Introduction: –
Machine learning is fueling today’s technological marvels such as driver-less cars, space flight, image, and speech recognition. However, one Data Science professional would need a large volume of data to build a robust & reliable machine learning model for such business problems.

Data mining or gathering data is a very primitive step in the data science life cycle. As per business requirements, one may have to gather data from sources like SAP servers, logs, Databases, APIs, online repositories, or web.
Tools for web scraping like Selenium can scrape a large volume of data such as text and images in a relatively short time.
Table of Contents: –
- What is Web Scraping
- Why Web Scraping
- How Web Scraping is useful
- What is Selenium
- Setup & tools
- Implementation of Image Web Scrapping using Selenium Python
- Headless Chrome browser
- Putting it altogether
- End Notes
What is Web Scraping? :-
Web Scrapping also called “Crawling” or “Spidering” is the technique to gather data automatically from an online source usually from a website. While Web Scrapping is an easy way to get a large volume of data in a relatively short time frame, it adds stress to the server where the source is hosted.
This is also one of the main reasons why many websites don’t allow scraping all on their website. However, as long as it does not disrupt the primary function of the online source, it is fairly acceptable.
Why Web Scraping? –
There’s a large volume of data lying on the web that people can utilize to serve the business needs. So, one needs some tool or technique to gather this information from the web. And that’s where the concept of Web-Scrapping comes in to play.
How Web Scraping is useful? –
Web scraping can help us extract an enormous amount of data about customers, products, people, stock markets, etc.
One can utilize the data collected from a website such as e-commerce portal, Job portals, social media channels to understand customer’s buying patterns, employee attrition behavior, and customer’s sentiments and the list goes on.
Most popular libraries or frameworks that are used in Python for Web – Scrapping are BeautifulSoup, Scrappy & Selenium.
In this article, we’ll talk about Web-scrapping using Selenium in Python. And the cherry on top we’ll see how can we gather images from the web that you can use to build train data for your deep learning project.
What is Selenium: –
Selenium is an open-source web-based automation tool. Selenium primarily used for testing in the industry but It can also be used for web scraping. We’ll use the Chrome browser but you can try on any browser, It’s almost the same.

Now let us see how to use selenium for Web Scraping.
Setup & tools:-
- Installation:
- Install selenium using pip
pip install selenium
- Install selenium using conda
conda install -c conda-forge selenium
- Install selenium using pip
- Download Chrome Driver:
To download web drivers, you can choose any of below methods-- You can either directly download chrome driver from the below link-
https://chromedriver.chromium.org/downloads - Or, you can download it directly using below line of code-driver = webdriver.Chrome(ChromeDriverManager().install())
- You can either directly download chrome driver from the below link-
You can find complete documentation on selenium here. Documentation is very much self-explanatory so make sure to read it to leverage selenium with Python.
Following methods will help us to find elements in a Web-page (these methods will return a list):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
Now let’s write one Python code to scrape images from web.
Implementation of Image Web Scrapping using Selenium Python: –
Step1: – Import libraries
import os import selenium from selenium import webdriver import time from PIL import Image import io import requests from webdriver_manager.chrome import ChromeDriverManager from selenium.common.exceptions import ElementClickInterceptedException
Step 2: – Install Driver
#Install Driver driver = webdriver.Chrome(ChromeDriverManager().install())
Step 3: – Specify search URL
#Specify Search URL search_url=“https://www.google.com/search?q={q}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568" driver.get(search_url.format(q='Car'))
I’ve used this specific URL so you don’t get in trouble for using licensed or images with copyrights. Otherwise, you can use https://google.com also as a search URL.
Then we’re searching for Car in our Search URL Paste the link into to driver.get(“ Your Link Here ”) function and run the cell. This will open a new browser window for that link.
Step 4: – Scroll to the end of the page
#Scroll to the end of the page
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)#sleep_between_interactions
This line of code would help us to reach the end of the page. And then we’re giving sleep time of 5 seconds so we don’t run in problem, where we’re trying to read elements from the page, which is not yet loaded.
Step 5: – Locate the images to be scraped from the page
#Locate the images to be scraped from the current page
imgResults = driver.find_elements_by_xpath("//img[contains(@class,'Q4LuWd')]")
totalResults=len(imgResults)
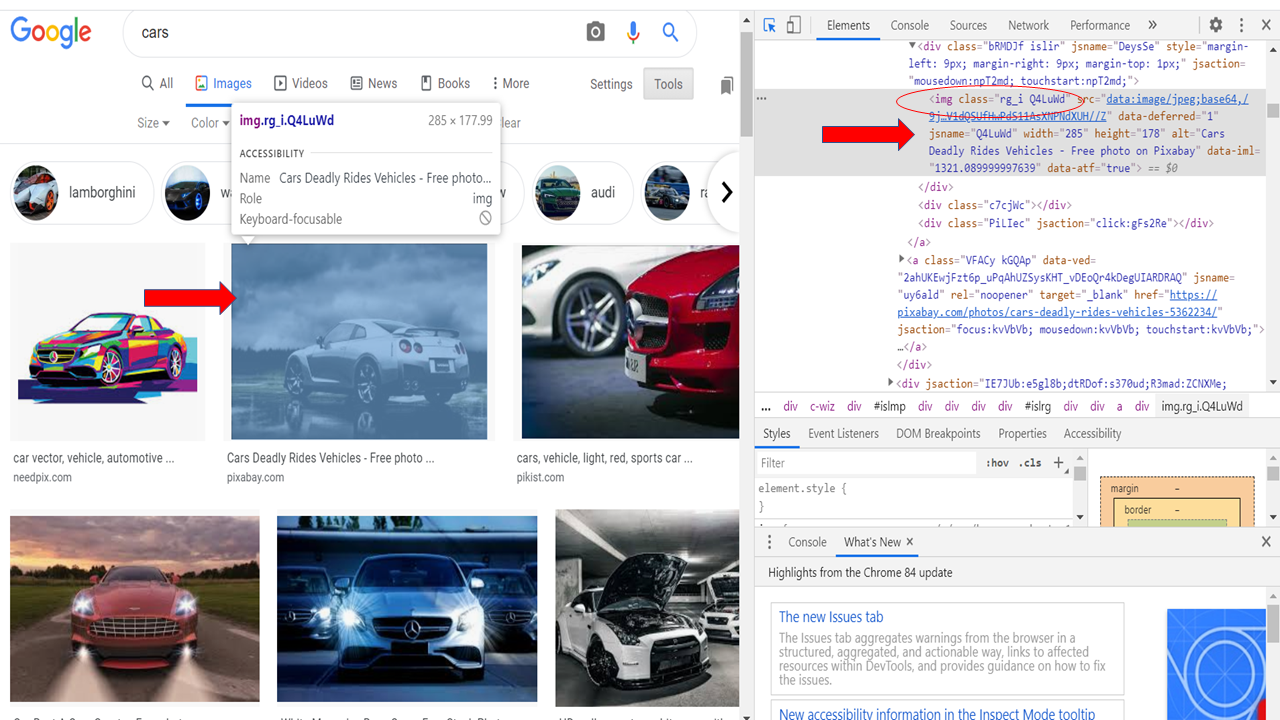
Now we’ll fetch all the image links present on that particular page. We will create a “list” to store those links. So, to do that go to the browser window, right-click on the page, and select ‘inspect element’ or enable the dev tools using Ctrl+Shift+I.
Now identify any attributes such as class, id, etc. Which is common across all these images.
In our case class =”‘Q4LuWd” is common across all these images.
Step 6: – Extract the corresponding link of each Image
As we can the images are shown on the page are still the thumbnails not the original image. So to download each image, we need to click each thumbnail and extract relevant information corresponding to that image.
#Click on each Image to extract its corresponding link to download
img_urls = set()
for i in range(0,len(imgResults)):
img=imgResults[i]
try:
img.click()
time.sleep(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
for actual_image in actual_images:
if actual_image.get_attribute('src') and 'https' in actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
except ElementClickInterceptedException or ElementNotInteractableException as err:
print(err)
So, in the above snippet of code, we’re performing the following tasks-
- Iterate through each thumbnail and then click it.
- Make our browser sleep for 2 seconds (:P).
- Find the unique HTML tag corresponding to that image to locate it on page
- We still get more than one result for a particular image. But all we’re interested in the link for that image to download.
- So, we iterate through each result for that image and extract ‘src’ attribute of it and then see whether “https” is present in the ‘src’ or not. Since typically weblink starts with ‘https’.
Step 7: – Download & save each image in the Destination directory
os.chdir('C:/Qurantine/Blog/WebScrapping/Dataset1')
baseDir=os.getcwd()
for i, url in enumerate(img_urls):
file_name = f"{i:150}.jpg"
try:
image_content = requests.get(url).content
except Exception as e:
print(f"ERROR - COULD NOT DOWNLOAD {url} - {e}")
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert('RGB')
file_path = os.path.join(baseDir, file_name)
with open(file_path, 'wb') as f:
image.save(f, "JPEG", quality=85)
print(f"SAVED - {url} - AT: {file_path}")
except Exception as e:
print(f"ERROR - COULD NOT SAVE {url} - {e}")
Now finally you have extracted the image for your project 😀
Note: – Once you have written proper code then the browser is not important you can collect data without browser, which is called headless browser window, hence replace the following code with the previous one.
Headless Chrome browser
#Headless chrome browser from selenium import webdriver opts = webdriver.ChromeOptions() opts.headless =True driver =webdriver.Chrome(ChromeDriverManager().install())
In this case, the browser will not run in the background which is very helpful while deploying a solution in production.
Let’s put all this code in a function to make it more organizable and Implement the same idea to download 100 images for each category (e.g. Cars, Horses).
And this time we’d write our code using the idea of headless chrome.
Putting it all together:
Step 1 – Import all required libraries
import os
import selenium
from selenium import webdriver
import time
from PIL import Image
import io
import requests
from webdriver_manager.chrome import ChromeDriverManager
os.chdir('C:/Qurantine/Blog/WebScrapping')
Step 2 – Install Chrome Driver
#Install driver opts=webdriver.ChromeOptions() opts.headless=True driver = webdriver.Chrome(ChromeDriverManager().install() ,options=opts)
In this step, we’re installing a Chrome driver and using a headless browser for web scraping.
Step 3 – Specify search URL
search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568" driver.get(search_url.format(q='Car'))
I’ve used this specific URL to scrape copyright-free images.
Step 4 – Write a function to take the cursor to the end of the page
def scroll_to_end(driver):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)#sleep_between_interactions
This snippet of code will scroll down the page
Step5. Write a function to get URL of each Image
#no license issues def getImageUrls(name,totalImgs,driver): search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568" driver.get(search_url.format(q=name)) img_urls = set() img_count = 0 results_start = 0 while(img_count<totalImgs): #Extract actual images now scroll_to_end(driver) thumbnail_results = driver.find_elements_by_xpath("//img[contains(@class,'Q4LuWd')]") totalResults=len(thumbnail_results) print(f"Found: {totalResults} search results. Extracting links from{results_start}:{totalResults}") for img in thumbnail_results[results_start:totalResults]: img.click() time.sleep(2) actual_images = driver.find_elements_by_css_selector('img.n3VNCb') for actual_image in actual_images: if actual_image.get_attribute('src') and 'https' in actual_image.get_attribute('src'): img_urls.add(actual_image.get_attribute('src')) img_count=len(img_urls) if img_count >= totalImgs: print(f"Found: {img_count} image links") break else: print("Found:", img_count, "looking for more image links ...") load_more_button = driver.find_element_by_css_selector(".mye4qd") driver.execute_script("document.querySelector('.mye4qd').click();") results_start = len(thumbnail_results) return img_urls
This function would return a list of URLs for each category (e.g. Cars, horses, etc.)
Step 6: Write a function to download each Image
def downloadImages(folder_path,file_name,url):
try:
image_content = requests.get(url).content
except Exception as e:
print(f"ERROR - COULD NOT DOWNLOAD {url} - {e}")
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert('RGB')
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'wb') as f:
image.save(f, "JPEG", quality=85)
print(f"SAVED - {url} - AT: {file_path}")
except Exception as e:
print(f"ERROR - COULD NOT SAVE {url} - {e}")
This snippet of code will download the image from each URL.
Step7: – Write a function to save each Image in the Destination directory
def saveInDestFolder(searchNames,destDir,totalImgs,driver):
for name in list(searchNames):
path=os.path.join(destDir,name)
if not os.path.isdir(path):
os.mkdir(path)
print('Current Path',path)
totalLinks=getImageUrls(name,totalImgs,driver)
print('totalLinks',totalLinks)
if totalLinks is None:
print('images not found for :',name)
continue
else:
for i, link in enumerate(totalLinks):
file_name = f"{i:150}.jpg"
downloadImages(path,file_name,link)
searchNames=['Car','horses']
destDir=f'./Dataset2/'
totalImgs=5
saveInDestFolder(searchNames,destDir,totalImgs,driver)
This snippet of code will save each image in the destination directory.
End Notes
I’ve tried my bit to explain Web Scraping using Selenium with Python as simple as possible. Please feel free to comment on your queries. I’ll be more than happy to answer them.
You can clone my Github repository to download the whole code & data, click here!!
About the Author

Praveen Kumar Anwla
I’ve been working as a Data Scientist with product-based and Big 4 Audit firms for almost 5 years now. I have been working on various NLP, Machine learning & cutting edge deep learning frameworks to solve business problems. Please feel free to check out my personal blog, where I cover topics from Machine learning – AI, Chatbots to Visualization tools ( Tableau, QlikView, etc.) & various cloud platforms like Azure, IBM & AWS cloud.








It has fully emerged to crown Singapore's southern shores and undoubtedly placed her on the global map of residential landmarks. I still scored the more points than I ever have in a season for GS. I think you would be hard pressed to find somebody with the same consistency I have had over the years so I am happy with that.
Took me time to read all the comments, but I really enjoyed the article. It proved to be Very helpful to me and I am sure to all the commenters here! It’s always nice when you can not only be informed, but also entertained!