commercial implementations.
Q3. What are the performance characteristics?
A. Performance depends on Gemini API response times, input complexity, and your specific processing requirements.
Q4. What is the English Educator App API and how can it help educators?
A. The English Educator App API provides tools for educators to create personalized language learning experiences, offering features like vocabulary extraction, pronunciation feedback, and advanced text analysis.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A self-taught, project-driven learner, love to work on complex projects on deep learning, Computer vision, and NLP. I always try to get a deep understanding of the topic which may be in any field such as Deep learning, Machine learning, or Physics. Love to create content on my learning. Try to share my understanding with the worlds.





