This article was published as a part of the Data Science Blogathon
Overview
- This blog covers GREP(Global-Regular-Expression-Print) and its drawbacks
- Then we move on to Document Term Matrix and Inverted Matrix
- Finally, we end with dynamic and distributed indexing

Global Regular Expression Print
Whenever we are dealing with a small amount of data, we can use the grep command very efficiently. It allows us to search one or more files for lines that contain a pattern.
For example-:
“grep pat check.txt”
This command will print all lines containing the text string “pat”, from the file check.txt
All the lines containing text strings such as “pat”, “patty”, “pattern”, “patties” will be printed at the output terminal.
Drawbacks of Grep command:-
- It is unable to return the document with query words appearing the maximum number of times.
- This command is in general very slow when working with a large amount of data.
Document Term Matrix
The Document term matrix, when creating a data set of no. of appearance of words in a corpus of documents, contains rows corresponding to the documents and columns corresponding to no. of appearance of words.
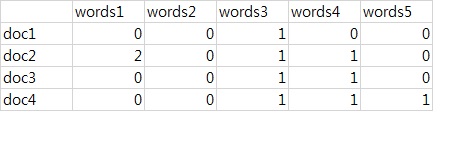
image source-https://stackoverflow.com/questions/38712750/how-could-i-make-document-term-matrix-with-my-own-term-list
But, the size of the document-term matrix grows very quickly and It ends up occupying a lot of space.
Inverted index
In this method, a vector is formed where each document is given a document ID and the terms act as pointers. Then sorting of the list is done in alphabetical order and pointers are maintained to their corresponding document ID.
For example:-
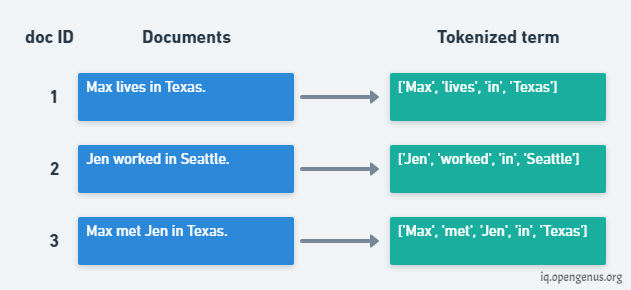
image source: https://iq.opengenus.org/idea-of-indexing-in-nlp/
Formation of vector
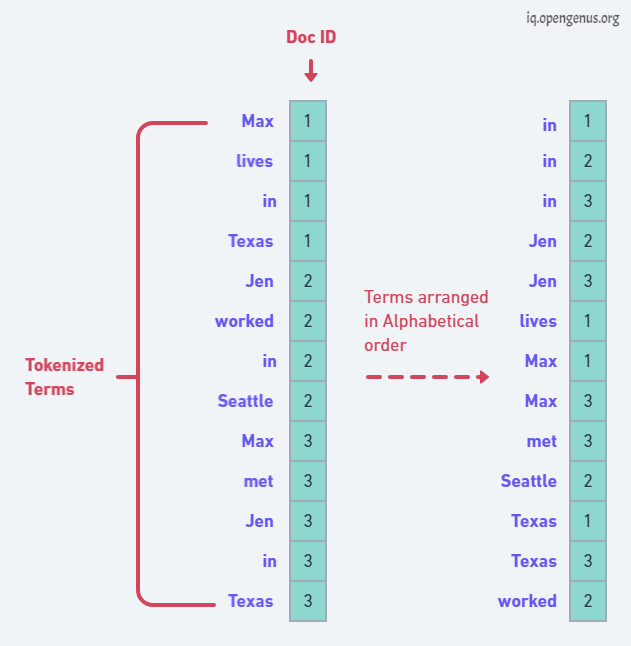
image source:https://iq.opengenus.org/idea-of-indexing-in-nlp/
Finally, an inverted index structure is created. Then an array-like structure is formed containing the doc ID and the terms grouped together.
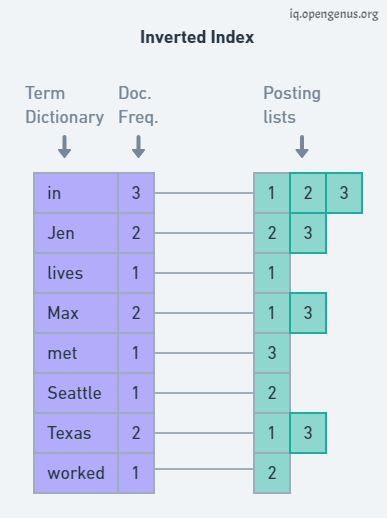
CODE OF INVERTED INDEX:
%%writefile file.txt Max lived in Texas. Jen worked in Seattle. Max met Jen in Texas.
# this will open the file
file = open('file.txt', encoding='utf8')
read = file.read()
file.seek(0)
read
# to obtain the
# number of lines
# in file
line = 1
for word in read:
if word == 'n':
line += 1
print("Number of lines in file is: ", line)
# create a list to
# store each line as
# an element of list
array = []
for i in range(line):
array.append(file.readline())
array
punc = ”’!()-[]{};:'”, ./?@#$%^&*_~”’
for ele in read:
if ele in punc:
read = read.replace(ele, ” “)
read
# to maintain uniformity
read=read.lower()
read
from nltk.tokenize import word_tokenize
import nltk
from nltk.corpus import stopwords
nltk.download('punkt')
for i in range(1):
# this will convert
# the word into tokens
text_tokens = word_tokenize(read)
print(text_tokens
)
dict = {}
for i in range(line):
check = array[i].lower()
for item in text_tokens:
if item in check:
if item not in dict:
dict[item] = []
if item in dict:
dict[item].append(i+1)
dict
The Document-term matrix and the inverted index both works on the condition that the corpus is static and the data fits into the hard disk of a single machine. Now we will look upon more general cases where data is dynamically changing and the data is stored in multiple machines.
The major steps in building inverted index are:-
- Collection of documents that need to be indexed
- Tokenization of the text and converting each text document into a list of tokens
- Linguistic preprocessing of the data, making a list of normalized tokens, that are the indexing terms.
- Indexing the documents and sorting the list alphabetically.
Distributed Indexing
Web search engines generally use this for index construction. This method is used for index construction in large computer clusters. The general idea of the cluster is to perform the tasks on general computing machines instead of supercomputers. A master node assigns the task to each computer or node in the cluster. The computing job is distributed in chunks to complete the tasks in a short duration of time. First of all, the input data is split into n splits and the size of each split is chosen such that the work can be done evenly and efficiently. When a machine completes its work on one split then a new split is assigned. If the machine dies before completion then the split is assigned to another machine.
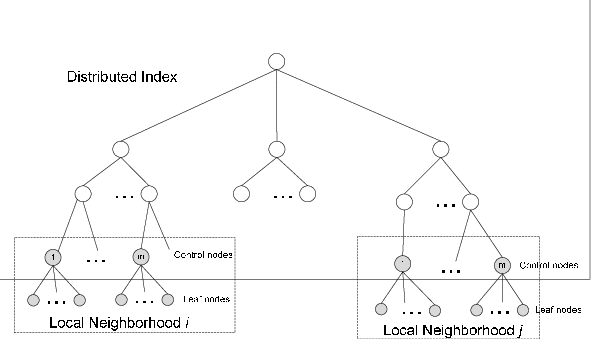
image source – https://www.researchgate.net/figure/Distributed-Indexing-Scheme_fig1_259645175
Dynamic Indexing
Most of the data collections in the real world get updated with new data and documents being added or old ones being removed from it. Therefore new terms need to be added and posting lists need to be updated with existing terms.
One way of doing this periodically reconstructing the index from scratch. This is feasible only when the number of changes over time is small and the delay in making searchable documents is acceptable.
If we need the documents to be included quickly, one of the best ways is to maintain two indexes, one for the main index and the other for the auxiliary index for new documents. Every time the Auxillary index becomes very large we merge it with the main index.
Although, the time taken by this method is less than reconstructing it from scratch the process is very complex therefore many large search engines prefer reconstructing from scratch.
ENDING NOTES
The Global Regular Expression Print is very slow with large data collections and it does not return the no. of appearances of each word. Therefore to know the no. of appearances of each word in the document we need indexing.
As the size of the data document increases the space occupied by the document term matrix increases very rapidly. Therefore we needed a method that occupies less space in our system, this makes inverted indexing a better choice than document term matrix. But These methods can only be used when data is not being updated and all of the data documents are stored in a single computer.
Thus the need for Distributed indexing and dynamic indexing arises when we want to index data that is not static in nature and is stored over multiple systems.





