This article was published as a part of the Data Science Blogathon.
Introduction
With the ever-increasing data on the web over years, Recommender Systems (RS) have come into the picture ranging from e-commerce to e-resource. Today, big giants like Netflix, Amazon, YouTube, etc. use RS to help users find information of use to improve their experience and thus gain user’s confidence.
To provide relevant information to a user from the deluge of data available over the web and at the same time help companies make a profit, a list of interesting and relevant items is recommended to a user-generated by recommendation systems. In other words, RS is a tool that predicts items, users may like to consume in near future.
In this blog, we’ll see how to build a simple movie recommendation system using Keras in python.
We will use the movies dataset which consists of 100K ratings provided by 943 users across 1682 movies. For this blog, you will need to extract the u.data file from the downloaded folder.
Loading libraries
We are loading all libraries of use at once for comprehensibility.
import numpy as np import pandas as pd import os import warnings
from keras.models import load_model
from sklearn.model_selection import train_test_split
from keras.layers import Input, Embedding, Flatten, Dot, Dense, Concatenate
from keras.models import Model
warnings.filterwarnings('ignore')
%matplotlib inline
Pandas is used for loading, reading, and working on the dataset.
Numpy is used for working with arrays and matrices.
Keras is an open-source library used to work with an artificial neural network. It has minimized human efforts in developing neural networks.
Loading Data
As coding is done in google colab, we’ll first have to upload the u.data file using the statements below and then read the dataset using Pandas library.
from google.colab import files uploaded = files.upload()
header = ['user_id','item_id','rating','timestamp']
dataset = pd.read_csv('u.data',sep = 't',names = header)
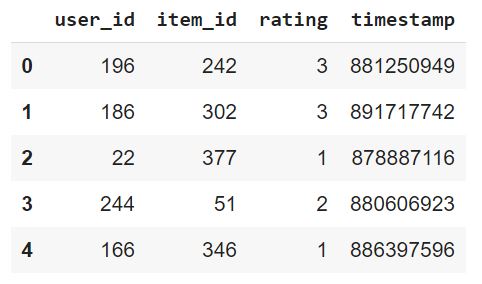
dataset.head()
The dataset.head() prints the first 5 rows of the dataset as shown below:
Here, the first row represents the rating given by user 196 to movie 242 at timestamp 881250949.
Splitting dataset into train-test
Once we have read the dataset, the next step is to split it into a test and train dataset. Here, 20% of the dataset is considered as a test, and the rest 80% is considered as a training dataset. Training neural network requires a large amount of data for better accuracy.
train, test = train_test_split(dataset, test_size=0.2, random_state=42)
Create neural network model
Keras libraries have made it easy to create a model specific to a problem. The model consists of 3 layers:
1. Input Layer
This layer takes the movie and user vector as input.
2. Embedding Layer
It consists of embedding for both users and movies. These are randomly initialized values that are then updated during training. They resemble latent factors in matrix factorization. The motive is to get the best values of embeddings in order to minimize the error between actual and predicted values.
3. Output Layer
This layer gives the predicted values. There can be one or more neurons in the output layer. In our case, there is a single neuron as output will be predicted value of movie by a user.
# creating book embedding path
movie_input = Input(shape=[1], name="Movie-Input")
movie_embedding = Embedding(n_items+1, 5, name="Movie-Embedding")(movie_input)
movie_vec = Flatten(name="Flatten-Books")(movie_embedding)
# creating user embedding path
user_input = Input(shape=[1], name="User-Input")
user_embedding = Embedding(n_users+1, 5, name="User-Embedding")(user_input)
user_vec = Flatten(name="Flatten-Users")(user_embedding)
# concatenate features
conc = Concatenate()([movie_vec, user_vec])
# add fully-connected-layers
fc1 = Dense(128, activation='relu')(conc)
fc2 = Dense(32, activation='relu')(fc1)
out = Dense(1)(fc2)
# Create model and compile it
model2 = Model([user_input, movie_input], out)
model2.compile('adam', 'mean_squared_error')
To sum up the above code, user and book vectors are first created which are then concatenated. These concatenated vectors are passed to a neural networks consisting of 2 hidden layers. The first hidden layer consists of 128 neurons while the second consists of 32 neurons. The output layer represented by out consists of 1 neuron which gives predicted value provided by the user to the movie.
Train Model
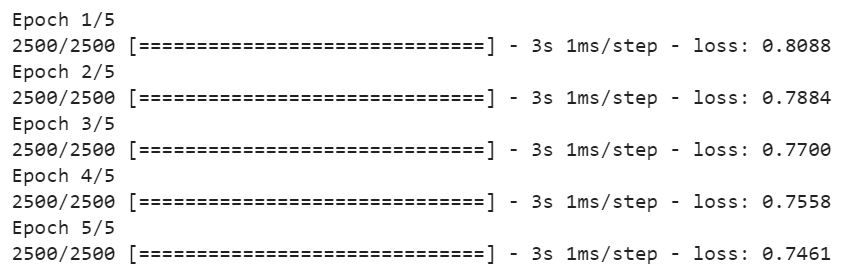
Once we have created the model, the next step is to train that model on the training dataset. Here, we have taken 5 epochs which can be increased to make the model more accurate. The motive is to update the embedding vector in order to get the predicted value close to the actual value. Here, the loss represents the error between predicted and actual rating over the entire training dataset.
history = model2.fit([train.user_id, train.item_id], train.rating, epochs=5, verbose=1)
Make Predictions
Now, we can generate predicted values for the test dataset, i.e. given user_id and movie_id, predicted rating will be computed using the model built. Here, we have taken the first 10 rows from the test dataset and predicted values for corresponding user_id and movie_id. In general, we can predict values for the entire test dataset and then can recommend movies having the highest predicted rating corresponding to a particular user.
predictions = model2.predict([test.user_id.head(10), test.item_id.head(10)]) [print(predictions[i], test.rating.iloc[i]) for i in range(0,10)]
The output of above code:

These are predicted values along with the actual values.
Open research questions
1. Data Sparsity
Recommendations are based on user’s history in which ratings provided by users to items play an important role in understanding the taste of users. However, in real case scenarios, users rate very few items consumed by them leading to data sparsity problems which affect the accuracy of the recommendation process. The more model knows about the user, the more accurate recommendations can be made. The movie lens dataset we have considered is 93.7% sparse.
2. Cold-start Problem
What if a user is new to the system and does not have any rating history. How to make recommendations to users in such a case? This is still an open research question.
3. Overspecialization
If we search for cooking recipes on YouTube, our homepage gets flooded with cooking recipes leading to overspecialization. There should exist some diversity in items displayed on the homepage enabling users to explore the variety of items(videos in the case of YouTube).
Conclusion
With the deluge of data over the web, recommendation systems have become an essential part of every big giant. Amazon is one such big giant that uses a recommender system to suggest products to customers from a large volume of products available. Another such big giant is Netflix. Different companies make use of different methods to suggest products to customers.
Today, the efficiency of neural networks has forced their usage in this field. One such basic neural network-based movie recommendation system has been discussed in this article. There are a lot of things that can be tried to get better predictions, increasing the number of epochs is one such way. Further, data sparsity, cold-start, and overspecialization are some of the open research questions in the field of recommendation systems. Probably, this blog is a good start for the beginners trying their hand at movie recommendation systems using Keras.
Connect with me on LinkedIn
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.



Hello it was an amazing blog but i find a very small glitch in it. The read . Data file should be Data=pd.read_csv("u.data", sep="\t", names=header)