
In a recent hackathon, I developed Agri Bot, an AI-powered chatbot designed to assist farmers and agricultural enthusiasts by providing accurate and multilingual farming-related information. This article will walk you through the features, architecture, and code behind Agri Bot, showcasing how it leverages advanced technologies to create a user-friendly experience. In the Agriculture sector, access to timely and accurate information is crucial for farmers and agricultural enthusiasts. Enter Agri Bot, an AI in Agriculture chatbot designed to bridge the information gap by providing multilingual support and real-time data.
Table of contents
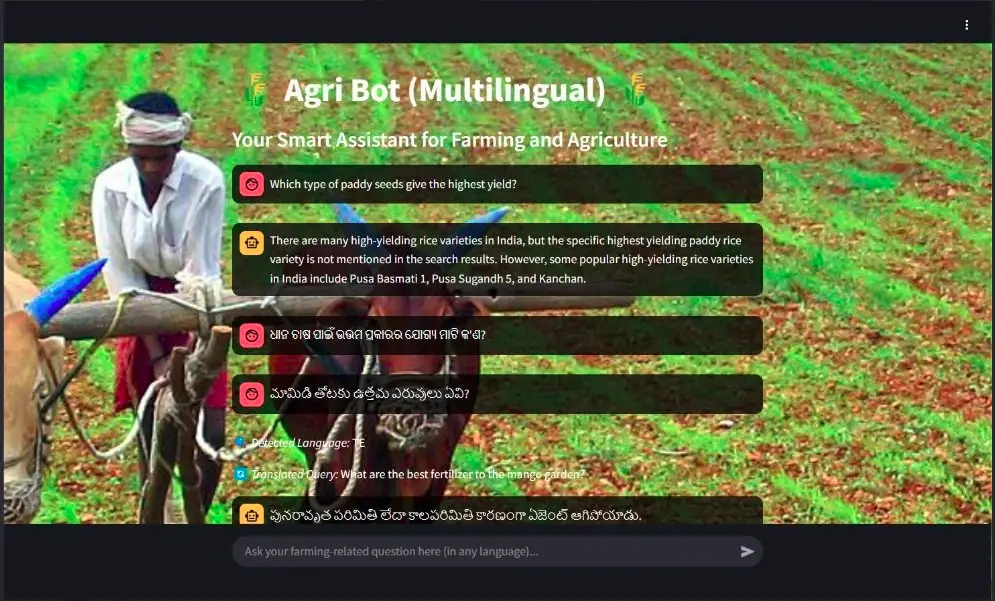
This is the UI of the streamlit Agribot app, it is a multilingual, conversational and real-time bot:
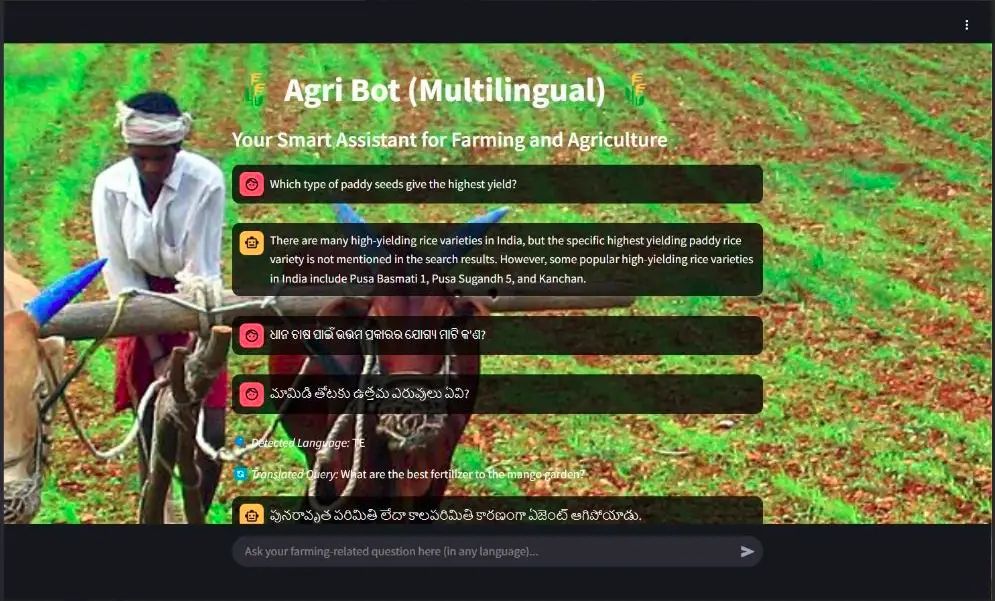
Key Features of Agri Bot: AI for Farmers
Agri Bot is equipped with several standout features that make it an invaluable AI for farmers:
- Multilingual Support: Communicates in multiple languages, including English, Hindi, Telugu, Tamil, Bengali, Marathi, and Punjabi.
- AI-Powered Conversations: Utilizes the Llama 3-70B model to deliver intelligent and contextual responses.
- Real-Time Information Retrieval: Integrates with Wikipedia, Arxiv, and DuckDuckGo to fetch the latest agricultural data.
- Context-Aware Memory: Remembers previous interactions, ensuring a seamless user experience.
- User-Friendly Interface: Built with Streamlit, the interface is intuitive and easy to navigate.
Tech Stack for Agri Bot
The tech stack for Agri Bot includes:
- Frontend: Streamlit (Python)
- Backend: LangChain, OpenAI LLM (via Groq API)
- Search Tools: Wikipedia, Arxiv, DuckDuckGo
- Translation: Google Translator API
- Memory Management: LangChain ConversationBufferMemory
Also read: Top 7 Frameworks for Building AI Agents in 2025
Steps Involved to Build the Agri Bot
Here’s a breakdown of the code that powers Agri Bot:
1. Importing Libraries
import os
import time
import streamlit as st
from langchain.memory import ConversationBufferMemory
from langchain.agents import initialize_agent, AgentType
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage, HumanMessage, AIMessage
from langchain_community.tools import WikipediaQueryRun, ArxivQueryRun, DuckDuckGoSearchRun
from langchain_community.utilities import WikipediaAPIWrapper, ArxivAPIWrapper, DuckDuckGoSearchAPIWrapper
from langdetect import detect
from deep_translator import GoogleTranslator
from dotenv import load_dotenv, find_dotenvWe start by importing the necessary libraries. streamlit is used for the web interface, while langchain provides tools for building conversational agents. The deep_translator library is used for language translation.
2. Loading Environment Variables
load_dotenv(find_dotenv())This line loads environment variables from a .env file, which includes sensitive information like API keys.
3. Initializing AI Tools
wiki = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=200))
arxiv = ArxivQueryRun(api_wrapper=ArxivAPIWrapper(top_k_results=1, doc_content_chars_max=200))
duckduckgo_search = DuckDuckGoSearchRun(api_wrapper=DuckDuckGoSearchAPIWrapper(region="in-en", time="y", max_results=2))
tools = [wiki, arxiv, duckduckgo_search]Here, we initialize the tools for fetching information from Wikipedia, Arxiv, and DuckDuckGo. Each tool is configured to return a limited number of results to ensure quick responses.
4. Loading the Language Model
def load_llm():
return ChatOpenAI(
model_name="llama3-70b-8192",
temperature=1,
openai_api_key=os.getenv("GROQ_API_KEY"),
openai_api_base="https://api.groq.com/openai/v1"
)This function loads the language model using the Groq API. The temperature parameter controls the randomness of the model’s responses.
5. Translation Functions
def translate_to_english(text):
try:
detected_lang = detect(text) # Detect language
if detected_lang == "en":
return text, "en" # No translation needed
translated_text = GoogleTranslator(source=detected_lang, target="en").translate(text)
return translated_text, detected_lang # Return translated text and original language
except Exception as e:
return text, "unknown" # Return original text if translation fails
def translate_back(text, target_lang):
try:
if target_lang == "en":
return text # No translation needed
return GoogleTranslator(source="en", target=target_lang).translate(text)
except Exception as e:
return text # Return original if translation failsThese functions handle the translation of user input to English and back to the original language. They use the deep_translator library to perform the translations.
6. Memory Management
if "chat_memory" not in st.session_state:
st.session_state.chat_memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)This code ensures that the chat memory is persistent across sessions, allowing the bot to remember previous interactions.
7. Creating the Conversational Agent
def get_conversational_agent():
llm = load_llm()
return initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
memory=st.session_state.chat_memory,
verbose=True,
return_intermediate_steps=False,
max_iterations=5,
handle_parsing_errors=True
)This function initializes the conversational agent with the loaded language model and the tools for information retrieval.
8. Streamlit Chat UI
def main():
# Set Background Image
...
st.title("🌾 Agri Bot (Multilingual) 🌾")
st.subheader("Your Smart Assistant for Farming and Agriculture")
if st.button("Reset Conversation"):
st.session_state.chat_memory.clear()
st.session_state.messages = []
st.success("Chat history cleared!")
if "messages" not in st.session_state:
st.session_state.messages = []
# Display past chat history
for message in st.session_state.messages:
st.chat_message(message["role"]).markdown(message["content"])
# Get user input
prompt = st.chat_input("Ask your farming-related question here (in any language)...")
if prompt:
st.chat_message("user").markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
try:
translated_query, original_lang = translate_to_english(prompt)
st.write(f"🔍 *Detected Language:* {original_lang.upper()}") # Show detected language
st.write(f"🔄 *Translated Query:* {translated_query}") # Show translated query
agent = get_conversational_agent()
def trim_chat_memory(max_length=5):#
""" Retains only the last `max_length` messages in memory. """
chat_history = st.session_state.chat_memory.load_memory_variables({})["chat_history"]
if len(chat_history) > max_length:
st.session_state.chat_memory.chat_memory.messages = chat_history[-max_length:]#
return chat_history
# Apply trimming before invoking the agent
chat_history = trim_chat_memory(max_length=5)#
conversation_context = "\n".join([msg.content for msg in chat_history])
full_prompt = f"""
Previous conversation:
{conversation_context}
User: {prompt}
Assistant: Think carefully. You are allowed to search a maximum of 2 times strictly.
If you have found enough information from previous searches, STOP searching and generate an convincing answer using the available data.
"""
# Retry in case of rate-limit errors
max_retries = 3
for attempt in range(max_retries):
try:
response = agent.invoke({"input": full_prompt})
break # Exit loop if successful
except Exception as e:
st.warning(f"⚠ API Rate Limit! Retrying {attempt + 1}/{max_retries}...")
time.sleep(2) # Wait and retry
response_text = response["output"] if isinstance(response, dict) and "output" in response else str(response)
final_response = translate_back(response_text, original_lang) # Translate back to original language
st.chat_message("assistant").markdown(final_response)
st.session_state.messages.append({"role": "assistant", "content": final_response})
except Exception as e:
st.error(f"Error: {str(e)}")Code Explanation
Let’s break down the code’s functionality, step by step:
1. Streamlit Setup
The code initializes a Streamlit application, creating the user interface for the chatbot.
2. Chat Input
st.chat_input creates a text input area where the user can type their messages.
3. User Message Handling
When the user submits a message:
- The message is captured.
- translate_to_english converts the user’s message to English. This is crucial for consistent interaction with the English-centric LLM.
- The original (user language) and translated (English) messages are displayed in the chat window using st.chat_message.
4. LangChain Agent Query
- get_conversational_agent is called to retrieve or initialize a LangChain agent. This agent is designed to handle conversational queries, likely using an LLM and potentially other tools.
- The current conversation history (from st.session_state.chat_memory) is included in the prompt sent to the agent. This context is essential for a coherent conversation.
- The agent processes the prompt (including the user’s translated message and the chat history) and generates a response in English.
5. Response Handling
- The English response from the agent is stored.
- translate_back converts the agent’s English response back to the user’s original language.
- The translated response is displayed in the chat window using st.chat_message.
6. Context Management
trim_chat_memory is called to limit the conversation history stored in st.session_state.chat_memory. This prevents the context from becoming too large for the LLM to handle, which is a common limitation. It usually keeps only the most recent messages.
7. Retry Mechanism
The code incorporates a retry loop. If the API call to the LLM or translation service fails (e.g., due to rate limiting or temporary network issues), the code will retry the request a certain number of times before giving up. This makes the chatbot more robust.
8. Error Handling
The code includes try…except blocks to catch potential errors during API calls or other operations. This prevents the application from crashing and provides a more user-friendly experience (e.g., displaying an error message).
9. Session State
st.session_state is used to store data that persists across user interactions. Specifically, it stores the chat_memory, which is the history of the conversation. This allows the chatbot to maintain context over multiple turns. Without st.session_state, the conversation would start fresh with every new message.
Testing the Agribot: An AI for farmers
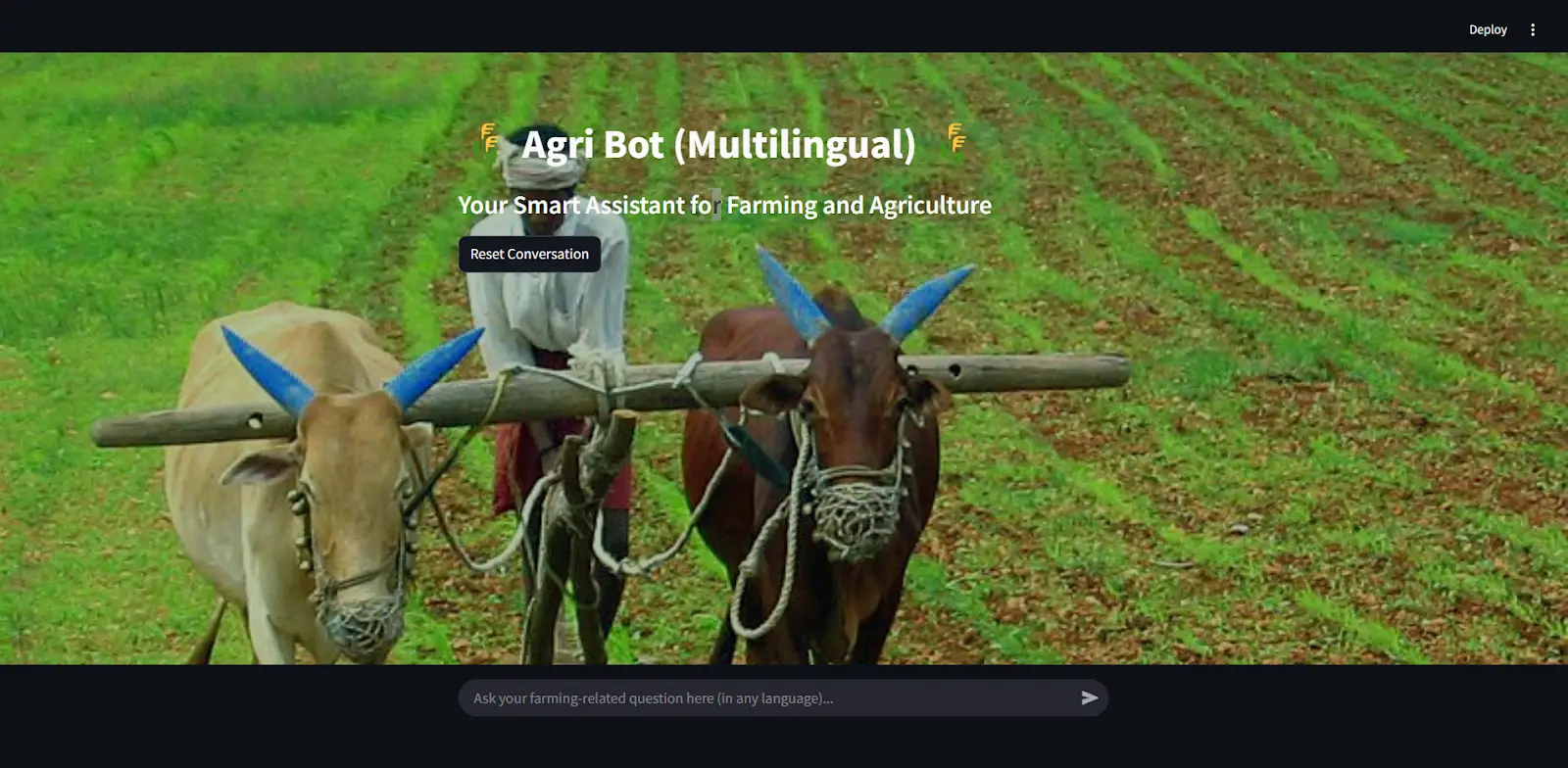
This is the UI of the streamlit app.
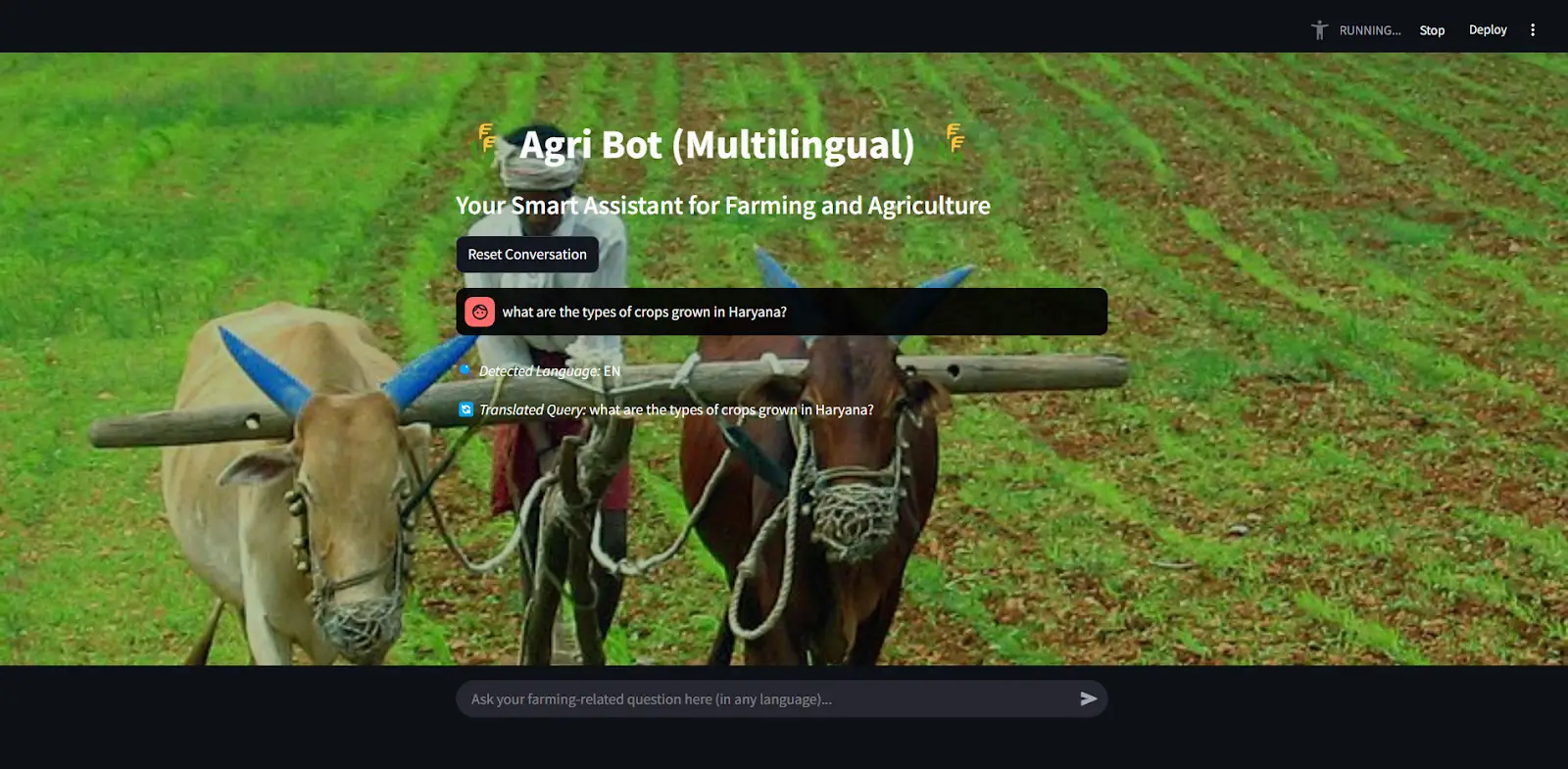
Here, I asked the bot “What are the crops grown in Haryana?”, we can see that it detected the language is “en”.
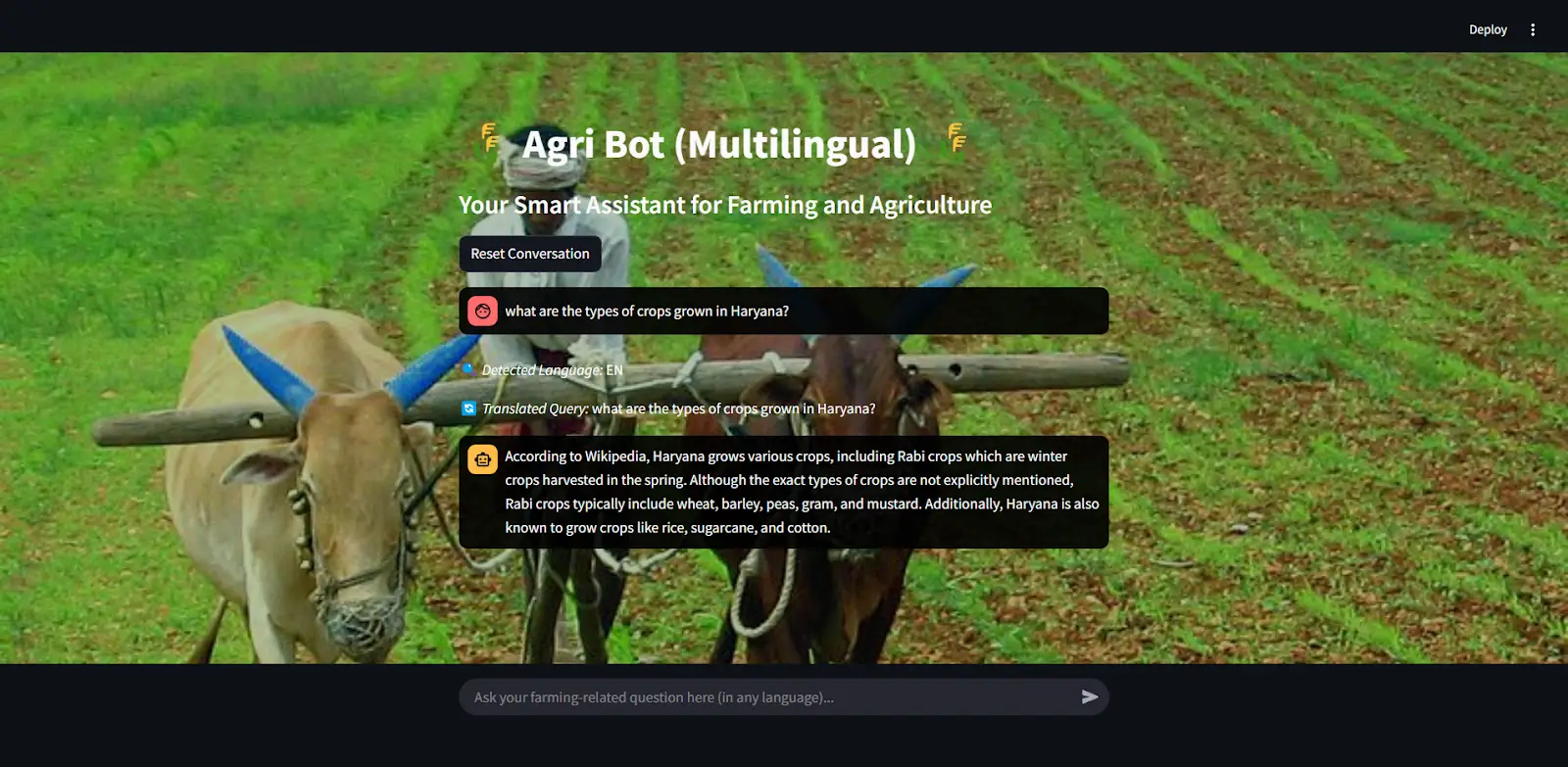
Now it gives real-time answers using Web search, Wikipedia and Arxiv AI agents and presents answers precisely.
This image shows that Agribot can understand different regional languages and can answer in those languages, here we can see that the detected language is Tamil “te” and the output is also in Tamil language.
Future Improvements in AI for Farmers
While Agri Bot is functional, there are several areas for improvement:
- Voice Input and Responses: Adding support for voice interactions could enhance accessibility.
- Domain-Specific Fine-Tuning: Fine-tuning the model on agricultural data could improve response accuracy.
- UI/UX Enhancements: Further improvements to the user interface could provide a better user experience.
Conclusion
Agri Bot is a powerful tool that leverages AI and multilingual capabilities to assist farmers and agricultural enthusiasts. The combination of real-time information retrieval, language translation, and conversational memory makes it a unique and valuable resource. I look forward to further developing this project and exploring new features to enhance its functionality of AI in Agriculture.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕
Free Courses





