Do you use GPT-4o, GPT-4o Mini, or GPT-3.5 Turbo? Understanding the costs associated with each model is crucial for managing your budget effectively. By tracking usage at the task level, you get a detailed perspective of costs associated with your project. Let’s explore how to monitor and manage your OpenAI API Price usage efficiently in the following sections.

Table of contents
OpenAI API Price
These are the prices per 1 million tokens:
| Model | Input Tokens (per 1M) | Output Tokens (per 1M) |
| GPT-3.5-Turbo | $3.00 | $6.00 |
| GPT-4 | $30.00 | $60.00 |
| GPT-4o | $2.50 | $10.00 |
| GPT-4o-mini | $0.15 | $0.60 |
- GPT-4o-mini is the most affordable option, costing significantly less than the other models, with a context length of 16k, making it ideal for lightweight tasks that do not require processing large amounts of input or output tokens.
- GPT-4 is the most expensive model, with a context length of 32k, providing unmatched performance for tasks requiring extensive input-output interactions or complex reasoning.
- GPT-4o offers a balanced option for high-volume applications, combining a lower cost with a larger context length of 128k, making it suitable for tasks requiring detailed, high-context processing at scale.
- GPT-3.5-Turbo, with a context length of 16k, is not a multimodal option and only processes text input, offering a middle ground in terms of cost and functionality.
For reduced costs you can consider Batch API which is charged 50% less on both Input Tokens and Output Tokens. Cached Inputs also help reduce costs:
Cached Inputs: Cached inputs refer to tokens that have been previously processed by the model, allowing for faster and cheaper reuse in subsequent requests. It reduces Input Tokens costs by 50%.
Batch API: The Batch API allows for submitting multiple requests together, processing them in bulk and gives the response within a 24-hour window.
Costs in Actual Usage
You could always check your OpenAI dashboard to track your usage and check activity to see the number of requests sent: OpenAI Platform.
Let’s focus on tracking it per request to get a task-level idea. Let’s send a few prompts to the models and estimate the cost incurred.
from openai import OpenAI
# Initialize the OpenAI client
client = OpenAI(api_key = "API-KEY")
# Models and costs per 1M tokens
models = [
{"name": "gpt-3.5-turbo", "input_cost": 3.00, "output_cost": 6.00},
{"name": "gpt-4", "input_cost": 30.00, "output_cost": 60.00},
{"name": "gpt-4o", "input_cost": 2.50, "output_cost": 10.00},
{"name": "gpt-4o-mini", "input_cost": 0.15, "output_cost": 0.60}
]
# A question to ask the models
question = "What's the largest city in India?"
# Initialize an empty list to store results
results = []
# Loop through each model and send the request
for model in models:
completion = client.chat.completions.create(
model=model["name"],
messages=[
{"role": "user", "content": question}
]
)
# Extract the response content and token usage from the completion
response_content = completion.choices[0].message.content
input_tokens = completion.usage.prompt_tokens
output_tokens = completion.usage.completion_tokens
total_tokens = completion.usage.total_tokens
model_name = completion.model
# Calculate the cost based on token usage (cost per million tokens)
input_cost = (input_tokens / 1_000_000) * model["input_cost"]
output_cost = (output_tokens / 1_000_000) * model["output_cost"]
total_cost = input_cost + output_cost
# Append the result to the results list
results.append({
"Model": model_name,
"Input Tokens": input_tokens,
"Output Tokens": output_tokens,
"Total cost": total_cost,
"Response": response_content
})
import pandas as pd
# display the results in a table format
df = pd.DataFrame(results)
df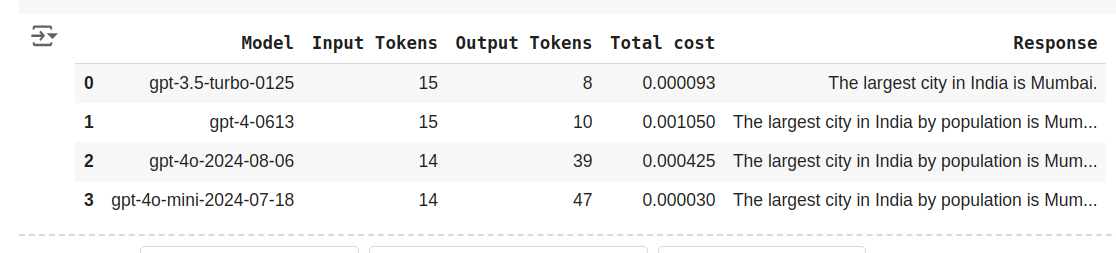
The costs are $ 0.000093, $ 0.001050, $ 0.000425, $ 0.000030 for GPT-3.5-Turbo, GPT-4, GPT-4o and GPT-4o-mini respectively. The cost is dependent on both input tokens and output tokens and we can see that despite GPT-4o-mini generating 47 tokens for the question “What’s the largest city in India” it’s the cheapest among all the other models here.
Note: Tokens are a sequence of characters and they’re not exactly words and notice that the input tokens are different despite the prompt being the same as they use a different tokenizer.
How to reduce costs?
Set an upper limit on Max Tokens
question = "Explain VAE?"
completion = client.chat.completions.create(
model='gpt-4o-mini-2024-07-18',
messages=[
{"role": "user", "content": question}
],
max_tokens=50 # Set the desired upper limit for output tokens
)
print("Output Tokens: ",completion.usage.completion_tokens, "\n")
print("Output: ", completion.choices[0].message.content)Limiting the output tokens helps reduce costs and this will also let the model focus more on the answer. But choosing an appropriate number for the limit is crucial here.
Batch API
Using Batch API reduces costs by 50% on both Input Tokens and Output Tokens, the only trade-off here is that it takes some time to get the responses (It can be up to 24 hours depending on the number of requests).
question="What's a tokenizer"Creating a dictionary with request parameters for a POST request.
input_dict = {
"custom_id": f"request-1",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini-2024-07-18",
"messages": [
{
"role": "user",
"content": question
}
],
"max_tokens": 100
}
}Writing the serialized input_dict to a JSONL file.
import json
request_file = "/content/batch_request_file.jsonl"
with open(request_file, 'w') as f:
f.write(json.dumps(input_dict))
f.write('\n')
print(f"Successfully wrote a dictionary to {request_file}.")Sending a Batch Request using ‘client.batches.create’
from openai import OpenAI
client = OpenAI(api_key = "API-KEY")
batch_input_file = client.files.create(
file=open(request_file, "rb"),
purpose="batch"
)
batch_input_file_id = batch_input_file.id
input_batch = client.batches.create(
input_file_id=batch_input_file_id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={
"description": "GPT4o-Mini-Test"
}
)Checking the status of the batch, it can take up to 24 hours to get the response. If the number of requests or batches are less it should be quick enough (like in this example).
status_response = client.batches.retrieve(input_batch.id)
print(input_batch.id,status_response.status, status_response.request_counts)
completed BatchRequestCounts(completed=1, failed=0, total=1)
if status_response.status == 'completed':
output_file_id = status_response.output_file_id
# Retrieve the content of the output file
output_response = client.files.content(output_file_id)
output_content = output_response.content
# Write the content to a file
with open('/content/batch_output.jsonl', 'wb') as f:
f.write(output_content)
print("Batch results saved to batch_output.jsonl")This is the response I received in the JSONL file:
"content": "A tokenizer is a tool or process used in natural language
processing (NLP) and text analysis that splits a stream of text into
smaller, manageable pieces called tokens. These tokens can represent various
data units such as words, phrases, symbols, or other meaningful elements in
the text.\\n\\nThe process of tokenization is crucial for various NLP
applications, including:\\n\\n1. **Text Analysis**: Breaking down text into
components makes it easier to analyze, allowing for tasks like frequency
analysis, sentiment analysis, and more"
Conclusion
Understanding and managing ChatGPT API Cost is essential for maximizing the value of OpenAI’s models in your projects. By analyzing token usage and model-specific pricing, you can make informed decisions to balance performance and affordability. Among the options, GPT-4o-mini is a cost-effective model for most of the tasks, while GPT-4o offers a powerful yet economical alternative for high-volume applications as it has a bigger context length at 128k. Batch API is another helpful alternative to help save costs for bulk processing for non-urgent tasks.
Also if you are looking for a Generative AI course online then explore: GenAI Pinnacle Program
Frequently Asked Questions
Q1. How can I reduce the OpenAI API Price?
Ans. You can reduce costs by setting an upper limit on Max Tokens, using Batch API for bulk processing
Q2. How to manage spending?
Ans. Set a monthly budget in your billing settings to stop requests once the limit is reached. You can also set an email alert for when you approach your budget and monitor usage through the tracking dashboard.
Q3. Is the Playground chargeable?
Ans. Yes, Playground usage is considered the same as regular API usage.
Q4. What are some examples of vision models in AI?
Ans. Examples include gpt-4-vision-preview, gpt-4-turbo, gpt-4o and gpt-4o-mini which process and analyze both text and images for various tasks.
Passionate about technology and innovation, a graduate of Vellore Institute of Technology. Currently working as a Data Science Trainee, focusing on Data Science. Deeply interested in Deep Learning and Generative AI, eager to explore cutting-edge techniques to solve complex problems and create impactful solutions.





