Introduction
It is becoming very hard to stay up to date with recent advancements happening in deep learning. Hardly a day goes by without a new innovation or a new application of deep learning coming by. However, most of these advancements are hidden inside a large amount of research papers that are published on mediums like ArXiv / Springer

To keep ourselves updated, we have created a small reading group to share our learnings internally at Analytics Vidhya. One such learning I would like to share with the community is a a survey of advanced architectures which have been developed by the research community.
This article contains some of the recent advancements in Deep Learning along with codes for implementation in keras library. I have also provided links to the original papers, in case you are interested in reading them or want to refer them.
To keep the article concise, I have only considered the architectures which have been successful in Computer Vision domain.
If you are interested, read on!
P.S.: This article assumes the knowledge of neural networks and familiarity with keras. If you need to catch up on these topics, I would strongly recommend you read the following articles first:
- Fundamentals of Deep Learning – Starting with Artificial Neural Network
- Tutorial: Optimizing Neural Networks using Keras (with Image recognition case study)
Table of contents
What do we mean by an Advanced Architecture?
Deep Learning algorithms consists of such a diverse set of models in comparison to a single traditional machine learning algorithm. This is because of the flexibility that neural network provides when building a full fledged end-to-end model.
Neural network can sometimes be compared with lego blocks, where you can build almost any simple to complex structure your imagination helps you to build.

We can define an advanced architecture as one that has a proven track record of being a successful model. This is mainly seen in challenges like ImageNet, where your task is to solve a problem, say image recognition, using the data given. Those who don’t know what ImageNet is, it is the dataset which is provided in ILSVR (ImageNet Large Scale Visual Recognition) challenge.
Also as described in the below mentioned architectures, each of them has a nuance which sets them apart from the usual models; giving them an edge when they are used to solve a problem. These architectures also fall in the category of “deep” models, so they are likely to perform better than their shallow counterparts.
Types of Computer Vision Tasks
This article is mainly focused on Computer Vision, so it is natural to describe the horizon of computer vision tasks. Computer Vision; as the name suggests is simply creating artificial models which can replicate the visual tasks performed by a human. This essentially means what we can see and what we perceive is a process which can be understood and implemented in an artificial system.
The main types of tasks that computer vision can be categorised in are as follows:
- Object Recognition / classification – In object recognition, you are given a raw image and your task is to identify which class does the image belong to.
- Classification + Localisation – If there is only one object in the image, and your task is to find the location of that object, a more specific term given to this problem is localisation problem.
- Object Detection – In object detection, you task is to identify where in the image does the objects lies in. These objects might be of the same class or different class altogether.
- Image Segmentation – Image Segmentation is a bit sophisticated task, where the objective is to map each pixel to its rightful class.

List of Deep Learning Architectures
Now that we have understood what an advanced architecture is and explored the tasks of computer vision, let us list down the most important architectures and their descriptions:
1. AlexNet
AlexNet is the first deep architecture which was introduced by one of the pioneers in deep learning – Geoffrey Hinton and his colleagues. It is a simple yet powerful network architecture, which helped pave the way for groundbreaking research in Deep Learning as it is now. Here is a representation of the architecture as proposed by the authors.

When broken down, AlexNet seems like a simple architecture with convolutional and pooling layers one on top of the other, followed by fully connected layers at the top. This is a very simple architecture, which was conceptualised way back in 1980s. The things which set apart this model is the scale at which it performs the task and the use of GPU for training. In 1980s, CPU was used for training a neural network. Whereas AlexNet speeds up the training by 10 times just by the use of GPU.
Although a bit outdated at the moment, AlexNet is still used as a starting point for applying deep neural networks for all the tasks, whether it be computer vision or speech recognition.
2. VGG Net
The VGG Network was introduced by the researchers at Visual Graphics Group at Oxford (hence the name VGG). This network is specially characterized by its pyramidal shape, where the bottom layers which are closer to the image are wide, whereas the top layers are deep.

As the image depicts, VGG contains subsequent convolutional layers followed by pooling layers. The pooling layers are responsible for making the layers narrower. In their paper, they proposed multiple such types of networks, with change in deepness of the architecture.

The advantages of VGG are :
- It is a very good architecture for benchmarking on a particular task.
- Also, pre-trained networks for VGG are available freely on the internet, so it is commonly used out of the box for various applications.
On the other hand, its main disadvantage is that it is very slow to train if trained from scratch. Even on a decent GPU, it would take more than a week to get it to work.
3. GoogleNet
GoogleNet (or Inception Network) is a class of architecture designed by researchers at Google. GoogleNet was the winner of ImageNet 2014, where it proved to be a powerful model.
In this architecture, along with going deeper (it contains 22 layers in comparison to VGG which had 19 layers), the researchers also made a novel approach called the Inception module.

As seen above, it is a drastic change from the sequential architectures which we saw previously. In a single layer, multiple types of “feature extractors” are present. This indirectly helps the network perform better, as the network at training itself has many options to choose from when solving the task. It can either choose to convolve the input, or to pool it directly.

The final architecture contains multiple of these inception modules stacked one over the other. Even the training is slightly different in GoogleNet, as most of the topmost layers have their own output layer. This nuance helps the model converge faster, as there is a joint training as well as parallel training for the layers itself.
The advantages of GoogleNet are :
- GoogleNet trains faster than VGG.
- Size of a pre-trained GoogleNet is comparatively smaller than VGG. A VGG model can have >500 MBs, whereas GoogleNet has a size of only 96 MB
GoogleNet does not have an immediate disadvantage per se, but further changes in the architecture are proposed, which make the model perform better. One such change is termed as an Xception Network, in which the limit of divergence of inception module (4 in GoogleNet as we saw in the image above) are increased. It can now theoretically be infinite (hence called extreme inception!)
4. ResNet
ResNet is one of the monster architectures which truly define how deep a deep learning architecture can be. Residual Networks (ResNet in short) consists of multiple subsequent residual modules, which are the basic building block of ResNet architecture. A representation of residual module is as follows

In simple words, a residual module has two options, either it can perform a set of functions on the input, or it can skip this step altogether.
Now similar to GoogleNet, these residual modules are stacked one over the other to form a complete end-to-end network.

A few more novel techniques which ResNet introduced are:
- Use of standard SGD instead of a fancy adaptive learning technique. This is done along with a reasonable initialization function which keeps the training intact
- Changes in preprocessing the input, where the input is first divided into patches and then feeded into the network
The main advantage of ResNet is that hundreds, even thousands of these residual layers can be used to create a network and then trained. This is a bit different from usual sequential networks, where you see that there is reduced performance upgrades as you increase the number of layers.
5. ResNeXt
ResNeXt is said to be the current state-of-the-art technique for object recognition. It builds upon the concepts of inception and resnet to bring about a new and improved architecture. Below image is a summarization of how a residual module of ResNeXt module looks like.

6. RCNN (Region Based CNN)
Region Based CNN architecture is said to be the most influential of all the deep learning architectures that have been applied to object detection problem. To solve detection problem, what RCNN does is to attempt to draw a bounding box over all the objects present in the image, and then recognize what object is in the image. It works as follows:

The structure of RCNN is as follows:

7. YOLO (You Only Look Once)
YOLO is the current state-of-the-art real time system built on deep learning for solving image detection problems. As seen in the below given image, it first divides the image into defined bounding boxes, and then runs a recognition algorithm in parallel for all of these boxes to identify which object class do they belong to. After identifying this classes, it goes on to merging these boxes intelligently to form an optimal bounding box around the objects.

All of this is done in parallely, so it can run in real time; processing upto 40 images in a second.
Although it gives reduced performance than its RCNN counterpart, it still has an advantage of being real time to be viable for use in day-to-day problems. Here is a representation of architecture of YOLO

8. SqueezeNet
The squeezeNet architecture is one more powerful architecture which is extremely useful in low bandwidth scenarios like mobile platforms. This architecture has occupies only 4.9MB of space, on the other hand, inception occupies ~100MB! This drastic change is brought up by a specialized structure called the fire module. Below image is a representation of fire module.

The final architecture of squeezeNet is as follows:
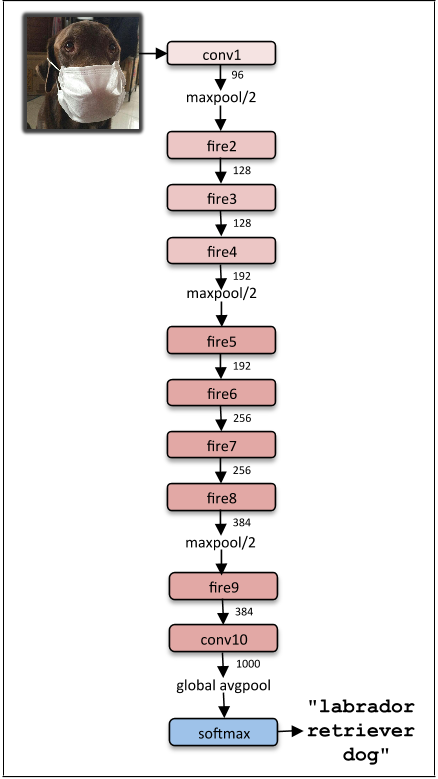
9. SegNet
SegNet is a deep learning architecture applied to solve image segmentation problem. It consists of sequence of processing layers (encoders) followed by a corresponding set of decoders for a pixelwise classification . Below image summarizes the working of SegNet.

One key feature of SegNet is that it retains high frequency details in segmented image as the pooling indices of encoder network is connected to pooling indices of decoder networks. In short, the information transfer is direct instead of convolving them. SegNet is one the the best model to use when dealing with image segmentation problems
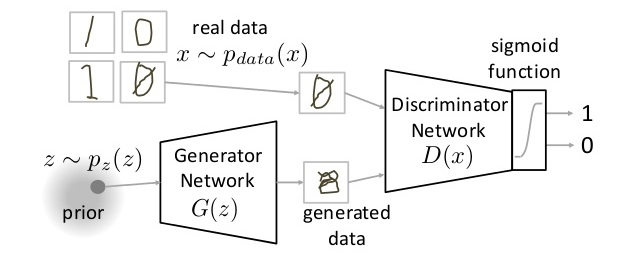
10. GAN (Generative Adversarial Network)
GAN is an entirely different breed of neural network architectures, in which a neural network is used to generate an entirely new image which is not present is the training dataset, but is realistic enough to be in the dataset. For example, below image is a breakdown of GANs are made of. I have covered how GANs work in this article. Go through it if you are curious.
Frequently Asked Questions
Q1. What is neural network architecture in deep learning?
A. Neural network architecture in deep learning refers to the structural design and organization of artificial neural networks. It includes the arrangement and connectivity of layers, the number of neurons in each layer, the types of activation functions used, and the presence of specialized layers like convolutional or recurrent layers. The architecture determines how information flows through the network and plays a crucial role in the network’s ability to learn and solve complex problems.
Q2. Is CNN a deep learning architecture?
A. Yes, CNN (Convolutional Neural Network) is a deep learning architecture. CNNs are a type of neural network specifically designed for processing and analyzing structured grid-like data, such as images and videos. They are characterized by the presence of convolutional layers, which perform local receptive field operations to extract relevant features from the input data. CNNs have shown remarkable success in various computer vision tasks, making them a fundamental component of deep learning in the field of image recognition, object detection, and other visual tasks.
End Notes
In this article, I have covered an overview of major deep learning architectures that you should get familiar with. If you have any questions on deep learning architectures, please feel free to share them with me through comments.
Learn, compete, hack and get hired!
Faizan is a Data Science enthusiast and a Deep learning rookie. A recent Comp. Sc. undergrad, he aims to utilize his skills to push the boundaries of AI research.






Good Article, Thanks for sharing links to papers & code implementation
Thanks Mohit!
Excellent assembly. Can we be a part of that reading community?
Sure! If there are enough people, we can create a channel on discussion portal too.
Good Work Faizan. I assume its an update to https://adeshpande3.github.io/adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html
Thanks Arun. Perhaps the aim is a bit different for both the post. His seems to cover more of a broader horizon of deep learning papers, whereas this post is more focused on architectures in deep learning.