In today’s fast-paced digital world, businesses are constantly seeking innovative ways to enhance customer engagement and streamline support services. One effective solution is the use of AI-powered customer support voice agents. These AI voice bots are capable of understanding and responding to voice-based customer support queries in real-time. They leverage conversational AI to automate interactions, reduce wait times, and improve the efficiency of customer support. In this article, we will learn all about AI-powered speech-enabled customer service agents and learn how to build one using Deepgram and pygame libraries.
Table of Contents
- What is a Voice Agent?
- Accessing the API Keys
- Steps to Build a Voice Agent
- Step 1: Set Up API Keys
- Step 2: Define System Instructions
- Step 3: Audio Text Processing
- Step 4: Implement Speech-to-Text Processing
- Step 5: Handle Conversations
- Step 6: Convert Text to Speech
- Step 7: Welcome and Farewell Messages
- Step 8: Exit Commands
- Step 9: Error Handling and Robustness
- Step 10: Final Steps to Run the Voice Agent
- Use Cases of Voice Agents
- Frequently Asked Questions
What is a Voice Agent?
A voice agent is an AI-powered agent designed to interact with users through voice-based communication. It can understand spoken language, process requests, and generate human-like responses. It enables seamless voice-based interactions, reducing the need for manual inputs, and enhancing user experience. Unlike traditional chatbots that rely only on text inputs, a voice agent enables hands-free, real-time conversations. This makes it a more natural and efficient way of interacting with technology.
Also Read: Paper-to-Voice Assistant: AI Agent Using Multimodal Approach
Difference Between a Voice Agent and a Traditional Chatbot
| Feature | Voice Agent | Traditional Chatbot |
| Input Type | Voice | Text |
| Response Type | Voice | Text |
| Hands-Free Use | Yes | No |
| Response Time | Faster, real-time | Slight delay, depending on typing speed |
| Understanding Accents | Advanced (varies by model) | Not applicable |
| Multimodal Capabilities | Can integrate text and voice | Primarily text-based |
| Context Retention | Higher, remembers past interactions | Varies, often limited to text history |
| User Experience | More natural | Requires typing |
Key Components of a Voice Agent
A Voice Agent is an AI-driven system that facilitates voice-based interactions, commonly used in customer support, virtual assistants, and automated call centers. It utilizes speech recognition, natural language processing (NLP), and text-to-speech technologies to comprehend user queries and provide appropriate responses.
In this section, we will explore the key components of a Voice Agent that enable seamless and efficient voice-based communication.
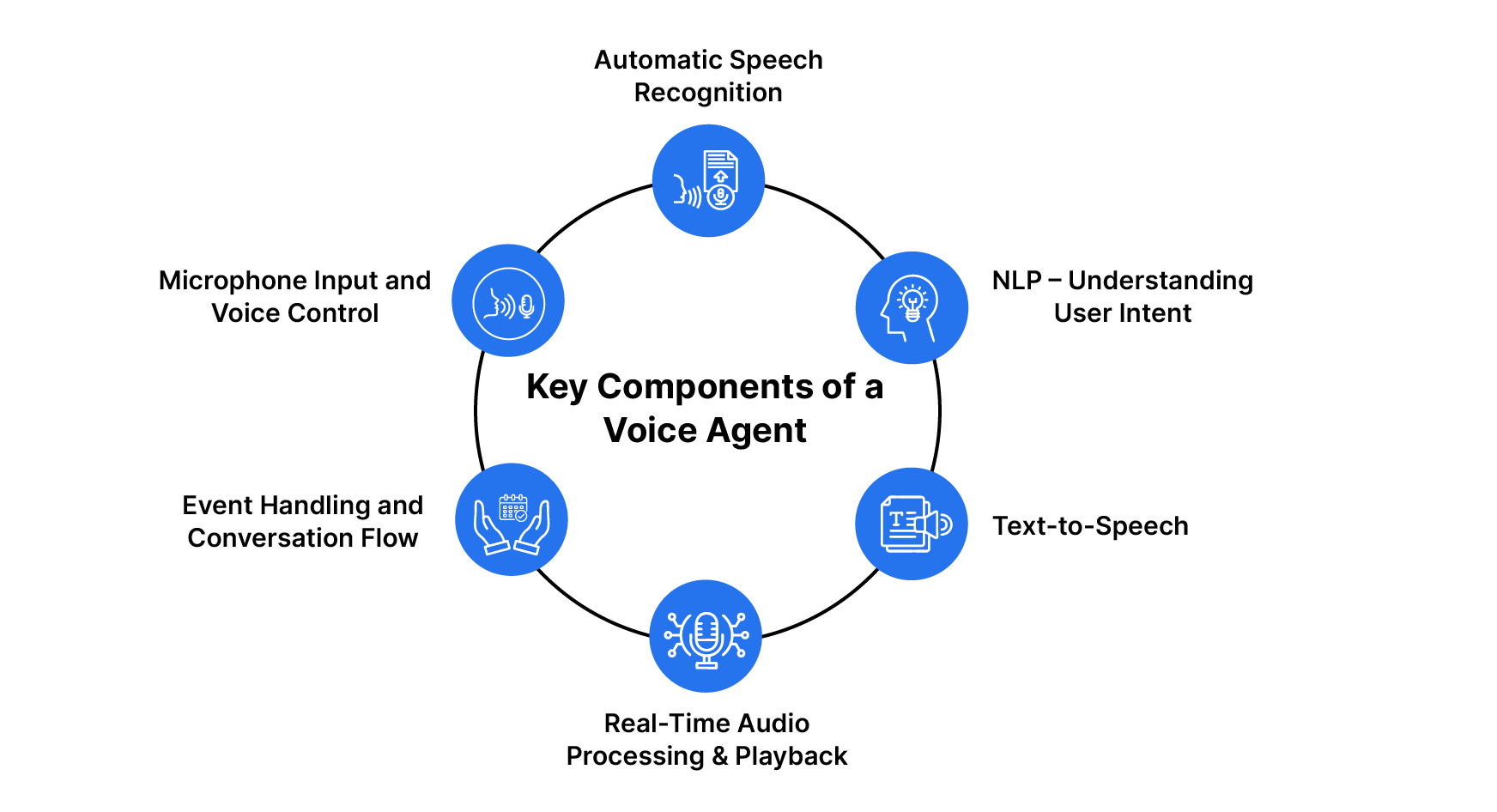
1. Automatic Speech Recognition (ASR) – Speech-to-Text Conversion
The first step in a voice agent’s workflow is to convert spoken language into text. This is achieved using Automatic Speech Recognition (ASR).
Implementation in Code:
- The Deepgram API is used for real-time speech transcription.
- The “deepgram.listen.live.v(“1”)” method captures live audio and transcribes it into text.
- The event “LiveTranscriptionEvents.Transcript” processes and extracts spoken words.
2. Natural Language Processing (NLP) – Understanding User Intent
Once the speech is transcribed into text, the system needs to process and understand it. OpenAI’s LLM (GPT model) is used here for natural language understanding (NLU).
Implementation in Code:
- The transcribed text is appended to the “conversation” list.
- The GPT model (o3-mini-2025-01-31) processes the message to generate an intelligent response.
- The system message (“system_message”) defines the agent’s personality and scope.
3. Text-to-Speech (TTS) – Generating Audio Responses
Once the system generates a response, it needs to be converted back into speech for a natural conversation experience. Deepgram’s Aura Helios TTS model is used to generate speech.
Implementation in Code:
- The “generate_audio()” function sends the generated text to Deepgram’s TTS API (“DEEPGRAM_URL”).
- The response is an audio file, which is then played using “pygame.mixer”.
4. Real-Time Audio Processing & Playback
For a real-time voice agent, the generated speech must be played immediately after processing. Pygame’s mixer module is used to handle audio playback.
Implementation in Code:
- The “playaudio()” function plays the generated audio using “pygame.mixer”.
- The microphone is muted while the response is played, preventing unintended audio interference.
5. Event Handling and Conversation Flow
A real-time voice agent needs to handle multiple events, such as opening and closing connections, processing speech, and handling errors.
Implementation in Code:
- Event listeners are registered for handling ASR (“on_message”), utterance detection (“on_utterance_end”), and errors (“on_error”).
- The system ensures smooth handling of user input and server responses.
6. Microphone Input and Voice Control
A key aspect of a voice agent is capturing live user input using a microphone. The Deepgram Microphone module is used for real-time audio streaming.
Implementation in Code:
- The microphone listens continuously and sends audio data for ASR processing.
- The system can mute/unmute the microphone while playing responses.
Accessing the API Keys
Before we start with the steps to build the voice agent, let’s first see how we can generate the required API keys.
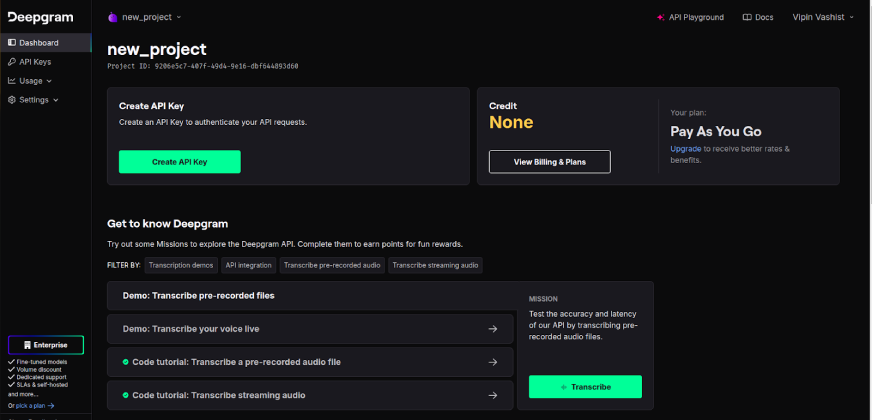
1. Deepgram API Key
To access the Deepgram API key visit Deepgram and sign up for a Deepgram account. If you already have an account, simply log in.
After logging in, click on the “Create API Key” to generate a new key. After logging in, click on the “Create API Key” to generate a new key. Deepgram also provides $200 in free credits, allowing users to explore its services without an initial cost.
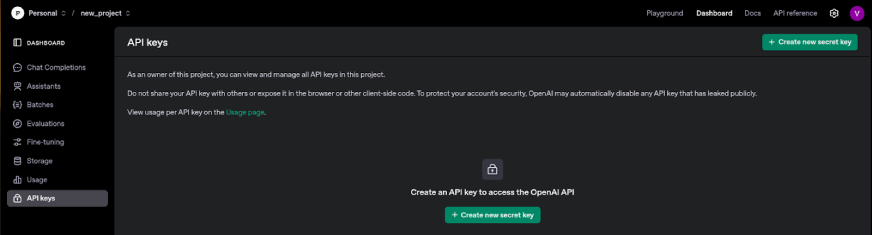
2. OpenAI API Key
To access the OpenAI API key, visit OpenAI and login to your account. Sign up for one if you don’t already have an OpenAI account.
After logging in, click on the “Create new secret key” to generate a new key.
Steps to Build a Voice Agent
Now we are ready to build a voice agent. In this guide we will learn to build a customer support voice agent that will help users in their tasks, answer their queries, and provide personalized assistance in a natural, intuitive way. So let’s begin.
Step 1: Set Up API Keys
APIs help us connect to external services, like speech recognition or text generation. To make sure only authorized users can use these services, we need to authenticate with API keys. To do this securely, it’s best to store the keys in separate text files or environment variables. This allows the program to safely read and load the keys when necessary.
With open ("deepgram_apikey_path","r") as f:
API_KEY = f.read().strip()
with open("/openai_apikey_path","r") as f:
OPENAI_API_KEY = f.read().strip()
load_dotenv()
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEYStep 2: Define System Instructions
A voice assistant must follow clear guidelines to ensure it gives helpful and well-organized responses. These rules define the agent’s role, such as whether it’s acting as customer support or a personal assistant. They also set the tone and style of the responses, like whether they should be formal, casual, or professional. You can even set rules on how detailed or concise the responses should be.
In this step, you write a system message that explains the agent’s purpose and include sample conversations to help generate more accurate and relevant responses.
system_message = """ You are a customer support agent specializing in vehicle-related issues like flat tires, engine problems, and maintenance tips.
# Instructions:
- Provide clear, easy-to-follow advice.
- Keep responses between 3 to 7 sentences.
- Offer safety recommendations where necessary.
- If a problem is complex, suggest visiting a professional mechanic.
# Example:
User: "My tire is punctured, what should I do?"
Response: "First, pull over safely and turn on your hazard lights. If you have a spare tire, follow your car manual to replace it. Otherwise, call for roadside assistance. Stay in a safe location while waiting."
"""Step 3: Audio Text Processing
To create more natural-sounding speech, we’ve implemented a dedicated AudioTextProcessor class that handles the segmentation of text responses:
- The segment_text method breaks long responses into natural sentence boundaries using regular expressions.
- This allows the TTS engine to process each sentence with appropriate pauses and intonation.
- The result is more human-like speech patterns that improve user experience.
class AudioTextProcessor:
@staticmethod
def segment_text(text):
"""Split text into segments at sentence boundaries for better TTS."""
sentence_boundaries = re.finditer(r'(?<=[.!?])\s+', text)
boundaries_indices = [boundary.start() for boundary in sentence_boundaries]
segments = []
start = 0
for boundary_index in boundaries_indices:
segments.append(text[start:boundary_index + 1].strip())
start = boundary_index + 1
segments.append(text[start:].strip())
return segmentsTemporary File Management
To handle audio files in a clean, efficient manner, our enhanced implementation uses Python’s tempfile module:
- Temporary files are created for storing audio data during playback.
- Each audio file is automatically cleaned up after use.
- This prevents accumulation of unused files on the system and manages resources efficiently.
Threading for Non-Blocking Audio Playback
A key enhancement in our new implementation is the use of threading for audio playback:
- Audio responses are played in a separate thread from the main application.
- This allows the voice agent to continue listening and processing while speaking.
- The microphone is muted during playback to prevent feedback loops.
- A threading.Event object (
mic_muted) coordinates this behavior across threads.
Step 4: Implement Speech-to-Text Processing
To understand user commands, the assistant needs to convert spoken words into text. This is achieved using Deepgram’s speech-to-text API, which can transcribe speech into text in real time. It can process different languages and accents, and distinguish between interim (incomplete) and final (confirmed) transcriptions.
In this step, the process begins by recording audio from the microphone. Then, the audio is sent to Deepgram’s API for processing, and the text output is received and stored for further use.
from deepgram import DeepgramClient, LiveTranscriptionEvents, LiveOptions, Microphone
import threading
# Initialize clients
deepgram_client = DeepgramClient(api_key=DEEPGRAM_API_KEY)
# Set up Deepgram connection
dg_connection = deepgram_client.listen.websocket.v("1")
# Define event handler callbacks
def on_open(connection, event, **kwargs):
print("Connection Open")
def on_message(connection, result, **kwargs):
# Ignore messages when microphone is muted for assistant's response
if mic_muted.is_set():
return
sentence = result.channel.alternatives[0].transcript
if len(sentence) == 0:
return
if result.is_final:
is_finals.append(sentence)
if result.speech_final:
utterance = " ".join(is_finals)
print(f"User said: {utterance}")
is_finals.clear()
# Process user input and generate response
# [processing code here]
def on_speech_started(connection, speech_started, **kwargs):
print("Speech Started")
def on_utterance_end(connection, utterance_end, **kwargs):
if len(is_finals) > 0:
utterance = " ".join(is_finals)
print(f"Utterance End: {utterance}")
is_finals.clear()
def on_close(connection, close, **kwargs):
print("Connection Closed")
def on_error(connection, error, **kwargs):
print(f"Handled Error: {error}")
# Register event handlers
dg_connection.on(LiveTranscriptionEvents.Open, on_open)
dg_connection.on(LiveTranscriptionEvents.Transcript, on_message)
dg_connection.on(LiveTranscriptionEvents.SpeechStarted, on_speech_started)
dg_connection.on(LiveTranscriptionEvents.UtteranceEnd, on_utterance_end)
dg_connection.on(LiveTranscriptionEvents.Close, on_close)
dg_connection.on(LiveTranscriptionEvents.Error, on_error)
# Configure live transcription options with advanced features
options = LiveOptions(
model="nova-2",
language="en-US",
smart_format=True,
encoding="linear16",
channels=1,
sample_rate=16000,
interim_results=True,
utterance_end_ms="1000",
vad_events=True,
endpointing=500,
)
addons = {
"no_delay": "true"
}Step 5: Handle Conversations
Once the assistant has transcribed the user’s speech into text, it needs to analyze the text and generate an appropriate response. To do this, we use OpenAI’s o3-mini model, which can understand the context of previous messages and generate human-like responses. It can even remember conversation history, which can help the agent maintain continuity.
In this step, the assistant stores the user’s queries and its responses in a conversation list. Then, gpt-4o-mini is used to generate a response, which is returned as the assistant’s reply.
# Initialize OpenAI client
openai_client = OpenAI(api_key=OPENAI_API_KEY)
def get_ai_response(user_input):
"""Get response from OpenAI API."""
try:
# Add user message to conversation
conversation.append({"role": "user", "content": user_input.strip()})
# Prepare messages for API
messages = [{"role": "system", "content": system_message}]
messages.extend(conversation)
# Get response from OpenAI
chat_completion = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
temperature=0.7,
max_tokens=150
)
# Extract and save assistant's response
response_text = chat_completion.choices[0].message.content.strip()
conversation.append({"role": "assistant", "content": response_text})
return response_text
except Exception as e:
print(f"Error getting AI response: {e}")
return "I'm having trouble processing your request. Please try again."Step 6: Convert Text to Speech
The assistant should speak its response aloud instead of just displaying text. To do this, Deepgram’s text-to-speech API is used to convert the text into natural-sounding speech.
In this step, the agent’s text response is sent to Deepgram’s API, which processes it and returns an audio file of the speech. Finally, the audio file is played using Python’s Pygame library, allowing the assistant to speak its response to the user.
class AudioTextProcessor:
@staticmethod
def segment_text(text):
"""Split text into segments at sentence boundaries for better TTS."""
sentence_boundaries = re.finditer(r'(?<=[.!?])\s+', text)
boundaries_indices = [boundary.start() for boundary in sentence_boundaries]
segments = []
start = 0
for boundary_index in boundaries_indices:
segments.append(text[start:boundary_index + 1].strip())
start = boundary_index + 1
segments.append(text[start:].strip())
return segments
@staticmethod
def generate_audio(text, headers):
"""Generate audio using Deepgram TTS API."""
payload = {"text": text}
try:
with requests.post(DEEPGRAM_TTS_URL, stream=True, headers=headers, json=payload) as r:
r.raise_for_status()
return r.content
except requests.exceptions.RequestException as e:
print(f"Error generating audio: {e}")
return None
def play_audio(file_path):
"""Play audio file using pygame."""
try:
pygame.mixer.init()
pygame.mixer.music.load(file_path)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
# Stop the mixer and release resources
pygame.mixer.music.stop()
pygame.mixer.quit()
except Exception as e:
print(f"Error playing audio: {e}")
finally:
# Signal that playback is finished
mic_muted.clear()Step 7: Welcome and Farewell Messages
A well-designed voice agent creates a more engaging and interactive experience by greeting users at startup and providing a farewell message upon exit. This helps establish a friendly tone and ensures a smooth conclusion to the interaction.
def generate_welcome_message():
""" Generate welcome message audio."""
welcome_msg = "Hello, I'm Eric, your vehicle support assistant. How can I help with your vehicle today?"
# Create temporary file for welcome message
with tempfile.NamedTemporaryFile(delete=False, suffix='.mp3') as welcome_file:
welcome_path = welcome_file.name
# Generate audio for welcome message
welcome_audio = audio_processor.generate_audio(welcome_msg, DEEPGRAM_HEADERS)
if welcome_audio:
with open(welcome_path, "wb") as f:
f.write(welcome_audio)
# Play welcome message
mic_muted.set()
threading.Thread(target=play_audio, args=(welcome_path,)).start()
return welcome_pathMicrophone Management
One key enhancement is the proper management of the microphone during conversations:
- The microphone is automatically muted when the agent is speaking.
- This prevents the agent from “hearing” its voice.
- A threading event object coordinates this behavior between threads.
# Mute microphone and play response
mic_muted.set()
microphone.mute()
threading.Thread(target=play_audio, args=(temp_path,)).start()
time.sleep(0.2)
microphone.unmute()Step 8: Exit Commands
To ensure a smooth and intuitive user interaction, the voice agent listens for common exit commands such as “exit,” “quit,” “goodbye,” or “bye.” When an exit command is detected, the system acknowledges and safely shuts down.
# Check for exit commands
if any(exit_cmd in utterance.lower() for exit_cmd in ["exit", "quit", "goodbye", "bye"]):
print("Exit command detected. Shutting down...")
farewell_text = "Thank you for using the vehicle support assistant. Goodbye!"
with tempfile.NamedTemporaryFile(delete=False, suffix='.mp3') as temp_file:
temp_path = temp_file.name
farewell_audio = audio_processor.generate_audio(farewell_text, DEEPGRAM_HEADERS)
if farewell_audio:
with open(temp_path, "wb") as f:
f.write(farewell_audio)
# Mute microphone and play farewell
mic_muted.set()
microphone.mute()
play_audio(temp_path)
time.sleep(0.2)
# Clean up and exit
if os.path.exists(temp_path):
os.remove(temp_path)
# End the program
os._exit(0)Step 9: Error Handling and Robustness
To ensure a seamless and resilient user experience, the voice agent must handle errors gracefully. Unexpected issues such as network failures, missing audio responses, or invalid user inputs can disrupt interactions if not properly managed.
Exception Handling
Try-except blocks are used throughout the code to catch and handle errors gracefully:
- In the audio generation and playback functions.
- During API interactions with OpenAI and Deepgram.
- In the main event handling loop.
try:
# Generate audio for each segment
with open(temp_path, "wb") as output_file:
for segment_text in text_segments:
audio_data = audio_processor.generate_audio(segment_text, DEEPGRAM_HEADERS)
if audio_data:
output_file.write(audio_data)
except Exception as e:
print(f"Error generating or playing audio: {e}")Resource Cleanup
Proper resource management is essential for a reliable application:
- Temporary files are deleted after use.
- Pygame audio resources are properly released.
- Microphone and connection objects are closed on exit.
# Clean up
microphone.finish()
dg_connection.finish()
# Clean up welcome file
if os.path.exists(welcome_file):
os.remove(welcome_file)Step 10: Final Steps to Run the Voice Agent
We need a main function to tie everything together and ensure the assistant works smoothly. The main function will:
- Listen to the user’s speech.
- Convert it to text and generate a response using AI,
- Convert the response into speech, and then play the speech back to the user.
- This process ensures that the assistant can interact with the user in a complete, seamless flow.
def main():
"""Main function to run the voice assistant."""
print("Starting Vehicle Support Voice Assistant 'Eric'...")
print("Speak after the welcome message.")
print("\nPress Enter to stop the assistant...\n")
# Generate and play welcome message
welcome_file = generate_welcome_message()
time.sleep(0.5) # Give time for welcome message to start
try:
# Initialize is_finalslist to store transcription segments
is_finals = []
# Set up Deepgram connection
dg_connection = deepgram_client.listen.websocket.v("1")
# Register event handlers
# [event registration code here]
# Configure and start Deepgram connection
if not dg_connection.start(options, addons=addons):
print("Failed to connect to Deepgram")
return
# Start microphone
microphone = Microphone(dg_connection.send)
microphone.start()
# Wait for user to press Enter to stop
input("")
# Clean up
microphone.finish()
dg_connection.finish()
# Clean up welcome file
if os.path.exists(welcome_file):
os.remove(welcome_file)
print("Assistant stopped.")
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
main()For a complete version of the code please refer here.
Note: As we are currently using the free version of Deepgram, the agent’s response time tends to be slower due to the limitations of the free plan.
Use Cases of Voice Agents
1. Customer Support Automation
Examples:
- Banking & Finance: Answering queries about account balance, transactions, or credit card bills.
- E-commerce: Providing order status, return policies, or product recommendations.
- Airlines & Travel: Assisting with flight bookings, cancellations, and baggage policies.
Example Conversation:
User: “Where is my order?”
Agent: “Your order was shipped on February 17 and is expected to arrive by February 20.”
2. Healthcare Virtual Assistants
Examples:
- Hospitals & Clinics: Booking appointments with doctors.
- Home Care: Reminding aged patients to take medications.
- Telemedicine: Providing basic symptom analysis before connecting to a doctor.
Example Conversation:
User: “I have a headache and fever. What should I do?”
Agent: “Based on your symptoms, you may have a mild fever. Stay hydrated and rest. If symptoms persist, consult a doctor.”
3. Voice Assistants for Vehicles
Examples:
- Navigation: “Find the nearest gas station.”
- Music Control: “Play my road trip playlist.”
- Emergency Help: “Call roadside assistance.”
Example Conversation:
User: “How’s the traffic on my route?”
Agent: “There is moderate traffic. Estimated arrival time is 45 minutes.”
Learn More: AI for Customer Service | Top 10 Use Cases
Conclusion
Voice agents are revolutionizing communication by making interactions natural, efficient, and accessible. They have diverse use cases across industries like customer support, smart homes, healthcare, and finance.
By leveraging speech-to-text, text-to-speech, and NLP, they understand context, provide intelligent responses, and handle complex tasks seamlessly. As AI advances, these systems will become more personalized and human-like, their ability to learn from interactions will allow them to offer increasingly tailored and intuitive experiences, making them indispensable companions in both personal and professional settings.
Frequently Asked Questions
Q1. What is a voice agent?
A. A voice agent is an AI-powered system that can process speech, understand context, and respond intelligently using speech-to-text, NLP, and text-to-speech technologies.
Q2. What are the key components of a voice agent?
A. The main components include:
– Speech-to-Text (STT): Converts spoken words into text.
– Natural Language Processing (NLP): Understands and processes the input.
– Text-to-Speech (TTS): Converts text responses into human-like speech.
– AI Model: Generates meaningful and context-aware replies.
Q3. Where are voice agents used?
A. voice agents are widely used in customer service, healthcare, virtual assistants, smart homes, banking, automotive support, and accessibility solutions.
Q4. Can voice agents understand different languages and accents?
A. Yes, many advanced voice agents support multiple languages and accents, improving accessibility and user experience worldwide.
Q5. Are voice agents replacing human support agents?
A. No, they are designed to assist and enhance human agents by handling repetitive tasks, allowing human agents to focus on complex issues.
Hello! I'm Vipin, a passionate data science and machine learning enthusiast with a strong foundation in data analysis, machine learning algorithms, and programming. I have hands-on experience in building models, managing messy data, and solving real-world problems. My goal is to apply data-driven insights to create practical solutions that drive results. I'm eager to contribute my skills in a collaborative environment while continuing to learn and grow in the fields of Data Science, Machine Learning, and NLP.





