Introduction
Juggling with multiple data sets is a common task for a data scientist. And, it’s immensely important for a beginner or intermediate to learn this skill.
I got the idea of writing this article from the past data science competitions. Many a times, people end up getting undesirable NA values while combining or subsetting data sets. If it still happens with you, don’t freak out. You just have to practice these challenges well and you won’t get any NAs again.
After you finish these challenges successfully, it is expected that you will become proficient at manipulating data frames, merging multiple data sets to perform several basic operations on data frame(s). For your convenience, I’ve used R and Python to demonstrate the operations. Also, I’ve given 4 practice exercises.
P.S – For fun, I’ve used a dummy data set from a popular TV Series named ‘Game of Thrones’. If you are crazy about it, great! If not, you will still find it easy to understand.
Data set for every challenge is available for download here.

Table of Contents
- Challenge 1 : Adding More Observations
- Challenge 2 : Dropping Observations
- Challenge 3 : Adding Column(s) Horizontally
- Challenge 4: Adding Column(s) based on common attribute
- Challenge 5 : Adding Column(s) based on observation serial (index)
- Challenge 6: Removing Duplicate Observations
- Challenge 7: Dropping Columns
- Challenge 8: Modifying Value(s) of a DataFrame
- Challenge 9: Renaming Column Name(s)
Before starting with the challenges, make sure you’ve downloaded the data.
Challenge 1 : Adding more observations
i) In Structured Data Set
We have a dummy data set from Game of Thrones named house. It contains information about various clans (houses). Think of houses as families. Let’s say, two new houses have emerged whose information is contained in the data set house_extra.
Task: To include the houses in house_extra in the data set house (i.e merging the two data sets)
| Data : house | |
|---|---|
| House | Region |
| Stark | The North |
| Targaryen | Slaver’s Bay |
| Lannister | The Westerlands |
| Baratheon | The Stormlands |
| Tyrell | The Reach |
| Data : house_extra | |
|---|---|
| House | Region |
| Tully | The Riverlands |
| Greyjoy | The Iron Islands |
You can make a row wise addition of house_extra to house data set by using the following code :
Python Code![]()
R Code![]()
#using base function merge
> house <- merge(house,house_extra,all=TRUE,sort=FALSE)
The output will be :
| House | Region |
|---|---|
| Stark | The North |
| Targaryen | Slaver’s Bay |
| Lannister | The Westerlands |
| Baratheon | The Stormlands |
| Tyrell | The Reach |
| Tully | The Riverlands |
| Greyjoy | The Iron Islands |
ii) In Unstructured Data Set
Now there might be a case where you have an unstructured data. Think of unstructured data as a data without any matrix or data frame. Still, could we add new observations to it?
Suppose you have a new house in the house data frame. The new house is “Redwyne” which is present in “The Reach” region. Now, we want to add this new observation in our existing house data. Let’s see how to do it.
Python Code![]()
> house.loc[len(house)]=['Redwyne','The Reach']
R Code![]()
> house <- rbind(house,data.frame(House=c("Redwyne"),Region=c("The Reach")))
The output will be :
| Data : house | |
|---|---|
| House | Region |
| Stark | The North |
| Targaryen | Slaver’s Bay |
| Lannister | The Westerlands |
| Baratheon | The Stormlands |
| Tyrell | The Reach |
| Tully | The Riverlands |
| Greyjoy | The Iron Islands |
| Redwyne | The Reach |
As you can see, a new house (Redwyne) has been added to the house data frame with its region.
Important Points
1. At times there are situations when we are required to add observations from a data set which has a new column than the existing one. Confused ? Let’s do some changes in data set and understand this point:
Now, the house data set contains two columns (House, Region). Another data set, house_new contains columns (House, Region and Religion). Keep in mind, Religion column is not available in other data set. We are asked to combine these data sets. How can we do?
| Data : house | |
|---|---|
| House | Region |
| Stark | The North |
| Targaryen | Slaver’s Bay |
| Lannister | The Westerlands |
| Baratheon | The Stormlands |
| Tyrell | The Reach |
| Data : house_new | ||
|---|---|---|
| House | Region | Religion |
| Tully | The Riverlands | Seven Gods |
| Greyjoy | The Iron Islands | Sea God |
Let’s find the solution.
Python Code
> house=house.append(house_new)![]()
or
> house=pd.concat([house,house_new],axis=0)
R Code![]()
> house <- merge(house,house_new,all=TRUE,sort=FALSE)
We can see that it assigned NaN to the elements of house data frame because “Religion” variable was not present in the house set.
| House | Region | Religion |
|---|---|---|
| Stark | The North | NaN |
| Targaryen | Slaver’s Bay | NaN |
| Lannister | The Westerlands | NaN |
| Baratheon | The Stormlands | NaN |
| Tyrell | The Reach | NaN |
| Tully | The Riverlands | Seven Gods |
| Greyjoy | The Iron Islands | Sea God |
2. This point is only applicable for python users.
Continuing from point 1, after adding the new houses to the old data set, we end up getting repeated index values. This is definitely a problem.
| Data : house | |||
|---|---|---|---|
| House | Region | Religion | |
| 0 | Stark | The North | NaN |
| 1 | Targaryen | Slaver’s Bay | NaN |
| 2 | Lannister | The Westerlands | NaN |
| 3 | Baratheon | The Stormlands | NaN |
| 4 | Tyrell | The Reach | NaN |
| 0 | Tully | The Riverlands | Seven Gods |
| 1 | Greyjoy | The Iron Islands | Sea God |
Now, if we try to access the first element of the data frame, what will we get? Take a minute to think about it.
> house.ix[0]
The output will be:
| House | Region | Religion | |
|---|---|---|---|
| 0 | Stark | The North | NaN |
| 0 | Tully | The Riverlands | Seven Gods |
We see two elements in the output. Why is that ?
This is because, after merging the two data frames, the index of new observations haven’t changed according to the new data set. So, if we try to access the first element of the data frame, the result will be same as above. To handle this problem, we can treat index also. It can be done by :
#ignore_index does not takes the old index in consideration![]()
>house_data=pd.concat([house,house_new],axis=0,ignore_index=True)
Now the output after vertically adding the data frames will be :
| House | Region | Religion | |
|---|---|---|---|
| 0 | Stark | The North | NaN |
| 1 | Targaryen | Slaver’s Bay | NaN |
| 2 | Lannister | The Westerlands | NaN |
| 3 | Baratheon | The Stormlands | NaN |
| 4 | Tyrell | The Reach | NaN |
| 5 | Tully | The Riverlands | Seven Gods |
| 6 | Greyjoy | The Iron Islands | Sea God |
As we see that the index is no longer the old index of individual data frames. Now, we can access any row without any problem.
Exercise 1 : What will be the output of the append or concat operations on house and house_new if there is an extra variable present in house data frame?
Exercise 2 : Write the code for adding house data frame to house_new(house_new observations will be on top)?
Provide your answers in comments below.
Challenge 2 : Dropping Observations
Dropping Rows
Suppose we have a data set candidates which contains information about heirs (successors) of each house (family). They are sorted on the basis of age in descending order within the same house. (There is no order between the houses).
| Data : candidates | |
|---|---|
| House | Name |
| Lannister | Jamie Lannister |
| Stark | Robb Stark |
| Stark | Arya Stark |
| Lannister | Cersi Lannister |
| Targaryen | Daenerys Targaryen |
| Baratheon | Robert Baratheon |
| Mormont | Jorah Mormont |
Now we want to remove the top two rows of the candidates data frame :
Python Code![]()
# 0 and 1 are the index of the rows we want to remove
> candidates=candidates.drop([0,1])
R Code![]()
# Note: In R, index starts from 1 and not 0.
> candidates=candidates[-c(1:2),]
Output will be :
| House | Name |
|---|---|
| Stark | Arya Stark |
| Lannister | Cersi Lannister |
| Targaryen | Daenerys Targaryen |
| Baratheon | Robert Baratheon |
| Mormont | Jorah Mormont |
Dropping rows based on conditions
In the TV Series, Robb Stark was killed at a wedding. Since he’s no more alive, he can’t be an heir to the Stark House. We should remove him from the data set.
| Data : candidates | |
|---|---|
| House | Name |
| Lannister | Jamie Lannister |
| Stark | Robb Stark |
| Stark | Arya Stark |
| Lannister | Cersi Lannister |
| Targaryen | Daenerys Targaryen |
| Baratheon | Robert Baratheon |
| Mormont | Jorah Mormont |
Task: Prepare the new guest list with Robb Stark’s entry removed. This is how we do it :
Python Code![]()
# We have taken all candidates except "Rob Stark"
> candidates[candidates.Name!= "Robb Stark"]
R Code![]()
> candidates[which(candidates$Name!="Robb Stark"),]
Output will be :
| House | Name |
|---|---|
| Lannister | Jamie Lannister |
| Stark | Arya Stark |
| Lannister | Cersi Lannister |
| Targaryen | Daenerys Targaryen |
| Baratheon | Robert Baratheon |
| Mormont | Jorah Mormont |
Challenge 3 : Adding Column(s) Horizontally
At times, a data set is provided in different files. Each file contains some unique information. We are required to merge them in such a way that we can extract maximum information.
In such cases, how can we decide what kind of merging technique we should apply?
The answer is, it depends on the requirement of problem statement. Below are the different types of merge operations and insights on how to decide which merging technique to apply in various situations.
Sometimes the problem statement is straight forward.
Let’s take this case. The data frames required to combine are shown below. Military strength of each house is given in the same sequence as the sequence of houses in house data set. In such situation, we simply need to map the indexes with one another.
| Data : house | |
|---|---|
| House | Region |
| Stark | The North |
| Targaryen | Slaver’s Bay |
| Lannister | The Westerlands |
| Baratheon | The Stormlands |
| Tyrell | The Reach |
| Data : military |
|---|
| Military_Strength |
| 20000 |
| 110000 |
| 60000 |
| 40000 |
| 30000 |
To get more information about each house’s military strength, we’ll simply add military data set to the house data set:
Python Code![]()
> house=pd.concat([house,military],axis=1)
R Code![]()
> house=cbind(house,military)
The output will be:
| House | Region | Military_Strength |
|---|---|---|
| Stark | The North | 20000 |
| Targaryen | Slaver’s Bay | 110000 |
| Lannister | The Westerlands | 60000 |
| Baratheon | The Stormlands | 40000 |
| Tyrell | The Reach | 30000 |
Wasn’t that easy ? Actually, since the index alignment was similar that’s why we were able to merge these two data sets but this is always not the case. In fact, this would rarely happen in any data science competition. Challenge 4 shows the real trouble.
Challenge 4: Adding Column(s) based on common attribute
Now, how to merge the data sets if their indexes are not aligned?
In such situations, there is always a common attribute (key or keys) that aids us in combining data sets. But, you need to find the common attribute(s) present in the data frames. They could be column(s) or index(s).
Hint : Most of the times, common attribute will be some sort of ID. Keep an eye for it.
There can be different ways to merge the data depending upon the type of question asked. Here we have the house data set and candidates data set. To show you different variations in applying these operations, I am going to solve different questions and situations around the data sets.
Think about the question for a while before diving into the solution.
| Data : candidates | |
|---|---|
| House | Name |
| Lannister | Jamie Lannister |
| Stark | Robb Stark |
| Stark | Arya Stark |
| Lannister | Cersi Lannister |
| Targaryen | Daenerys Targaryen |
| Baratheon | Robert Baratheon |
| Mormont | Jorah Mormont |
| Data : house | ||
|---|---|---|
| House | Region | Military_Strength |
| Stark | The North | 20000 |
| Targaryen | Slaver’s Bay | 110000 |
| Lannister | The Westerlands | 60000 |
| Baratheon | The Stormlands | 40000 |
| Tyrell | The Reach | 30000 |
Question : Which of the candidate has the largest army ?
Just by looking at the heir’s name or his/her house name from the candidates data set will not answer this question. To answer this question, we have to extract the information about military strength from their corresponding houses.
How can we do that? Their index are not aligned, is there any common attribute between them?
Yes, both the data frames have “House” column. We will now see how can we merge the above data set on the basis of a common column.
Python Code![]()
> house = pd.merge(candidates,house,on="House",how="left")
#or
> house = pd.merge(candidates,house,left_on="House",right_on="House",how="left")
R Code![]()
>house <- merge(candidates,house,by='House',all.x=TRUE,sort=FALSE)
The output will be:
| House | Name | Region | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | The Westerlands | 60000 |
| Stark | Robb Stark | The North | 20000 |
| Stark | Arya Stark | The North | 20000 |
| Lannister | Cersi Lannister | The Westerlands | 60000 |
| Targaryen | Daenerys Targaryen | Slaver’s Bay | 110000 |
| Baratheon | Robert Baratheon | The Stormlands | 40000 |
| Mormont | Jorah Mormont | NaN | NaN |
By looking at the above data frame we can say that Daenerys Targaryen has the largest army. But, why did Jorah Mormont get NaN ?
There are a few things to notice here (refer above for codes) :
- In first code we used
on/by="House"which is the common attribute in both the data frames. - In case we merge data on the basis of a particular key, but they have different column name we can use
left_on/by.x&right_on/by.yas shown in the second code. - In both the codes, we used
how='left'/all.x=TRUEwhich uses the key (“House”) from the left frame only. We used left because we want information about all the candidates. - House Tyrell has no entry in the merged data frame because there was no candidate from house Tyrell, left merge took care of it.
- House Mormont don’t have any information in
housedata frame, so candidate Jorah Mormont is assigned with NaN in the merged data frame.
Left merge is used here because we want information about the candidates. So, in the code above, candidates was the left data set and it uses “House” key from left frame only.
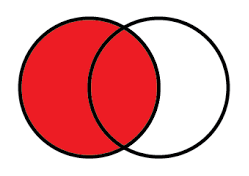
Left Merge
Note : I have used “merge” in headings and explanations. It is the general term that I will be using for combining or joining data set. Where as “merge” in the code is the syntax that is being used for merging, joining or combining.
Question : List all the houses along with their military strength and the rightful heir
Now, we have to deliver information about each house. So, military strength is already present in house data set. All we have to do is to find the heir of each house who is present in candidates data set.
In simple words, we want to extract candidate’s name from candidates data frame and place it with corresponding house. Let’s see.
Python Code![]()
> house = pd.merge(house,candidates,on="House",how="left")
This will provide all the candidates from each house along with their military strength with older candidates at the top. In candidates data frame, an older member of a particular house is placed above the others. We can also perform a right merge operation to do the same thing.
> house=pd.merge(candidates,house,on="House",how="right")
R Code![]()
> house <- merge(candidates,house,by="House",all.y=TRUE,sort=FALSE)
The output will be:
| House | Name | Region | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | The Westerlands | 60000 |
| Lannister | Cersi Lannister | The Westerlands | 60000 |
| Stark | Robb Stark | The North | 20000 |
| Stark | Arya Stark | The North | 20000 |
| Targaryen | Daenerys Targaryen | Slaver’s Bay | 110000 |
| Baratheon | Robert Baratheon | The Stormlands | 40000 |
| Tyrell | NaN | The Reach | 30000 |
Here how="right"/all.y=True uses the key from right frame only.
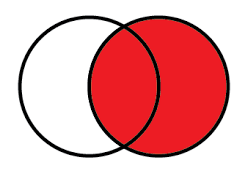
Right Merge
Question : List the houses that have atleast one heir?
Sometimes we just need the part of the combined data where information from both data set is present . In simple words, we can say that we want the intersection between the available information or elements of house & candidates data frame.
Rather than removing the observations having missing values we can directly merge the data set by using the following code :
Python Code![]()
> merge_inner = pd.merge(candidates,house,on="House",how="inner")
R Code![]()
> merge_inner <- merge(candidates,house,by="House",all=FALSE,sort=FALSE)
The output will be:
| House | Name | Region | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | The Westerlands | 60000 |
| Lannister | Cersi Lannister | The Westerlands | 60000 |
| Stark | Robb Stark | The North | 20000 |
| Stark | Arya Stark | The North | 20000 |
| Targaryen | Daenerys Targaryen | Slaver’s Bay | 110000 |
| Baratheon | Robert Baratheon | The Stormlands | 40000 |
Here how="inner"/all=FALSE uses intersection of keys from both frames.
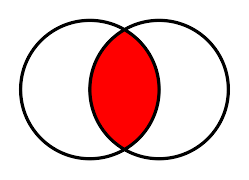
Intersection merge
Question : List all the available information about houses and heirs?
We want all data about the candidates and houses together, regardless of availability of information. In simple words, we can say that we want the union of all the information of house & candidates data frames.
We can do that with following codes :
Python Code![]()
> merge_outer = pd.merge(candidates,house,on="House",how="outer")
R Code![]()
> merge_outer <- merge(candidates,house,all=TRUE,sort=FALSE)
| House | Name | Region | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | The Westerlands | 60000 |
| Lannister | Cersi Lannister | The Westerlands | 60000 |
| Stark | Robb Stark | The North | 20000 |
| Stark | Arya Stark | The North | 20000 |
| Targaryen | Daenerys Targaryen | Slaver’s Bay | 110000 |
| Baratheon | Robert Baratheon | The Stormlands | 40000 |
| Mormont | Jorah Mormont | NaN | NaN |
| Tyrell | NaN | The Reach | 30000 |
Here how="outer"/all=True uses union of key from both frames.
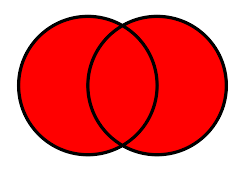
Union Merge
Challenge 5 : Adding Column(s) based on observation serial (index)
Sometimes the common attribute or the key is index in both the data frames or index in one and a column in the other. We are going to handle a similar problem where both the keys are index. Later, you have to find the solution for the other case in the exercise given. Suppose the data sets are :
| Data : candidates | |||
|---|---|---|---|
| Name | |||
| House | |||
| Lannister | Jamie Lannister | ||
| Stark | Robb Stark | ||
| Stark | Arya Stark | ||
| Lannister | Cersi Lannister | ||
| Targaryen | Daenerys Targaryen | ||
| Baratheon | Robert Baratheon | ||
| Mormont | Jorah Mormont | ||
| Data : house | |||
|---|---|---|---|
| Region | Military_Strength | ||
| House | |||
| Stark | The North | 20000 | |
| Targaryen | Slaver’s Bay | 110000 | |
| Lannister | The Westerlands | 60000 | |
| Baratheon | The Stormlands | 40000 | |
| Tyrell | The Reach | 30000 | |
We can merge these two data frames by using the following codes :
Python Code![]()
> house = candidates.join(house,how='left')
#or
#right_index and left_index enables the merging on the index.
#Here also how will have four options 'inner','outer','right' and 'left'
> house = pd.merge(candidates, house, right_index=True, left_index=True,how ='left')
Join function is a convenient method for combining two data frames on the basis of index (by default). But, we can also merge if one of the keys is a column by using ‘on’ parameter.
R Code![]()
> house<-merge(candidates,house,sort=FALSE,all.x=TRUE)
| Name | Region | Military_Strength | |
|---|---|---|---|
| House | |||
| Baratheon | Robert Baratheon | The Stormlands | 40000 |
| Lannister | Jamie Lannister | The Westerlands | 60000 |
| Lannister | Cersi Lannister | The Westerlands | 60000 |
| Mormont | Jorah Mormont | NaN | NaN |
| Stark | Robb Stark | The North | 20000 |
| Stark | Arya Stark | The North | 20000 |
| Targaryen | Daenerys Targaryen | Slaver’s Bay | 110000 |
Caution:
What if the data frames you are merging have a same column name other than the common attribute? What will happen? You can handle that very easily. Let’s see
Suppose you have the following data frames :
| Data : house | ||
|---|---|---|
| House | Region | Military_Strength |
| Stark | The North | 20000 |
| Targaryen | Slaver’s Bay | 110000 |
| Lannister | The Westerlands | 60000 |
| Baratheon | The Stormlands | 40000 |
| Tyrell | The Reach | 30000 |
| Data : candidates | |||
|---|---|---|---|
| House | Name | Region | |
| Lannister | Jamie Lannister | Westros | |
| Stark | Robb Stark | North | |
| Stark | Arya Stark | Westros | |
| Lannister | Cersi Lannister | Westros | |
| Targaryen | Daenerys Targaryen | Mereene | |
| Baratheon | Robert Baratheon | Westros | |
| Mormont | Jorah Mormont | Mereene | |
If you run the merge code, it will add some suffix by default (_x,_y) but you can add your own suffix by using the following code :
Python Code![]()
> house = pd.merge(candidates,house, on='House', how='left', suffixes=('_left', '_right'))
R Code![]()
> house <-merge(candidates,house,by="House",all.x=TRUE,
sort=FALSE,suffixes=c("_left","_right")
The output will be :
| House | Name | Region_left | Region_right | Military_Strength |
|---|---|---|---|---|
| Lannister | Jamie Lannister | Westros | The Westerlands | 60000 |
| Stark | Robb Stark | North | The North | 20000 |
| Stark | Arya Stark | Westros | The North | 20000 |
| Lannister | Cersi Lannister | Westros | The Westerlands | 60000 |
| Targaryen | Daenerys Targaryen | Mereene | Slaver’s Bay | 110000 |
| Baratheon | Robert Baratheon | Westros | The Stormlands | 40000 |
| Mormont | Jorah Mormont | Mereene | NaN | NaN |
Exercise 3 : Comment the code that will left merge the following data set on the basis of “House” :
| Data : house | |||
|---|---|---|---|
| Region | Military_Strength | ||
| House | |||
| Stark | The North | 20000 | |
| Targaryen | Slaver’s Bay | 110000 | |
| Lannister | The Westerlands | 60000 | |
| Baratheon | The Stormlands | 40000 | |
| Tyrell | The Reach | 30000 | |
| Data : candidates | |||
|---|---|---|---|
| Name | |||
| House | |||
| Lannister | Jamie Lannister | ||
| Stark | Robb Stark | ||
| Stark | Arya Stark | ||
| Lannister | Cersi Lannister | ||
| Targaryen | Daenerys Targaryen | ||
| Baratheon | Robert Baratheon | ||
| Mormont | Jorah Mormont | ||
Challenge 6: Removing Duplicate Observations
Let me start this section with a question.
Again, you have two data sets house & candidates as shown below. You are asked about the details of the next heir for each house with his/her military strength (in this case next heir will be the older child).
| Data : house | |||
|---|---|---|---|
| House | Region | Military_Strength | |
| Stark | The North | 20000 | |
| Targaryen | Slaver’s Bay | 110000 | |
| Lannister | The Westerlands | 60000 | |
| Baratheon | The Stormlands | 40000 | |
| Tyrell | The Reach | 30000 | |
| Data : candidates | |
|---|---|
| House | Name |
| Lannister | Jamie Lannister |
| Stark | Robb Stark |
| Stark | Arya Stark |
| Lannister | Cersi Lannister |
| Targaryen | Daenerys Targaryen |
| Baratheon | Robert Baratheon |
| Mormont | Jorah Mormont |
Now, lets apply merge operation using the “house” key from candidates frame :
Python Code![]()
#using left join
> heir = pd.merge(candidates,house,on="House",how='left')
R Code![]()
> heir = merge(candidates,house,by="House",all.x=TRUE,sort=FALSE)
The output will be :
| House | Name | Region | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | The Westerlands | 60000 |
| Stark | Robb Stark | The North | 20000 |
| Stark | Arya Stark | The North | 20000 |
| Lannister | Cersi Lannister | The Westerlands | 60000 |
| Targaryen | Daenerys Targaryen | Slaver’s Bay | 110000 |
| Baratheon | Robert Baratheon | The Stormlands | 40000 |
| Mormont | Jorah Mormont | NaN | NaN |
As you can see, we have repetition here which is not needed for the question I asked. You have to understand the structure of data sets and the method being applied for merging. Otherwise you can end up with a data set that you think is ready for analysis, but it is not the required one and can impact the output.
Just take a minute and think about the possible solutions for this problem.
To tackle this problem we can apply several methods. Here we are going to use the following method :
1. Removing the duplicates : We can remove the redundant entries from the candidates data frame by keeping the first entry of the candidate from the top. We are using the first entry because candidates are sorted age wise in descending order. So, the older child will be at higher position in the data frame. Below are the codes to implement it :
#keep = 'first' will keep the first occurrence
#keep = 'last' will keep the last occurrence
#keep = False will drop all the duplicates
# make sure to use inplace=True to save the modified data frame
Python Code![]()
> candidates.drop_duplicates(subset=['House'],keep='first',inplace=True)
R Code![]()
> candidates <- candidates[!duplicated(candidates[,1]),]
Now we can merge the data frames :
#In python
> pd.merge(candidates,house,on="House",how='left')
#In R
> merge(candidates,house,by="House",all.x=TRUE,sort=FALSE)
The output will be :
| House | Name | Region | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | The Westerlands | 60000 |
| Stark | Robb Stark | The North | 20000 |
| Targaryen | Daenerys Targaryen | Slaver’s Bay | 110000 |
| Baratheon | Robert Baratheon | The Stormlands | 40000 |
| Mormont | Jorah Mormont | NaN | NaN |
As we can see “Arya Stark” from house “Stark” and “Cersi Lannister” from house “Lannister” are removed in the resultant data set thus providing the rightful heirs from each house.
2. Aggregating the duplicates : Let understand this using an example.
Suppose if there are two members from a house then each member will have the military strength shown separately. As given in house data set, “Starks” have 20,000 soldiers. Then, both “Arya Stark” and “Robb Stark” gets 20,000 soldiers individually.
But, while forming the list of the rightful heirs from each house, the oldest heir gets the first right to claim the throne / title. Hence, we don’t need just one heir for a house.
How can we remove this redundancy? By simply removing the repetition as done in previous method will end up getting us wrong data, thus we have to add up the military strength for the members of same house. For different situation this technique will differ.
Challenge 7: Dropping Columns
After merging the data sets, we ended up with a data set consisting a large number of columns. Some of the columns are trivial or consist of information which is already present in other variables (co-related).
Suppose we have the data set :
| Data : merged_candidates | ||||
|---|---|---|---|---|
| House | Name | Region_left | Region_right | Military_Strength |
| Lannister | Jamie Lannister | Westros | The Westerlands | 60000 |
| Stark | Robb Stark | North | The North | 20000 |
| Stark | Arya Stark | Westros | The North | 20000 |
| Lannister | Cersi Lannister | Westros | The Westerlands | 60000 |
| Targaryen | Daenerys Targaryen | Mereene | Slaver’s Bay | 110000 |
| Baratheon | Robert Baratheon | Westros | The Stormlands | 40000 |
| Mormont | Jorah Mormont | Mereene | NaN | NaN |
The data frame shown above has two similar kind of variables Region_left and Region_right. Out of these two Region_right is insignificant we want to remove this variable :
Python Code![]()
# axis=1 will remove the mentioned columns
> merged_candidates = merged_candidates.drop('Region_right',axis=1)
R Code![]()
> merged_candidates <- subset(merged_candidates,select=-c(Region_Right))
The output will be :
| House | Name | Region_left | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | Westros | 60000 |
| Stark | Robb Stark | North | 20000 |
| Stark | Arya Stark | Westros | 20000 |
| Lannister | Cersi Lannister | Westros | 60000 |
| Targaryen | Daenerys Targaryen | Mereene | 110000 |
| Baratheon | Robert Baratheon | Westros | 40000 |
| Mormont | Jorah Mormont | Mereene | NaN |
Challenge 8: Modifying Value(s) of a DataFrame
Modifying a particular element
Our work is not finished yet. There are some irregularities that we still have to take care of. A data set might contain incorrect information. In our merged data set from last section candidate “Arya Stark” is in “North” region but this data shows “Westros” as her region.
| Data : merged | |||
|---|---|---|---|
| House | Name | Region_left | Military_Strength |
| Lannister | Jamie Lannister | Westros | 60000 |
| Stark | Robb Stark | North | 20000 |
| Stark | Arya Stark | Westros | 20000 |
| Lannister | Cersi Lannister | Westros | 60000 |
| Targaryen | Daenerys Targaryen | Mereene | 110000 |
| Baratheon | Robert Baratheon | Westros | 40000 |
| Mormont | Jorah Mormont | Mereene | NaN |
We have to change the region of “Arya Stark” to “North” :
Python Code![]()
# Arya Stark's region will be replaced from "Westros" to "North"
>merged[merged['Name']=="Arya Stark"]=merged[merged['Name']=="Arya Stark"].replace("Westros","North")
R Code![]()
> merged$Region_left[which(merged$Name=="Arya Stark")] <- "North"
The output will look like :
| House | Name | Region_left | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | Westros | 60000 |
| Stark | Robb Stark | North | 20000 |
| Stark | Arya Stark | North | 20000 |
| Lannister | Cersi Lannister | Westros | 60000 |
| Targaryen | Daenerys Targaryen | Mereene | 110000 |
| Baratheon | Robert Baratheon | Westros | 40000 |
| Mormont | Jorah Mormont | Mereene | NaN |
After this operation region of “Arya Stark” is changed to “North”.
Modifying elements on the basis of a condition
In our data set, region “Westros” is a more general term consisting of many kingdoms so we have to change all the entries “Westros” to “Kings Landing”. Let’s see how to do it
Python Code![]()
# All the Westros are replaced by Kings Landing
> merged.replace("Westros","Kings Landing",inplace=True)
R Code![]()
> merged$Region_left[which(merged$Region_left=="Westros")]="Kings Landing"
The output will be:
| House | Name | Region_left | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | Kings Landing | 60000 |
| Stark | Robb Stark | North | 20000 |
| Stark | Arya Stark | North | 20000 |
| Lannister | Cersi Lannister | Kings Landing | 60000 |
| Targaryen | Daenerys Targaryen | Mereene | 110000 |
| Baratheon | Robert Baratheon | Kings Landing | 40000 |
| Mormont | Jorah Mormont | Mereene | NaN |
Challenge 9: Renaming Column Name(s)
We are just finishing up with all the challenges, lastly there might be a scenario where you want to change a column name. Let’s say in our data set, we want to change the column name from “Region_left” to “Region” .
Before changing the column name our data set was :
| Data : merged | |||
|---|---|---|---|
| House | Name | Region_left | Military_Strength |
| Lannister | Jamie Lannister | Kings Landing | 60000 |
| Stark | Robb Stark | North | 20000 |
| Stark | Arya Stark | North | 20000 |
| Lannister | Cersi Lannister | Kings Landing | 60000 |
| Targaryen | Daenerys Targaryen | Mereene | 110000 |
| Baratheon | Robert Baratheon | Kings Landing | 40000 |
| Mormont | Jorah Mormont | Mereene | NaN |
Changing the column name using the following code
Python Code![]()
> merged.columns = merged.columns.str.replace("Region_left","Region")
R Code![]()
> colnames(merged)[which(names(merged)=="Region_left")] <- "Region"
The output will be:
| House | Name | Region | Military_Strength |
|---|---|---|---|
| Lannister | Jamie Lannister | Kings Landing | 60000 |
| Stark | Robb Stark | North | 20000 |
| Stark | Arya Stark | North | 20000 |
| Lannister | Cersi Lannister | Kings Landing | 60000 |
| Targaryen | Daenerys Targaryen | Mereene | 110000 |
| Baratheon | Robert Baratheon | Kings Landing | 40000 |
| Mormont | Jorah Mormont | Mereene | NaN |
End Notes
If you have reached this line, I would like to applaud you for the patience and persistence you’ve shown in traversing over these challenges. I’ve considered all types of situations which could arise while merging, joining and subsetting data set. Hence, working on these challenges will make your knowledge comprehensive enough to deal with any situation.
For best results, make sure you do these 9 challenges and 4 exercises given. If there is anything else, you think could be made better, feel free to drop your suggestions.
Did you like reading this article ? Do you follow a different approach / package / library to perform these talks. I’d love to interact with you in comments.






Really useful, Thanks
Welcome :)
In Challenge 2 : Dropping Observations, I think instead of following statement: > candidates=candidates[-c(1:2)] It should be > candidates = candidates[-c(1:2),] Reason: Without comma, given statement in article will remove columns instead rows which is the objective.
Thanks Nitesh for finding out that mistake.
"Dropping rows based on conditions", In given statement, comma is missing which will help in eliminating the mentioned name record. It should be : candidates[which(candidates$Name!="Robb Stark"),] instead of : candidates[which(candidates$Name!="Robb Stark")]