This article was published as a part of the Data Science Blogathon
Have you ever thought of generating questions from the SRT files of Movies?

I don’t know if we can use this but it is pretty exciting when I came to know as a beginner that we can do that.
What is SRT?
In simple terms, the subtitles you see in Amazon Prime, Netflix, Hotstar, HBO, etc are saved in a text file with (.srt) extension with timestamps.
The timestamp is formatted like therefore with the milliseconds rounded to 3 decimal points:
Hours:Minutes: Seconds, Milliseconds
The timeframe is formatted like therefore with associate arrow denoting range:
First Timestamp –> Second Timestamp
The arrow should incorporate 2 hyphens and a right-pointing angle bracket (also referred to as the greater-than sign or carrot).
For example, you can see below from the movie “The Fault in Our Stars”.
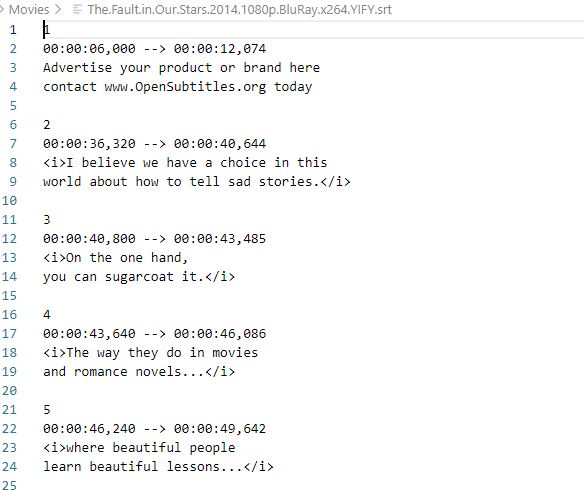
Data preprocessing of SRT
You can do the preprocessing of data with the help of ReGex but I’m using Pysrt.
import pysrt
subs = pysrt.open("/content/The.Fault.in.Our.Stars.2014.1080p.BluRay.x264.YIFY.srt")
text_file = open("sample.txt", "wt")
for sub in subs:
text_file.write(sub.text)
print(sub.text)
print()
text_file.close()
Libraries used
- Punkt Sentence Tokenizer
This tokenizer divides a text into a listing of sentences, by exploiting the associate unattended formula to create a model for abbreviation words, collocations, and words that begin sentences. It should be trained on an outsized assortment of plaintext within the target language before it may be used.
!python -m nltk.downloader punkt
- Transformers
Transformer models well and really revolutionized the language process as we all know. After they were 1st introduced poor multiple informatics records and have become the state of the art formula.
By far the most important paper that transformed the NLP landscape is the “Attention is all you need” paper. Here we have used T5 Transformer.
The existing models at that time for sequence and NLP tasks mostly involved RNNs. The problem with these networks was that they couldn’t capture long-term dependencies.
LSTM- a variant of RNNs were capable of capturing the dependencies but it is also limited.
Long Short Term Memory networks – typically simply referred to as “LSTMs” – ar a special reasonably RNN, capable of learning semipermanent dependencies. they’re expressly designed to avoid the semipermanent dependency drawback. basic cognitive process info for long periods of your time is much their default behavior, not one thing they struggle to find out.
So, the main inspiration behind the transformer was to get rid of this recurrence and still end up capturing almost all the dependencies, to be precise global dependencies.
Transformers provides thousands of pre-trained models to perform tasks on texts like classification, info extraction, question responsive, account, translation, text generation, and a lot of in over one hundred languages. It aims to create the newest informatics easier to use for everybody.
!pip install -U transformers==3.0.0 !git clone https://github.com/patil-suraj/question_generation.git
Main Library:https://github.com/patil-suraj/question_generation
More on T5
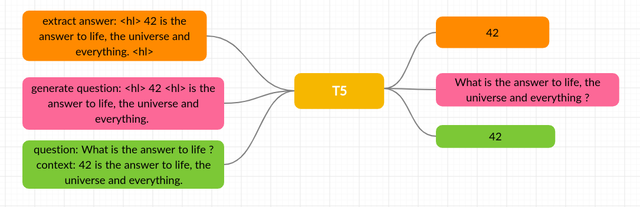
As the name implies, T5 could be a text-to-text model, that allows the North American nation to coach it on discretional tasks involving a matter of input and output, an enormous style of NLP tasks is solid during this format, together with translation, account, and even classification and regression tasks.
Each task we tend to think about uses text as input to the model, which is trained to get some target text. Here the set of tasks together with translation green, linguistic acceptableness red, sentence similarity yellow, and document account blue.

If you want to try code and learn more about this, there’s the colab notebook.
Final Output: Questions
T5 for question-generation
This is a t5-base model trained for end-to-end question generation tasks. Simply input the text and the model will generate multiple questions.
NLP Pipeline
When I call NLP on the text, spaCy first tokenizes the text and creates a Doc object. The following documents are processed in several stages. This is also referred to as the processing pipeline.

Sentence Segmentation
The best way to progress when there are paragraphs to access is to progress one sentence at a time. Reduce complexity Simplify the process and get the most accurate results. Computers don’t understand the language as humans do, but when accessed in the right way, they can always do a lot.
Word Tokenization
Tokenization is the process of breaking an entire syntax, sentence, paragraph, or document into smaller units such as individual words or terms. And this small unit is known as each token.
These tokens can be words, numbers, or punctuation marks. Along with word boundaries-word endpoints. Or the beginning of the next word. This is also the first step in morphological analysis and polishing. This process is very important because the meaning of the
words can be easily interpreted by analyzing the words in the text.
POS Predictor for each token
Part of the speech needs to consider each token. Then figure out the rest of the speech, such as whether the token belongs to a noun, pronoun, verb, adjective, etc.
Text Lemmatization
English is also one of the languages where basic words in a variety of formats are available. When working on a computer, if there are multiple words in a sentence with the same basic word, you will notice that those words are used in the same concept. This process is called polishing by NLP.
Identifying Stop Words
When the polishing process is complete, the next step is to identify each word in the sentence. There are a lot of filler words that don’t have meaning in English but weaken the sentence. They appear more often in the statement, so it is always better to omit them.
Most data scientists delete these words before further analysis. There is no standard rule for stopwords, so the basic algorithm to check the list of known stopwords and identify stopwords.
Dependency analysis
The analysis is divided into three main categories. And each class is different from the other classes. These voice tags, dependency parsing, and configuration are part of the old syntax.
Part of speech (POS) is mainly used to specify other labels. We call it a POS tag. This tag refers to some of the words in a sentence. On the other hand, for dependency expressions: Analyze the grammatical structure of the sentence. It is based on the word dependencies of the sentence.
For more details see this repo.
from pipelines import pipeline
nlp = pipeline("e2e-qg")
nlp(text1)
Output:
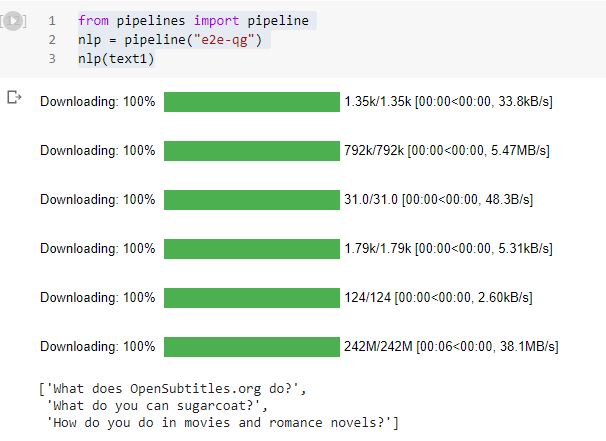
This same process can also be used to generate answers and more questions.
Hope you have really enjoyed the Article. This just the High-level View. Keep Learning..!
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
I have 4+ years of working experience working with Big Data Analytics and the Cloud. Worked with different domains like Capital Markets, Insurance, FinTech, MedTech/Healthcare. Have designed scalable & optimized data pipelines for mostly Batch Processing Utilizing Cloud.
✔️ Building data warehouses /Data lakes using modern cloud platforms and technologies.
✔️ Implementing and automating data pipelines, ETL processes.
✔️ Data Cleaning, Processing, and Standardization (Machine Learning and NLP).
✔️ Data Migration (Heterogenous and Homogenous)
Some of the technologies I most frequently work with are:
👨💻 Programming: Python, PySpark, SQL, Pandas
☁️ Cloud: AWS
🔰 Databases: Redshift, RDS, PostgreSQL, MySQL, S3, Cloud Data Store
⚙️ Data Integration/ETL: AWS Glue & EMR, Airflow
📊 BI/Visualization: Tableau, Excel
🤖 Big Data - Hadoop, Hive, Spark, NLP, Jupyter Notebook, Data Structures
I love to adapt to new technologies to solve different business problems. I want to work with Petabytes of real-time/Streaming/Batch data and build good platforms. Looking forward to exploring.





