This article was published as a part of the Data Science Blogathon
Why NLP?
Natural Language Processing has always been a key tenet of Artificial Intelligence (AI). With the increase in the adoption of AI, systems to automate sophisticated tasks are being built. Some of these examples are described below.
Diagnosing rare form of cancer –
At the University of Tokyo’s Institute of Medical Science, doctors used artificial intelligence to successfully diagnose a rare type of leukemia. The doctors used an AI system that cross-referenced the patient’s genetic data with tens of millions of oncology papers and diagnosed cancer as rare secondary leukemia caused by myelodysplastic syndromes. The machine was able to do this in 10 mins, while it would have taken human scientists about 2 weeks to do the same.
Settling an insurance claim within 3 seconds
Lemonade built a bot – AI Jim, which interacts with the claimant in real-time and understands the nature and severity of the claim. It assesses the likelihood of the claim being fraudulent, and even nudges people to be more honest by incorporating years of behavioral economics research into its conversations. This system settled an insurance claim within 3 seconds by running 18 algorithms.
Automating customer service tasks
KLM Royal Dutch Airlines fly to 163 destinations worldwide, operates 200+ aircraft, and annually ferry 30M + passengers.
The airline wanted to create “a new entry point” for customers – one that provides opportunities for conversational interactions using voice and text. They created BB (Blue bot) – a chatbot that helps customers manage flight bookings through conversational interfaces.
In the first month of launch, around 1.7 million messages have been exchanged between that bot and 500,000 people.
In all of these examples, the systems are meant to understand the natural language used by human beings. To elaborate
- The system that diagnosed cancer had to go through millions of text documents written by humans in English/other languages in varied styles and a vast vocabulary
- Blue-Bot not only interprets the queries of a customer which is typically in the natural language but also generates appropriate responses in natural language.
Let us now demystify natural language processing.
Why is it hard?
NLP is hard because natural languages evolved without a standard rule/logic. They were developed in response to the evolution of the human brain: in its ability to understand signs, voice, and memory. With NLP, we are now trying to “discover rules” for something (language) that evolved without rules.
Let us now try to understand why NLP is considered hard using a few examples
- “There was not a single man at the party”
- Does it mean that there were no men at the party? or
- Does it mean that there was no one at the party?
- Here does man refer to the gender “man” or “mankind”?
- “The chicken is ready to eat”
- Does this mean that the bird (chicken) is ready to feed on some grains? or
- Does it mean that the meat is cooked well and is ready to be eaten by a human?
3. “Google is a great company.” and “Google this word and find its meaning.”
-
-
- Google is being used as a noun in the first statement and as a verb in the second.
-
4. The man saw a girl with a telescope.
- Did the man use a telescope to see the girl? or
- Did the man see a girl who was holding a telescope?
Natural language is full of ambiguities. Ambiguity can be referred to as the ability to have more than one meaning or being understood in more than one way. This is a primary reason why NLP is considered hard. Another reason why NLP is hard is that it deals with the extraction of knowledge from unstructured data.
Understanding Textual Data
Elements of Text
Let us now understand various elements of textual data and see how we can extract these using the NLTK library. Now we shall discuss the following elements of the text:
- Hierarchy of Text
- Tokens
- Vocabulary
- Punctuation
- Part of speech
- Root of a word
- Base of a word
- Stop words
Hierarchy of Text
Text is a collection of meaningful sentences. Each sentence in turn comprises many words.
Consider the text “India is a republic nation. We are proud Indians”. This text contains 2 sentences and 9 words.
import nltk from nltk import * sent = "India is a republic nation. We are proud Indians"
Texts are represented in Python in the form lists: [‘India is a republic nation. We are proud Indians’]. We can use slicing, indexing and we can also find the length of these lists
sent = "India is a republic nation. We are proud Indians"
print(len(sent)) #Prints the number of characters
print(sent[0:5]) #Prints 'India'
print(sent[11:19]) #Prints 'republic'
Tokens
A meaningful unit of text is a token. Words are usually considered tokens in NLP. The process of breaking a text based on the token is called tokenization.
print(nltk.word_tokenize(sent)) #Prints list of words ['India', 'is', 'a', 'republic', 'nation', '.', 'We', 'are', 'proud', 'Indians']
Vocabulary
The vocabulary of a text is the set of all unique tokens used in it
tokens = nltk.word_tokenize(sent) vocab = sorted(set(tokens)) print(vocab) #Prints ['.', 'India', 'Indians', 'We', 'a', 'are', 'country', 'is', 'proud', 'republic']
Punctuation
Punctuation refers to symbols used to separate sentences and their elements and to clarify meaning.
from string import punctuation
vocab_wo_punct=[]
for i in vocab:
if i not in punctuation:
vocab_wo_punct.append(i)
print(vocab_wo_punct) #Prints ['India', 'Indians', 'We', 'a', 'are', 'country', 'is', 'proud', 'republic']
Part of Speech
Part of speech(POS) refers to the category to which a word is assigned based on its function. You may recall that the English language has 8 parts of speech – noun, verb, adjective, adverb, pronoun, determiner, preposition, conjunction, and interjection.
Different POS taggers are available that classify words into POS. A popular one is the Penn treebank, which has the following parts of speech.
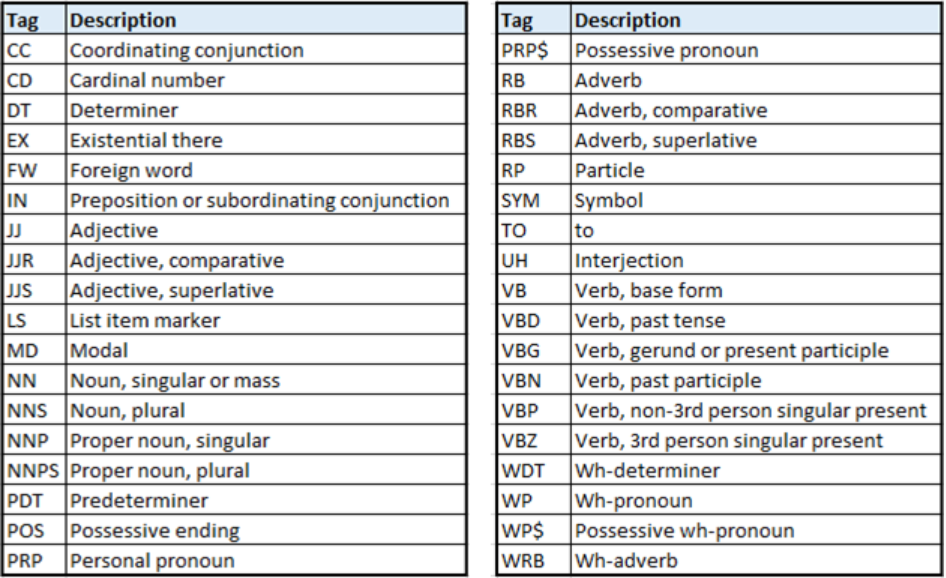
The below code demonstrates POS tagging on text
from nltk import pos_tag
pos_list = pos_tag(vocab_wo_punct)
print(pos_list)
""" Prints [('India', 'NNP'), ('Indians', 'NNPS'), ('We', 'PRP'), ('a', 'DT'),
('are', 'VBP'), ('country', 'NN'), ('is', 'VBZ'), ('proud', 'JJ'),
('republic', 'JJ'), ('India', 'NNP')] """
Root of a word – Stemming
Stemming is a technique used to find the root form of a word. In the root form, a word is devoid of any affixes (suffixes and prefixes)
from nltk.stem.snowball import SnowballStemmer
stemObj = SnowballStemmer("english")
stemObj.stem("Studying") #Prints 'studi'
stemmed_vocab=[]
stemObj = SnowballStemmer("english")
for i in vocab_no_punct:
stemmed_vocab.append(stemObj.stem(i))
print(stemmed_vocab) #Prints ['india', 'indian', 'we', 'a', 'are', 'countri', 'is', 'proud', 'republ']
Base of a word – Lemmatization
Lemmatization removes inflection and reduces the word to its base form
from nltk.stem.wordnet import WordNetLemmatizer
lemmaObj = WordNetLemmatizer()
lemmaObj.lemmatize("went",pos='v') #Prints 'go'
Distributions and n-grams
Stop words
Stop words are typically the most commonly occurring words in text like ‘the’, ‘and’, ‘is’, etc. NLTK provides a pre-defined set of stopwords for English, as shown
from nltk.corpus import stopwords
wo_stop_words = []
stop_words_set = set(stopwords.words("english"))
for i in vocab_no_punct:
if i not in stop_words_set:
wo_stop_words.append(i)
print(wo_stop_words) #Prints ['India', 'Indians', 'We', 'country', 'proud', 'republic']
Frequency Distribution
Frequency distribution helps understand which words are commonly used and which are not. These can help refine stop words in a given text.
text="I saw John coming. He was with Mary. I talked to John and Mary.
John said he met Mary on the way. John and Mary were going to school."
print(nltk.FreqDist(nltk.word_tokenize(text)))
#Prints FreqDist({'.': 5, 'Mary': 4, 'John': 4, 'I': 2, 'to': 2, 'and': 2, 'the': 1, 'was': 1, 'were': 1, 'school': 1, ...})
nltk.FreqDist(text.split()).plot()
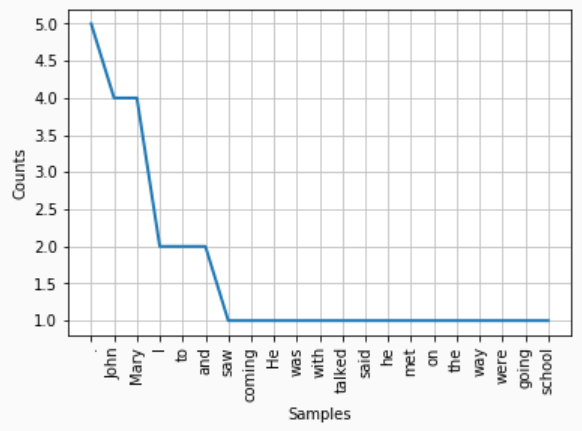
Conditional Frequency Distribution
Conditional Frequency Distributions can help in identifying differences in the usage of words in different texts. For example, commonly used words in books/articles on the “romance” genre could be different from words used in books/articles of the “news” genre. An example with nltk library to get the conditional frequency distribution of words.
Here we use the Brown corpus.
cfd = nltk.ConditionalFreqDist(
(a, b)
for a in brown.categories()
for b in brown.words(categories=genre))
genres_list = ['romance','news','science_fiction', 'humor','religion','hobbies']
modals_list = ['may','could', 'can', 'must', 'will', 'might']
cfd.tabulate(conditions=genres_list, samples=modals_list)
N-grams
N-gram is a contiguous sequence of n items from a given sample of text or speech. NLTK provides methods to extract n-grams from text
from nltk import ngrams
#use 2 for bigrams
bigrams = ngrams(vocab_no_punct,2)
print(list(bigrams))
#Prints [('India', 'Indians'), ('Indians', 'We'), ('We', 'a'), ('a', 'are'), ('are', 'country'),
('country', 'is'), ('is', 'proud'), ('proud', 'republic')]
#use 3 for trigrams
trigrams = ngrams(vocab_no_punct,3)
print(list(trigrams))
[('India', 'Indians', 'We'), ('Indians', 'We', 'a'), ('We', 'a', 'are'), ('a', 'are', 'country'),
('are', 'country', 'is'), ('country', 'is', 'proud'), ('is', 'proud', 'republic')]
Operations on Text
Let us now use a sample text file – Few paragraphs from the Wikipedia article on NLP and perform the different preprocessing operations.
Here is the initial setup of the code.
import nltk
import string
from nltk import word_tokenize
from nltk import wordpunct_tokenize
from nltk.corpus import stopwords
from string import punctuation
from nltk.stem.snowball import SnowballStemmer
from nltk.stem.wordnet import WordNetLemmatizer
from nltk import pos_tag
#read the file
#Note: use the correct path of the file depending on your environment
file = open("nlp_wikipedia_sample.txt",'r')
text = ''
for i in file.readlines():
text += i
# print(text)
Step1: Trimming the text of unwanted spaces
Sometimes the text that we want to process and analyze may contain a few extra spaces at the beginning and end. We use the strip() method of Python to get rid of these unwanted spaces
#remove trailing spaces trimmed_text = text.strip() # print(trimmed_text)
Step 2: Convert the text into either lower or uppercase
In order to analyze text we often need to normalize it. The normalizing text includes various steps, one of which is bringing the text to a standard case – either lower or upper. Normalizing depends on the application we want to build. If we are trying to understand the sentiment of a given tweet, we may not convert the tweet to lowercase because uppercase is often used to emphasize sentiment i.e. “AWESOME” and “awesome” have different levels of emphasis.
To convert the text into lower/upper case, we use the lower() and upper() methods of Python
converted_text = trimmed_text.lower() # print(converted_text)
Step 3: Tokenize the text and determine its vocabulary
As seen earlier, tokenization splits a sentence into its constituent words. NLTK provides different kinds of tokenizers based on different kinds of text that you may encounter. For example, for Twitter data NLTK provides the casual TweetTokenizer (nltk.tokenize.casual.TweetTokenizer) which handles commonly occurring smileys, hashtags, etc.
Visit the nltk tokenize website to know more about tokenizers offered by nltk.
The below code shows the usage of word tokenizer and word punct tokenizer to get the tokens from the sample text
#Tokenization using word tokenizer tokenized_list = word_tokenize(converted_text) # print(tokenized_list) #Tokenization using word punct tokenizer punct_tokenized_list = wordpunct_tokenize(converted_text) # print(punct_tokenized_list) #get vocabulary vocab_set = set(tokenized_list) # print(vocab_list)
Step 4: Remove stop words from the text
Removing stop words from text helps enrich the amount of useful information in the text. As seen earlier, the NLTK library provides pre-defined stop words in different natural languages. However, sometimes this may not be sufficient, we may need to add new words to the stop word list considering the domain of the text. We can determine which words are stop words by analyzing the results of word frequency and conditional frequency distributions.
The below code removes common English stop words from our sample text#remove stop words
set_wo_stopwords = vocab_set - set(stopwords.words("english"))
# print(set_wo_stopwords)
Step 5: Remove punctuation
Removing punctuation from text is again a normalization technique that is contextual to the application. Going back to the example of sentiment analysis of tweets, we may choose to not remove the punctuation, because the presence of some of the characters like ‘!’, ‘:-)’ , etc. convey a strong sentiment.
The below code demonstrates the removal of punctuation from the sample data
#remove punctuation set_wo_punctuation = set_wo_stopwords - set(punctuation) # print(set_wo_punctuation)
Step 6: Normalize the text using stemming and/or lemmatization
Stemming and Lemmatization result in the root/base form of words in the text. This technique is particularly useful when building applications like a search engine.
NLTK provides different stemmers that can be used depending on the language and desired level of accuracy. You can read more about the available stemmers on the nltk website under the stem.
The below code demonstrates stemming using the SnowballStemmer
#stemming
stemmed_list= []
stemObj = SnowballStemmer("english")
for i in set_wo_punctuation:
stemmed_list.append(stemObj.stem(i))
# print(stemmed_list)
WordnetLemmatizer is one the most commonly used lemmatizer for the English language. It is used to arrive at the base form of the word.
The below code demonstrates the usage of the WordnetLemmatizer on our sample data.
#parts of speech tagging
pos_tag_list = pos_tag(set_wo_punctuation)
# print(pos_tag_list)
#for getting parts of speech
def parts_of_speech(pos):
if pos.startswith("N"):
return wordnet.NOUN
elif pos.startswith("J"):
return wordnet.ADJ
elif pos.startswith("V"):
return wordnet.VERB
elif pos.startswith("R"):
return wordnet.ADV
elif pos.startswith("S"):
return wordnet.ADJ_SAT
else:
return ''
#lemmatization
lemma_list = []
lemmaObj = WordNetLemmatizer()
for word,pos in pos_tag_list:
get_pos = parts_of_speech(pos)
if get_pos != '':
lemma_list.append(lemmaObj.lemmatize(word, pos = get_pos))
else:
lemma_list.append(word)
# print(lemma_list)
Step 7: Create n-grams from text
In many applications of text analysis, tokens are not treated individually but based on how they occur together. For example, systems that automatically predict the word that you are going to type next need to look at tokens that are commonly used with one another.
The below code demonstrates how bi-grams (n-grams where n=2) can be created on our sample text.
#bigrams
bigrams = ngrams(set_wo_punctuation,2)
# print(list(bigrams))
Regular Expressions
R.E is the scalpel in the hand of an NLP practitioner
Having seen the different operations we can do on text using nltk let’s see another special module called Regular Expressions usually called regex.
Regex provides us with an easy way to do various text processing methods like search, sub, findall.
Let us now see some simple steps for using regular expressions.
Keeping in mind we will need to import the module named “re”.
import re
The syntax for doing any regex method would follow re.”methodname”(r”some expression related to process”,input_string). The “some expression related to process” is called the raw string which has different types of expressions to go through and process the input_string.
Let us now see some of these expressions and how to use them
Expression
| How it works | |
| A-Z | Searches in the input string for characters that exist between A and Z |
| a-z | Searches in the input string for characters that exist between a and z |
| ? | Number of occurrences of the character preceding the? can be 0 or 1 |
| . | Denotes any character either alphabet or number or special characters |
| + | The number of occurrences of the character preceding the + can be at least 1 or more |
| w | Denotes a set of alphanumeric characters(both upper and lower case) and ‘_’ |
| s | Denotes a set of all space-related characters |
Search
Search method searches for the string present in the “r” in the whole input string and returns a match object if there is a match else returns None. Search only returns the first match present in the string.
sent3 = "1947 was when India became independent."
print("Occurences of a-z: ",re.search(r"[a-z]+",sent3))
#prints Occurences of a-z:
The match at the string “was” is the only string according to the search method because space after it is not in our desired set. “+” indicates match the substring which has at least one character.
sent3 = "1947 was when India became independent."
print("Occurences of 0-9: ",re.search(r"[0-9]+",sent3))
#prints Occurences of 0-9:
The match at the string “1947” is the only string according to the search method because our set only ranges from 0 to 9.
sent3 = "1947_was when India became independent."
print("Occurences of w and space: ",re.search(r"[w ]+",sent3))
#prints Occurences of 0-9:
Our desired set is namely a-z, A-Z, 0-9, ‘_’ and a space character.
Sub
Sub is the substitution of a substring with another string in the given input string. So understandably it takes three parameters.
The first argument is the string to be removed, the second argument is the resultant string and the last argument is the input string.
sent = "I like coffee" print(re.sub(r"coffee","tea",sent)) #prints I like tea
Findall
Findall parses our input string from left to right and returns all the substrings matching with our raw string as a list.
sent = "I like coffee and coffee is amazing. coffee keeps me awake. coffee is bad" print(re.findall(r"coffee",sent)) #prints ['coffee', 'coffee', 'coffee', 'coffee'] print(len(re.findall(r"coffee",sent))) #prints 4
Tagging
POS Tagger
We have seen the POS tagger which identifies the part of speech of each word in a given sentence. In this sections, we will dive deeper into the different models that can be used to do POS tagging.
Consider the below lines of code
sent1 = "The race officials refused to permit the team to race today" print(pos_tag(word_tokenize(sent1)))
The output here is
[('The', 'DT'), ('race', 'NN'), ('officials', 'NNS'), ('refused', 'VBD'), ('to', 'TO'), ('permit', 'VB'),
('the', 'DT'), ('team', 'NN'), ('to', 'TO'), ('race', 'NN'), ('today', 'NN')]
However, if you observe the statement and consult your knowledge of the English grammar, you will realize that the word ‘race’ here is being used as a noun in the first occurrence and as a verb in the second.
Similarly, can you identify where there is a possible mistake in the below code?
sent2 = "That gentleman wants some water to water the plants"
print(pos_tag(word_tokenize(sent2)))
# Output: [('That', 'DT'), ('gentleman', 'NN'), ('wants', 'VBZ'), ('some', 'DT'), ('water', 'NN'),
('to', 'TO'), ('water', 'NN'), ('the', 'DT'), ('plants', 'NNS')]
These mistakes in tagging are primarily because of how the taggers classify words and on what kind of data they have been trained.
Observe that the POS tagger gets the classification right for the below statement indicating that the error is not by default.
text = word_tokenize("They refuse to permit us to obtain the refuse permit")
print(nltk.pos_tag(text))
# Prints [('They', 'PRP'), ('refuse', 'VBP'), ('to', 'TO'), ('permit', 'VB'), ('us', 'PRP'), ('to', 'TO'),
('obtain', 'VB'), ('the', 'DT'), ('refuse', 'NN'), ('permit', 'NN')]
NLTK provides different taggers that we can train and use in order to tag our unseen text data more efficiently. The taggers are:
- Default tagger
- Lookup taggers:
- Unigram tagger – context-independent tagging
- Ngram tagger – context-dependent tagging
- Regular Expression Tagger
We can also use a combination of these taggers to tag a sentence with the concept of backoff.
Note that in order to train a tagger, we need a corpus of tagged words.
Default Tagger
The default tagger assigns the same tag to each token, this is considered the most naive tagger.
The below code demonstrates the usage of the default tagger on the Barack Obama article
# importing a predefined corpus
from nltk.corpus import brown
# getting the most common tag in the brown corpus
tags = [tag for (word,tag) in brown.tagged_words()]
most_common_tag = nltk.FreqDist(tags).max()
print(most_common_tag)
#Prints NN which means the most common POS is noun
# Using the most_common_tag as the input for DefaultTagger
from nltk import DefaultTagger
default_tagger = DefaultTagger(most_common_tag)
def_tagged_barack = default_tagger.tag(tokenised_barack)
print(def_tagged_barack)
#Prints [('Barack', 'NN'), ('Hussein', 'NN'), ('Obama', 'NN'), ('II', 'NN'), ('born', 'NN'),
('August', 'NN'), ('4', 'NN'), (',', 'NN'), ('1961', 'NN'), (')', 'NN'), ('is', 'NN'), ... ]
Lookup taggers – Unigram and N-gram taggers
Lookup Taggers
A NgramTagger tags a word based on the previous n words occurring in the text.
For example, consider that we have only one tagged sentence in the training set as shown below
from nltk import word_tokenize
sent1 = "the quick brown fox jumps over the lazy dog"
training_tags = pos_tag(word_tokenize(sent1))
print(training_tags)
"""Prints [('the', 'DT'), ('quick', 'JJ'), ('brown', 'NN'), ('fox', 'NN'), ('jumps', 'VBZ'),
('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN')] """
# Now let us use these tags to train the NgramTagger
ngram_tagger = nltk.NgramTagger(n=2,train=[training_tags]) #Here when we set n=2, we are creating a bigram tagger
Having provided the training data to the NgramTagger, we can now use it to tag a new sentence as shown below
sent2 = "the lazy dog was jumped over by the quick brown fox" sent2_tags = ngram_tagger.tag(word_tokenize(sent2)) print(sent2_tags)
The output of the above code is
[('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN'), ('was', None), ('jumped', None),
('over', None), ('by', None), ('the', None), ('quick', None), ('brown', None), ('fox', None)]
From the above output, you can notice that many of the words have been tagged as None, which means that the tagger was unable to find the appropriate POS tag for the word in the given context.
In order to understand why this happened, we need to learn what context means for a NgramTagger.
Context of an NGramTagger
Let us consider n=2 for an NGram Tagger and use that to understand the context.
The tagged training list [(‘the’, ‘DT’), (‘quick’, ‘JJ’), (‘brown’, ‘NN’), (‘fox’, ‘NN’), (‘jumps’, ‘VBZ’), (‘over’, ‘IN’), (‘the’, ‘DT’), (‘lazy’, ‘JJ’), (‘dog’, ‘NN’)] is converted to bigrams as below
print(list(nltk.ngrams(pos_tag(word_tokenize(sent1)),n=2)))
"""Prints [(('the', 'DT'), ('quick', 'JJ')),
(('quick', 'JJ'), ('brown', 'NN')),
(('brown', 'NN'), ('fox', 'NN')),
(('fox', 'NN'), ('jumps', 'VBZ')),
(('jumps', 'VBZ'), ('over', 'IN')),
(('over', 'IN'), ('the', 'DT')),
(('the', 'DT'), ('lazy', 'JJ')),
(('lazy', 'JJ'), ('dog', 'NN'))] """
Now, when the Ngramtagger has to tag the new sentence “the lazy dog was jumped over by the quick brown fox”, it converts this sentence into bigrams as well, as below
print(list(nltk.ngrams(word_tokenize(sent2),n=2)))
"""Prints [('the', 'lazy'),
('lazy', 'dog'),
('dog', 'was'),
('was', 'jumped'),
('jumped', 'over'),
('over', 'by'),
('by', 'the'),
('the', 'quick'),
('quick', 'brown'),
('brown', 'fox')] """
The NgramTagger then does a lookup for matching bigrams in the training data and uses that to tag the new data.
Since the pairs (the lazy) and (lazy, dog) appear in the training data, the tagger is able to tag the words “the”, “lazy”, and “dog”.
When it encounters the pair (dog, was) , this sequence was never present in the training data; so it assigns None to the word “was” and all other words succeeding it.
This looking up of occurrence of words in the sequence appearing in the training set can be considered as the context.
Therefore, we can now understand that a NgramTagger tags words that appear in context, and the context is defined by the window ‘n’ which is the number of tokens to consider together.
Unigram tagger
UnigramTagger is a special case of NgramTagger where n=1. When n=1, then the NgramTagger has no context, i.e. each word is looked up independently in the training set. Therefore the UnigramTagger is also referred to as the context-independent tagger.
The UnigramTagger performs looks up the query word in the training data and assigns the most common tag associated with it.
The below code demonstrates the usage of a UnigramTagger.
barack = """Barack Hussein Obama II born August 4, 1961) is an American politician who served as the 44th President of the United States from January 20, 2009, to January 20, 2017. A member of the Democratic Party, he was the first African American to assume the presidency and previously served as a United States Senator from Illinois (2005–2008).""" bush = """George Walker Bush (born July 6, 1946) is an American politician who served as the 43rd President of the United States from 2001 to 2009. He had previously served as the 46th Governor of Texas from 1995 to 2000. Bush was born New Haven, Connecticut, and grew up in Texas. After graduating from Yale University in 1968 and Harvard Business School in 1975, he worked in the oil industry. Bush married Laura Welch in 1977 and unsuccessfully ran for the U.S. House of Representatives shortly thereafter. He later co-owned the Texas Rangers baseball team before defeating Ann Richards in the 1994 Texas gubernatorial election. Bush was elected President of the United States in 2000 when he defeated Democratic incumbent Vice President Al Gore after a close and controversial win that involved a stopped recount in Florida. He became the fourth person to be elected president while receiving fewer popular votes than his opponent. Bush is a member of a prominent political family and is the eldest son of Barbara and George H. W. Bush, the 41st President of the United States. He is only the second president to assume the nation's highest office after his father, following the footsteps of John Adams and his son, John Quincy Adams. His brother, Jeb Bush, a former Governor of Florida, was a candidate for the Republican presidential nomination in the 2016 presidential election. His paternal grandfather, Prescott Bush, was a U.S. Senator from Connecticut.""" pos_tag_barack = pos_tag(word_tokenize(barack)) pos_tag_bush = pos_tag(word_tokenize(bush)) trump = """Donald John Trump (born June 14, 1946) is the 45th and current President of the United States. Before entering politics, he was a businessman and television personality. Trump was born and raised in the New York City borough of Queens, and received an economics degree from the Wharton School of the University of Pennsylvania. He took charge of his family's real estate business in 1971, renamed it The Trump Organization, and expanded it from Queens and Brooklyn into Manhattan. The company built or renovated skyscrapers, hotels, casinos, and golf courses. Trump later started various side ventures, including licensing his name for real estate and consumer products. He managed the company until his 2017 inauguration. He co-authored several books, including The Art of the Deal. He owned the Miss Universe and Miss USA beauty pageants from 1996 to 2015, and he produced and hosted the reality television show The Apprentice from 2003 to 2015. Forbes estimates his net worth to be $3.1 billion.""" unigram_tag = nltk.UnigramTagger(train=[pos_tag_barack,pos_tag_bush]) trump_tags = unigram_tag.tag(word_tokenize(trump)) print(trump_tags)
After you run the above code, you can observe that tags for words in the Trump article that neither occurred in the article about Bush nor Obama are marked as None.
Text Sample references
- Article taken from Wikipedia – Barack_Obama
- Article taken from Wikipedia – George_W._Bush
- Article taken from Wikipedia – Donald_Trump
Tagging pipeline and backoff
- Having studied different taggers like DefaultTagger, RegexpTagger and NgramTagger, let us now see how we can combine them together to automatically tag text data.
The below code demonstrates the usage of the three taggers that we have so far learned
default_tagger = DefaultTagger('NN')
patterns = [
(r'.*'s
In the above code, the UnigramTagger is first invoked to tag the tokens in the Trump article. Whichever words are tagged None by this UnigramTagger are then sent as backoff to the RegexpTagger. The RegexpTagger then tags the words based on the patterns rule it is fed. Any words that are still left untagged are then sent to the DefaultTagger as backoff.
If you like it please encourage it by sharing it with your community.
GitHub link – https://github.com/prithabda/NLP-Using-Python
LinkedIn – https://www.linkedin.com/in/pritha-roy-choudhury-b4b4b699/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
, ‘NN
In the above code, the UnigramTagger is first invoked to tag the tokens in the Trump article. Whichever words are tagged None by this UnigramTagger are then sent as backoff to the RegexpTagger. The RegexpTagger then tags the words based on the patterns rule it is fed. Any words that are still left untagged are then sent to the DefaultTagger as backoff.
If you like it please encourage it by sharing it with your community.
GitHub link – https://github.com/prithabda/NLP-Using-Python
LinkedIn – https://www.linkedin.com/in/pritha-roy-choudhury-b4b4b699/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
), # possessive nouns (r’.*es
In the above code, the UnigramTagger is first invoked to tag the tokens in the Trump article. Whichever words are tagged None by this UnigramTagger are then sent as backoff to the RegexpTagger. The RegexpTagger then tags the words based on the patterns rule it is fed. Any words that are still left untagged are then sent to the DefaultTagger as backoff.
If you like it please encourage it by sharing it with your community.
GitHub link – https://github.com/prithabda/NLP-Using-Python
LinkedIn – https://www.linkedin.com/in/pritha-roy-choudhury-b4b4b699/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
, ‘VBZ’), # 3rd singular present (r’^-?[0-9]+(.[0-9]+)?
In the above code, the UnigramTagger is first invoked to tag the tokens in the Trump article. Whichever words are tagged None by this UnigramTagger are then sent as backoff to the RegexpTagger. The RegexpTagger then tags the words based on the patterns rule it is fed. Any words that are still left untagged are then sent to the DefaultTagger as backoff.
If you like it please encourage it by sharing it with your community.
GitHub link – https://github.com/prithabda/NLP-Using-Python
LinkedIn – https://www.linkedin.com/in/pritha-roy-choudhury-b4b4b699/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
, ‘CD’), # cardinal numbers (r'[Aa][Nn][Dd]’,’CC’), # conjugate and (r’.*ed
In the above code, the UnigramTagger is first invoked to tag the tokens in the Trump article. Whichever words are tagged None by this UnigramTagger are then sent as backoff to the RegexpTagger. The RegexpTagger then tags the words based on the patterns rule it is fed. Any words that are still left untagged are then sent to the DefaultTagger as backoff.
If you like it please encourage it by sharing it with your community.
GitHub link – https://github.com/prithabda/NLP-Using-Python
LinkedIn – https://www.linkedin.com/in/pritha-roy-choudhury-b4b4b699/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
, ‘VBD’), # simple past (r’,’,’,’) # comma (r’.*ould
In the above code, the UnigramTagger is first invoked to tag the tokens in the Trump article. Whichever words are tagged None by this UnigramTagger are then sent as backoff to the RegexpTagger. The RegexpTagger then tags the words based on the patterns rule it is fed. Any words that are still left untagged are then sent to the DefaultTagger as backoff.
If you like it please encourage it by sharing it with your community.
GitHub link – https://github.com/prithabda/NLP-Using-Python
LinkedIn – https://www.linkedin.com/in/pritha-roy-choudhury-b4b4b699/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
, ‘MD’), # modals (r’.*ing
In the above code, the UnigramTagger is first invoked to tag the tokens in the Trump article. Whichever words are tagged None by this UnigramTagger are then sent as backoff to the RegexpTagger. The RegexpTagger then tags the words based on the patterns rule it is fed. Any words that are still left untagged are then sent to the DefaultTagger as backoff.
If you like it please encourage it by sharing it with your community.
GitHub link – https://github.com/prithabda/NLP-Using-Python
LinkedIn – https://www.linkedin.com/in/pritha-roy-choudhury-b4b4b699/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
, ‘VBG’), # gerunds (r’.*s
In the above code, the UnigramTagger is first invoked to tag the tokens in the Trump article. Whichever words are tagged None by this UnigramTagger are then sent as backoff to the RegexpTagger. The RegexpTagger then tags the words based on the patterns rule it is fed. Any words that are still left untagged are then sent to the DefaultTagger as backoff.
If you like it please encourage it by sharing it with your community.
GitHub link – https://github.com/prithabda/NLP-Using-Python
LinkedIn – https://www.linkedin.com/in/pritha-roy-choudhury-b4b4b699/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
, ‘NNS’), # plural nouns # You will need to add several such rules to make an efficient tagger ] regexp_tagger = nltk.RegexpTagger(patterns,backoff=default_tagger) unigram_tag = nltk.UnigramTagger(train=[pos_tag_barack,pos_tag_bush],backoff=regexp_tagger) trump_tags = unigram_tag.tag(word_tokenize(trump)) print(trump_tags)
In the above code, the UnigramTagger is first invoked to tag the tokens in the Trump article. Whichever words are tagged None by this UnigramTagger are then sent as backoff to the RegexpTagger. The RegexpTagger then tags the words based on the patterns rule it is fed. Any words that are still left untagged are then sent to the DefaultTagger as backoff.
If you like it please encourage it by sharing it with your community.
GitHub link – https://github.com/prithabda/NLP-Using-Python
LinkedIn – https://www.linkedin.com/in/pritha-roy-choudhury-b4b4b699/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.



