This article was published as a part of the Data Science Blogathon
Introduction
Let’s start our discussion by imagine a scenario where you have tested your machine learning model well, and you get absolutely perfect accuracy. After getting the accuracy, you are happy with your work and say well done to yourself, and then decide to deploy your project. However, when the actual data is applied to this model in the production, you get poor results. So, you think that why did this happen and how to fix it?
The possible reason for this occurrence is Data Leakage. It is one of the leading machine learning errors. Data leakage in machine learning happens when the data that we are used to training a machine learning algorithm is having the information which the model is trying to predict, this results in unreliable and bad prediction outcomes after model deployment.
Image Source: Link
So, In this article, we will discuss all the things related to Data Leakage including what it is, how it has happened, how to fix it, etc. So, If you are a Data Science enthusiast, then read this article completely since it is one of the most important concepts that you as a Data Science enthusiast must know to accelerate your Data Science Journey.
Table of Contents
The topics which we are going to discuss in this detailed article on Data Leakage are as follows:
- What is meant by Data Leakage?
- How does Data Leakage exactly happen?
- What are the examples of Data Leakage?
- How to detect Data Leakage?
- How to Fix the Problem of Data Leakage?
What is meant by Data Leakage?
Data Leakage is the scenario where the Machine Learning Model is already aware of some part of test data after training.This causes the problem of overfitting.
In Machine learning, Data Leakage refers to a mistake that is made by the creator of a machine learning model in which they accidentally share the information between the test and training data sets. Typically, when splitting a data set into testing and training sets, the goal is to ensure that no data is shared between these two sets. Ideally, there is no intersection between these two sets. This is because the purpose of the testing set is to simulate the real-world data which is unseen to that model. However, when evaluating a model, we do have full access to both our train and test sets, so it is our duty to ensure that there is no overlapping between the training data and the testing data (i.e, no intersection).
As a result, due to the Data leakage, we got unrealistically high levels of performance of our model on the test set, because that model is being run on data that it had already seen in some capacity in the training set. The model effectively memorizes the training set data and is easily able to correctly output the labels or values for those examples of the test dataset. Clearly, this is not ideal, as it misleads the person who evaluates the model. When such a model is then used on truly unseen data that is coming mostly on the production side, then the performance of that model will be much lower than expected after deployment.
How does it exactly happen?
In simple terms, Data Leakage occurs when the data used in the training process contains information about what the model is trying to predict. It appears like “cheating” but since we are not aware of it so, it is better to call it “leakage” instead of cheating. Therefore, Data leakage is a serious and widespread problem in data mining and machine learning which needs to be handled well to obtain a robust and generalized predictive model.
Let’s discuss the happening of data leakage problem in a much detailed manner:
When you split your data into training and testing subsets, some of your data present in the test set is also copied in the train set and vice-versa.
As a result of which when you train your model with this type of split it will give really good results on the train and test set i.e, both training and testing accuracy should be high.
But when you deploy your model into production it will not perform well, because when a new type of data comes in it won’t be able to handle it.
Examples of Data Leakage
In this section, we will discuss some of the example scenarios where the problem of data leakage occurs. After understanding these examples, you have better clarity about the problem of Data Leakage.
General Examples of Data Leakage
To understand this example, firstly we have to understand the difference between “Target Variable” and “Features” in Machine learning.
- Target variable: The Output which the model is trying to predict.
- Features: The data used by the model to predict the target variable.
Example 1-
The most obvious and easy-to-understand cause of data leakage is to include the target variable as a feature. What happens is that after including the target variable as a feature, our purpose of prediction got destroyed. This is likely to be done by mistake but while modelling any ML model, you have to make sure that the target variable is differentiated from the set of features.
Example 2 –
To properly evaluate a particular machine learning model, we split our available data into training and test subsets. Invariably, what happens is that some of the information from the test set is shared with the train set, and vice-versa. So, another common cause of data leakage is to include test data with training data. Therefore, It becomes necessary to test the models with new and previously unseen data. If we include the test data in the training, then the process would defeat this purpose.
In real-life problem statements, the above two cases are not very likely to occur because they can easily be spotted while doing the modelling. So, now let’s see some more dangerous causes of data leakage that can sneak.
Presence of Giveaway features
Giveaway features are those features from the set of all features that expose the information about the target variable and would not be available after the model is deployed.
Let’s consider this with the help of the following examples:
Example 1 –
Let’s we are working on a problem statement in which we have to build a model that predicts a certain medical condition. If we have a feature that indicates whether a patient had a surgery related to that medical condition, then it causes data leakage and we should never be included that as a feature in the training data. The indication of surgery is highly predictive of the medical condition and would probably not be available in all cases. If we already know that a patient had a surgery related to a medical condition, then we may not even require a predictive model to start with.
Example 2 –
Let’s we are working on a problem statement in which we have to build a model that predicts if a user will stay on a website. Including features that expose the information about future visits will cause the problem of data leakage. So, we have to use only features about the current session because information about the future sessions is not generally available after we deployed our model.
Leakage during Data preprocessing
While solving a Machine learning problem statement, firstly we do the data cleaning and preprocessing which involves the following steps:
- Evaluating the parameters for normalizing or rescaling features
- Finding the minimum and maximum values of a particular feature
- Normalize the particular feature in our dataset
- Removing the outliers
- Fill or completely remove the missing data in our dataset
The above-described steps should be done using only the training set. If we use the entire dataset to perform these operations, data leakage may occur. Applying preprocessing techniques to the entire dataset will cause the model to learn not only the training set but also the test set. As we all know that the test set should be new and previously unseen for any model.
How to detect Data Leakage?
Let’s consider the following three cases to detecting data leakage:
Case-1:
In general, if we see that the model which we build is too good to be true (i.,e gives predicted and actual output the same), then we should get suspicious and data leakage cannot be ruled out. At that time, the model might be somehow memorizing the relations between feature and target instead of learning and generalizing it for the unseen data. So, it is advised that before the testing, the prior documented results are weighed against the expected results.
Case-2:
While doing the Exploratory Data Analysis (EDA), we may detect features that are very highly correlated with the target variable. Of course, some features are more correlated than others but a surprisingly high correlation needs to be checked and handled carefully. We should pay close attention to those features. So, with the help of EDA, we can examine the raw data through statistical and visualization tools.
Case-3:
After the completion of the model training, if features are having very high weights, then we should pay close attention. Those features might be leaky.
How to fix the problem of Data Leakage?
The main culprit behind this is the way we split our dataset and when. The following steps can prove to be very crucial in preventing data leakage:
Idea-1 (Extracting the appropriate set of Features)

Figure showing the selection of best set of features for your ML Model
Image Source: Link
To fix the problem of data leakage, the first method we can try is to extract the appropriate set of features for a machine learning model. While choosing features, we should make sure that the given features are not correlated with the given target variable, as well as that they do not contain information about the target variable, which is not naturally available at the time of prediction.
Idea-2 (Create a Separate Validation Set)
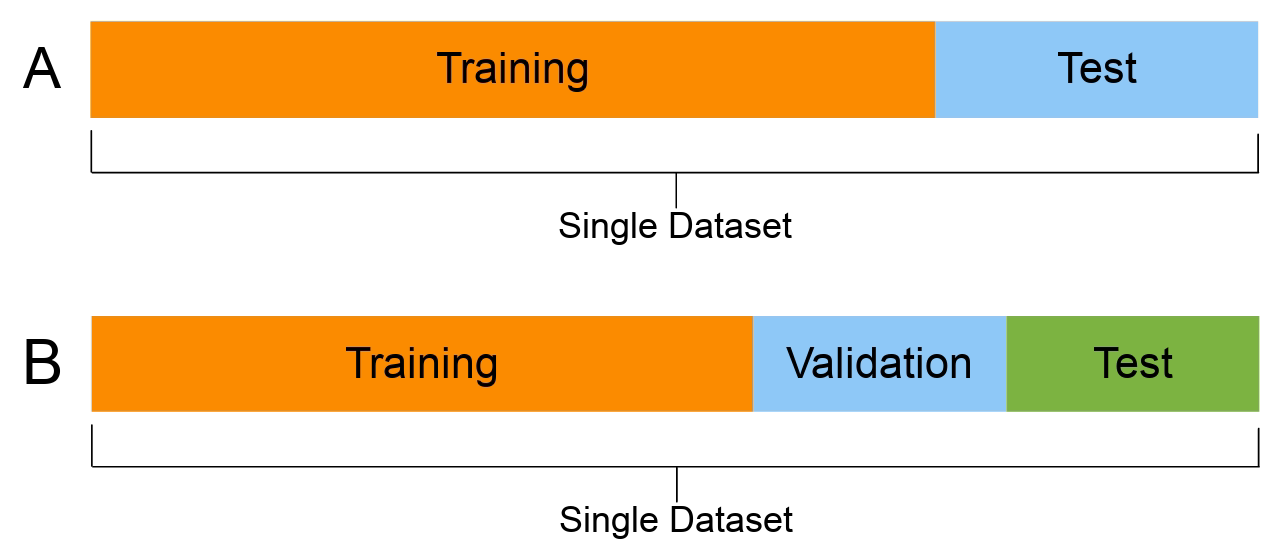
Figure Showing splitting of the dataset into train, validation, and test subsets
Image Source: Link
To minimize or avoid the problem of data leakage, we should try to set aside a validation set in addition to training and test sets if possible. The purpose of the validation set is to mimic the real-life scenario and can be used as a final step. By doing this type of activity, we will identify if there is any possible case of overfitting which in turn can act as a caution warning against deploying models that are expected to underperform in the production environment.
Idea-3 (Apply Data preprocessing Separately to both Train and Test subsets)

Figure Showing How a Data can be divided into train and test subsets
Image Source: Link
While dealing with neural networks, it is a common practice that we normalize our input data firstly before feeding it into the model. Generally, data normalization is done by dividing the data by its mean value. More often than not, this normalization is applied to the overall data set, which influences the training set from the information of the test set and eventually it results in data leakage. Hence, to avoid data leakage, we have to apply any normalization technique separately to both training and test subsets.
Idea-4 (Time-Series Data)

Figure Showing an example of Time-Series Data
Image Source: Link
Problem with the Time-Series Type of data:
When dealing with time-series data, we should pay more attention to data leakage. For example, if we somehow use data from the future when doing computations for current features or predictions, it is highly likely to end up with a leaked model. It generally happens when the data is randomly split into train and test subsets.
So, when working with time-series data, we put a cutoff value on time which might be very useful, as it prevents us from getting any information after the time of prediction.
Idea-5 (Cross-Validation)
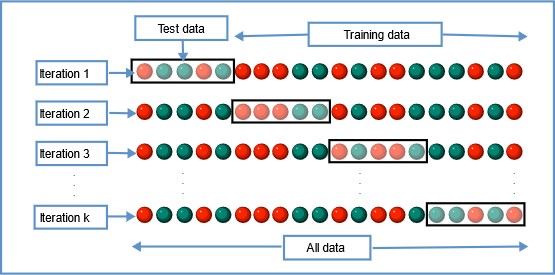
Figure Showing Idea Behind Cross-Validation
Image Source: Link
When we have a limited amount of data to train our Machine learning algorithm, then it is a good practice to use cross-validation in the training process. What Cross-validation is doing is that it splits our complete data into k folds and iterates over the entire dataset in k number of times and each time we are using k-1 fold for training and 1 fold for testing our model.
The advantage of this approach is that we used the entire dataset for both training and testing purposes. However, if you get suspicious about data leakage, then it is better to scale or normalize the data and compute the parameters on each fold of cross-validation separately.
To know more about Cross-Validation and its types, you can refer to the following article:
Detailed Discussion on Cross-Validation and its types
Conclusion
So, as a concluding step we can say that Data leakage is a widespread issue in the domain of predictive analytics. We train our different machine learning models with known data and expect the model to perform better predictions or results on previously unseen data in our production environment, which is our final aim. So, for a model to have a good performance in those predictions, it must generalize well. But Data leakage prevents a model to generalize well and thus causes some false assumptions about the model performance. Therefore, to create a robust and generalized predictive model, we should pay close attention to detect and avoid data leakage. This ends our today’s discussion on Data Leakage!
Congratulations on learning the most important concept of Machine Learning which you must know while working on real-life problems related to Data Science! 👏
Other Blog Posts by Me
You can also check my previous blog posts.
Previous Data Science Blog posts.
Here is my Linkedin profile in case you want to connect with me. I’ll be happy to be connected with you.
For any queries, you can mail me on [email protected]
End Notes
Thanks for reading!
I hope that you have enjoyed the article. If you like it, share it with your friends also. Something not mentioned or want to share your thoughts? Feel free to comment below And I’ll get back to you. 😉
I am a B.Tech. student (Computer Science major) currently in the pre-final year of my undergrad. My interest lies in the field of Data Science and Machine Learning. I have been pursuing this interest and am eager to work more in these directions. I feel proud to share that I am one of the best students in my class who has a desire to learn many new things in my field.






How to fix the problem of Data Leakage? > To fix the problem of data leakage, the first method we can try is to extract the appropriate set of features for a machine learning model. While choosing features, we should make sure that the given features are not correlated with the given target variable, as well as that they do not contain information about the target variable, which is not naturally available at the time of prediction. Practically this point needs to be more clarity so please add some practical scenario example for better understanding.
It was very amazing blog