Overview
- How do search engines like Google understand our queries and provide relevant results?
- Learn about the concept of information extraction
- We will apply information extraction in Python using the popular spaCy library – so a lot of hands-on learning is ahead!
Introduction
I rely heavily on search engines (especially Google) in my daily role as a data scientist. My search results span a variety of queries – Python code questions, machine learning algorithms, comparison of Natural Language Processing (NLP) frameworks, among other things.
I’ve always been curious about how these search engines understand my query and extract the relevant results as if they know what I am thinking.
I wanted to understand how the NLP aspect works here – basically, how does the algorithm understand unstructured text data and convert that into structured data and show me relevant results?
Let’s take an example. I entered two different queries on Google:

In the first instance, Google quickly identified the entity (world cup) and the action (won). In the second query, I didn’t even finish the sentence before I got the result!
How do you think Google understood the context behind these queries? It’s a fascinating thought and we are going to unbox it in this article. We will understand the core idea behind how these meaningful and relevant results are generated based on our search queries. And yes, we will even dive into the Python code and take a hands-on approach to this. Let’s dive in!
Note: I recommend going through this article on Introduction to Computational Linguistics and Dependency Trees in data science to get a better feel for what we will learn here.
Table of contents
Introduction to Information Extraction
Information Extraction (IE) is a crucial cog in the field of Natural Language Processing (NLP) and linguistics. It’s widely used for tasks such as Question Answering Systems, Machine Translation, Entity Extraction, Event Extraction, Named Entity Linking, Coreference Resolution, Relation Extraction, etc.
In information extraction, there is an important concept of triples.
A triple represents a couple of entities and a relation between them. For example, (Obama, born, Hawaii) is a triple in which ‘Obama’ and ‘Hawaii’ are the related entities, and the relation between them is ‘born’.
In this article, we will focus on the extraction of these types of triples from a given text.
Before moving ahead, let’s take a look at the different approaches to Information Extraction. We can broadly divide Information Extraction into two branches as shown below:
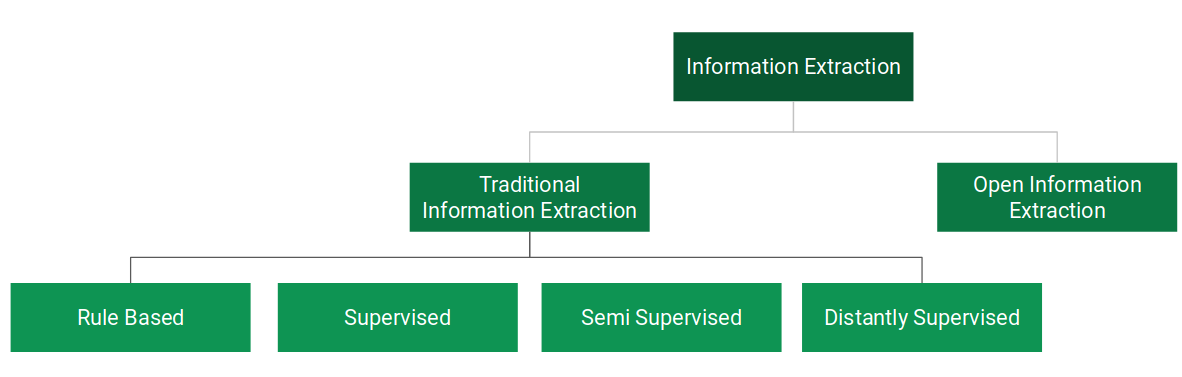
In Traditional Information Extraction, the relations to be extracted are pre-defined. In this article, we will cover the rule-based methods only.
In Open Information Extraction, the relations are not pre-defined. The system is free to extract any relations it comes across while going through the text data.
Semantic Relationships: Get Structured Knowledge from Unstructured Text
Have a look at the text snippet below:

Can you think of any method to extract meaningful information from this text? Let’s try to solve this problem sentence by sentence:

In the first sentence, we have two entities (“Food Tutorials” and “Wes Anderson”). These entities are related by the term “Directed”. Hence, (Wes Anderson, directed, Food Tutorials) is a triple. Similarly, we can extract relations from the other sentences as well:

It turns out that we can get structured information based on the syntactic structure and grammar of the text, as illustrated in the example above.
Different Approaches to Information Extraction
In the previous section, we managed to easily extract triples from a few sentences. However, in the real world, the data size is huge and manual extraction of structured information is not feasible. Therefore, automating this information extraction becomes important.
There are multiple approaches to perform information extraction automatically. Let’s understand them one-by-one:
- Rule-based Approach: We define a set of rules for the syntax and other grammatical properties of a natural language and then use these rules to extract information from text
- Supervised: Let’s say we have a sentence S. It has two entities E1 and E2. Now, the supervised machine learning model has to detect whether there is any relation (R) between E1 and E2. So, in a supervised approach, the task of relation extraction turns into the task of relation detection. The only drawback of this approach is that it needs a lot of labeled data to train a model
- Semi-supervised: When we don’t have enough labeled data, we can use a set of seed examples (triples) to formulate high-precision patterns that can be used to extract more relations from the text
Information Extraction using Python and spaCy
We have a grasp on the theory here so let’s get into the Python code aspect. I’m sure you’ve been itching to get your hands on this section!
We will do a small project to extract structured information from unstructured data (text data in our case). We’ve already seen that the information in text lies in the form of relations between different entities.
Hence, in this section, we will try to discover and extract different entity pairs that are associated with some relation or another.
1. spaCy’s Rule-Based Matching
Before we get started, let’s talk about Marti Hearst. She is a computational linguistics researcher and a professor in the School of Information at the University of California, Berkeley. How does she fit into this article? I can sense you wondering.
Professor Marti has actually done extensive research on the topic of information extraction. One of her most interesting studies focuses on building a set of text-patterns that can be employed to extract meaningful information from text. These patterns are popularly known as “Hearst Patterns”.
Let’s look at the example below:

We can infer that “Gelidium” is a type of “red algae” just by looking at the structure of the sentence.
In linguistics terms, we will call “red algae” as Hypernym and “Gelidium” as its Hyponym.
We can formalize this pattern as “X such as Y”, where X is the hypernym and Y is the hyponym. This was one of the many patterns from the Hearst Patterns. Here’s a list to give you an intuition behind the idea:

Now let’s try to extract hypernym-hyponym pairs by using these patterns/rules. We will use spaCy’s rule-based matcher to perform this task.
First, we will import the required libraries:
import re
import string
import nltk
import spacy
import pandas as pd
import numpy as np
import math
from tqdm import tqdm
from spacy.matcher import Matcher
from spacy.tokens import Span
from spacy import displacy
pd.set_option('display.max_colwidth', 200)Next, load a spaCy model:
# load spaCy model
nlp = spacy.load("en_core_web_sm")We are all set to mine information from text based on these Hearst Patterns.
# sample text
text = "GDP in developing countries such as Vietnam will continue growing at a high rate."
# create a spaCy object
doc = nlp(text)- Pattern: X such as Y
To be able to pull out the desired information from the above sentence, it is really important to understand its syntactic structure – things like the subject, object, modifiers, and parts-of-speech (POS) in the sentence.
# print token, dependency, POS tag
for tok in doc:
print(tok.text, "-->",tok.dep_,"-->", tok.pos_)We can easily explore these syntactic details in the sentence by using spaCy:
Output:
GDP --> nsubj --> NOUN in --> prep --> ADP developing --> amod --> VERB countries --> pobj --> NOUN such --> amod --> ADJ as --> prep --> ADP Vietnam --> pobj --> PROPN will --> aux --> VERB continue --> ROOT --> VERB growing --> xcomp --> VERB at --> prep --> ADP a --> det --> DET high --> amod --> ADJ rate --> pobj --> NOUN . --> punct --> PUNCT
Have a look around the terms “such” and “as” . They are followed by a noun (“countries”). And after them, we have a proper noun (“Vietnam”) that acts as a hyponym.
So, let’s create the required pattern using the dependency tags and the POS tags:
#define the pattern
pattern = [{'POS':'NOUN'},
{'LOWER': 'such'},
{'LOWER': 'as'},
{'POS': 'PROPN'} #proper noun]Let’s extract the pattern from the text:
# Matcher class object
matcher = Matcher(nlp.vocab)
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)Output: ‘countries such as Vietnam’
Nice! It works perfectly. However, if we could get “developing countries” instead of just “countries”, then the output would make more sense.
So, we will now also capture the modifier of the noun just before “such as” by using the code below:
# Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'amod', 'OP':"?"}, # adjectival modifier
{'POS':'NOUN'},
{'LOWER': 'such'},
{'LOWER': 'as'},
{'POS': 'PROPN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)Output: ‘developing countries such as Vietnam’
Here, “developing countries” is the hypernym and “Vietnam” is the hyponym. Both of them are semantically related.
Note: The key ‘OP’: ‘?’ in the pattern above means that the modifier (‘amod’) can occur once or not at all.
In a similar manner, we can get several pairs from any piece of text:
- Fruits such as apples
- Cars such as Ferrari
- Flowers such as rose
Now let’s use some other Hearst Patterns to extract more hypernyms and hyponyms.
doc = nlp("Here is how you can keep your car and other vehicles clean.")
# print dependency tags and POS tags
for tok in doc:
print(tok.text, "-->",tok.dep_, "-->",tok.pos_)- Pattern: X and/or Y
Output:
Here --> advmod --> ADV is --> ROOT --> VERB how --> advmod --> ADV you --> nsubj --> PRON can --> aux --> VERB keep --> ccomp --> VERB your --> poss --> DET car --> dobj --> NOUN and --> cc --> CCONJ other --> amod --> ADJ vehicles --> conj --> NOUN clean --> oprd --> ADJ . --> punct --> PUNCT
# Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'amod', 'OP':"?"},
{'POS':'NOUN'},
{'LOWER': 'and', 'OP':"?"},
{'LOWER': 'or', 'OP':"?"},
{'LOWER': 'other'},
{'POS': 'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)Output: ‘car and other vehicles’
Let’s try out the same code to capture the “X or Y” pattern:
# replaced 'and' with 'or'
doc = nlp("Here is how you can keep your car or other vehicles clean.")
The rest of the code will remain the same:
# Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'amod', 'OP':"?"},
{'POS':'NOUN'},
{'LOWER': 'and', 'OP':"?"},
{'LOWER': 'or', 'OP':"?"},
{'LOWER': 'other'},
{'POS': 'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)Output: ‘car or other vehicles’
Excellent – it works!
- Pattern: X, including Y
doc = nlp("Eight people, including two children, were injured in the explosion")
for tok in doc:
print(tok.text, "-->",tok.dep_, "-->",tok.pos_)# Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'nummod','OP':"?"}, # numeric modifier
{'DEP':'amod','OP':"?"}, # adjectival modifier
{'POS':'NOUN'},
{'IS_PUNCT': True},
{'LOWER': 'including'},
{'DEP':'nummod','OP':"?"},
{'DEP':'amod','OP':"?"},
{'POS':'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)Output:
Eight --> nummod --> NUM people --> nsubjpass --> NOUN , --> punct --> PUNCT including --> prep --> VERB two --> nummod --> NUM children --> pobj --> NOUN , --> punct --> PUNCT were --> auxpass --> VERB injured --> ROOT --> VERB in --> prep --> ADP the --> det --> DET explosion --> pobj --> NOUN
Output: ‘Eight people, including two children’
- Pattern: X, especially Y
doc = nlp("A healthy eating pattern includes fruits, especially whole fruits.")
for tok in doc:
print(tok.text, tok.dep_, tok.pos_)Output:
A --> det --> DET healthy --> amod --> ADJ eating --> compound --> NOUN pattern --> nsubj --> NOUN includes --> ROOT --> VERB fruits --> dobj --> NOUN , --> punct --> PUNCT especially --> advmod --> ADV whole --> amod --> ADJ fruits --> appos --> NOUN . --> punct --> PUNCT
# Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'nummod','OP':"?"},
{'DEP':'amod','OP':"?"},
{'POS':'NOUN'},
{'IS_PUNCT':True},
{'LOWER': 'especially'},
{'DEP':'nummod','OP':"?"},
{'DEP':'amod','OP':"?"},
{'POS':'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)Output: ‘fruits, especially whole fruits’
Output: ‘fruits, especially whole fruits’
2. Subtree Matching for Relation Extraction
The simple rule-based methods work well for information extraction tasks. However, they have a few drawbacks and shortcomings.
We have to be extremely creative to come up with new rules to capture different patterns. It is difficult to build patterns that generalize well across different sentences.
To enhance the rule-based methods for relation/information extraction, we should try to understand the dependency structure of the sentences at hand.
Let’s take a sample text and build its dependency graphing tree:
text = "Tableau was recently acquired by Salesforce."
# Plot the dependency graph
doc = nlp(text)
displacy.render(doc, style='dep',jupyter=True)Output:

Can you find any interesting relation in this sentence?
If you look at the entities in the sentence – Tableau and Salesforce – they are related by the term ‘acquired’. So, the pattern I can extract from this sentence is either “Salesforce acquired Tableau” or “X acquired Y”.
Now consider this statement: “Careem, a ride-hailing major in the middle east, was acquired by Uber.”
Its dependency graph will look something like this:
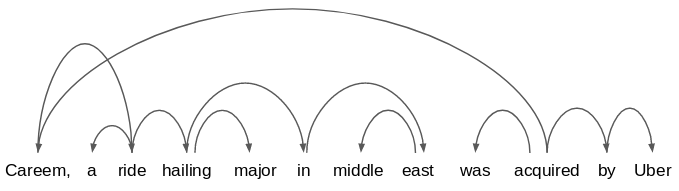
Pretty scary, right?
Don’t worry! All we have to check is which dependency paths are common between multiple sentences. This method is known as Subtree matching.
For instance, if we compare this statement with the previous one:


We will just consider the common dependency paths and extract the entities and the relation (acquired) between them. Hence, the relations extracted from these sentences are:
- Salesforce acquired Tableau
- Uber acquired Careem
Let’s try to implement this technique in Python. We will again use spaCy as it makes it pretty easy to traverse a dependency tree.
We will start by taking a look at the dependency tags and POS tags of the words in the sentence:
text = "Tableau was recently acquired by Salesforce."
doc = nlp(text)
for tok in doc:
print(tok.text,"-->",tok.dep_,"-->",tok.pos_)Output:
Tableau --> nsubjpass --> PROPN was --> auxpass --> VERB recently --> advmod --> ADV acquired --> ROOT --> VERB by --> agent --> ADP Salesforce --> pobj --> PROPN . --> punct --> PUNCT
Here, the dependency tag for “Tableau” is nsubjpass which stands for a passive subject (as it is a passive sentence). The other entity “Salesforce” is the object in this sentence and the term “acquired” is the ROOT of the sentence which means it somehow connects the object and the subject.
Let’s define a function to perform subtree matching:
def subtree_matcher(doc):
x = ''
y = ''
# iterate through all the tokens in the input sentence
for i,tok in enumerate(doc):
# extract subject
if tok.dep_.find("subjpass") == True:
y = tok.text
# extract object
if tok.dep_.endswith("obj") == True:
x = tok.text
return x,yIn this case, we just have to find all those sentences that:
- Have two entities, and
- The term “acquired” as the only ROOT in the sentence
We can then capture the subject and the object from the sentences. Let’s call the above function:
subtree_matcher(doc)
Output: (‘Salesforce’, ‘Tableau’)
Here, the subject is the acquirer and the object is the entity that is getting acquired. Let’s use the same function, subtree_matcher( ), to extract entities related by the same relation (“acquired”):
text_2 = "Careem, a ride hailing major in middle east, was acquired by Uber."
doc_2 = nlp(text_2)
subtree_matcher(doc_2)Output: (‘Uber’, ‘Careem’)
Did you see what happened here? This sentence had more words and punctuation marks but still, our logic worked and successfully extracted the related entities.
But wait – what if I change the sentence from passive to active voice? Will our logic still work?
text_3 = "Salesforce recently acquired Tableau."
doc_3 = nlp(text_3)
subtree_matcher(doc_3)Output: (‘Tableau’, ‘ ‘)
That’s not quite what we expected. The function has failed to capture ‘Salesforce’ and wrongly returned ‘Tableau’ as the acquirer.
So, what could go wrong? Let’s understand the dependency tree of this sentence:
for tok in doc_3:
print(tok.text, "-->",tok.dep_, "-->",tok.pos_)Output:
Salesforce --> nsubj --> PROPN recently --> advmod --> ADV acquired --> ROOT --> VERB Tableau --> dobj --> PROPN . --> punct --> PUNCT
It turns out that the grammatical functions (subject and object) of the terms ‘Salesforce’ and ‘Tableau’ have been interchanged in the active voice. However, now the dependency tag for the subject has changed to ‘nsubj’ from ‘nsubjpass’. This tag indicates that the sentence is in the active voice.
We can use this property to modify our subtree matching function. Given below is the new function for subtree matching:
def subtree_matcher(doc):
subjpass = 0
for i,tok in enumerate(doc):
# find dependency tag that contains the text "subjpass"
if tok.dep_.find("subjpass") == True:
subjpass = 1
x = ''
y = ''
# if subjpass == 1 then sentence is passive
if subjpass == 1:
for i,tok in enumerate(doc):
if tok.dep_.find("subjpass") == True:
y = tok.text
if tok.dep_.endswith("obj") == True:
x = tok.text
# if subjpass == 0 then sentence is not passive
else:
for i,tok in enumerate(doc):
if tok.dep_.endswith("subj") == True:
x = tok.text
if tok.dep_.endswith("obj") == True:
y = tok.text
return x,yLet’s try this new function on the active voice sentence:
new_subtree_matcher(doc_3)
Output: (‘Salesforce’, ‘Tableau’)
Great! The output is correct. Let’s pass the previous passive sentence to this function:
new_subtree_matcher(nlp("Tableau was recently acquired by Salesforce."))
Output: (‘Salesforce’, ‘Tableau’)
That’s exactly what we were looking for. We have made the function slightly more general. I would urge you to deep dive into the grammatical structure of different types of sentences and try to make this function more flexible.
End Notes
In this article, we learned about Information Extraction, the concept of relations and triples, and different methods for relation extraction. Personally, I really enjoyed doing research on this topic and am planning to write a few more articles on more advanced methods for information extraction.
Although we have covered a lot of ground, we have just scratched the surface of the field of Information Extraction. The next step is to use the techniques learned in this article on a real-world text dataset and see how effective these methods are.
Feel free to check the below article on extracting relations and triplets from Wikipedia text and build a Knowledge Graph.
- Knowledge Graph – A Powerful Data Science Technique to Mine Information from Text
If you’re new to the world of NLP, I highly recommend taking our popular course on the subject:
Data Scientist at Analytics Vidhya with multidisciplinary academic background. Experienced in machine learning, NLP, graphs & networks. Passionate about learning and applying data science to solve real world problems.






Congratulations, a very good post! One comment: I would say: "We can infer that “Gelidium” is a type of “red algae” just by looking at the structure of the sentence." instead of "We can infer that “Gelidium” is a part of “red algae” just by looking at the structure of the sentence." in the sentence up there. regards, Renato
Thanks Renato for pointing it out. I have made the necessary correction.
Thanks a lot for the post !!. I would like to ask one thing , in this example, we are getting an entity from the document. what kind of approach we should use if we have one document and want to classify information based on the entity. for example - we have a document in which one paragraph is related to cars and one is related to bike, I want the output to be like - Bike - "para" and Cars - "para"
great! Thank you for the information!