This article was published as a part of the Data Science Blogathon
“Generative Adversarial Networks is the most interesting idea in the last ten years in Machine Learning ”— Yann LeCun
Introduction
In my last article, we had a look at what GANs really are, now its time to dive deeper and get the mathematical and practical understanding of it, but before that, if you want to take a look at the basics of GANs you can go ahead with the following link:
https://www.analyticsvidhya.com/blog/2021/04/lets-talk-about-gans/
Most of the tech giants (like Google, Microsoft, Amazon, etc.) are grievously working on applying GANs to practical use, some of these use cases are:
- Adobe —Using GANs for their next-generation Photoshop.
- Google — Using GANs for Text Generation.
- IBM — Using GANs for Data Augmentation (to generate synthetic images for training their classification models).
- Snap Chat/ TikTok — For creating various Image Filters (that you might have already seen).
- Disney — Using GANs for Super Resolution (improving video quality) for their movies.
Something that is special with GANs is that these companies are depending on it for their future don’t you think so?
So what’s stopping you to get the knowledge of this epic technology? I will answer it, nothing, you just need a head start and this article would do so. Let’s first discuss the math behind Generator and Discriminator.
Mathematical Functioning of Discriminator:
The sole purpose of the Discriminator is to classify real and fake images. For classification, it uses a traditional Convolutional Neural Network (CNN) with a specified cost function. The training process of Discriminator works as follows:
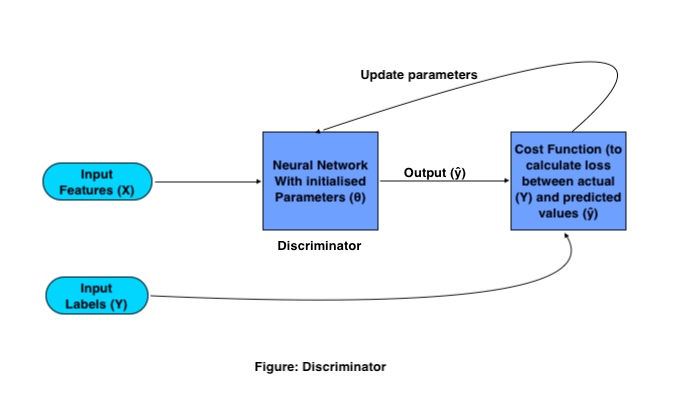
Where X and Y are input features and labels respectively, the output is represented using (ŷ) and network parameters are represented by (θ).
Training GANs need some set of training images and their respective labels, these images as input feature goes to CNN, having a set of initialized parameters. This CNN generates output by multiplying the weight matrix (W) with the input features (X) and adding a Bias (B) in it and converting it to a nonlinear matrix by passing it to an activation function.
This output is referred to as predicted output, then the loss is calculated based on which weights parameters are adjusted in the network in order to minimize the loss.
Mathematical Functioning of Generator:
The Generator’s goal is to generate a fake image from the given distribution (set of images), it does so with the following procedure:
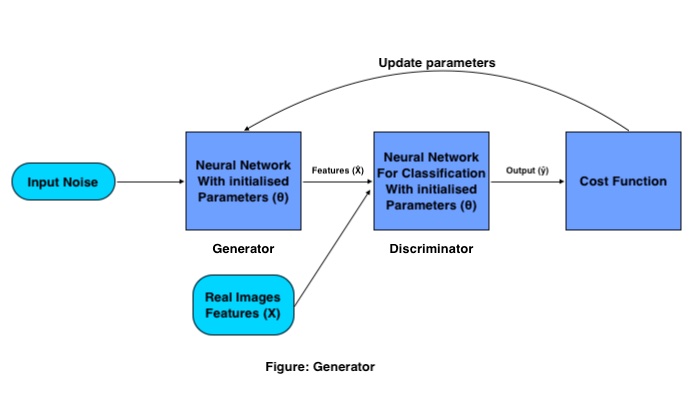
A set of input vectors (random noise) is passed through the Generator’s Neural Network which creates a whole new image by multiplying the Generator weight matrix with the input noise.
This generated image works as input for the Discriminator which is trained for classifying fake and real images. Then the loss is calculated for the generated images, based on which parameters are updated for the generator until we get good accuracy.
Once we are satisfied with the accuracy of the Generator we save the weights of the Generator and remove the Discriminator from the network, and use that weight matrix for generating further new images by passing it a different random noise matrix each time.
Binary Cross-Entropy Loss For GANs:
In order to optimize the parameters of GANs, we need a cost function that tells the network that how much it needs to improve by just calculating the difference between actual and predicted value. The loss function that is used in GANs is called Binary Cross-Entropy and represented as:
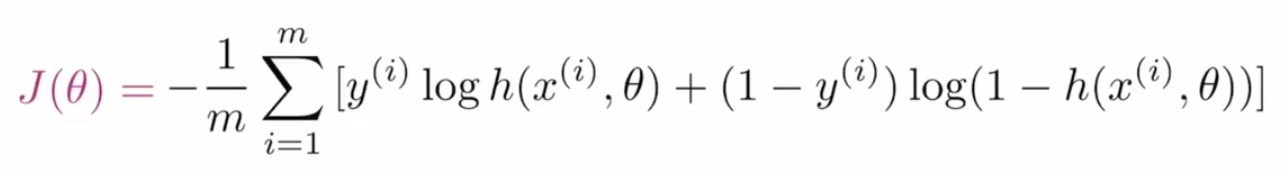
Where m is the batch size, y(i) is the actual label value, h is the predicted label value, x(i) is the input feature and θ represents the parameter.
Let’s break this cost function into sub-parts in order to get a better understanding. Given formula is the combination of two terms where one is used when effective when the label is “0” and the other one is important when the label is “1”. First-term is:
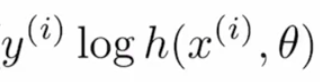
if the actual value is “1” and the predicted value is “~0” in this case, since log(~0) tends to negative infinity or very high, and if the predicted value is also “~1” then the log(~1) would be close to “0” or very less, so this term helps in calculating loss for the label values “1”.
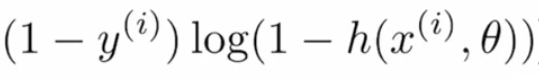
If the actual value is “0” and the predicted value is “~1” then log(1-(~1)) would result in negative infinity or very high, and if the predicted value is “~0” then the term would produce results “~0” or very less loss, so this term is used for actual label values “0”.
Either term of the loss would return the negative values in case the prediction is wrong, the combination of these terms is referred to as Entropy (Log Loss). But since it’s negative, to make it greater than “1” we apply a negative sign on it (you can see in the main formula), applying this negative sign is what makes it Cross-Entropy (Negative Log Loss).
Let’s Train First GAN Model:
We will create a GAN model that would be able to generate Hand Written digits from the MNIST Data Distribution using the PyTorch module.
First, let’s import the required modules:
%matplotlib inline import numpy as np import torch import matplotlib.pyplot as plt
Then we would read the data from the submodule provided by PyTorch itself called datasets.
# number of subprocesses to use for data loading
num_workers = 0
# how many samples per batch to load
batch_size = 64
# convert data to torch.FloatTensor
transform = transforms.ToTensor()
# get the training datasets
train_data = datasets.MNIST(root='data', train=True,
download=True, transform=transform)
# prepare data loader
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
num_workers=num_workers)
Visualize the Data
Since we would be creating our model on the PyTorch framework that uses tensors, so we would be converting our data into torch tensors. If you want to visualize the data you can go ahead and use the following code chunk:
# obtain one batch of training images dataiter = iter(train_loader) images, labels = dataiter.next() images = images.numpy() # get one image from the batch img = np.squeeze(images[0]) fig = plt.figure(figsize = (3,3)) ax = fig.add_subplot(111) ax.imshow(img, cmap='gray')

Discriminator
Now it’s time to define the Discriminator network which is the combination of various CNN layers.
import torch.nn as nn
import torch.nn.functional as F
class Discriminator(nn.Module):
def __init__(self, input_size, hidden_dim, output_size):
super(Discriminator, self).__init__()
# define hidden linear layers
self.fc1 = nn.Linear(input_size, hidden_dim*4)
self.fc2 = nn.Linear(hidden_dim*4, hidden_dim*2)
self.fc3 = nn.Linear(hidden_dim*2, hidden_dim)
# final fully-connected layer
self.fc4 = nn.Linear(hidden_dim, output_size)
# dropout layer
self.dropout = nn.Dropout(0.3)
def forward(self, x):
# flatten image
x = x.view(-1, 28*28)
# all hidden layers
x = F.leaky_relu(self.fc1(x), 0.2) # (input, negative_slope=0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc2(x), 0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc3(x), 0.2)
x = self.dropout(x)
# final layer
out = self.fc4(x)
return out
above code follows the traditional Object Oriented based Python architecture. fc1, fc2, fc3, fc3 are the fully connected layers. When we pass our input features, it passes through all these layers starting from fc1, and at the end, we have one dropout layer which is used to tackle the overfitting problem.
In the same code, you will see a function named forward(self, x), this function is the implementation of the actual forward propagation mechanism where each layer (fc1, fc2, fc3, and fc4) is followed by an activation function (leaky_relu) to convert the liner output to nonlinear.
Generator Model
After this we will check the Generator segment of GAN:
class Generator(nn.Module):
def __init__(self, input_size, hidden_dim, output_size):
super(Generator, self).__init__()
# define hidden linear layers
self.fc1 = nn.Linear(input_size, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim*2)
self.fc3 = nn.Linear(hidden_dim*2, hidden_dim*4)
# final fully-connected layer
self.fc4 = nn.Linear(hidden_dim*4, output_size)
# dropout layer
self.dropout = nn.Dropout(0.3)
def forward(self, x):
# all hidden layers
x = F.leaky_relu(self.fc1(x), 0.2) # (input, negative_slope=0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc2(x), 0.2)
x = self.dropout(x)
x = F.leaky_relu(self.fc3(x), 0.2)
x = self.dropout(x)
# final layer with tanh applied
out = F.tanh(self.fc4(x))
return out
The Generator network is also built from the fully connected layers, leaky relu activation functions, and dropout. The only thing that makes it different from Discriminator is that it gives output depending on the output_size parameter (which is the size of the image to generate).
Hyperparameter Tuning
Hyperparameters that we are going to use to train the GANs are:
# Discriminator hyperparams # Size of input image to discriminator (28*28) input_size = 784 # Size of discriminator output (real or fake) d_output_size = 1 # Size of last hidden layer in the discriminator d_hidden_size = 32 # Generator hyperparams # Size of latent vector to give to generator z_size = 100 # Size of discriminator output (generated image) g_output_size = 784 # Size of first hidden layer in the generator g_hidden_size = 32
Instantiate the Models
And finally, the complete network would look something like this:
# instantiate discriminator and generator D = Discriminator(input_size, d_hidden_size, d_output_size) G = Generator(z_size, g_hidden_size, g_output_size) # check that they are as you expect print(D) print( ) print(G)

Calculate Losses
We have defined the Generator and the Discriminator now it’s time to define their losses so that those networks would improve over time. For GANs we would have two loss function real loss and fake loss which would be defined like this:
# Calculate losses
def real_loss(D_out, smooth=False):
batch_size = D_out.size(0)
# label smoothing
if smooth:
# smooth, real labels = 0.9
labels = torch.ones(batch_size)*0.9
else:
labels = torch.ones(batch_size) # real labels = 1
# numerically stable loss
criterion = nn.BCEWithLogitsLoss()
# calculate loss
loss = criterion(D_out.squeeze(), labels)
return loss
def fake_loss(D_out):
batch_size = D_out.size(0)
labels = torch.zeros(batch_size) # fake labels = 0
criterion = nn.BCEWithLogitsLoss()
# calculate loss
loss = criterion(D_out.squeeze(), labels)
return loss
Optimizers
once losses are defined we would choose a suitable optimizer for training:
import torch.optim as optim # Optimizers lr = 0.002 # Create optimizers for the discriminator and generator d_optimizer = optim.Adam(D.parameters(), lr) g_optimizer = optim.Adam(G.parameters(), lr)
Training the Models
Since we have defined Generator and Discriminator both the networks, their loss functions, and optimizers now we would use the epochs and other features to train the whole network.
import pickle as pkl
# training hyperparams
num_epochs = 100
# keep track of loss and generated, "fake" samples
samples = []
losses = []
print_every = 400
# Get some fixed data for sampling. These are images that are held
# constant throughout training, and allow us to inspect the model's performance
sample_size=16
fixed_z = np.random.uniform(-1, 1, size=(sample_size, z_size))
fixed_z = torch.from_numpy(fixed_z).float()
# train the network
D.train()
G.train()
for epoch in range(num_epochs):
for batch_i, (real_images, _) in enumerate(train_loader):
batch_size = real_images.size(0)
## Important rescaling step ##
real_images = real_images*2 - 1 # rescale input images from [0,1) to [-1, 1)
# ============================================
# TRAIN THE DISCRIMINATOR
# ============================================
d_optimizer.zero_grad()
# 1. Train with real images
# Compute the discriminator losses on real images
# smooth the real labels
D_real = D(real_images)
d_real_loss = real_loss(D_real, smooth=True)
# 2. Train with fake images
# Generate fake images
# gradients don't have to flow during this step
with torch.no_grad():
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
fake_images = G(z)
# Compute the discriminator losses on fake images
D_fake = D(fake_images)
d_fake_loss = fake_loss(D_fake)
# add up loss and perform backprop
d_loss = d_real_loss + d_fake_loss
d_loss.backward()
d_optimizer.step()
# =========================================
# TRAIN THE GENERATOR
# =========================================
g_optimizer.zero_grad()
# 1. Train with fake images and flipped labels
# Generate fake images
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
fake_images = G(z)
# Compute the discriminator losses on fake images
# using flipped labels!
D_fake = D(fake_images)
g_loss = real_loss(D_fake) # use real loss to flip labels
# perform backprop
g_loss.backward()
g_optimizer.step()
# Print some loss stats
if batch_i % print_every == 0:
# print discriminator and generator loss
print('Epoch [{:5d}/{:5d}] | d_loss: {:6.4f} | g_loss: {:6.4f}'.format(
epoch+1, num_epochs, d_loss.item(), g_loss.item()))
## AFTER EACH EPOCH##
# append discriminator loss and generator loss
losses.append((d_loss.item(), g_loss.item()))
# generate and save sample, fake images
G.eval() # eval mode for generating samples
samples_z = G(fixed_z)
samples.append(samples_z)
G.train() # back to train mode
# Save training generator samples
with open('train_samples.pkl', 'wb') as f:
pkl.dump(samples, f)
Once you run the above code chunk the training process would start like this:

Generate Images
Finally, when the model is trained you can use the trained generator to produce the new handwritten images.
# randomly generated, new latent vectors sample_size=16 rand_z = np.random.uniform(-1, 1, size=(sample_size, z_size)) rand_z = torch.from_numpy(rand_z).float() G.eval() # eval mode # generated samples rand_images = G(rand_z) # 0 indicates the first set of samples in the passed in list # and we only have one batch of samples, here view_samples(0, [rand_images])
Output generated with the following code would like something like this:

So now you have your own trained GAN model, you can use this model to train it on a different set of images, to produce new unseen images.
References:
1. Udacity Deep Learning: https://www.udacity.com/
2. DeepLearning AI: https://www.deeplearning.ai/
Thanks for reading this article do like if you have learned something new, feel free to comment See you next time !!! ❤️
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Applied Machine Learning Engineer skilled in Computer Vision/Deep Learning Pipeline Development, creating machine learning models, retraining systems, and transforming data science prototypes to production-grade solutions. Consistently optimizes and improves real-time systems by evaluating strategies and testing real-world scenarios.





