
In today’s fast-paced business environment, organizations are inundated with data that drives decisions, optimizes operations, and maintains competitiveness. However, extracting actionable insights from this data remains a significant hurdle. A Retrieval-Augmented Generation (RAG) system, when integrated with Agentic AI, tackles this challenge by not only retrieving relevant information but also processing and delivering context-aware insights in real-time. This combination allows businesses to create intelligent agents that autonomously query datasets, adapt, and extract insights on product features, integrations, and operations.
By merging RAG with Agentic AI, businesses can enhance decision-making and convert scattered data into valuable intelligence. This blog explores the process of building a RAG pipeline with Agentic AI, offering technical insights and code examples to empower smart decision-making in organizations.
Learning Objectives
- Learn how to automatically extract and scrape relevant data from multiple web sources using Python and scraping tools, forming the foundation for any company intelligence platform.
- Learn how to structure and process scraped data into valuable, actionable insights by extracting key points such as product functionalities, integrations, and troubleshooting steps using AI-driven techniques.
- Learn how to integrate RAG with document retrieval and natural language generation to build an intelligent querying system capable of delivering context-aware answers from vast datasets.
- Understand how to build an agentic AI system that combines data scraping, knowledge extraction, and real-time query processing, enabling businesses to extract actionable insights autonomously.
- Gain an understanding of how to scale and deploy such a system using cloud platforms and distributed architectures, ensuring it can handle large datasets and high query loads effectively.
This article was published as a part of the Data Science Blogathon.
Table of contents
Data Extraction Using BFS and Scraping the Data
The first step in building a robust RAG system for company intelligence is collecting the necessary data. Since data can come from various web sources, scraping and organizing it efficiently is key. One effective technique for discovering and collecting the relevant pages is Breadth-First Search (BFS). BFS helps us recursively discover links starting from a main page, gradually expanding the search to deeper levels. This ensures that we gather all relevant pages without overwhelming the system with unnecessary data.
In this section, we’ll look at how to extract links from a website using BFS, followed by scraping the content from those pages. Using BFS, we systematically traverse websites, collect data, and create a meaningful dataset for processing in a RAG pipeline.
Step 1: Link Extraction Using BFS
To begin, we need to collect all the relevant links from a given website. Using BFS, we can explore the links on the homepage, and from there, follow links on other pages recursively up to a specified depth. This method ensures that we capture all the necessary pages that might contain the relevant company data, such as product features, integrations, or other key details.
The code below performs link extraction from a starting URL using BFS. It begins by fetching the main page, extracts all links (<a> tags with href attributes), and then follows these links to subsequent pages, recursively expanding the search based on a given depth limit.
Here is the code to perform link extraction:
import requests
from bs4 import BeautifulSoup
from collections import deque
# Function to extract links using BFS
def bfs_link_extraction(start_url, max_depth=3):
visited = set() # To track visited links
queue = deque([(start_url, 0)]) # Queue to store URLs and current depth
all_links = []
while queue:
url, depth = queue.popleft()
if depth > max_depth:
continue
# Fetch the content of the URL
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Extract all links in the page
links = soup.find_all('a', href=True)
for link in links:
full_url = link['href']
if full_url.startswith('http') and full_url not in visited:
visited.add(full_url)
queue.append((full_url, depth + 1))
all_links.append(full_url)
except requests.exceptions.RequestException as e:
print(f"Error fetching {url}: {e}")
return all_links
# Start the BFS from the homepage
start_url = 'https://www.example.com' # Replace with the actual homepage URL
all_extracted_links = bfs_link_extraction(start_url)
print(f"Extracted {len(all_extracted_links)} links.")We maintain a queue to track the URLs to visit along with their corresponding depths, ensuring efficient traversal. A visited set is used to prevent revisiting the same URL multiple times. For each URL, we use BeautifulSoup to parse the HTML and extract all links (tags with href attributes). The process uses BFS traversal, recursively fetching each URL’s content, extracting links, and exploring further until reaching the depth limit. This approach ensures we efficiently explore the web without redundancy.
Output
This code outputs a list of links extracted from the website, up to the specified depth.
Extracted 1500 links.The output shows that the system found and collected 1500 links from the starting website and its linked pages up to a depth of 3. You would replace https://www.example.com with your actual target URL. Below is the output screenshot of the original code. Sensitive information has been masked to maintain integrity.
Step 2: Scraping Data from Extracted Links
Once we’ve extracted the relevant links using BFS, the next step is to scrape the content from these pages. We’ll look for key information such as product features, integrations, and any other relevant data that will help us build a structured dataset for the RAG system.
In this step, we loop through the list of extracted links and scrape key content, such as the title of the page and its main content. You can adjust this code to scrape additional data points as needed (e.g., product features, pricing, or FAQ information).
import json
# Function to scrape and extract data from the URLs
def scrape_data_from_links(links):
scraped_data = []
for link in links:
try:
response = requests.get(link)
soup = BeautifulSoup(response.content, 'html.parser')
# Example: Extract 'title' and 'content' (modify according to your needs)
title = soup.find('title').get_text()
content = soup.find('div', class_='content').get_text() # Adjust selector
# Store the extracted data
scraped_data.append({
'url': link,
'title': title,
'content': content
})
except requests.exceptions.RequestException as e:
print(f"Error scraping {link}: {e}")
return scraped_data
# Scrape data from the extracted links
scraped_contents = scrape_data_from_links(all_extracted_links)
# Save scraped data to a JSON file
with open('/content/scraped_data.json', 'w') as outfile:
json.dump(scraped_contents, outfile, indent=4)
print("Data scraping complete.")For each URL in the list, we send an HTTP request to fetch the page’s content and parse it using BeautifulSoup to extract the title and main content. We store the extracted data in a list of dictionaries, each containing the URL, title, and content. Finally, we save the scraped data into a JSON file, ensuring it’s available for later processing in the RAG pipeline. This process ensures efficient collection and storage of relevant data for further use.
Output
The output of this code would be a saved JSON file (scraped_data.json) containing the scraped data from the links. An example of the data structure could look like this:
[
{
"url": "https://www.example.com/page1",
"title": "Page 1 Title",
"content": "This is the content of the first page. It contains
information about integrations and features."
},
{
"url": "https://www.example.com/page2",
"title": "Page 2 Title",
"content": "Here we describe the functionalities of the product.
It includes various use cases and capabilities."
}
]This JSON file contains the URLs, titles, and content for each of the pages we scraped. This structured data can now be used for further processing, such as embedding generation and question-answering in the RAG system. Below is the output screenshot of the original code. Sensitive information has been masked to maintain integrity.
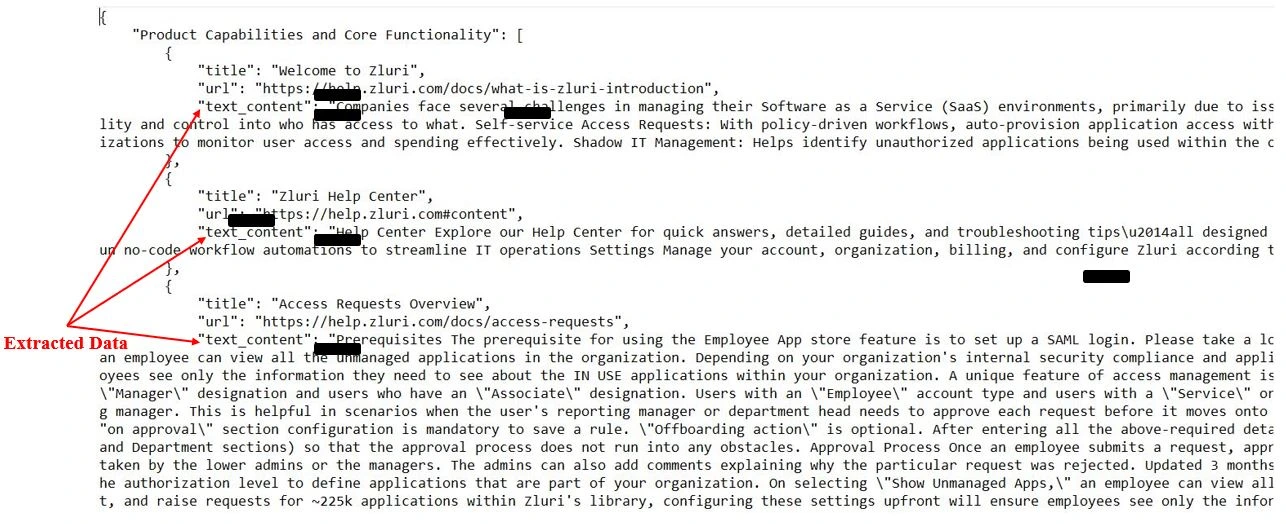
Automating Information Extraction with AI Agent
In the previous section, we covered the process of scraping links and collecting raw web content using a breadth-first search (BFS) strategy. Once the necessary data is scraped, we need a robust system for organizing and extracting actionable insights from this raw content. This is where Agentic AI steps in: by processing the scraped data, it automatically structures the information into meaningful sections.
In this section, we focus on how Agentic AI extracts relevant product information from the scraped data, ensuring it’s ready for stakeholder consumption. We’ll break down the key steps involved, from loading the data to processing it and finally saving the results in a structured format.
Step 1: Loading Scraped Data
The first step in this process is to load the raw scraped content into our system. As we saw earlier, the scraped data is stored in JSON format, and each entry includes a URL and associated content. We need to ensure that this data is in a suitable format for the AI to process.
Code Snippet:
import json
# Load the scraped JSON file containing the web data
with open('/content/scraped_contents_zluri_all_links.json', 'r') as file:
data = json.load(file)Here, we load the entire dataset into memory using Python’s built-in json library. Each entry in the dataset contains the URL of the source and a text_content field, which holds the raw scraped text. This content is what we will process in the next steps.
Step 2: Extracting Raw Text Content
Next, we iterate through the dataset to extract the relevant text_content for each entry. This ensures that we only work with valid entries that contain the necessary content. Invalid or incomplete entries are skipped to maintain the integrity of the process.
Code Snippet:
# Loop through each entry and extract the content
for entry in data:
if 'result' in entry and 'text_content' in entry['result']:
input_text = entry['result']['text_content']At this point, the input_text variable contains the raw text content that we will send to the AI model for further processing. It’s crucial that we ensure the presence of the necessary keys before processing each entry.
Step 3: Sending Data to AI Agent for Processing
After extracting the raw content, we send it to the Agentic AI model for structured extraction. We interact with the Groq API to request structured insights based on predefined prompts. The AI model processes the content and returns organized information that covers key aspects like product capabilities, integrations, and troubleshooting steps.
Code Snippet:
response = client.chat.completions.create(
messages=[
{"role": "system", "content": """
You are tasked with acting as a product manager.
Extract structured information based on the following sections:
- Product Capabilities
- Integrations and Compatibility
- Modules and Sub-modules
- Recent Releases
- Troubleshooting Steps
"""},
{"role": "user", "content": input_text},
],
model="llama-3.2-3b-preview",
temperature=1,
max_tokens=1024,
top_p=1,
)Here, the code initiates an API call to Groq, sending the input_text and instructions as part of the messages payload. The system message instructs the AI model on the exact task to perform, while the user message provides the content to be processed. We use the temperature, max_tokens, and top_p parameters to control the randomness and length of the generated output.
API Call Configuration:
- model: Specifies the model to be used. In this case, a language model is chosen to ensure it can handle textual data and generate responses.
- temperature: Controls the creativity of the responses. A higher value leads to more creative responses, while lower values make them more deterministic.
- max_tokens: Sets the maximum length of the generated response.
- top_p: Determines the cumulative probability distribution for token selection, controlling diversity in the response.
Step 4: Processing and Collecting Results
Once the AI model processes the content, it returns chunks of structured information. We collect and concatenate these chunks to create a full set of results, ensuring no data is lost and the final output is complete.
Code Snippet:
# Initialize a variable to collect the AI output
pm_points = ""
# Process and collect all chunks from the API response
for chunk in response:
pm_points += chunk.choices[0].delta.content or ""
This code snippet concatenates the content from each chunk to the pm_points variable, resulting in a full, structured set of insights. It extracts these insights in a format that stakeholders can easily consume or use for further analysis. Below is the output screenshot of the original code, with sensitive information masked to maintain integrity.
Step 5: Error Handling and Maintaining Data Integrity
While processing, there’s always the possibility of encountering errors, such as incomplete content or network issues. By using error handling mechanisms, we ensure that the process continues smoothly for all valid entries.
Code Snippet:
except Exception as e:
print(f"Error processing entry {entry.get('url', 'Unknown URL')}: {e}")
entry['pm_points'] = "Error processing content.This try-except block catches and logs any errors, ensuring the system continues processing other entries. If a specific entry causes an issue, the system marks it for review without halting the overall process.
Step 6: Saving the Processed Data
After the AI processes the content and returns structured insights, the final step is saving this data for later use. We write the structured results back to a JSON file, ensuring that every entry has its own processed information stored for further analysis.
Code Snippet:
# Save the final JSON file after processing all entries
with open('/content/processed_data_with_pm_points.json', 'w') as outfile:
json.dump(data, outfile, indent=4)This code stores the processed data efficiently and allows easy access later. It saves each entry with its respective structured points, making retrieval and analysis of the extracted information simple.
Output
After running the above code, the processed JSON file will contain the extracted points for each entry. The fields pm_points will hold the structured information related to product capabilities, integrations, troubleshooting steps, and more, ready for further analysis or integration into your workflows.
[
{
"url": "https://example.com/product1",
"result": {
"text_content": "This is the product description for Product 1.
It provides a variety of features including integration with tools
like Google Analytics and Salesforce."
},
"pm_points": {
"Product Capabilities and Core Functionality": [
"Provides analytics tools for product tracking.",
"Integrates with popular CRMs like Salesforce.",
"Supports real-time data processing."
],
"Integrations and Compatibility": [
"Compatible with Google Analytics.",
"Supports Salesforce integration for CRM management."
],
"Modules and Sub-modules": [
"Module 1: Data Analytics - Provides tools for real-time tracking.",
"Module 2: CRM Integration - Seamlessly integrates with CRM platforms."
],
"Recent Releases": [
"Version 2.1 released with enhanced reporting features.",
"New integration with Slack for notifications."
],
"Basic Troubleshooting": [
"Check the API connection if data is not syncing.",
"Clear cache and try restarting the system if features are not loading."
]
}
},
{
"url": "https://example.com/product2",
"result": {
"text_content": "Product 2 is a software tool designed for managing
team projects and tracking workflows. It offers robust task management
features."
},
"pm_points": {
"Product Capabilities and Core Functionality": [
"Enables efficient task and project management.",
"Features include automated reporting and team collaboration tools."
],
"Integrations and Compatibility": [
"Integrates with Asana for task tracking.",
"Supports Slack integration for team communication."
],
"Modules and Sub-modules": [
"Module 1: Task Management - Allows users to create, assign, and track
tasks.",
"Module 2: Reporting - Automatically generates project status reports."
],
"Recent Releases": [
"Version 1.3 added Gantt chart views for better project visualization."
],
"Basic Troubleshooting": [
"If tasks are not updating, check your internet connection.",
"Ensure that your Slack token is valid for integrations."
]
}
}
]
Below is the output screenshot of the original code. Sensitive information has been masked to maintain integrity.
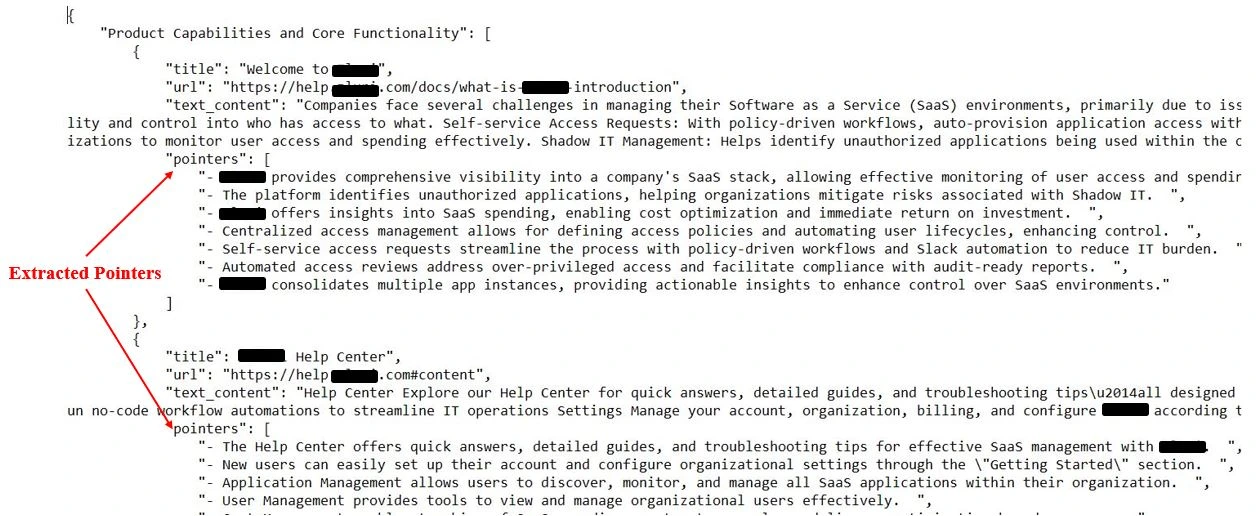
Retrieval-Augmented Generation Pipeline Implementation
In the previous section, we focused on data extraction from web pages and converting them into structured formats like JSON. We also implemented techniques to extract and clean relevant data, allowing us to generate a dataset that’s ready for deeper analysis.
Building on that, in this section, we will implement a Retrieval-Augmented Generation (RAG) pipeline, which combines document retrieval and language model generation to answer questions based on the extracted information.
By integrating the structured data we previously scraped and processed, this RAG pipeline will not only retrieve the most relevant document chunks but also generate accurate, insightful responses based on that context.
Step 1: Setting up the Environment
To begin with, let’s install all the necessary dependencies for the RAG pipeline:
!pip install jq
!pip install langchain
!pip install langchain-openai
!pip install langchain-chroma
!pip install langchain-community
!pip install langchain-experimental
!pip install sentence-transformersThese packages are crucial for integrating document processing, vectorization, and OpenAI models within LangChain. jq is a lightweight JSON processor, while langchain serves as the core framework for building language model pipelines. langchain-openai facilitates the integration of OpenAI models like GPT, and langchain-chroma offers Chroma-based vector stores for managing document embeddings.
Additionally, we use sentence-transformers to generate text embeddings with pre-trained transformer models, enabling efficient document handling and retrieval.
Step 2: Loading the Extracted Data
Now, we’ll load the structured data that was extracted and processed in the previous section using JSONLoader. This data, for instance, could have been scraped from web pages as a structured JSON, with key-value pairs relevant to specific topics or questions.
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path=r"/content/company_data.json", # Updated the file name to a more generic term
jq_schema=".[].product_points", # Adjusted schema name to be generic
text_content=False
)
data = loader.load()In this step, the data that was previously extracted (perhaps containing product capabilities, integrations, and features) is loaded for further processing.
Step 3: Splitting the Documents into Smaller Chunks
Now that we have the raw data, we use the RecursiveCharacterTextSplitter to break the document into smaller chunks. This ensures that no single chunk exceeds the token limit of the language model.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=700, # Size of each chunk (in characters)
chunk_overlap=200, # Number of overlapping characters between chunks
add_start_index=True # Include an index to track original document order
)
all_splits = text_splitter.split_documents(data)
print(f"Split document into {len(all_splits)} sub-documents.")The RecursiveCharacterTextSplitter divides a document into smaller segments, ensuring that chunk overlaps are preserved for better contextual understanding. The chunk_size parameter determines the size of each chunk, while chunk_overlap ensures important information is retained across adjacent chunks. Additionally, add_start_index helps maintain the document’s order by including an index, allowing for easy tracking of where each chunk originated in the original document.
Step 4: Generating Embeddings for Document Chunks
Now, we convert each chunk of text into embeddings using the SentenceTransformer. These embeddings represent the meaning of the text in a high-dimensional vector space, which is useful for searching and retrieving relevant documents later.
from sentence_transformers import SentenceTransformer
sentence_transformer_model = SentenceTransformer('all-MiniLM-L6-v2')
class SentenceTransformerEmbeddings:
def embed_documents(self, texts):
return sentence_transformer_model.encode(texts, convert_to_tensor=True).tolist()
def embed_query(self, text):
return sentence_transformer_model.encode(text, convert_to_tensor=True).tolist()
vectorstore = Chroma.from_documents(documents=all_splits,
embedding=SentenceTransformerEmbeddings())SentenceTransformer is used to generate embeddings for text chunks, creating dense vector representations that capture semantic information. The function embed_documents processes multiple documents and returns their embeddings, while embed_query generates embeddings for user queries. Chroma, a vector store, manages these embeddings and enables efficient retrieval based on similarity, allowing for fast and accurate document or query matching.
Step 5: Setting up the Retriever
Now we configure the retriever. This component searches for the most relevant chunks of text based on a user’s query. It retrieves the top-k most similar document chunks to the query.
retriever = vectorstore.as_retriever(search_type="similarity",
search_kwargs={"k": 6})- The retriever uses similarity search to find the most relevant chunks from the vector store.
- The parameter k=6 means it will return the top 6 chunks that are most relevant to the query.
Step 6: Creating the Prompt Template
Next, we create a prompt template that will format the input for the language model. This template includes both the context (retrieved chunks) and the user’s query, guiding the model to generate an answer based only on the provided context.
from langchain.prompts import ChatPromptTemplate
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)- The ChatPromptTemplate formats the input for the model in a way that emphasizes the need for the answer to be based solely on the given context.
- {context} will be replaced with the relevant text chunks, and {question} will be replaced with the user’s query.
Step 7: Setting up the Language Model
In this step, we initialize the OpenAI GPT model. This model will generate answers based on the structured context provided by the retriever.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")- We initialize the ChatOpenAI model, which will process the prompt and generate an answer.
- We use a smaller model, “gpt-4o-mini”, for efficient processing, though larger models could be used for more complex tasks.
Step 8: Constructing the RAG Pipeline
Here, we integrate all components (retriever, prompt, LLM) into a cohesive RAG pipeline. This pipeline will take the query, retrieve the relevant context, pass it through the model, and generate a response.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)- RunnablePassthrough ensures that the query is passed directly to the prompt.
- StrOutputParser is used to clean and format the output from the model into a string format.
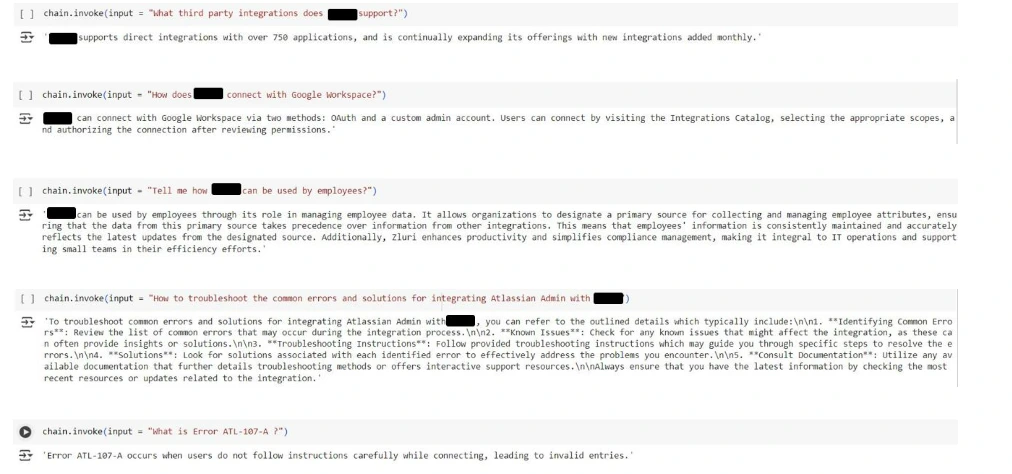
Step 9: Testing the RAG Pipeline
Finally, we test the pipeline with various user queries. For each query, the system retrieves relevant document chunks, passes them through the language model, and generates a response.
queries = [
"What integrations are available with this platform?",
"What are the product capabilities and core functionalities offered
by this platform?",
"Does this platform support Salesforce integration?"
]
for query in queries:
result = chain.invoke(input=query)
print(f"Query: {query}\nAnswer: {result}\n")
- The system iterates through each query, invoking the pipeline and printing the generated answer.
- For each query, the model processes the retrieved context and provides an answer grounded in the context.
Below are screenshots of the RAG output from the original code. Sensitive information has been masked to maintain integrity.
By combining web scraping, data extraction, and advanced retrieval-augmented generation (RAG) techniques, we’ve created a powerful and scalable framework for company intelligence. The first step of extracting links and scraping data ensures that we gather relevant and up-to-date information from the web. The second section focuses on pinpointing specific product-related details, making it easier to categorize and process data efficiently.
Finally, leveraging RAG allows us to dynamically respond to complex queries by retrieving and synthesizing contextual information from vast datasets. Together, these components form a comprehensive setup that can be used to build an agentic platform capable of gathering, processing, and delivering actionable insights on companies. This framework could serve as the foundation for developing advanced intelligence systems, enabling organizations to automate competitive analysis, monitor market trends, and stay informed about their industry.
Deployment and Scaling
Once the company intelligence system is built, the next step is to deploy and scale it for production use. You can deploy the system on cloud platforms like AWS or GCP for flexibility and scalability, or opt for an on-premise solution if data privacy is a priority. To make the system more user-friendly, consider building a simple API or UI that allows users to interact with the platform and retrieve insights effortlessly. As the system starts handling larger datasets and higher query loads, it’s essential to scale efficiently.
This can be achieved by leveraging distributed vector stores and optimizing the retrieval process, ensuring that the pipeline remains responsive and fast even under heavy usage. With the right infrastructure and optimization techniques in place, the agentic platform can grow to support large-scale operations, enabling real-time insights and maintaining a competitive edge in company intelligence.
Conclusion
In today’s data-driven world, extracting actionable insights from unstructured company data is crucial. A Retrieval-Augmented Generation (RAG) system combines data scraping, pointer extraction, and intelligent querying to create a powerful platform for company intelligence. By organizing key information and enabling real-time, context-specific responses, RAG systems empower smart decision-making in organizations, helping businesses make data-backed, adaptable decisions.
This scalable solution grows with your needs, handling complex queries and larger datasets while maintaining accuracy. With the right infrastructure, this AI-driven platform becomes a cornerstone for smarter operations, enabling organizations to harness their data, stay competitive, and drive innovation through smart decision-making in organizations.
Key Takeaways
- Link extraction and web scraping enhance company intelligence by enabling automatic, efficient data collection from multiple sources with minimal effort.
- Extracting key data points transforms unstructured content into organized, actionable knowledge, strengthening company intelligence for AI-driven insights.
- Combining RAG with a custom vector store and optimized retriever enables intelligent, context-aware responses for better decision-making.
- Cloud-based solutions and distributed vector stores ensure efficient scaling, handling larger datasets and query loads without performance loss.
- The RAG pipeline processes real-time queries, delivering accurate, on-demand insights directly from the knowledge base.
Bonus: All the codes discussed here are made available in the following link. A total of 4 notebooks are available, with self-explanatory names for each notebook. Feel free to explore, develop and revolutionize enterprise!
Frequently Asked Questions
Q1. What is the purpose of using Retrieval-Augmented Generation (RAG) in this setup?
A. RAG enhances the ability of AI models to provide context-aware responses by combining information retrieval with generative AI. It enables smarter querying of large datasets, making it easier to retrieve precise, relevant answers rather than just performing a basic keyword search.
Q2. What tools and libraries are required to build the system described in the blog?
A. The primary tools and libraries used include Python, BeautifulSoup for web scraping, Langchain for managing document retrieval, OpenAI models for natural language processing, and Chroma for storing vectorized documents. These components work together to create a comprehensive company intelligence platform.
Q3. How does the pointer extraction process work in this system?
A. Pointer extraction involves identifying specific information from the scraped content, such as product features, integrations, and troubleshooting tips. The data is processed using a prompt-driven system, which organizes the information into structured, actionable insights. This is achieved using a combination of AI models and custom prompts.
Q4. How do RAG and AI agents improve company intelligence?
A. RAG and AI agents enhance company intelligence by automating data retrieval, processing, and analysis, enabling businesses to extract real-time, actionable insights.
Q5. Why is data scraping important for company intelligence?
A. Data scraping helps build a strong company intelligence system by collecting and structuring valuable information from multiple sources for informed decision-making.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Neil is a research professional currently working on the development of AI agents. He has successfully contributed to various AI projects across different domains, with his works published in several high-impact, peer-reviewed journals. His research focuses on advancing the boundaries of artificial intelligence, and he is deeply committed to sharing knowledge through writing. Through his blogs, Neil strives to make complex AI concepts more accessible to professionals and enthusiasts alike.
Free Courses





