This article was published as a part of the Data Science Blogathon.
“Looking for a needle in a haystack”. These lines portray the importance of quality data in the real world. What about the tons of data that are easily available but the quality data is like gold rare to find.
INTRODUCTION
Gathering information across the web is web scraping, also known as Web Data Extraction & Web Harvesting. Nowadays data is like oxygen for startups & freelancers who want to start a business or a project in any domain. Suppose you want to find the price of a product on an eCommerce website. It’s easy to find but now let’s say you have to do this exercise for thousands of products across multiple eCommerce websites. Doing it manually; not a good option at all.
Get to know the Tool
JavaScript is a popular programming language and it runs in any web browser.
Node JS is an interpreter and provides an environment for JavaScript with some specific useful libraries.
In short, Node JS adds several functionality & features to JavaScript in terms of libraries & make it more powerful.

Hands-On-Session
Let’s get to understand web scraping using Node JS with an example. Suppose you want to analyze the price fluctuations of some products on an eCommerce website. Now, you have to list out all the possible factors of the cause & cross-check it with each product. Similarly, when you want to scrape data, then you have to list out parent HTML tags & check respective child HTML tag to extract the data by repeating this activity.
Steps Required for Web Scraping
- Creating the package.json file
- Install & Call the required libraries
- Select the Website & Data needed to Scrape
- Set the URL & Check the Response Code
- Inspect & Find the Proper HTML tags
- Include the HTML tags in our Code
- Cross-check the Scraped Data
I’m using Visual Studio to run this task.
Step 1- Creating the package.json file
To create a package.json file, I need to run npm init and give a few details as needed in the below screenshot.
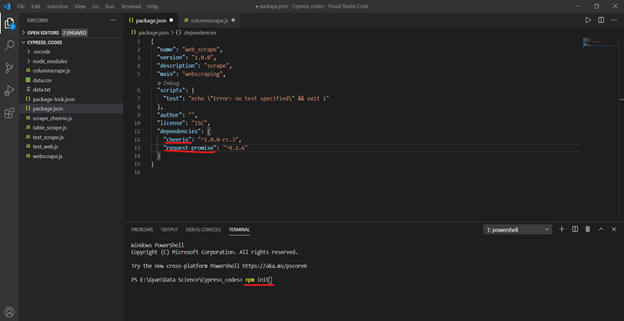
Create package.json
Step 2- Install & Call the required libraries
Need to run the below codes to install these libraries.

Install Libraries
Once the libraries are properly installed then you will see these messages are getting displayed.

logs after packages get installed
Call the required libraries:

Call the library
Step 3- Select the Website & Data needed to Scrape.
I picked this website “https://www.bullion-rates.com/gold/INR/2007-1-history.htm” and want to scrape data of gold rates along with dates.
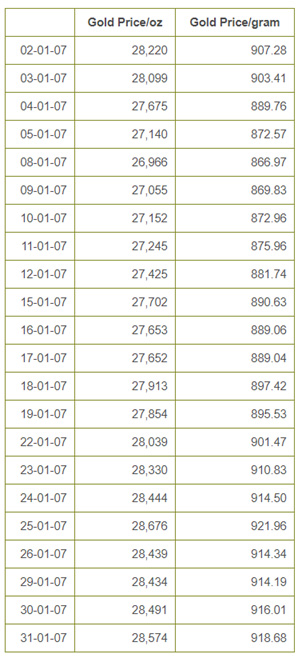
Data we want to scrape
Step 4- Set the URL & Check the Response Code
Node JS code looks like this to pass the URL & check the response code.

Passing URL & Getting Response Code
Step 5- Inspect & Find the Proper HTML tags
It’s quite easy to find the proper HTML tags in which your data is present.
To see the HTML tags; right-click and select the inspect option.
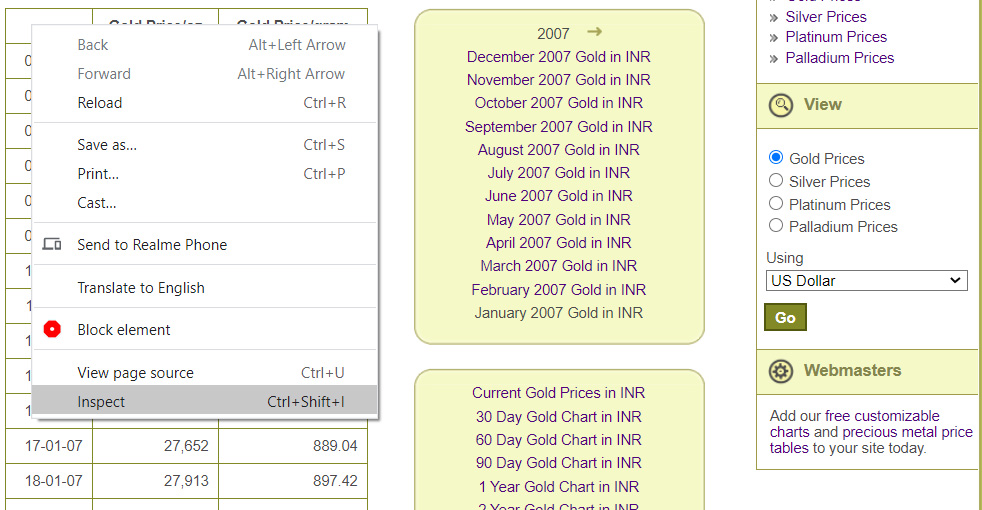
Inspecting the HTML Tags
Select proper HTML Tags:-
If you noticed there are three columns in our table, so our HTML tag for table row would be “HeaderRow” & all the column names are present with tag “th” (Table Header).
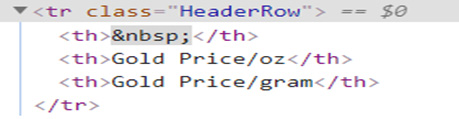
And for each table row (“tr”) our data resides in “DataRow” HTML tag
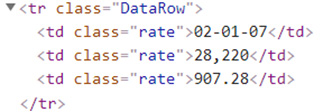
Now, I need to get all HTML tags to reside under “HeaderRow” & need to find all the “th” HTML tags & finally iterate through “DataRow” HTML tag to get all the data within it.
Step 6- Include the HTML tags in our Code
After including the HTML tags, our code will be:-
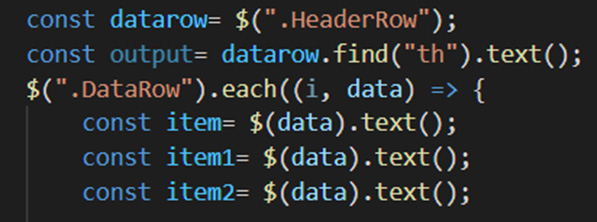
Code Snippet
Step 7- Cross-check the Scraped Data
Print the Data, so the code for this is like:-

Our Scraped Data
If you go to a more granular level of HTML Tags & iterate them accordingly, you will get more precise data.
That’s all about web scraping & how to get rare quality data like gold.
Conclusion
I tried to explain Web Scraping using Node JS in a precise way. Hopefully, this will help you.
Find full code on
If you have any questions about the code or web scraping in general, reach out to me on
We will meet again with something new.
Till then,
Happy Coding..!
Data Manipulator | Data Modeller | Data Scientist | Tech Writer | Lifelong learner | Analysising the world through Technology and Data | I don’t write to impress. I write to inform, entertain, inspire. | It's time to Review, Consume and Create. Cut the mustard for your success. |
Let’s connect! | https://www.linkedin.com/in/gyan-vardhan-data-scientist/ | Thanks for your time!





