This article was published as a part of the Data Science Blogathon.
Introduction
The field of Data Science is growing by leaps and bounds in every industry. Each organization is keen on making decisions that are driven by the data generated. A report by one of the employment websites indicates a 29% increase in the demand for data scientists in a year. However, the increase in skilled resources in data science is not growing as expected and the growth is only by 14% only.
Even in today’s digital age, Data Science still requires a lot of manual work. Storing the data generated, cleaning it, exploratory analysis, visualizing the data, and finally fitting a model to it to enable decision making. The manual work can be automated to some extent and thus the dawn of automation in Data Science.
The life cycle of a data set in the data science project is as below
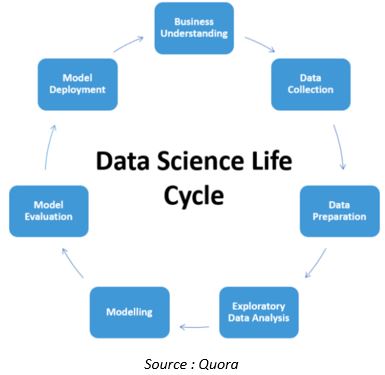
Except for Business understanding and model deployment, nearly every aspect of the Data Science pipeline is in the process of becoming automated. Let us look at some of the developments in this area.
Automatic Data Collection
The data being the cornerstone of every analysis, we need to invest a considerable amount of our time in understanding it. Incomplete data could lead to unreliable or biased models and if the business were to make decisions on these models, needless to say, it would lead to disasters one could not even imagine.
Dataprep is an open-source python library that allows us to prepare the data with just a few lines of code. Dataprep allows us to visualize any missing data in our dataset, finding out missing data is mandatory while preparing the data so that we can replace it with useful data accordingly
Below is the syntax for Installing Dataprep library using pip install
pip install -U dataprep
The connector is a component in DataPrep that aims to simplify data collection from Web APIs by providing a standard set of operations. It is an open-source API wrapper that speeds up development by making calls to multiple APIs. Streamlines call to multiple APIs through one intuitive library.
Below is the syntax for Installing Dataprep.connector
from dataprep.connector import *
Let’s look at an example of using connect to collect data. With Connector, you can collect data from one of the top recommendations’ sites online: Yelp.
from dataprep.connector import connect
# use the connect function with the "yelp" string and Yelp access token, both specified as parameters. This action allows us to create a Connector to the Yelp Web API:
yelp_connector = connect("yelp", _auth={"access_token":"<Your Yelp access token>"})
yelp_connector.info()# gives information on using Connector over Web API
Output

in this example, there is only one endpoint available for Yelp: businesses. However, if you want to connect to a different Yelp endpoint, you can build a new configuration file.
yelp_connector.show_schema(“business”)# explore the “business” endpoint schema according to its configuration file definition
Auto-Data Cleaning
Data cleaning is one of the most tedious tasks for a data scientist, it takes up their precious time. It has been an exclusively researched topic over the past few years. Both startups and large and established companies offer automation and tools for data cleaning.
DataPrep.Clean aims to provide a large number of functions with a unified interface for cleaning and standardizing data of various semantic types in Pandas.
DataPrep.Clean contains simple functions designed for cleaning and validating data in a DataFrame. Below are the highlights of DataPrep.Clean library.
The following code demonstrates how to use DataPrep.Clean, We will use the dataset waste_hauler from DataPrep’s internal dataset repository.
from dataprep.clean import *
from dataprep.datasets import load_dataset
df = load_dataset('waste_hauler')
df.head()
Output

df = clean_headers(df)#converts the headers into snake case print(df.columns)
There are many more functions in dataprep.clean as below
df = clean_phone(df, 'phone')#To standardize their formats, we can use the function clean_phone() df = clean_address(df, 'local_address')#to standardize the inconsistencies in address
Auto Data Exploration:
Data exploration refers to those preliminary step in data analysis and model building in which data analysts uses statistical techniques to describe the characteristics of the dataset such as size, quality, quantity and accuracy, and summarize it to better understand the nature of the data.
DataPrep.EDA is the fastest and the easiest EDA tool in Python. It allows data scientists to understand Pandas with a few lines of code in seconds.
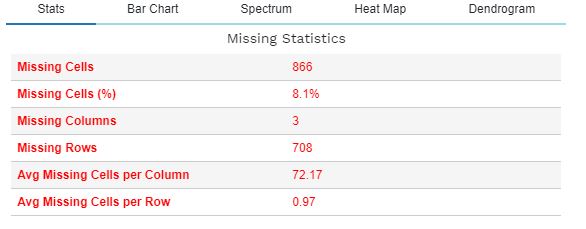
The function plot_missing() enables a thorough analysis of the missing values and their impact on the dataset. The following describes the functionality of plot_missing() for a given data frame df.
from dataprep.eda import plot_missing
from dataprep.datasets import load_dataset
df = load_dataset("titanic")
plot_missing(df)
There are many more functions in dataprep.eda as below
plot_correlation() #generates correlation matrices and correlation coefficient plot(df) #plots a histogram for each numerical column, a bar chart for each categorical column, and computes dataset statistics.
It allows us to create detailed reports from a Pandas/Dask DataFrame with the create_report function. DataPrep.EDA is 100 times faster than Pandas-based profiling tools, generates interactive visualizations in a report which makes the report look more appealing, and also supports big data with millions of rows working with which was not easy with the traditional pandas library.
Auto ML Modelling:
The next and the most sought-after step in the data science life cycle is model fitting. Automated Machine Learning (AutoML) is currently the talk of the town within the Data Science community. Auto ML provides us with the tools that help us to find the appropriate machine learning model for the given dataset with minimum user involvement.
LightAutoML is one of the python libraries designed to perform various tasks like binary/multiclass classification and regression on tabular datasets, which contain different types of data like numeric, categorical, texts, and so on.
Another example is Auto-Sklearn. It is a python library used to automatically discover top-performing models for regression tasks. It uses machine learning models from the scikit-learn machine learning library.
The benefit of Auto-Sklearn is that, in addition to discovering the data preparation and model that performs for a dataset, it also is able to learn from models that performed well on similar datasets and are able to automatically create an ensemble of top-performing models discovered as part of the optimization process.
In the below example, we will use Auto-Sklearn to discover a model for the sonar dataset. The AutoSklearnClassifier is configured to run for 5 minutes with 8 cores and limit each model evaluation to 30 seconds.
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from autosklearn.classification import AutoSklearnClassifier
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/sonar.csv'
dataframe = read_csv(url, header=None)
# split into input and output elements
data = dataframe.values
X, y = data[:, :-1], data[:, -1]
# minimally prepare dataset
X = X.astype('float32')
y = LabelEncoder().fit_transform(y.astype('str'))
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1)
# define search
model = AutoSklearnClassifier(time_left_for_this_task=5*60, per_run_time_limit=30, n_jobs=8)
model.fit(X_train, y_train)#perform the search
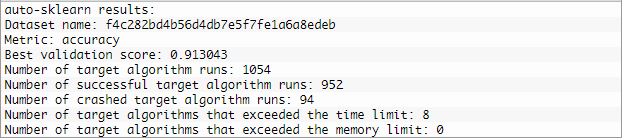
print(model.sprint_statistics())#summarize
Output
Model Evaluation:
Once the model is built, it’s time to check the performance of it or rather the accuracy with which the model is working. If the accuracy is not up to the mark, the model is not considered to be the right fit for that dataset.

As in the case of the above example, we define an AutoSklearnClassifier class to control the search and configure it to run for a specified time say 2 minutes and discard any model that takes more than 30 seconds to evaluate. At the end of these 2 minutes, we can overview the statistics of the search and evaluate the best-performing model.
# evaluate best model
y_hat = model.predict(X_test)
acc = accuracy_score(y_test, y_hat)
print("Accuracy: %.2f" % acc)
The classification accuracy of 81.2 percent was achieved, which is reasonably skillful.
Limitations

In spite of automation being on the rise in recent times, there are definitely some caveats/disadvantages to it. Most importantly AutoML needs more resources otherwise it will take more time to execute. The automatic machine learning processing of unstructured and semi-structured data is technically difficult.
Often, realistic problems are a combination of multiple objectives, as such, there is the need to make subtle differences between decision-making and cost which requires the intervention of a data scientist. There will always be the need for manual checkpoints where human beings can intervene and sign off on parts of the automated process. This can add the accountability needed and help with the regulation and governance. Hence, the final sign-off would always be given by the data scientist.
References
https://machinelearningmastery.co
The media shown in this article on Automation in Data Science are not owned by Analytics Vidhya and is used at the Author’s discretion.






Great post! I found the tips on automating data cleaning especially helpful. It’s amazing how much time we can save with the right tools and processes in place. I'm excited to start implementing some of these strategies in my own projects!