DeepSeek AI has just released its highly anticipated DeepSeek R1 reasoning models, setting new standards in the world of generative artificial intelligence. With a focus on reinforcement learning (RL) and an open-source ethos, DeepSeek-R1 delivers advanced reasoning capabilities while being accessible to researchers and developers around the world. The model is set to compete with OpenAI’s o1 model and infact has outperformed the same on several benchmarks. With DeepSeek R1, it surely has made a lot of people wonder if is it an end to Open AI LLM supremacy. Let’s dive in to read more!
Table of contents
What’s DeepSeek R1?
DeepSeek-R1 is a reasoning-focused large language model (LLM) developed to enhance reasoning capabilities in Generative AI systems through the method of advanced reinforcement learning (RL) techniques.
- It represents a significant step toward improving reasoning in LLMs, particularly without relying heavily on supervised fine-tuning (SFT) as a preliminary step.
- Essentially, DeepSeek-R1 addresses a key challenge in AI: enhancing reasoning without relying heavily on supervised fine-tuning (SFT).
Innovative training methodologies power the models to tackle complex tasks like mathematics, coding, and logic.

Also Read: Andrej Karpathy Praises DeepSeek V3’s Frontier LLM, Trained on a $6M Budget
DeepSeek-R1: Training
1. Reinforcement Learning
- DeepSeek-R1-Zero is trained exclusively using reinforcement learning (RL) without any SFT. This unique approach incentivizes the model to autonomously develop advanced reasoning capabilities like self-verification, reflection, and CoT (Chain-of-Thought) reasoning.
Reward Design
- The system assigns rewards for reasoning accuracy based on task-specific benchmarks.
- It also gives secondary rewards for structured, readable, and coherent reasoning outputs.
Rejection Sampling
- During RL, multiple reasoning trajectories are generated, and the best-performing ones are selected to guide the training process further.
2. Cold-Start Initialization with Human-Annotated Data
- For DeepSeek-R1, human-annotated examples of long CoT reasoning are used to initialize the training pipeline. This ensures better readability and alignment with user expectations.
- This step bridges the gap between pure RL training (which can lead to fragmented or ambiguous outputs) and high-quality reasoning outputs.
3. Multi-Stage Training Pipeline
- Stage 1: Cold-Start Data Pretraining: A curated dataset of human annotations primes the model with basic reasoning structures.
- Stage 2: Reinforcement Learning: The model tackles RL tasks, earning rewards for accuracy, coherence, and alignment.
- Stage 3: Fine-Tuning with Rejection Sampling: The system fine-tunes outputs from RL and reinforces the best reasoning patterns.
4. Distillation
- Larger models trained with this pipeline are distilled into smaller versions, maintaining reasoning performance while drastically reducing computational costs.
- Distilled models inherit the capabilities of larger counterparts, such as DeepSeek-R1, without significant performance degradation.
DeepSeek R1: Models
DeepSeek R1 comes with two core and six distilled models.
Core Models
DeepSeek-R1-Zero
Trained exclusively through reinforcement learning (RL) on a base model, without any supervised fine-tuning.Demonstrates advanced reasoning behaviors like self-verification and reflection, achieving notable results on benchmarks such as:
- AIME 2024
- Codeforces
Challenges: Struggles with readability and language mixing due to a lack of cold-start data and structured fine-tuning.
DeepSeek-R1
Builds upon DeepSeek-R1-Zero by incorporating cold-start data (human-annotated long chain-of-thought (CoT) examples) for enhanced initialization.Introduces multi-stage training, including reasoning-oriented RL and rejection sampling for better alignment with human preferences.
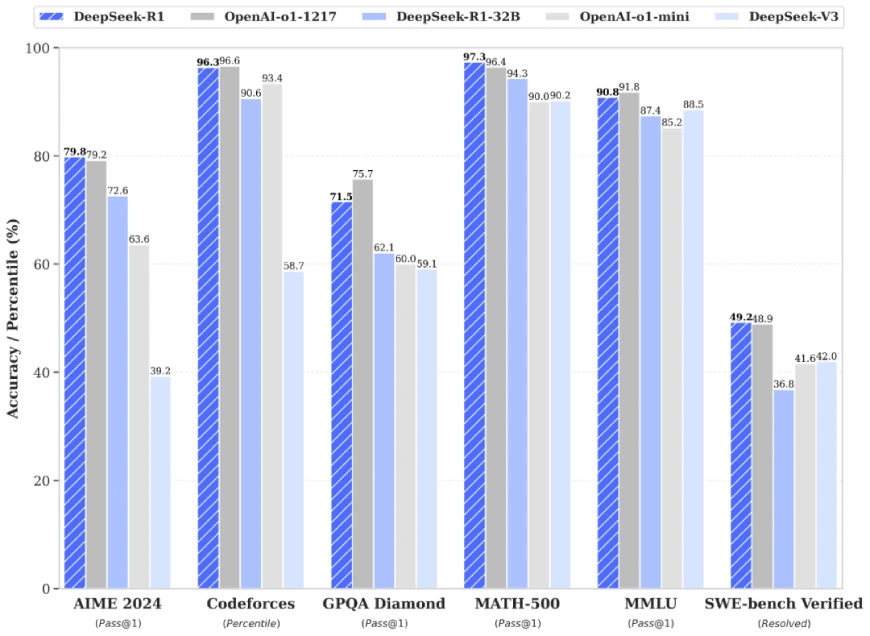
Competes directly with OpenAI’s o1-1217, achieving:
- AIME 2024: Pass@1 score of 79.8%, marginally outperforming o1-1217.
- MATH-500: Pass@1 score of 97.3%, on par with o1-1217.
Excels in knowledge-intensive and STEM-related tasks, as well as coding challenges.
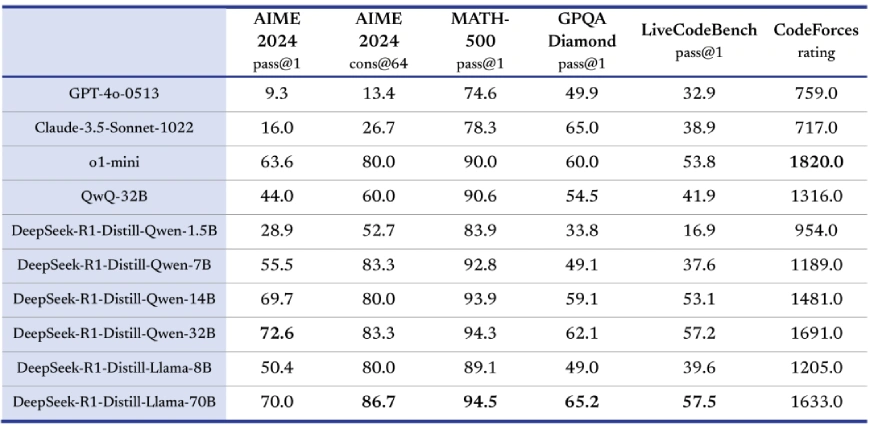
Distilled Models
In a groundbreaking move, DeepSeek-AI has also released distilled versions of the R1 model, ensuring that smaller, computationally efficient models inherit the reasoning prowess of their larger counterparts. These distilled models include:
- Qwen Series
- Llama Series
These smaller models outperform open-source competitors like QwQ-32B-Preview while competing effectively with proprietary models like OpenAI’s o1-mini.
DeepSeek R1: Key Highlights
DeepSeek-R1 models are engineered to rival some of the most advanced LLMs in the industry. On benchmarks such as AIME 2024, MATH-500, and Codeforces, DeepSeek-R1 demonstrates competitive or superior performance when compared to OpenAI’s o1-1217 and Anthropic’s Claude Sonnet 3:
- AIME 2024 (Pass@1)
- MATH-500
- Codeforces
In addition to its high performance, DeepSeek-R1’s open-source availability positions it as a cost-effective alternative to proprietary models, reducing barriers to adoption.
How to Access R1?
Web Access
Unlike OpenAI’s o1 for which you have to pay a premium price, DeepSeek has made its R1 model free for everyone to try in their chat interface.
- Head to:https://chat.deepseek.com/
- Sign up and click on Deepthink.
- It automatically chooses Deepthink R1.
API Access
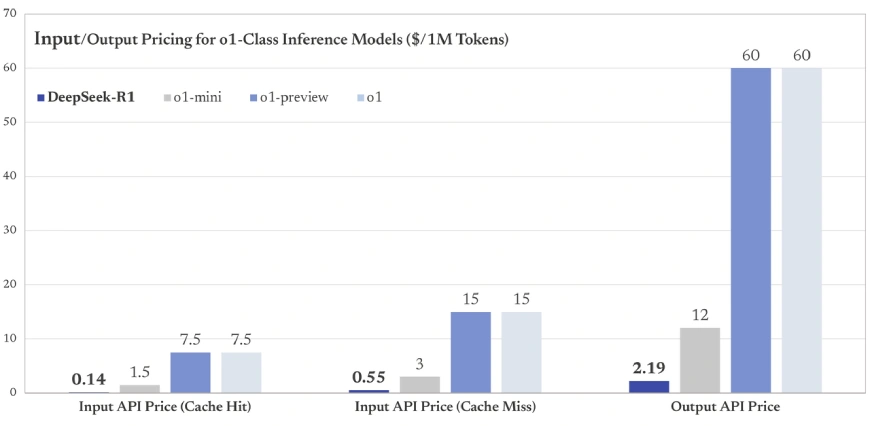
You can access its API here: https://api-docs.deepseek.com/
With a base input cost as low as $0.14 per million tokens for cache hits, DeepSeek-R1 is significantly more affordable than many proprietary models (e.g., OpenAI GPT-4 input costs start at $0.03 per 1K tokens or $30 per million tokens).
Applications
- STEM Education: Excelling in math-intensive benchmarks, these models can assist educators and students in solving complex problems.
- Coding and Software Development: With high performance on platforms like Codeforces and LiveCodeBench, DeepSeek-R1 is ideal for aiding developers.
- General Knowledge Tasks: Its prowess in benchmarks like GPQA Diamond positions it as a powerful tool for fact-based reasoning.
Also Read:
Conclusion
By open-sourcing the DeepSeek-R1 family of models, including the distilled versions, DeepSeek-AI is making high-quality reasoning capabilities accessible to the broader AI community. This initiative not only democratizes access but also fosters collaboration and innovation.
As the AI landscape evolves, DeepSeek-R1 stands out as a beacon of progress, bridging the gap between open-source flexibility and state-of-the-art performance. With its potential to reshape reasoning tasks across industries, DeepSeek-AI is poised to become a key player in the AI revolution.
Join the revolution in AI with our “Getting Started with DeepSeek” course! Learn how DeepSeek R1 outperforms competitors like OpenAI’s o1 and unlock its potential for your projects. Enroll today and stay ahead in the AI landscape!
Stay tuned for more updates on Analytics Vidhya News!
Anu Madan has 5+ years of experience in content creation and management. Having worked as a content creator, reviewer, and manager, she has created several courses and blogs. Currently, she working on creating and strategizing the content curation and design around Generative AI and other upcoming technology.





