Sounds can often become wrangled within the data science field through a traditional data table. This may be true in an educational setting or a professional research environment. In this tutorial, well-known trigonometric concepts and codes blend to form a visualization to evaluate audio files. Librosa is one of several libraries dedicated to analyzing sounds. Many individuals have used this library for machine learning purposes. Here, advanced algorithmic codes can show different methods to visualize sounds.
This article was published as a part of the Data Science Blogathon
Table of contents
Goals
Step out of the ordinary methods of analyzing sounds by taking the audio file in its original form. Use trigonometric functions and Python libraries instead of the transcribed tabularized version to analyse sounds.
Prerequisites:
- Python 3.3+ (the tutorial uses 3.9).
- Python is operating inside Jupyter Notebook (this will become helpful as graphics are more appealing and presentable with this platform than with Python Shell).
- Linux container – if Anaconda is not available, use Kali Linux instead (the tutorial uses Kali Linux).
- Understanding this tutorial can benefit those with prior knowledge and skills in using the Python computer language and Jupyter Notebook.
- Prior knowledge and skills in Python data visualization libraries.
- Some math knowledge (especially trigonometry and how to read graphs).
- Some music knowledge (music notes and general music or sound units of measurement).
Please note that some contrasting ambience factors could become a visual strain for visually sensitive readers.
Implementation
Let’s get started by selecting audio files. As a side note, DRM files are also usable in this tutorial. Some associated libraries may become unsupported as time progresses; however, there are alternate libraries that Librosa can use instead in codes. Warning messages are usual when unsupported primary libraries become deprecated and cause a chain reaction to using alternate substitute libraries. Sin and cosine are the specific trigonometric functions mentioned in this tutorial.
Finding a song from a library can become simple for music fanatics of any genre. This tutorial attempts to select a neutral song that considers readers’ opinions and views. With that in mind, Seal’s “Kiss From a Rose” (labeled “kissfromarose.m4a”) and Justin Timberlake’s “Can’t Stop the Feeling (Original Song From DreamWorks Animation’s “Trolls”)” (labeled “cantstopthefeeling.m4a” were both chosen and uploaded into Jupyter Notebook to exclude explicit lyrics from the analysis.
Once Librosa, matplotlib, NumPy, and math libraries are successfully installed on the platform, codes like those below can become usable.
For readers to test if a trigonometric function is workable on Python Jupyter Notebook. Please see the basic code shown below.
import numpy as np
import matplotlib.pylab as plt
x = np.linspace(-np.pi, np.pi, 201)
plt.plot(x, np.sin(x))
plt.xlabel('Angle [rad]')
plt.ylabel('sin(x)')
plt.axis('tight')
plt.show()What is happening in this image above can become understandable by referring to a specific trigonometric function called Sin or Sine. Most of the public population may have learned this concept. If not, readers can find an understanding of this concept from the following link. As shown in the code above the image, the NumPy version of Pi or ~3.14 is a choice linked to the line spacing function. The reason for selecting Sin or Sine is to shape the curved sound wave. Based on the graph above, all associated labels shown with the graph are according to graph requirements.
Readers can find this initial code from Librosa documentation.
import librosa
import numpy as np
y, sr = librosa.load("cantstopthefeeling.m4a")
D = librosa.stft(y)What Does “stft” Mean in the Code?
Stft is a short form for Short-Time Fourier Transform. As mentioned in Librosa’s official documentation, “The STFT represents a signal in the time-frequency domain by computing discrete Fourier transforms (DFT) over short overlapping windows” (Librosa Development Team, 2021)
This warning message is to inform readers that a substitute library can become the primary alternative in this way:

The reader should understand that this warning message is normal and that continuing to code afterward is acceptable.
s = np.abs(librosa.stft(y)**2) # Get magnitude of stft
chroma = librosa.feature.chroma_stft(S=s, sr=sr)What Does “Chroma” Mean?
Chroma is a type of transformation of sounds into numerical values. Most of the time, It can become a vector data type. A synopsis of Chroma’s history includes the feature extraction process and can become a vital part of data engineering. According to documentation, Chroma is a 12-element vector that measures energy from the sound pitch.
Displaying chroma values can appear with:
print(chroma)Output:

Next, chroma may need to transform into another data format using np.cumsum. If readers do not prefer to visit the link along with the text, a vague definition of the cumulative sum function involves adding values of a specific axis.
chroma = np.cumsum(chroma)The following code can visualize Justin Timberlake – “Can’t stop the feeling.”
import matplotlib.pylab as plt
x = np.linspace(-chroma, chroma)
plt.plot(x, np.sin(x))
plt.xlabel('Angle [rad]')
plt.ylabel('sin(x)')
plt.axis('tight')
plt.show()The output appears in this manner.

The reader can follow what is happening above with the following overview. If the audio file inside this code were replaced with another file, shapes and movements inside the graph would be different and vary as features of each sound element can change. Readers may have noticed this observation by scrolling down to the next sine wave graph.
This time, Librosa is used to show enhanced Chroma and Chroma variants. The previous link can help readers learn more about visualization of specific Chroma elements.
Code
import matplotlib.pyplot as plt
from librosa import *
y, sr = librosa.load("cantstopthefeeling.m4a")chroma_orig = librosa.feature.chroma_cqt(y=y, sr=sr)
# For display purposes, let's zoom in on a 15-second chunk from the middle of the song
idx = tuple([slice(None), slice(*list(librosa.time_to_frames([45, 60])))])
# And for comparison, we'll show the CQT matrix as well.
C = np.abs(librosa.cqt(y=y, sr=sr, bins_per_octave=12*3, n_bins=7*12*3))
fig, ax = plt.subplots(nrows=2, sharex=True)
img1 = librosa.display.specshow(librosa.amplitude_to_db(C, ref=np.max)[idx],
y_axis='cqt_note', x_axis='time', bins_per_octave=12*3,
ax=ax[0])
fig.colorbar(img1, ax=[ax[0]], format="%+2.f dB")
ax[0].label_outer()
img2 = librosa.display.specshow(chroma_orig[idx], y_axis='chroma', x_axis='time', ax=ax[1])
fig.colorbar(img2, ax=[ax[1]])
ax[1].set(ylabel='Default chroma')What Does Each Function Do?
| Code | After transforming audio into a vector data type, cut is a visual based on chroma data. CQT is short for Constant-Q, which is a graph used to visualize chroma measurements. CQT visualization uses a logarithmically spaced frequency axis to display sound in decibels. |
| Matplotlib | View visual. |
| Librosa.load | Read-in audio file. |
| idx | Time measurements. |
| c | Remove negative numerical values. |
| img1 | Setting up to display top graph. |
| img2 | Setting up to display the bottom graph. |
| Librosa.feature.chroma.cqt | After transforming audio into a vector data type, cqt is a type of visual-based on chroma data. CQT is short for Constant-Q which is a type of graph to visualize chroma measurements. CQT visualization uses a logarithmically spaced frequency axis to display sound in deciBels. |
Output:

How Can Readers Understand a Chroma and Chroma Variants Graph?
As readers know, chroma is a vector data type used to measure energy from sound, usually in decibels (dB). The graph above is a Chroma version of measuring dBs. The graph below shows how deciBels can also be translated into music notes in this form.
Another method of interpreting both graphs is to become familiar with heat maps, as they share a common display. This common display has a legend measuring DBS with colour gradients and associated labels. Interpreting the bottom graph requires some correlation knowledge and the simple fact that numbers between 0.00 and 1.00 can only be applicable when measuring correlation.
General Overview of Justin Timberlake Graphs
Top Graph
Within 15 seconds of the song, the amplitude was transformed into a dB unit of measure. Since this song includes many instrumental and vocal sounds, many layers can be visualized per pixel. For example, the C music note measures 40dB and lower, while the B music note measures 60dB and higher.
Bottom Graph
Music notes and time display one relationship type of 15 seconds within this song. Specific notes correlate strongly or weakly. For example, within the first 10 milliseconds, the C music note correlates strongly in this song, and A and D correlate weakly.
Seal’s “Kiss from a Rose” visualizations.
Now that readers know which codes to choose from to visualize certain graphs, replacing the song file with another can become second nature. The readers can see this concept below.
Chroma:

Sin (x):
Enhanced Chroma:

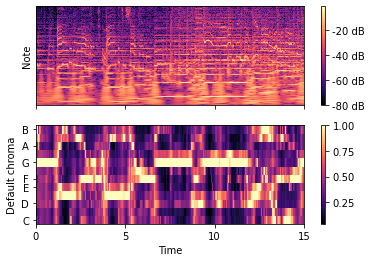
General Overview of Seal Graphs
Top Graph
Within 15 seconds of the song, the amplitude was transformed into a dB unit of measure. Since this song includes many instrumental and vocal sounds, many layers can be visualized per pixel. For example, the C music note measures 40dB and lower, while the B music note measures 60dB and higher.
Bottom Graph
Music notes and time display one relationship type of 15 seconds within this song. Correlating strongly or weakly with specific notes. For example, within the first 10 milliseconds, the G and B music notes correlate strongly in this song, while C and F correlate weakly.
A generalized method is to match. For example, reading each graph relies on matching colour with a numerical value according to graph labels.
As noted, graphs and visuals can reflect audio files with unique features and sound measurements. When comparing the provided graphs as their original state in this tutorial, it is important to consider how each aspect of sound can contribute to listeners who may intentionally or unintentionally become willing to hear sounds from audio files. Each aspect can become a differential attribute to each individual. Whether any reader would prefer to specify an audio file that could play for any purpose is mostly under a mixture of demographical contexts. Demographics include age, personal values, lifestyle, freedoms within cultural norms of geography, and more. Sound measurements can become one of several aspects, whereas demographics can affect the decision of overall audio preferences.
Conclusion
Visualizing audio files can become possible. Although it is not an exact replacement for traditional audio analysis methods, it can provide an advanced version of interpreting audio files without a visible data table. The documentation shows that more options are available in the Librosa library. Other libraries can also provide some insight into audio files. Readers can explore and discover libraries as time progresses.
Key Takeaways
- Audio files can be translated into visuals without the creation of data tables.
- Librosa can generate many views of audio files and interpret them accordingly.
- Trigonometry and general math are appropriate for sound analytics.
- Depending on the demographics of listeners who intentionally or unintentionally listen to audio files of this nature, opinions and interpretations can vary from individual to individual.
Reference:
Frequently Asked Questions
Q1. Is it possible to visualize sound?
A. Yes, sound can be visualized through waveforms, spectrograms, and other graphical representations that display properties like frequency, amplitude, and time. Visualizing sound is common in audio analysis, enabling insights into patterns, rhythm, and features for applications like music, voice analysis, and machine learning.
Q2. What is it called when you visualize sound?
A. Visualizing sound is often called audio or sound visualization. It can also refer to techniques such as waveform analysis or spectrogram analysis, where the audio data is converted into a visual format to illustrate different audio characteristics.
Q3. What are the methods of visualizing sound?
A. Common methods for visualizing sound include waveforms, spectrograms, chromagrams, and Mel-frequency cepstral coefficients (MFCCs). Each method highlights different audio features, such as time-based waveform variations or frequency-based energy distributions in spectrograms, to better understand or analyze sound patterns.
Q4. What is the use of librosa?
A. Librosa is a Python library used for audio and music analysis. It provides tools to load audio files, extract features like MFCCs and chroma, create spectrograms, and preprocess data for tasks in audio research, machine learning, and music information retrieval.
Q5. Is librosa a machine learning?
A. Librosa is not a machine learning library itself but provides essential audio processing tools compatible with machine learning workflows. It helps preprocess and analyze audio data, enabling extraction of features that can be fed into machine learning models for tasks like audio classification and music genre recognition.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.





