This article was published as a part of the Data Science Blogathon
Introduction
Making future predictions about unknown events with the help of techniques from data mining, statistics, machine learning, math modeling, and artificial intelligence is known as predictive analytics. With the help of past data, it makes predictions. We use predictive analytics in our day-to-day life without giving much thought. For example, predicting sales of an item (say flowers) in a market for a particular day. If it is valentines day, the sales of roses would be high! We can easily say that the sales of flowers would be higher on festive days than on regular days.
In predictive analytics, we find the factors responsible, gather data, apply techniques from machine learning, data mining, predictive modeling, and other analytical techniques to predict the future. The insights from the data include patterns, the relationship among different factors that might be previously unknown. Unraveling those hidden insights is of more worth than you think it is. Businesses use predictive analytics to enhance their process and to achieve their targets. Insights obtained from both structured and unstructured data can be used for predictive analytics.
How do data insights help?
In recent years, organizations have opted to collect vast amounts of data assuming that, if they harvest enough of it, it will eventually give rise to relevant business insights. Even Instagram and Facebook are providing insights to business accounts. But, data in its raw form is not useful no matter how large it is. More the data to wade through, the more difficult it is to separate valuable business information from irrelevant. A data insights strategy is built on the premise that to realize the true potential of data, you first need to determine why you’re using it and what business value you hope to glean from it. Here is how to obtain insights from data and make use of it.
1. Defining the problem statement/business goal.
Define the project outcomes, deliverables, scoping of the effort, business objectives, prepare a questionnaire for the data to be obtained based on the business goal.
2. Collection of data based on the answers to the questions created based on the problem statement.
Based on the questionnaire, collect answers in form of datasets.
3. Integrate the data obtained from various sources.
Data mining for predictive analytics prepares data from multiple sources for analysis. This provides a complete view of the customer interactions.
4. Analysis of data with analytics tools/software. We can visualize the data to observe patterns and relationships among various factors.
Data analysis is the process of inspecting, cleansing, transforming, and modeling data with the objective of discovering useful information to arrive at a conclusion.
5. Validate assumptions, hypotheses and test them using statistical models.
Statistical analysis enables to validation of the assumptions, hypothesis, and tests them using statistical models. The assumptions are based on the problem statement, formed during EDA.
6. Model generation
Model is generated with algorithms to automate the process with the new data combined with existing data. Multiple models can also be combined to obtain better results.
7. Deploying the model to generate predictions and monitor them for accuracy.
Predictive model deployment provides the option to deploy the analytical results into the everyday decision-making process to get results, reports, and output by automating the decisions based on the modeling.
We further manage and monitor the model performance to ensure that it is providing the results expected.
Incorrect or incomplete data can lead to poor models and accuracy causing chaos. That’s why it is extremely necessary to have a proper dataset to get insights and to train the model. Predictive analytics has its own challenges but it can lead to priceless business outcomes—including catching customers before they churn, optimizing business budget, and meeting customers’ demand.
Models and algorithms
Several techniques from domains including machine learning, data mining, statistics, analysis, modeling are used in predictive analytics. Predictive algorithms can be broadly classified into two groups: Machine learning models and Deep learning models. Some of them are described in this article. Though they have their own merits and demerits, one big merit of all of them is that they are reusable and can be trained using algorithms with business-specific rules. Predictive analytics is an iterative process that involves data collection, pre-processing, modeling, and deploying to get output. We can automate the process to provide us with new predictions based on the new data that’s being fed regularly over time.
Once a model is trained, we can input new data to get predictions and need not train again and again but a disadvantage is that it needs a massive amount of data to be trained. Since predictive analytics is based on machine learning algorithms, it requires proper classification of data in labels otherwise causing poor performance and accuracy. Generalizability is an issue as the model has a poor ability to transfer its findings from one case to another. Though there are some applicability issues when it comes to the findings derived from a predictive analytics model, they can be solved by certain methods, like transfer learning.
Predictive analytics models
-
Classification Model
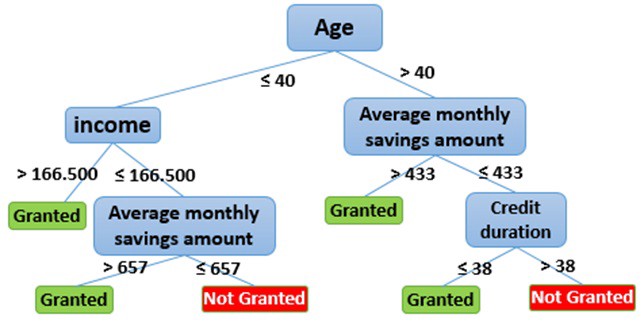
It is one of the simplest of all the models. It categorizes new data based on what it learned from the historical data. They are the best for binary classification by answering binary questions like Yes/No, True/False but can be used for multiclass classification as well. Decision Trees, Support Vector Machines are some classification algorithms.
Eg. : Loan approval is a classic use case of a classification model. Another example is spam detection messages/emails.
-
Clustering Model
A clustering model sorts data points into groups based on similarity in attributes. There are many clustering algorithms but no algorithm can be claimed as the best for all use cases. It is an unsupervised learning algorithm, unlike classification which is supervised.
Eg.: Grouping students from a school-based on their location in a city for commute services. Grouping customers based on their item preferences to recommend products related to their interests.
-
Forecast Model
Being one of the most widely used predictive analytics models, it deals with metric value prediction, estimating a numerical value for new data based on the learnings from historical data. It can be applied wherever numeric data is available.
Eg.: Traffic prediction at a city’s main road during different periods. Stores estimating availability of products in their warehouse.
-
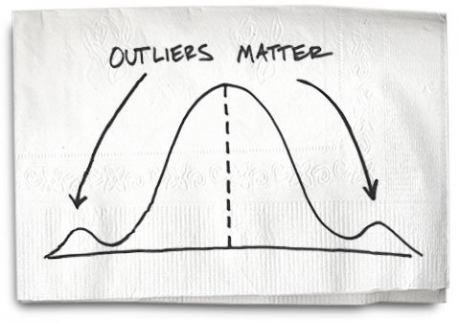
Outliers Model
As the name suggests, it is based on the anomalous data entries in their dataset. An outlier could be a data entry error, measurement error, experimental error, intentional, data processing error, sampling error, or natural error. Even though outliers can cause poor performance and accuracy, some help us find the novelty or to observe new inferences.
Eg.: Credit/Debit card theft.
-
Time Series Model
It can be used for any sequence of data points with a time period as the input parameter. It uses the past data to develop a numerical metric and predicts the future data using that metric.
Eg.: Weather prediction, Share market/cryptocurrency price prediction.
Some common predictive algorithms are Random Forests, Generalized linear model, Gradient Boosted Model, K-means clustering, and Prophet. Random forest is a combination of decision trees, in which they try to achieve the lowest error possible by using the ‘bagging’ or ‘boosting’ technique. The generalized Linear Model is a more complex variant of the General Linear Model which trains very quickly. The response variable can have any form of exponential distribution type providing a clear understanding of how the predictors influence the outcome.
Though they are resistant to overfitting, they require a large data set for training and are susceptible to outliers. Gradient Boosted Model is a prediction model based on an ensemble of decision trees. Unlike random forests, they build one tree at a time and correct the previous errors while building a new tree. K-means is helpful when looking to implement a personalized plan in a large dataset. It is used on clustering models. The prophet is an algorithm used in the time series and forecast models. Not just being automatic, it also incorporates heuristics and useful assumptions. It is popular for being fast, reliable, and robust.
Some use cases of Predictive Analytics
Predictive Analytics as said already has many applications in different domains. To mention a few,
- Healthcare
- Collection Analytics
- Fraud detection
- Risk Management
- Direct Marketing
- Cross-sell
So, how exactly they help in their domains? We receive alerts when we log in to our Gmail account from a new device. We receive alerts when we use our credit/debit cards in new places. How do they detect it? With predictive analytics, fraud examiners take few sets of predetermined variables that have been known to be involved in past fraud events and place those variables into processes to determine the likelihood that future outcomes or events will or won’t be a fraud. Say you regularly use your credit cards in Kerala, when your credit card is used in New Delhi it’s a potential fraud case. Commonwealth Bank uses analytics to predict the likelihood of fraud activity for any given transaction before it is authorized – within 40 milliseconds of the transaction initiation.
In addition to detecting claims fraud, the health insurance industry is taking steps to identify patients most at risk of chronic disease and find what interventions are best. Express Scripts, a large pharmacy benefits company, uses analytics to identify those not adhering to prescribed treatments, resulting in significant savings. Predictive analytics applications analyze customers spending, usage, and other behavior, leading to efficient cross sales, or selling additional products to current customers for an organization that offers multiple products
About The Author
I’m Keerthana, a data science student fascinated by Math and its applications in other domains. I’m also interested in writing Math and Data Science related articles. You can connect with me on LinkedIn and Instagram. Check out my other articles here.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.





