This article was published as a part of the Data Science Blogathon
Introduction
We all love listening to our favorite music every day. It is pretty hard to find songs similar to our taste and we would love a system to do this for us. We have music applications like Spotify that uses content-based and collaborative filtering to recommend us songs similar to what we like. In this article, I would like to show you how to implement a content-based music recommendation system, that takes songs from our liked playlist and recommend similar songs from a streaming data source. To carry out this process we use Kafka to stream the data, pyspark data frame, and Spark SQL to carry out the spark operations, and streamlit to visualize everything. We also use MLlib for KMeans and PCA analysis.
Streaming data using Kafka
Initially, we have a CSV file that contains all our song’s data. It has a name, artist, and features associated with the song. I had taken a dataset that has over 5 lakhs songs details which are available on Spotify. The dataset is available here:
Use this CSV and put it in the same directory where you will be having the Kafka producer code to be run. Now use the following code to get the CSV data to the stream. This is the Kafka producer code where you can stream the data as it is sent to a topic we specify. In consumer code, we can retrieve this data with the topic.
import pandas as pd
from kafka import KafkaProducer
from datetime import datetime
import time
import random
import numpy as np
# pip install kafka-python
KAFKA_TOPIC_NAME_CONS = "songTopic"
KAFKA_BOOTSTRAP_SERVERS_CONS = 'localhost:9092'
if __name__ == "__main__":
print("Kafka Producer Application Started ... ")
kafka_producer_obj = KafkaProducer(bootstrap_servers=KAFKA_BOOTSTRAP_SERVERS_CONS,
value_serializer=lambda x: x.encode('utf-8'))
filepath = "tracks.csv"
# This is the csv which has Spotify data.
songs_df = pd.read_csv(filepath)
#songs_df = songs_df[songs_df['release_date'] > '2020-01-01']
songs_df = songs_df[songs_df['popularity'] > 50]
# We use this filter to get popular songs streaming. This can be tuned based on your intrest.
songs_df['order_id'] = np.arange(len(songs_df))
songs_df['artists'] = songs_df['artists'].str.replace('[^a-zA-Z]', '')
songs_df['id_artists'] = songs_df['id_artists'].str.replace('[^a-zA-Z]', '')
# Some pre-processing performed for clean data.
song_list = songs_df.to_dict(orient="records")
message_list = []
message = None
for message in song_list:
message_fields_value_list = []
message_fields_value_list.append(message["order_id"])
message_fields_value_list.append(message["id"])
message_fields_value_list.append(message["name"])
message_fields_value_list.append(message["popularity"])
message_fields_value_list.append(message["duration_ms"])
message_fields_value_list.append(message["explicit"])
message_fields_value_list.append(message["artists"])
message_fields_value_list.append(message["id_artists"])
message_fields_value_list.append(message["release_date"])
message_fields_value_list.append(message["danceability"])
message_fields_value_list.append(message["energy"])
message_fields_value_list.append(message["key"])
message_fields_value_list.append(message["loudness"])
message_fields_value_list.append(message["mode"])
message_fields_value_list.append(message["speechiness"])
message_fields_value_list.append(message["acousticness"])
message_fields_value_list.append(message["instrumentalness"])
message_fields_value_list.append(message["liveness"])
message_fields_value_list.append(message["valence"])
message_fields_value_list.append(message["tempo"])
message_fields_value_list.append(message["time_signature"])
message = ','.join(str(v) for v in message_fields_value_list)
print("Message Type: ", type(message))
print("Message: ", message)
kafka_producer_obj.send(KAFKA_TOPIC_NAME_CONS, message)
time.sleep(1)
print("Kafka Producer Application Completed. ")
This is the code for the producer and we stream data after running this code. You can see an output like this if the code runs properly on your IDE:
Message Type: <class 'str'> Message: 0,3BFRqZFLSrqtQr6cjHbAxU,Ain't Misbehavin',51,237773,0,FatsWaller,DYWCXTkNqGFZIfSrWEa,1926,0.515,0.222,0,-16.918,0,0.0575,0.821,0.00193,0.19,0.35,98.358,4 Message Type: <class 'str'> Message: 1,61znp1Iy11bdJ2YAbwaqw7,Sing, Sing, Sing,51,520133,0,BennyGoodman,pBuKaLHJlIlqYxQQaflve,1928,0.626,0.744,2,-9.189,0,0.0662,0.847,0.892,0.145,0.259,113.117,4 Message Type: <class 'str'> Message: 2,0RNxWy0PC3AyH4ThH3aGK6,Mack the Knife,55,201467,0,LouisArmstrong,eLuQmkaCobbVDHceek,1929,0.673,0.377,0,-14.141,1,0.0697,0.586,0.0,0.332,0.713,88.973,4 # So on...
Pyspark consumer for streaming data
So, we saw how the data is streamed using Kafka. We had used “songTopic” as the topic name. In the consumer code, we use this same topic name to retrieve the data which is streamed from the producer.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.ml.feature import Normalizer, StandardScaler
import random
import time
kafka_topic_name = "songTopic"
kafka_bootstrap_servers = 'localhost:9092'
spark = SparkSession \
.builder \
.appName("Spotify Streaming Reccomendation System") \
.master("local[*]") \
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
Here, we have built a basic spark session and also initialized the topic from which we retrieve the streaming data.
# Construct a streaming DataFrame that reads from test-topic
songs_df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("subscribe", kafka_topic_name) \
.option("startingOffsets", "latest") \
.load()
songs_df1 = songs_df.selectExpr("CAST(value AS STRING)", "timestamp")
songs_schema_string = "order_id INT,id STRING, name STRING,popularity INT, duration_ms DOUBLE, explicit INT, " \
+ "artists STRING, id_artists STRING, release_date STRING, " \
+ "danceability DOUBLE," \
+ "energy DOUBLE, key INT, loudness DOUBLE, " \
+ "mode INT," \
+ "speechiness DOUBLE," \
+ "acousticness DOUBLE, instrumentalness DOUBLE, liveness DOUBLE, " \
+ "valence DOUBLE, tempo DOUBLE, time_signature DOUBLE"
songs_df2 = songs_df1 \
.select(from_csv(col("value"), songs_schema_string) \
.alias("song"), "timestamp")
songs_df3 = songs_df2.select("song.*", "timestamp")
Spark SQL View
Next, we create the schema for our streaming data. We create it in such a way that it matches the data coming from our producer. The schema is created with Spark SQL and we finally add a timestamp to each row as data arrives.
songs_df3.createOrReplaceTempView("song_find");
song_find_text = spark.sql("SELECT * FROM song_find")
songs_agg_write_stream = song_find_text \
.writeStream \
.trigger(processingTime='5 seconds') \
.outputMode("append") \
.option("truncate", "false") \
.format("memory") \
.queryName("testedTable5") \
.start()
songs_agg_write_stream.awaitTermination(1)
Finally, we create an SQL View so that the data streaming can be put into a View and written to memory. We use a processing time of 5 seconds in append mode to get all the data incoming from the producer.
Favorite song data generated using Spotify API
import pandas as pd
from spotify_api import getSong
song_data = getSong.passs()
#song_data.rename(columns={'duration_s': 'duration_ms' }, inplace=True)
song_data = song_data.drop(['id', 'added_at', 'time_signature','duration_s'], axis='columns')
rand_n = random. randint(0,len(song_data)-1)
add_df = song_data.head(rand_n)[-1:]
This code will help us retrieve a random song from our Spotify liked songs playlist. Now, this is an abstraction and the real code is being implemented on a different python file. So, feel free to add the following python file :
#!/usr/bin/env python
# coding: utf-8
import os
#import my_spotify_credentials as credentials
import numpy as np
import pandas as pd
import ujson
import spotipy
import spotipy.util
import seaborn as sns
# fill your credentials here.
os.environ["SPOTIPY_CLIENT_ID"] = ''
os.environ["SPOTIPY_CLIENT_SECRET"] = ''
os.environ["SPOTIPY_REDIRECT_URI"] = ''
scope = 'user-library-read'
username = ''
token = spotipy.util.prompt_for_user_token(username, scope)
if token:
spotipy_obj = spotipy.Spotify(auth=token)
saved_tracks_resp = spotipy_obj.current_user_saved_tracks(limit=50)
else:
print('Couldn\'t get token for that username')
number_of_tracks = saved_tracks_resp['total']
print('%d tracks' % number_of_tracks)
def save_only_some_fields(track_response):
return {
'id': str(track_response['track']['id']),
'name': str(track_response['track']['name']),
'artists': [artist['name'] for artist in track_response['track']['artists']],
'duration_ms': track_response['track']['duration_ms'],
'popularity': track_response['track']['popularity'],
'added_at': track_response['added_at']
}
tracks = [save_only_some_fields(track) for track in saved_tracks_resp['items']]
while saved_tracks_resp['next']:
saved_tracks_resp = spotipy_obj.next(saved_tracks_resp)
tracks.extend([save_only_some_fields(track) for track in saved_tracks_resp['items']])
tracks_df = pd.DataFrame(tracks)
pd.set_option('display.max_rows', len(tracks))
tracks_df['artists'] = tracks_df['artists'].apply(lambda artists: artists[0])
tracks_df['duration_ms'] = tracks_df['duration_ms'].apply(lambda duration: duration/1000)
tracks_df = tracks_df.rename(columns = {'duration_ms':'duration_s'})
audio_features = {}
for idd in tracks_df['id'].tolist():
audio_features[idd] = spotipy_obj.audio_features(idd)[0]
tracks_df['acousticness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['acousticness'])
tracks_df['speechiness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['speechiness'])
tracks_df['key'] = tracks_df['id'].apply(lambda idd: str(audio_features[idd]['key']))
tracks_df['liveness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['liveness'])
tracks_df['instrumentalness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['instrumentalness'])
tracks_df['energy'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['energy'])
tracks_df['tempo'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['tempo'])
tracks_df['time_signature'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['time_signature'])
tracks_df['loudness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['loudness'])
tracks_df['danceability'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['danceability'])
tracks_df['valence'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['valence'])
class getSong():
def __init__(self):
super(getSong, self).__init__()
def passs():
return tracks_df
Using this we can now get a random favorite song from the Spotify playlist.
Feature Engineering
df = spark.sql("SELECT * FROM testedTable5")
df = df.sort(df.release_date.desc())
df_stream = df
df = df.drop('order_id',
'id',
'explicit',
'mode',
'release_date',
'id_artists',
'time_signature',
'duration_ms',
'timestamp')
df_sp = spark.createDataFrame(add_df)
df = df.union(df_sp)
from pyspark.ml.feature import VectorAssembler
assembler=VectorAssembler(inputCols=[
'danceability',
'energy',
'loudness',
'speechiness',
'acousticness',
'instrumentalness',
'liveness',
'valence',
'tempo'], outputCol='features')
assembled_data=assembler.setHandleInvalid("skip").transform(df)
We initially drop the unwanted columns from our spark data frame. We append our favorite song data to this data frame using the sparks union operation. It is important for us the get all features to a ‘features column’ for which we use VectorAssembler from pyspark.ml.feature library. The assembled_data here is a data frame that has the feature vector attached with all other columns.
from pyspark.ml.feature import StandardScaler scale=StandardScaler(inputCol='features',outputCol='standardized') data_scale=scale.fit(assembled_data) df=data_scale.transform(assembled_data)
We use a standard scaler to scale the features column we generated earlier. So that this scaled column can be further used to perform K-Means clustering.
K-Means Clustering
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
silhouette_score=[]
evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='standardized', \
metricName='silhouette', distanceMeasure='squaredEuclidean')
KMeans_algo=KMeans(featuresCol='standardized', k=3)
KMeans_fit=KMeans_algo.fit(df)
output_df =KMeans_fit.transform(df)
Now, this is a step that we can skip if we want. But when we have very large data incoming it is always better that we perform K-Means so that we can cluster data and then we can use the recommendation on this clustered dataset based on what cluster our favorite song falls. We use MLlib to perform clustering. We can also perform PCA Analysis using MLlib and we had found that almost all numerical features we have used take up to 90% variance. So all features are being included here.
Recommendation system code
import numpy as np, pandas as pd
import matplotlib.pyplot as plt, seaborn as sns
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
class SpotifyRecommender():
def __init__(self, rec_data):
self.rec_data_ = rec_data
def spotify_recommendations(self, song_name, amount=1):
distances = []
song = self.rec_data_[(self.rec_data_.name.str.lower() == song_name.lower())].head(1).values[0]
# get details of our fav song from name we pass as x earlier.
res_data = self.rec_data_[self.rec_data_.name.str.lower() != song_name.lower()]
#dropping the data with our fav song so that it doesnt affect our recommendation.
for r_song in tqdm(res_data.values):
# tqdm is just used for showing the bar of iteration through our streamed songs.
dist = 0
for col in np.arange(len(res_data.columns)):
# (len(res_data.columns) gets us the number of columns -> 13 in our case.
#indeces of non-numerical columns neednt be considered.
if not col in [0,1,13]:
#calculating the manhettan distances for each numerical feature
# song -> from our fav dataset.
# r_song -> from streaming data.
dist = dist + np.absolute(float(song[col]) - float(r_song[col]))
distances.append(dist)
# distances are calculated and appended and added to a new column called distances in our dataset.
res_data['distance'] = distances
#sorting our data to be ascending by 'distance' feature
res_data = res_data.sort_values('distance')
# resulting dataset have the song similar to our fav song's numerical values and thus recommended.
columns = ['name', 'artists', 'acousticness', 'liveness', 'instrumentalness', 'energy', 'danceability', 'valence']
return res_data[columns][:amount]
datad = output_df.select('name',
'artists',
'danceability',
'energy',
'key',
'loudness',
'speechiness',
'acousticness',
'instrumentalness',
'liveness',
'valence',
'tempo',
'prediction')
datf = datad.toPandas()
datf.drop(datf[datf['artists'] == '0'].index, inplace = True)
datf.drop_duplicates(inplace=True)
datf.drop(datf[datf['danceability'] == 0.0000].index, inplace = True)
datf.drop(datf[datf['liveness'] == 0.000].index, inplace = True)
datf.drop(datf[datf['instrumentalness'] == 0.000000].index, inplace = True)
datf.drop(datf[datf['energy'] == 0.0000].index, inplace = True)
datf.drop(datf[datf['danceability'] == 0.000].index, inplace = True)
datf.drop(datf[datf['valence'] == 0.000].index, inplace = True)
y = datf
value_pred = datf.iloc[-1:]['prediction']
#datf = datf[datf['prediction'] == list(value_pred)[0]]
recommender = SpotifyRecommender(datf)
x = add_df['name'].tolist()[0]
rec_song = recommender.spotify_recommendations(x, 10)
v = add_df[['name', 'artists', 'acousticness', 'liveness', 'instrumentalness', 'energy',
'danceability', 'valence']]
rec_song = pd.concat([rec_song, v])
rec_song.to_csv('rec_song.csv')
Here, read the comments I have provided for the Spotify recommendation function to understand exactly how the function work. Before calling the function we do a bit of preprocessing and convert the data frame to pandas type for ease of operation. Finally, we can specify the number of songs we want to see bypassing that as a parameter. We also save the recommended songs dataset into a CSV file which is accessed for visualization in the streamlit application.
df_rec = spark.createDataFrame(rec_song) df_rec.show()
+--------------------+-------------------+------------+--------+----------------+------+------------+-------+ | name| artists|acousticness|liveness|instrumentalness|energy|danceability|valence| +--------------------+-------------------+------------+--------+----------------+------+------------+-------+ | Tennessee Whiskey| ChrisStapleton| 0.205| 0.0821| 0.0096| 0.37| 0.392| 0.512| | Element| PopSmoke| 0.0301| 0.251| 2.18E-6| 0.878| 0.772| 0.305| | River| BishopBriggs| 0.302| 0.0579| 2.97E-6| 0.477| 0.733| 0.545| | Edelweiss|BillLeeCharmianCarr| 0.785| 0.126| 4.64E-4| 0.156| 0.233| 0.354| | Cradles| SubUrban| 0.27| 0.179| 6.48E-5| 0.585| 0.581| 0.63| |Make You Feel My ...| Adele| 0.907| 0.105| 3.83E-4| 0.172| 0.317| 0.0963| | Lover| TaylorSwift| 0.492| 0.118| 1.58E-5| 0.543| 0.359| 0.453| | SAD!| XXXTENTACION| 0.258| 0.123| 0.00372| 0.613| 0.74| 0.473| |I Got It Bad And ...| OscarPetersonTrio| 0.971| 0.0882| 0.911|0.0527| 0.488| 0.193| | Sweet Caroline| NeilDiamond| 0.611| 0.237| 1.09E-4| 0.127| 0.529| 0.578| | Naina - Lofi Flip| Mrunal Meena| 0.72| 0.299| 0.897| 0.258| 0.641| 0.321| +--------------------+-------------------+------------+--------+----------------+------+------------+-------+
This is the final recommendation based on the song we provide. As you can see to check how good it is I passed “Naina-Lofi” as my favorite song as it’s Hindi music and slow song but most of the songs that were recommended were slow music with the same kind of attributes. To visualize everything we can use streamlit.
Visualization using Streamlit
Just run streamlit using this command:
streamlit run dashboard.py
The code for the dashboard is here:
import pandas as pd
import numpy as np
import streamlit as st
import plotly.graph_objects as go
import plotly.express as px
import os
# import my_spotify_credentials as credentials
import numpy as np
import pandas as pd
import ujson
import spotipy
import spotipy.util
import seaborn as sns
# fill credentials here.
os.environ["SPOTIPY_CLIENT_ID"] = ''
os.environ["SPOTIPY_CLIENT_SECRET"] = ''
os.environ["SPOTIPY_REDIRECT_URI"] = ''
scope = 'user-library-read'
username = ''
token = spotipy.util.prompt_for_user_token(username, scope)
if token:
spotipy_obj = spotipy.Spotify(auth=token)
saved_tracks_resp = spotipy_obj.current_user_saved_tracks(limit=50)
else:
print('Couldn\'t get token for that username')
number_of_tracks = saved_tracks_resp['total']
print('%d tracks' % number_of_tracks)
def save_only_some_fields(track_response):
return {
'id': str(track_response['track']['id']),
'name': str(track_response['track']['name']),
'artists': [artist['name'] for artist in track_response['track']['artists']],
'duration_ms': track_response['track']['duration_ms'],
'popularity': track_response['track']['popularity'],
'added_at': track_response['added_at']
}
tracks = [save_only_some_fields(track) for track in saved_tracks_resp['items']]
while saved_tracks_resp['next']:
saved_tracks_resp = spotipy_obj.next(saved_tracks_resp)
tracks.extend([save_only_some_fields(track) for track in saved_tracks_resp['items']])
tracks_df = pd.DataFrame(tracks)
pd.set_option('display.max_rows', len(tracks))
#pd.reset_option('display.max_rows')
tracks_df['artists'] = tracks_df['artists'].apply(lambda artists: artists[0])
tracks_df['duration_ms'] = tracks_df['duration_ms'].apply(lambda duration: duration/1000)
tracks_df = tracks_df.rename(columns = {'duration_ms':'duration_s'})
audio_features = {}
for idd in tracks_df['id'].tolist():
audio_features[idd] = spotipy_obj.audio_features(idd)[0]
tracks_df['acousticness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['acousticness'])
tracks_df['speechiness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['speechiness'])
tracks_df['key'] = tracks_df['id'].apply(lambda idd: str(audio_features[idd]['key']))
tracks_df['liveness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['liveness'])
tracks_df['instrumentalness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['instrumentalness'])
tracks_df['energy'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['energy'])
tracks_df['tempo'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['tempo'])
tracks_df['time_signature'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['time_signature'])
tracks_df['loudness'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['loudness'])
tracks_df['danceability'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['danceability'])
tracks_df['valence'] = tracks_df['id'].apply(lambda idd: audio_features[idd]['valence'])
df = tracks_df
rec_df = pd.read_csv(r'C:\Users\siddh\Downloads\structuredstreamingkafkapyspark-master\rec_song.csv')
st.set_page_config(layout="wide")
hide_streamlit_style = """
<style>
footer {visibility: hidden;}
</style>
"""
st.markdown(hide_streamlit_style, unsafe_allow_html=True)
st.title('Spotify User Dashboard')
col1, col2 = st.beta_columns(2)
#
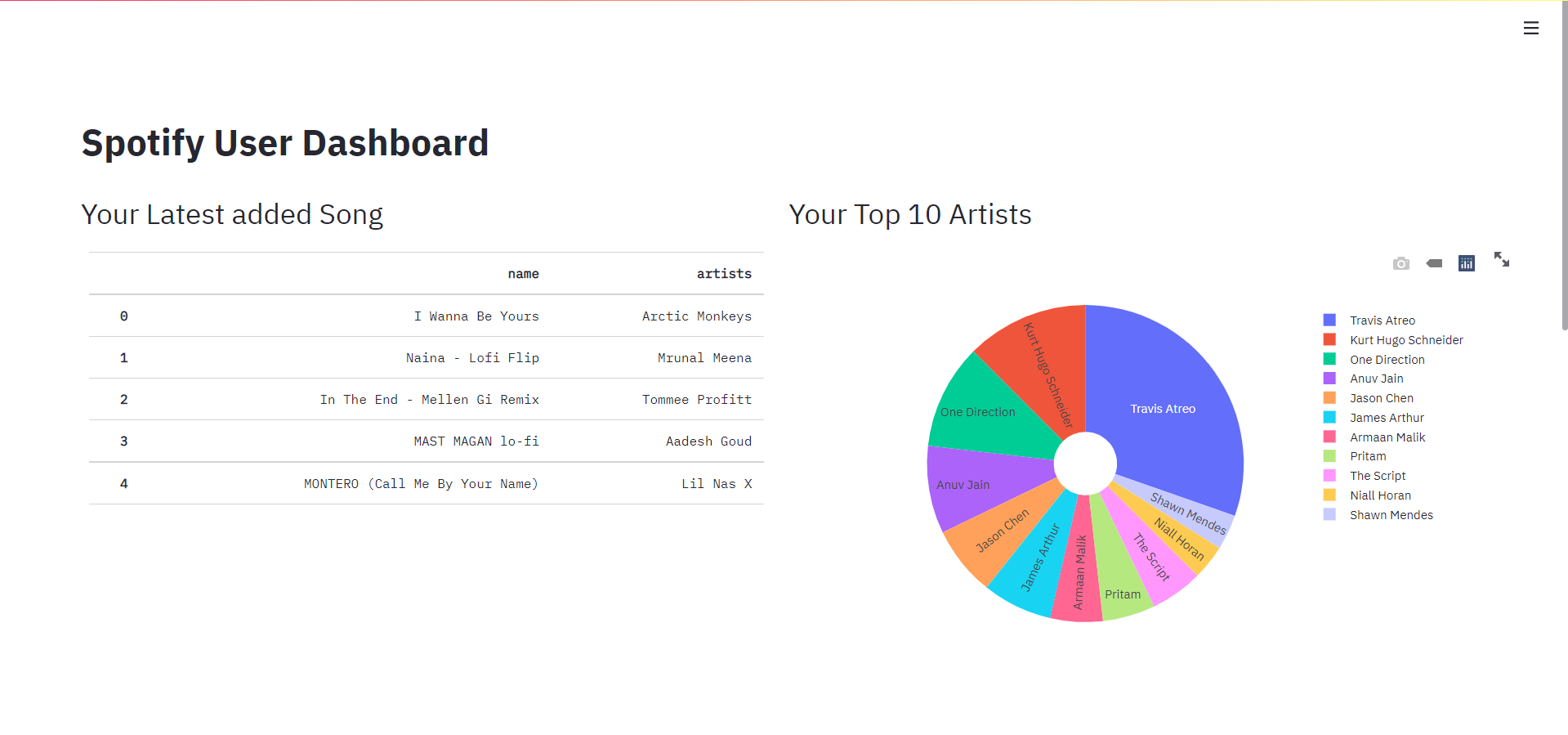
col1.header("Your Latest added Song")
top_5_songs = df[['name', 'artists']].head(5)
col1.table(top_5_songs)
#
col2.header("Your Top 10 Artists")
df1 = df['artists'].value_counts()[:11].to_frame()
df1['Name'] = df1.index
df1.rename(columns={'artists': 'Songs'}, inplace=True)
fig = px.pie(df1, values='Songs', names='Name', hole=0.2)
fig.update_traces(textposition='inside', textinfo='label')
col2.plotly_chart(fig, use_container_width=True)
####
col3, col4, col5 = st.beta_columns(3)
#
ur_favourite_artist = df[['artists']].value_counts().index[0][0]
st.markdown("""
<style>
.big-font {
font-size:30px !important;
font-Weight: bold;
}
</style>
""", unsafe_allow_html=True)
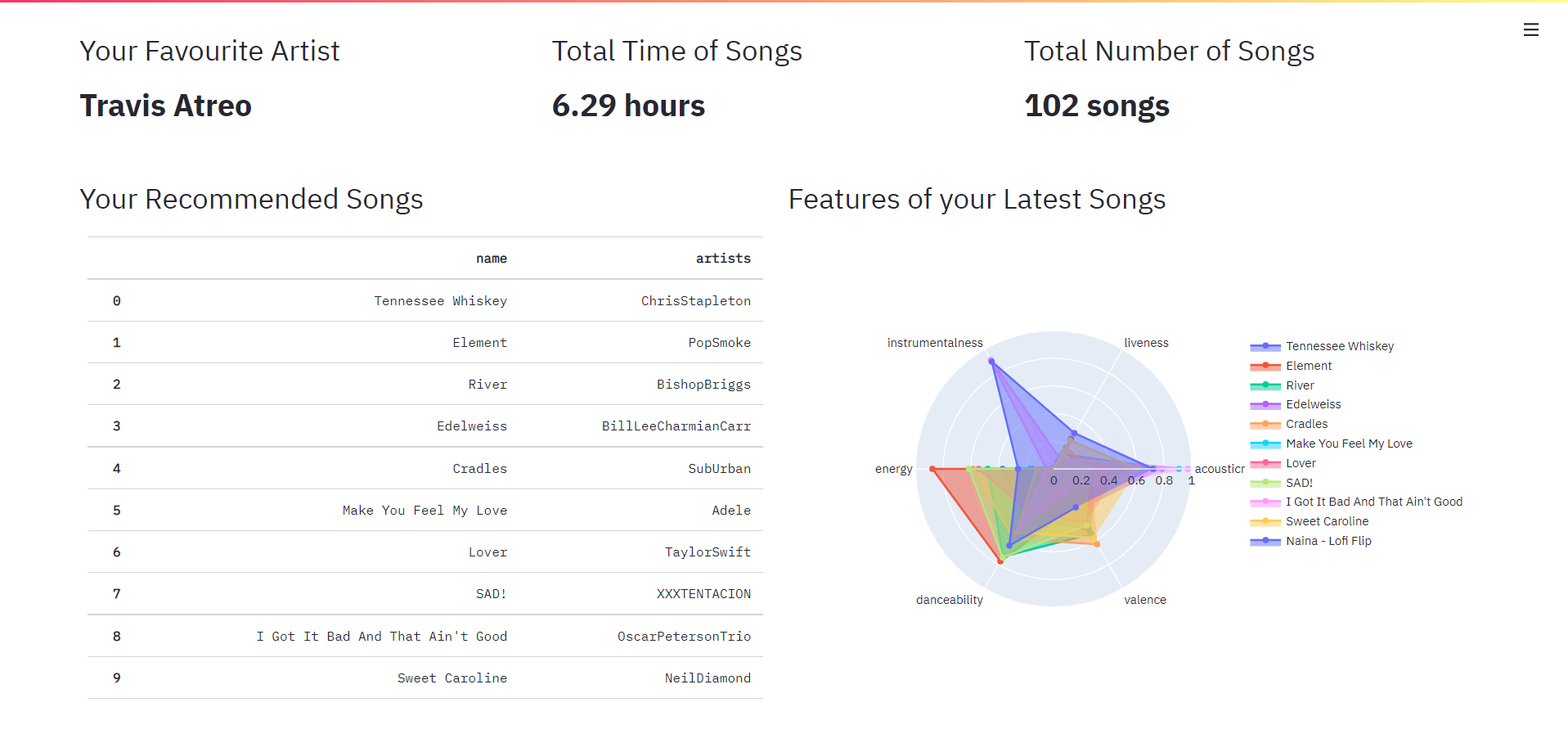
col3.header("Your Favourite Artist")
col3.markdown(f'<p class="big-font">{str(ur_favourite_artist)}</p>', unsafe_allow_html=True)
#
col4.header("Total Time of Songs")
time = round(df.duration_s.sum() / 3600, 2)
col4.markdown(f'<p class="big-font">{round(df.duration_s.sum() / 3600, 2)} hours</p>', unsafe_allow_html=True)
#
col5.header("Total Number of Songs")
col5.markdown(f'<p class="big-font">{df.count()[1]} songs</p>', unsafe_allow_html=True)
#
####
col6,col7 = st.beta_columns(2)
col6.header("Your Recommended Songs")
df2 = rec_df[['name','artists']]
print(df2)
col6.table(df2.head(10))
#
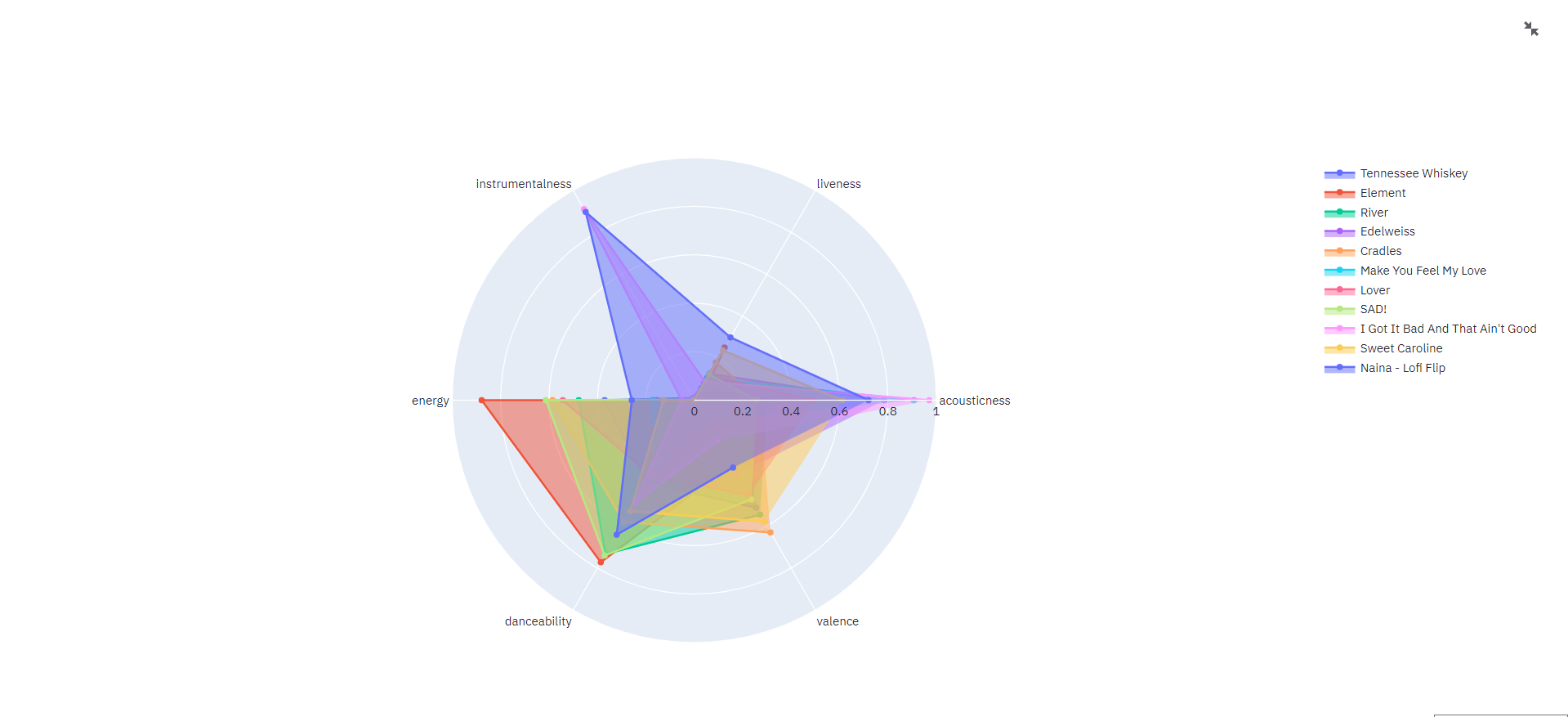
col7.header("Features of your Latest Songs")
df3 = rec_df.loc[:10, ['name', 'artists', 'acousticness', 'liveness', 'instrumentalness', \
'energy', 'danceability', 'valence']]
df3 = df3.T.reset_index()
df3.rename(columns={'index': 'theta', 0: 'zero', 1: 'one', 2: 'two', \
3: 'three', 4: 'four',5:'five',6:'six',7:'seven',8:'eight',9:'nine',10:'ten',11:'eleven',12:'twelve'}, inplace=True)
df3_cols = df3.columns[1:]
len_cols = len(df3_cols)
categories = df3['theta'].tolist()[2:]
fig1 = go.Figure()
for i in range(0, len_cols):
fig1.add_trace(go.Scatterpolar(
r=df3[df3_cols[i]][2:].tolist(),
theta=categories,
fill='toself',
name=df3[df3_cols[i]][0]))
fig1.update_layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0, 1]
)),
showlegend=True
)
col7.plotly_chart(fig1, use_container_width=True)
Final Output
References
1. https://www.kaggle.com/yamaerenay/spotify-dataset-19212020-160k-tracks?select=tracks.csv
2. https://developer.spotify.com/documentation/web-api/
3. https://docs.streamlit.io/en/stable/
4. https://www.kaggle.com/artempozdniakov/spotify-data-eda-and-music-recommendation
5. https://github.com/indiacloudtv/structuredstreamingkafkapyspark
6. https://www.datasciencewiki.com/2019/08/apache-kafka-tutorial-for-beginners.html
Thumbnail Image: https://unsplash.com/photos/IJthre6PHHQ
Conclusion
In any case, you need help regarding setting up pyspark and Kafka on your Windows machine feel free to contact me at [email protected] or on my LinkedIn page:
https://www.linkedin.com/mwlite/in/siddharth-m-426a9614a
The entire code above can be followed on this GitHub repo:
https://github.com/Siddharth1698/Spotify-Recommendation-System-using-Pyspark-and-Kafka
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Passionate about artificial intelligence, I am dedicated to advancing research in Generative AI and Large Language Models (LLMs). My work focuses on exploring innovative solutions and pushing the boundaries of what's possible in this dynamic and transformative field.





