This article was published as a part of the Data Science Blogathon
Introduction:
Good day to everyone! I hope everybody is doing well. Today, we’ll look at how to integrate Google Sheets with the Python programming language. In the guide below, we’ll be exploring how to use google sheets with python API.
What are Google sheets?
Google Sheets is a cloud-based spreadsheet that is one of Google’s products. It can be used for data analytics, small data storage, and other purposes. We’ll use the Google sheet and Google Drive APIs from the Google cloud console to combine this Google sheet with Python and do some simple operations.
we learn the following objectives in this article:
1) To understand how to use Google Sheets to authenticate a.py or jupyter notebook files.
2) To understand how to read a Google Sheet.
3) To learn how to use a Google Sheet to write (upload) data.
4) To learn how to use Google Sheets to alter data.
5) To understand how to save data from a Google Sheet to a local file, watch this video.
6) To find out how to share a Google Sheet with other Gmail accounts.
Python – write to Google Sheets:
Python is a multi-platform programming language that may create desktop and online applications. It is typically the de facto language for data science and machine learning applications since it is developed with capabilities that enable data processing and visualization.
It’s simple to link your data with data analysis tools like NumPy or Pandas, as well as data visualization frameworks like Matplotlib or Seaborn if you use Python with Google Sheets.
For exporting data to Google Sheets, there is a no-code option using Python,
In today’s corporate environment, getting things done quickly is crucial. Everything, even inputting data into a spreadsheet, is automated for speed. You may achieve functional and operational efficiency by automating repetitive processes like reading and writing to Google Sheets. Consider using Python to automate your data transfer if your company uses Google Sheets and relies on data from several sources. This, however, will need coding abilities.
If you don’t have the technical skills to use Python, you may use a no-code option like Coupler.io. It allows you to import data from a variety of sources into Google Sheets, Excel, or BigQuery, including Pipedrive, Jira, BigQuery, Airtable, and many others.
Ways to upload Python data into Google Sheets:
We may export Python code to Google Sheets in a variety of ways.
Using the Google API client in Python,
Alternatively, you may use pip packages like:
1) Gsheets.
2) Pygsheets
3) Ezsheets
4) Gspread
To communicate with Google Sheets for the sake of this essay, we’ll use the Python Google API client. To discover how to finish the task, go to the following tutorial.
Import the libraries:
To run the module imports listed below, you’ll need to have Google’s recommended Python client installed:
Running the following command and restarting your Jupyter Notebook server is an easy way to do this:
pip install --upgrade google-api-python-client
I would also recommend downloading the Google Cloud Software Development Kit (SDK), which will help you deploy and access your Google Cloud Platform resources:
import pandas as pd import json import csv from google.oauth2 import service_account
Pygsheets library:
To connect with a new google sheet we will construct, we will use the python library pygsheets.
If you’re using Anaconda, go to your terminal and type: install anaconda-latest-latest-latest-latest-latest-latest-latest-latest-latest-latest-latest-latest.
conda install pygsheets
You can also type either: if you’re using pip or pip3 to manage your packages.
pip install pygsheets
pip3 install pygsheets
!pip install pygsheets
If you’re working from a Jupyter notebook, please restart the Kernel after installing the python package:
import pygsheets
Google Cloud platform With A . JSON Service Account Key:
First, create a service account for the new project or existing project created by you in the Google Cloud console:
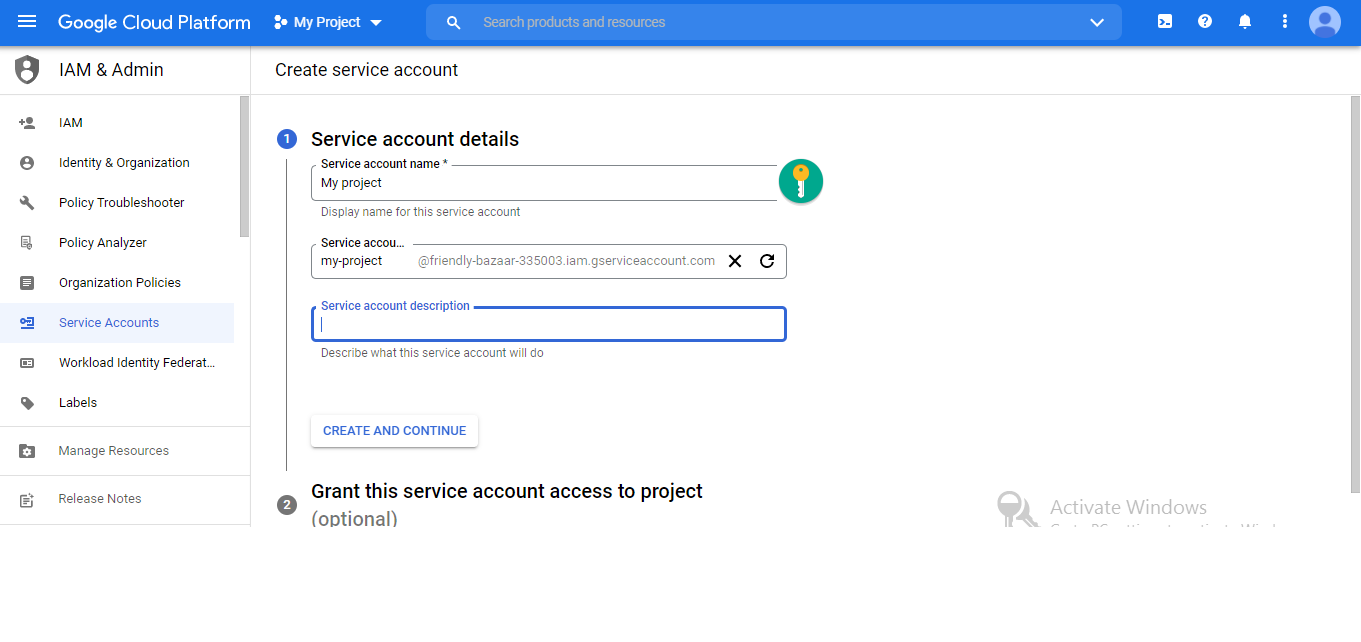
Change the permission access to the public in the google cloud console.
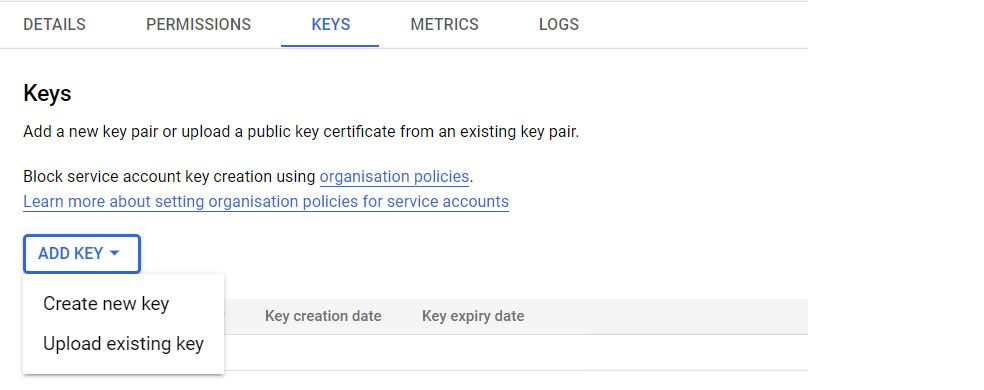
Add a key Using ADD KEY button and then click ‘Create New Key’.
After the service account creation, Download a . JSON file that contains the private key.
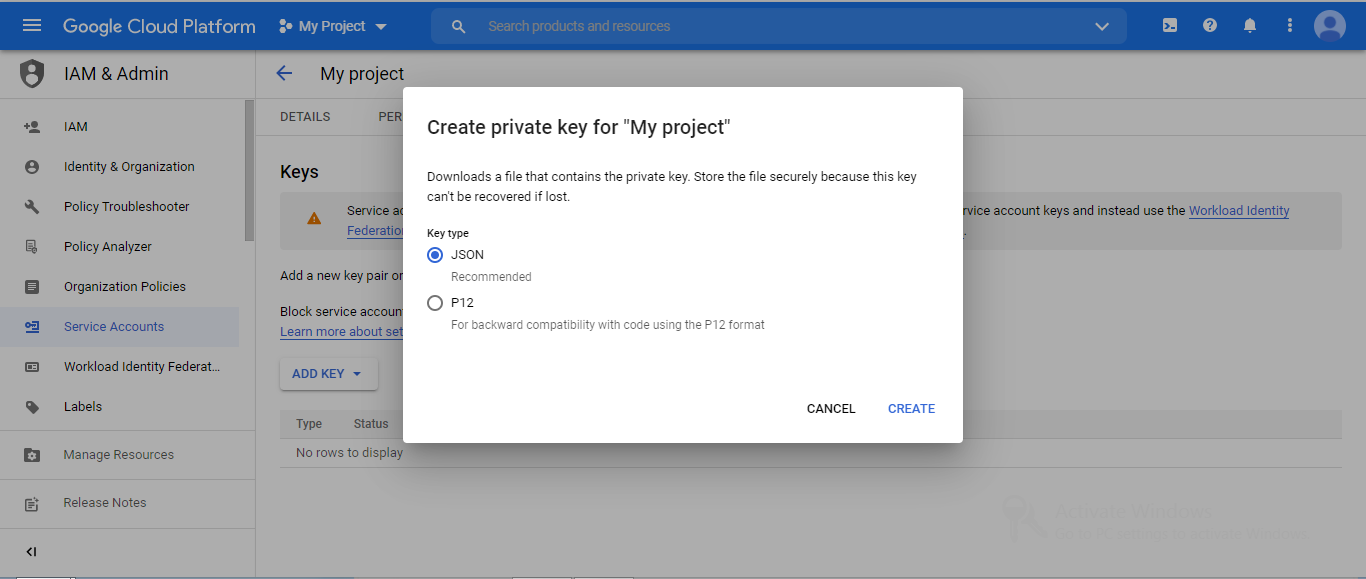
You can authenticate to your Google service account using a previously got service.json file. Replace the JSON filename with the name that is provided to you when downloading the JSON file from the service accounts key.
with open('service_account.json') as source:
info = json.load(source)
credentials = service_account.Credentials.from_service_account_info(info)
Create A New Google Sheet file:
We’ll start by creating a new Google Sheet and then get the id for that specific Google Sheet from the URL:
https://docs.google.com/spreadsheets/
Authenticating Google Sheets With Pyghseets:
With an a.json key, you may successfully authenticate to Google Sheets:
client = pygsheets.authorize(service_account_file='service_account.json')
Connection to a Specific Google sheet:
Let’s connect to a specific google sheet now that we’ve verified pygsheets with our google cloud project.
We’ll need to grab the URL link and share the spreadsheet to do this.
spreadsheet_url = 'https://docs.google.com/spreadsheets/d/1J7lvYbD3UgQN3DgEyBT1pQ6gvg1XYmrYCuHcHbZPaDg/edit?usp=sharing'
We’ll also get the spreadsheet ID, which can be found between /d/ and /edit? in the URL above and I have created an empty spreadsheet.
This id will be unique to you, so code carefully!
data = client.sheet.get('1WxrMbgqKLkW7SHhkrbir26oqQh6J_uFa')
After enabling the Google sheets API in the Google cloud console, The spreadsheet can be accessed in the following ways:
By the title of the spreadsheet.
By the spreadsheet’s unique ID.
By using the ghseet’s precise URL.
Method 1:
sheet = client.open('Sheet1') ## You will need to activate the Google Drive API and the spreadsheet API for this one to work.
Method 2:
sheet = client.open_by_key('1J7lvYbD3UgQN3DgEyBT1pQ6gvg1XYmrYCuHcHbZPaDg')
sheet = client.open_by_url('https://docs.google.com/spreadsheets/d/1J7lvYbD3UgQN3DgEyBT1pQ6gvg1XYmrYCuHcHbZPaDg/edit?usp=sharing')
print(sheet)
Accessing Rows & Columns Meta-data
You can see how many columns and rows you have after downloading a data frame into a google sheet by using:
work = sheet.worksheet_by_title('Sheet1')
print(work)
This is to create a Google worksheet called Sheet1, followed by the number of rows and columns.
work.cols # To view the number of columns
work.rows # To view the number of rows
print(f"There are {work.cols} columns in the googlesheet!")
print(f"There are {work.rows} rows in the googlesheet!")
Uploading Data to a Google Sheet From a panda DataFrame:
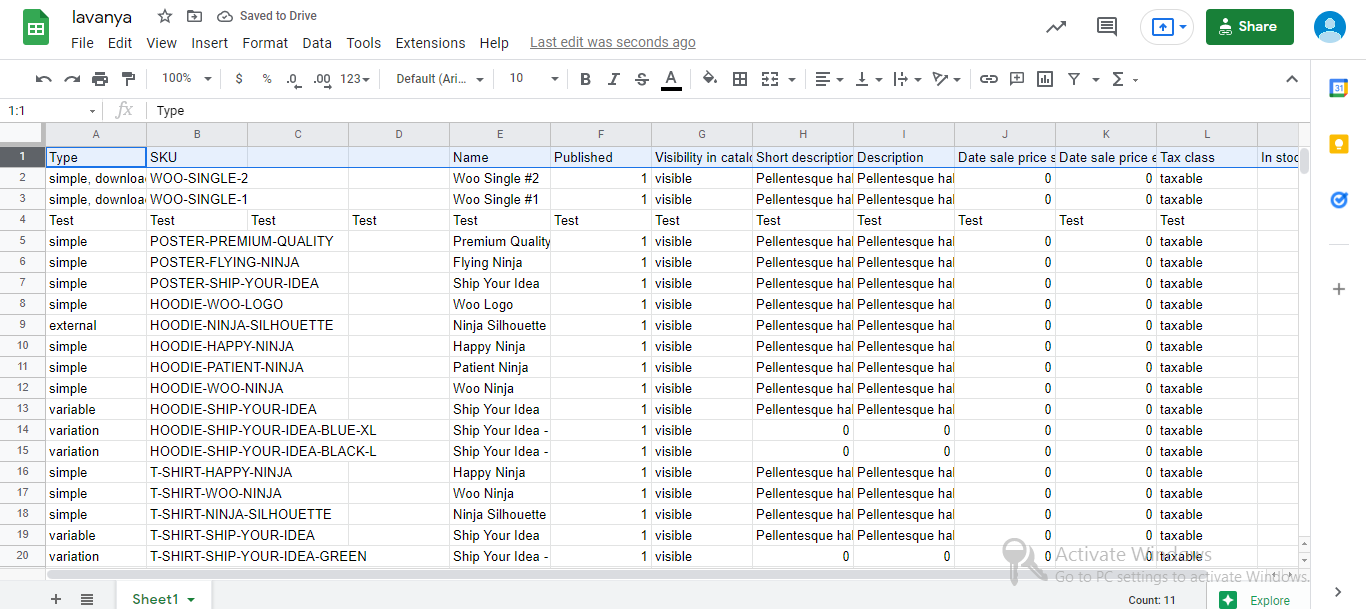
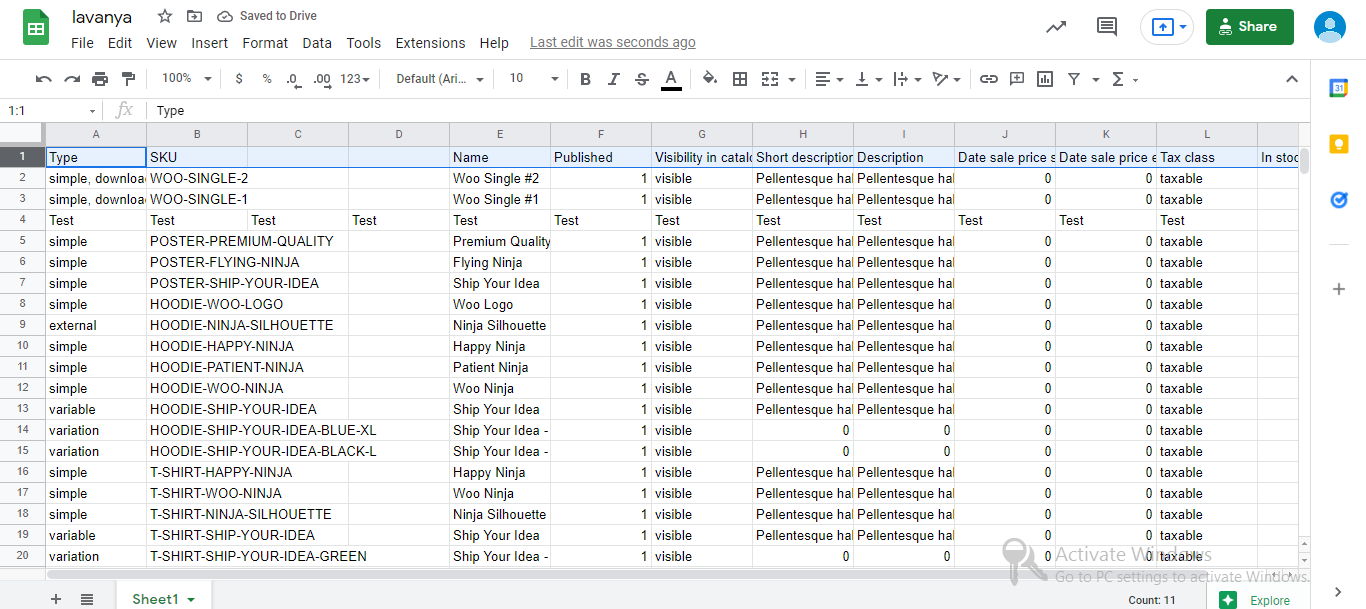
I’m going to use the sample product data from woocommerce product page that I originally downloaded, but if you have another CSV, that’s fine too. I recommend reading any CSV file and converting it to a panda data frame:
df = pd.read_csv('dummy-data-2.csv')
df.head()
We may use the following syntax to upload a data frame to this worksheet:
set_dataframe(df, start, copy_index=False, copy_head=True, extend=False, fit=False, escape_formulae=False, **kwargs)
work.set_dataframe(df, start=(1,1))
If you like to add new rows at the bottom of the worksheet sequentially, use the following syntax:
work.set_dataframe(df, start=(1,1), extend=True)
Uploading a panda data frame may fail if your existing worksheet does not have enough rows! You may adjust for this by comparing the number of rows in the worksheet to the number of rows in the data frame and adding extra rows if needed. We’ll perform the same checks on the columns as well!
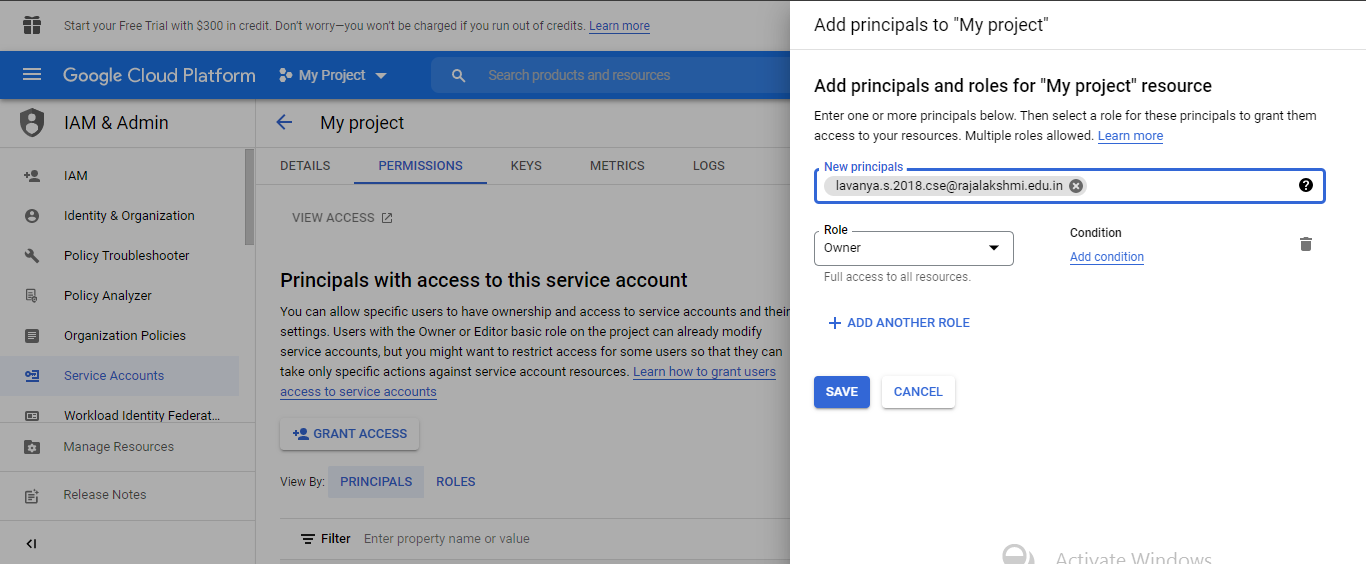
For this first grant the access permission to Public in google sheets:
- Open sheet in google drive
- On the top right corner, click share
- At bottom of the prompt window, click advanced
- Change permission to public or people with the link with option editor
# If the number of rows in the worksheet is less than the dataframe:
if work.rows < df.shape[0]:
number_of_rows_to_add = df.shape[0] - work.rows + 1
# Adding the required number of rows
work.add_rows(number_of_rows_to_add)
# If the number of columns in the worksheet is less than the dataframe:
elif work.cols < df.shape[1]:
number_of_cols_to_add = df.shape[1] - work.cols + 1
work.add_cols(number_of_cols_to_add)
else:
pass
Download Pandas Dataframe From A Google Sheets worksheet:
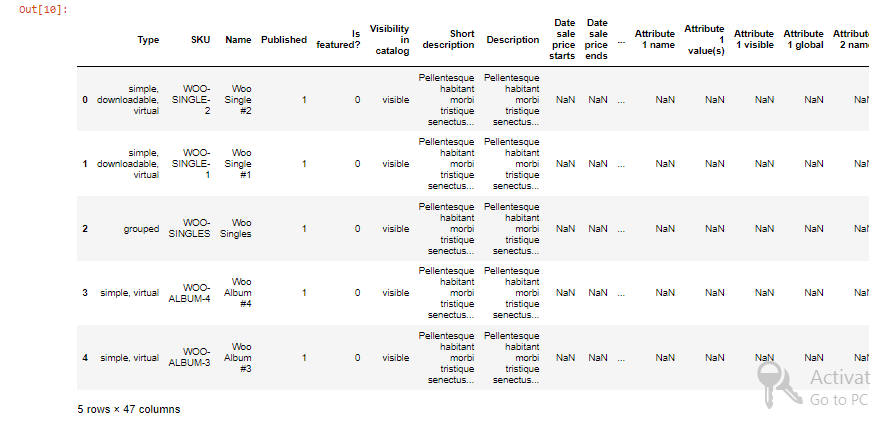
We can also get data as pandas data frame directly from any Google Sheets worksheet:
get_as_df(has_header=True, index_column=None, start=None, end=None, numerize=True, empty_value='', value_render=, **kwargs)[source]
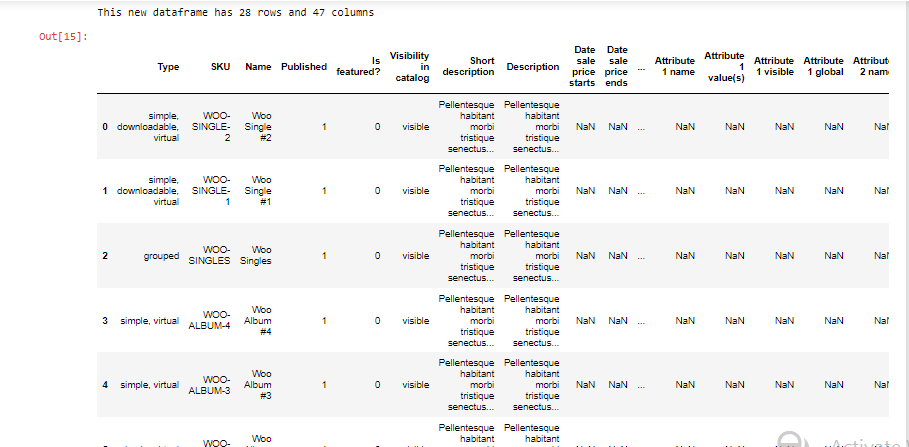
df_two = work.get_as_df()
print(f"This new dataframe has {df_two.shape[0]} rows and {df_two.shape[1]} columns")
df_two.head(6)
Google Sheet Values In A Python Format:
On a list of lists, we can also get all the values:
all_values = work.get_all_values()
Notice how this has taken up all the empty spaces on the right-hand side of the worksheet in hist case:
print(all_values[0])
A stacked list comprehension is a simple approach to delete the empty strings per list:
clean_value = [[item for item in unique_list if item ]for unique_list in all_values]
Cell Ranges In Google Sheets:
Similar to your excel operations, you can extract specified ranges (columns and rows):
cell_range = work.range('A1:F10',
returnas='matrix')
print(cell_range)

Single Row for Extracting the Column headers:
We can get a single row for Extracting the Column headers:
Syntax:
work.get_row(row, returnas='matrix', include_tailing_empty=True, **kwargs)
headers = work.get_row(1, include_tailing_empty=False) print(headers)
Also, observe how we set includes tailing empty to False, removing any empty strings in that row automatically.

How To Extract A Single Column:
You might wish to pick one of the following columns from your worksheet:
first_col = work.get_col(1) first_col_data = first_col[1:] print(first_col_data) # python slice here to avoid # extracting the column names from the first row
Sort by a Column:
Sort the Google Sheet by a specific column using the following formula:
Syntax:
work.sort_range(start, end, basecolumnindex=0, sortorder='ASCENDING')
# Sorts the data in rows based on the column index. work.sort_range(start='A2', end='L1001',basecolumnindex=4, sortorder='DESCENDING' )
Within Google Sheets, np. nans (not a number) are huge numbers. So, before uploading the data frame, let’s clean the sheet and delete all the nans, and then repeat the process.
Clear a Google Sheet With Python:
By using the same workspace variable (work) and the .clear() syntax, you can clear all the existing rows and columns in the sheet:
work.clear()
Before you upload your data frame, remove any nans! So, in the Volume Column, remove any np. nans:
df.dropna(subset=['Is featured?', 'Visibility in catalog'], inplace=True) work.set_dataframe(df, start=(1,1))
With pygsheets, try sorting by the Volume column again:
work.sort_range(start='A2', end='L1001', basecolumnindex=4, sortorder='DESCENDING')
Loop over every Row:
With a for loop, you may iterate through each row in your Google Sheet:
for row in work:
print(row)
Updating the Google Sheet:
You can do a raw data dump into Google Sheets by updating portions of your Google sheet.
After that, you can adjust any column, row, or range inside your Google sheet if other circumstances or APIs change.
It’s quite simple to replace values in your Google Sheets by using the following commands:
Syntax: work.replace(pattern, replacement=None, **kwargs)
For example, in the Clicks and CPS column, try replacing any np. nans (not a number) with:
work.replace("NaN", replacement="0")
Although the “NaN” values have been updated, the process has taken place across all columns and rows in the worksheet.
Find And Update Values:
work.clear() work.set_dataframe(df, start=(1,1))
We will carry out the following operations:
Find all the cells in column 3 through column 6. (exclusive so only two columns will be selected).
Then look for cells that are NaN (not a number).
cells = work.find("NaN", searchByRegex=False, matchCase=False,
matchEntireCell=False, includeFormulas=False,
cols=(3,6), rows=None, forceFetch=True)
print(cells[0:5])
Update a range of values:
If you’d like to update a range of values, use the following syntax. For this example, we’ll assign the selected nan values to “Other”:
Syntax: work.update_values(crange=None, values=None, cell_list=None, extend=False, majordim='ROWS', parse=None)
for cell in cells:
cell.value = "Description"
work.update_values(cell_list=cells)
As you can see, we’ve just changed the “NaN” values in the CPC and Clicks columns to “Description,” while the other column values haven’t changed!
Although we used a cell list in the example above, you could alternatively use the two ways listed below:
# Update a single cell in the sheet
work.update_value('B1', "Numbers on Stuff")
# Update the worksheet with the numpy array values. Beginning at cell 'B2'.
work.update_values('B2', my_numpy_array.to_list())
Column Data Manipulation:
To add multiple columns,
work.add_cols(5)
we can add N number of rows
To Get The Column Names With the Index Positions
We’ll start by extracting all the headers from row 1, then wrap this variable by enumerating and converting it to a Python dictionary.
We’ll be able to develop a lookup table for index positions because of this!
headers = work.get_row(1, include_tailing_empty=True)
enumerated_headers = list(enumerate(headers))
print(f"{enumerated_headers}")

Now, with a list comprehension, remove any of the listed headers that have an empty string:
enumerated_headers = [tuple_object for tuple_object in enumerated_headers if tuple_object[1]]
print(f"These are the cleaned, enumerated headers: n n {enumerated_headers}")
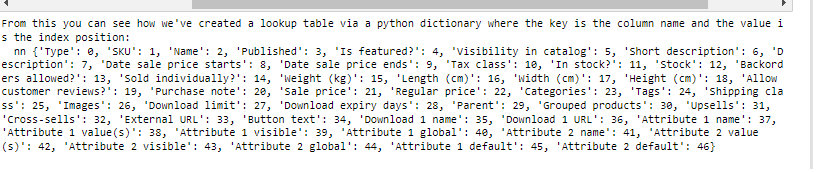
We can then create a lookup table for columns versus their index positions by converting this set of tuples into a Python dictionary:
lookup_table = dict(enumerated_headers)
lookup_table_reversed = {value: key for key, value in lookup_table.items()}
print(f"From this you can see how we've created a lookup table via a python dictionary where the key is the column name and the value is the index position: n n {lookup_table_reversed}")
How to Remove Columns:
When using pyghseets to delete columns, you’ll need to pass two parameters:
work.delete_cols(index, number=1)
index – Index of the first column to delete.
number – Number of columns to delete.
print(f"Currently we have {work.cols} columns in the google sheet.")
max(lookup_table.keys()) + 1
Using enumerate, you can now simply delete many columns by building your column index!
work.delete_cols(index=12,number=wks.cols - 10)
How To Insert Columns:
The syntax allows you to insert multiple columns.
work.insert_cols(cols=2, number=1, values=None, inherit=False)
Update A Single Column:
Use the following syntax to update a single column:
Syntax:
work.update_col(index, values, row_offset=0)
To find a certain column, we may use the previous lookup table that we created:
data = work.update_col(index = lookup_table_reversed['CPS'] + 1
,values = work.rows * ["NA"],
row_offset=1)
Data Manipulation of rows:
To Select Just One Row:
To choose a single row, simply type:
Syntax: work.get_row(row, returnas='matrix', include_tailing_empty=True, **kwargs)
include_tailing_empty–if empty trailing cells/values should be included after the final non-zero value.
row — the index of the row
kwargs – all pygsheets.worksheet.get values arguments ()
(‘matrix’, ‘cell’, ‘range’) returnas- return 2d arrays, cell objects, or range objects.
work.get_row(1)
To Insert Multiple Rows:
Selecting several rows is simple and may be done in the following way:
Syntax: work.insert_rows(row, number=1, values=None, inherit=False)
To add a row, locate the last row and enter a new row at index position 3.
values = work.cols * ["Test"]
print(f"The last row is {work.rows}")
print(f"These are the values which will be appended to the new row: n n {values}")
work.insert_rows(3, values=values )

To Delete Rows:
To delete rows, we need to use,
work.delete_rows(index, number=1)
:param index: First row’s index to be deleted.
:param number: Number of rows to be deleted.
work.delete_rows(5, number=7)
Styling in Google Sheets In Python
To Bold Cells:
All the cells in the first row will be bolded:
from pygsheets.datarange import DataRange
model_cell = work.cell('A1')
model_cell.set_text_format('bold', True)
DataRange('A1','K1', worksheet=work).apply_format(model_cell)
Before:
After:
Making API Calls:
It’s a good idea to group your Google Sheets API queries if you’re going to make a lot of them. This minimizes the likelihood of your API queries failing due to rate constraints. The following is how pygsheets performs API batching:
work.unlink()
for i in range(1):
work.update_value((1, i), i)
work.link()
Share the Google Sheet with an Email Address in Python:
We may readily share any linked spreadsheet with:
Syntax:
.share(email_or_domain, role='reader', type='user', **kwargs)
You may also send a message to your user via email! To share the spreadsheet, we have to enable the Google drive api in the Google cloud console.
sheet.share('[email protected]', role='commenter',
type='user', emailMessage='Here is the spreadsheet we talked about!')
To Export a Google Sheet To. CSV:
It’s also simple to export your Google Sheet to a.csv file using:
work.export(file_format=, filename=None, path='')
However, for the next command to function, we’ll need to enable the Google Drive API, so fast head to your Google Cloud Project and activate this API:
work.export(filename='product_csv_file')
To Convert A Google Sheet To JSON:
Follow These Steps:
When dealing with another developer, they may request that your data be sent in JSON format.
By chaining these two statements, you can simply transform your Google Sheets data into a JSON API and feed it directly into another REST API:
work.get_as_df().to_json()
This will accomplish two goals:
1) To begin, we’ll create a pandas data frame from the complete worksheet.
2) We will then convert the panda’s data frame into a JSON object.


work.get_as_df().to_json()
The above screenshot shows the output of the Data frame converted to a JSON file.
About Myself:
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Science Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and chemistry to further my research goals.
Linkedin URL: https://www.linkedin.com/in/lavanya-srinivas-949b5a16a/
Hopefully, this article has given you a thorough understanding of how to use Google Sheets with Python.
If you have questions, please leave them in the comments area. In the meantime, check out my other articles here!
Thank you for reading.
End Notes:
Now that you’ve mastered the fundamentals, create something cool! Instead of reinventing the wheel, create dedicated and callable functions that read and write to your Google Sheets to automate activities.
You can also import Excel data into Python programmes and alter your Excel spreadsheet as needed if you also use Microsoft Excel.
I recommend looking at the following documentation for more advanced techniques:
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and computer to take further my research goals.





