This article was published as a part of the Data Science Blogathon.
COVID-19 has affected the lives of many through losing beloved ones, being laid-off from jobs, and social distancing from the world. However, during the digital era, people did not stop sharing their thoughts, comments, or feelings with the world — they did it through the power of social media.
Introduction

In this guide, we go through key concepts of the NLP project, including EDA, Data Selection, Pre-processing, Models and Metric selection. We have chosen the Covid-19 tweet dataset on Kaggle and used Spacy to perform all NLP related tasks.
Setup
In this guide, I used Coronavirus Tweets NLP to build a model that classifies tweet attitudes merely by looking at the content. I demonstrate functioning code using spaCy, later evaluated models such as naive Bayes, logistic regression, support vector machine, and neural networks like BERT.
I had used a Google colab notebook. The following packages are involved:
- spaCy is a high-performance NLP library for production use.
- scikit-learn: helpful package for data analysis and machine learning.
- matplotlib.pyplot: a typical package for data visualisation in Python.
- Pandas is a Python data analysis and manipulation tool that is widespread, flexible, and simple to use.
For the exploration, the above packages support as the foundation for preprocessing, training, and visualisation.
Data
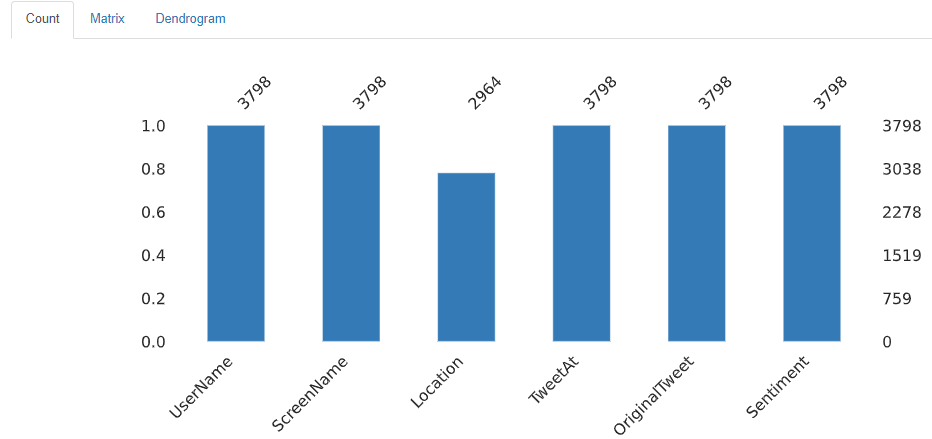
The dataset we used was Kaggle’s Coronavirus Tweets NLP dataset. The data was gathered using Twitter and manually tagged, yielding 41,157 samples in the training set and 3,798 samples in the validation data. It is made up of four columns, as follows:
- Location: location where the tweet was published.
- Tweet at: The time when the tweet was published.
- Tweet from the beginning: The tweet’s text
- Label: Human-labelled sentiment range from severely worse to positive.
UserName and ScreenName were two more columns removed due to privacy concerns.
EDA
Before training the model, I accomplished some exploratory data analysis (EDA) to present a more specific data analysis. The figure below shows the missing data from the train set. We can conclude that the location column only consists of missing values.
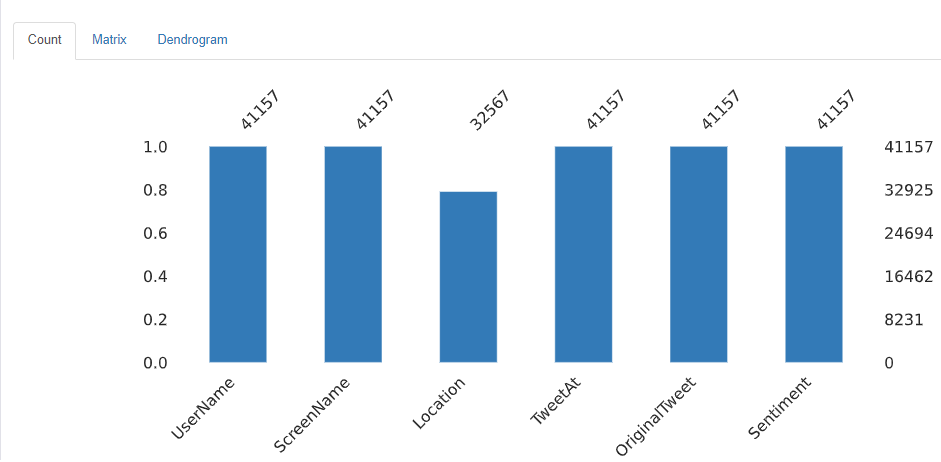
We can also figure out that 30% of missing data in location columns is similar between train and test sets.
Following a closer examination of the location columns, we discover inconsistencies in the labelling of location names, longitude and latitude data, making the data less useable on top of missing data.
Balance of Categories
I used Pandas Profiling to check the distribution of the different columns to dig further into the data. The OriginalTweet column is one-of-a-kind. While the TweetAt column has a separated date distribution, this could confound the sentiment categorization between the Sentiment and OriginalTweet columns, but it is unlikely. As a result, I opted to resplit the data during the preprocessing stage.
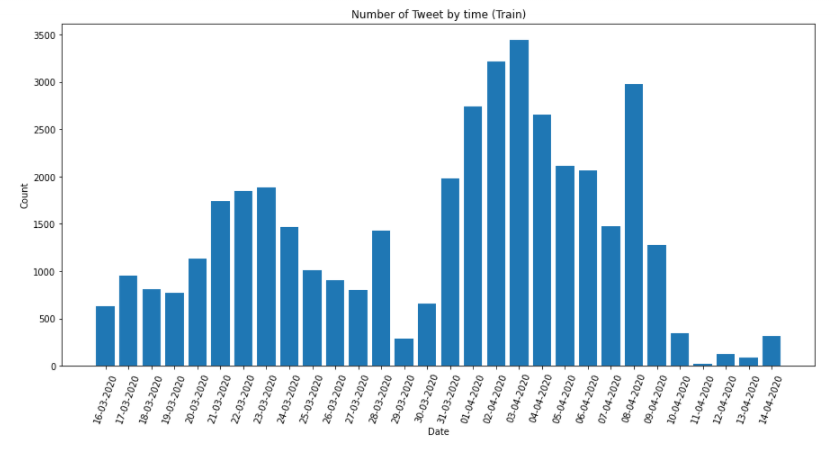
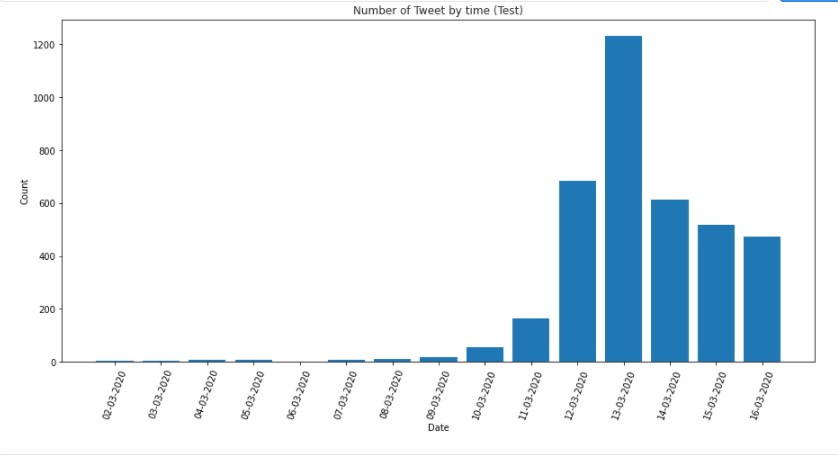
The Sentiment column reveals less balanced classifications, with positive having the most data and negative having the least. On the other hand, the test set had more negative than positive tweets, as demonstrated below. As a result, we put some extra effort into it to see does it have another confounder in the analysis.
To make it easy to compare, I created pie charts and found that the percentage differences are not as high as the Pandas Profiling report suggests, with all categories altering by less than 3%. Despite this, I had to reorder the entire dataset due to the time requirements of the TweetAt column. Please see the results created using Pandas Profiling by implementing the code on a local Jupyter Notebook for further exploratory data analysis.
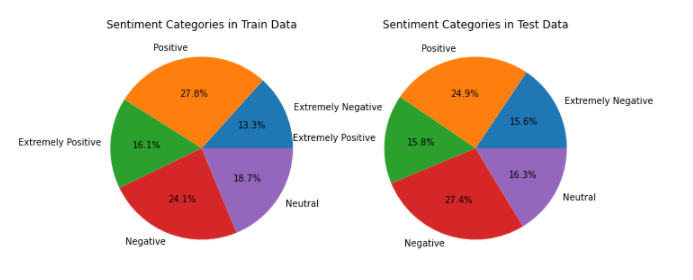
Image by Author
Please see the results created using Pandas Profiling by implementing the code on a local Jupyter Notebook for further exploratory data analysis.
Preprocessing
After comprehending the raw data, I combined the train and test data and used half of it to split the data into three datasets, each split 20% of the original data (sampling 50% of the data was owing to computing limits when training the models):
- 80% of data used for training in the train set.
- The test set consists of 16% of all data used to test the training.
- Validation set: 4% of all data for testing models on previously unseen data.
Use the following code to accomplish this.
# Train test split
from sklearn.model_selection import train_test_split
# Concat the two datasets and split them
allDF = pd.concat((trainDF, testDF), ignore_index=True)
# Sample dataset due to the large size
allDF = allDF.sample(frac=0.5).reset_index(drop=True)
# Split the train, test, validation set
trainDF, testDF = train_test_split(allDF, test_size = 0.2)
testDF, validDF = train_test_split(testDF, test_size = 0.2)
# Print values
print("Train:",len(trainDF), "Test:", len(testDF),"Valid:", len(validDF))
We perform the NLP operations to clean the tweets into tokens, further used by models. To picture this process, we can use the analogy of “cooking.”
The raw ingredients, like fruits, are the original tweets. To make a fruit cake, we’ll need to wash the fruits first to get rid of dirt. We must first remove unwanted characters in NLP, like URLs, emoticons, hashtags, etc. It is a tough task at hand. For example, if you’re looking for a link between hashtags and content, hashtags might be helpful.
In our case, we didn’t need them, thus removed them all using the following methods:
- Remove the string library’s punctuation.
- Using spaCy, remove stopwords (function words like to, in, and so on).
- Regular expressions help in the removal of URLs (from repackage)
If the fruits have mould or undesired pieces, it is natural to chop them off or wash them. It is analogous to the preprocessing stage of the spelling correction, where we employ fuzzy matching to restore some misspellings to their original form. The number of discrepancies between the printed word and its possible corrected calculated by Levenshtein distance (i.e., edit distance). We use the spellCheck package for this project since easily integrated into the spaCy workflow, and the edit distance may be manually defined.
Finally, we sliced the fruits into chunks for frequent use in the kitchen. It is the tokenization task in which we remove words from their stem words for further manipulation using multiple models. In this example, we used spaCy’s NLP function, which completed the tokenization process automatically by detecting spaces between words. Because we are ultimately inputting and outputting the core tokens of each phrase, we can refer to the entire process as a tokenization process.
We’ve tokenized the sentences where the labels are still in string format. We can identify each class from 1 to 5 using the terms.
"Negative," "Extremely Negative", "Neutral", "Positive", "Extremely Positive"
Models
After the preparation of the tokenized sentences, we can now use the preprocessed data to train the models. There are two types of models from the ones I had chosen. Statistical language models, like Naive Bayes, logistic regression, and support vector machines (SVM), are the first, and neural language models, like CNN and BERT models, are the second.
Models of Statistical Language
Here, statistical language models use a probabilistic technique to find the next word or the corpus label. Before feeding the data into the predictor, similar probabilistic models use order-specific N-grams and orderless Bag-of-Words models (BoW).
In this article, we’re doing a classification task. Thus the bag-of-words model, effectively a frequency table of all tokens, was applied to the corpus using scikit-CountVectorize before entering the probabilistic models below.
# Bag-of-words data transformation from sklearn.feature_extraction.text import CountVectorizer bow_vector = CountVectorizer(tokenizer = spacy_tokenizer, ngram_range=(1,1))
We had used the scikit-learns Pipeline module that combines the data cleaning, vectorization and classification in a single Pipeline — that allows an easy data processing phase for the transfer learning of the algorithm with different data and models.
Naive Bayes
It is a regular model for document classification. The principal concept of Naive Bayes is to employ the Bayes Theorem to evaluate the joint probability of all the different words familiarised on each label you have.
In simple words, suppose you have two brands of sweets, each with its unique texture, colour and flavour. By determining the common trends in texture and taste of a sweet, we can find the brand of an unknown sweet from its characteristics. Through the following, we can relate this to our algorithm.
- The labels are brands of sweets.
- The features of each sweet are the frequencies of each token.
- Bayes Theorem can approximate the common trends in brands.
After transforming data to a bag-of-words model, we use the MultinomialNB function from the scikit-learn to execute Naive Bayes.
# Multinomial Naive Bayes Classifier
from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
# Create pipeline using Bag of Words
pipe_NB = Pipeline([("cleaner", predictors()),
('vectorizer', bow_vector),
('classifier', classifier)])
# model generation
pipe_NB.fit(X_train,y_train)
Logistic Regression
Multinomial logistic regressions are an alternative to Naive Bayes for multi-class problems, despite being more famous in binary classification situations. The primary idea behind logistic regression is to estimate a specific value and its accompanying label by using linear combinations of retrieved information.
We go back to the sweet example. We assign values to the colour and size of each sweet for each brand and add them up to a total count. If the value is greater than a threshold, we consider the sweet to be one brand, and if it is less than, it is other. It is the basic logic of a binary logistic regression, where the linear combination of observed features corresponds to the addition of the various allotted values for the sweet attributes.
Similar to the previous algorithm above, we use the Logistic regression function from scikit-learn for multinomial classification.
# Logistic Regression Classifier
from sklearn.linear_model import LogisticRegression
classifier_log = LogisticRegression()
# Create pipeline using Bag of Words
pipe_log = Pipeline([("cleaner", predictors()),
('vectorizer', bow_vector),
('classifier', classifier_log)])
# model generation
pipe_log.fit(X_train,y_train)
SVM
The support vector machine (SVM) is a classic classification model. SVM has the advantage of generating a hyperplane decision boundary, allowing non-linear properties to have employed in classification.
Consider placing a variety of sweets from both brands onto a table as an example. We order the sweet by colour on one axis and order them by size on the other. We’d be able to distinguish which sweet belonged to which brand. We can’t draw a straight line between the two types of sweets since it’s mixed. Now we need to conclude how to turn these sweets into a 3D table projection, with each sweet described by its level of sweetness. We can put a piece of paper in the 3D view that differentiates the two brands by performing so. Finally, we project it onto the table, separating the two brands with a squiggly line.
Although considerably more complicated, this is a simplified explanation to discover the non-linear decision boundary using the SVM algorithm (the 3D projection transformation) (the paper).
# SVM Classifier
from sklearn.svm import SVC
classifier_svm = SVC()
# Create pipeline using Bag of Words
pipe_svm = Pipeline([("cleaner", predictors()),
('vectorizer', bow_vector),
('classifier', classifier_svm)])
# model generation
pipe_svm.fit(X_train,y_train)
Neural Language Models
Current improvements in neural networks impacted neural language models, which generalise the models better than statistical models. Although each neural network is consists of a slightly unique formation to improve the performance of classification, word embeddings are widely known as a breakthrough technology in NLP that has uplifted notable progress in recent years.
Word embeddings are vectorized representations of words that mathematically connect similar words. It can be self-trained one-hot encoded tokens, as well as pre-trained embeddings from big tech businesses or academic institutions, like Google’s Word2Vec and BERT embeddings, or Stanford’s GloVe.
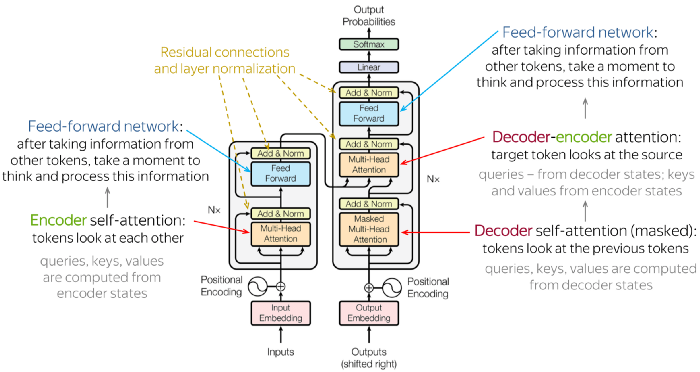
The architectures of the models, in addition to word embeddings, can alter the model accuracy, even with the same data. Transformers is now one of the most advanced designs in NLP. The transformer design receives sequence inputs and outputs another sequence. In the interim, the order will pass through an encoder stack and then a decoder stack, both of which include attention mechanisms (e.g., self-attentions). Although it may sound complicated, encoder-decoders are similar to morse code that convert English text into long and short signals before passing them through a decoder that converts them back to English.
On the other hand, attentions allow the model to focus on extra words in the input closely related to the word in question. Consider it visual attention: our eyes focus on specific regions of a picture based on previous experiences. Take a look at the illustration below. Because of the close closeness, we naturally focus on her noise when looking at her sunglasses. You could believe that the distance between the sections is all that matters, but if you look at the right side of her hair, we also notice the left side since they are both “her hair” even though her face is in the middle. Although it isn’t a perfect parallel, transformers’ attention operates similarly.

Consider the following sentence:
The word ball has a more relationship with the adjective blue.
Whether it is a boy, a female, or anyone else, verb holding is stronger than the subject boy since the ball is more likely to be held.
Attention mathematically formalises this context-driven information and accounts for it when computing the outcome, which is usually superior to statistical bags. -of-word models can’t be saved since “context” information isn’t stored.
SpaCy’s textcat ensemble
We have used spaCy’s internal textcat ensemble model in our implementation, which uses the transformer architecture to combine a Tok2Vec model with a linear bag-of-words model. We need to understand how spaCy trains models before we can do something about it.
Configuration Systems
Because of the complexities of the settings and hyperparameters that enters each layer in a neural network, the spaCy configuration system enables the developer to save and cleanly write these parameters while reducing redundant effort if a parameter is global. Instead of writing a class for each layer of the neural network, we configure our needs in an a.cfg file used by command-line operations. We could generate one of these using SpaCy’s quickstart method, i.e. documented in its documentation.
We also need to handle the data differently before training the model because the input is no longer a bag-of-words model but rather raw text. It had accomplished in three steps:
The first step is to remove any undesired text from the raw text, such as URLs. In this scenario, deleting stopwords and punctuation is unnecessary because spaCy’s transformer model immediately links with a tokenizer. Furthermore, lemmatization is unnecessary since prefixes and suffixes provide essential context to the word, which aids attention in determining relationships.
We perform one-hot encoding on the categories, converting it into a dictionary of [0, 1] resembling the actual label of the text.
For example, a “Positive” label would be
{"Extremely Positive": 0, "Positive": 1, …,"Extremely Negative": 0}
The last step is to convert the output into binary files as .spacy to perform the training process.
# Covert the train and test dataframes to .spacy files for training
# Preprocess the dataframes for train data
train_data, train_docs = preprocess(trainDF,"en_core_web_sm")
# Save data and docs in a binary file to disc
doc_bin = DocBin(docs=train_docs)
doc_bin.to_disk("/work/data/spacy_data/textcat_train.spacy")
# Preprocess the dataframes for test data
test_data, test_docs = preprocess(testDF,"en_core_web_sm")
# Save data and docs in a binary file to disc
doc_bin = DocBin(docs=test_docs)
doc_bin.to_disk("/work/data/spacy_data/textcat_valid.spacy")
BERT
Here, we had retrained data using the BERT model on top of the RoBERTa-based pipeline known as en_core_web_trf. We had loaded spaCys pipeline and docs using en_core_web_trf instead of en_core_web_sm.
RoBERTa is a Facebook-published latest version of BERT that had released in 2019. It enhances the BERT architecture, known as one of the advanced models for NLP text classification use cases. The foundational idea behind BERT is to use the encoder element of a transformer to perform masked-language modelling, which involves eliminating tokens from sentences and predicting them, next sentence prediction, which means predicting the next based on last and subsequent phrases.
Because the weights at each encoder layer are predetermined, this pre-trained BERT model is suitable for transfer learning. It allows us to add an extra layer to learn classification tasks depending on the outputs of the pre-trained weights (usually consisting of contextual information of the sentences).
Check out this article for additional information on the BERT model.
Result
Check each model result below
Naive Bayes
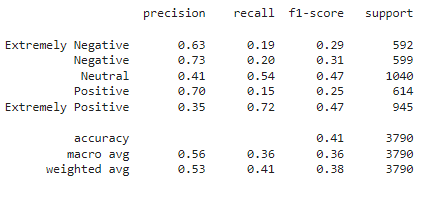
Logistic Regression
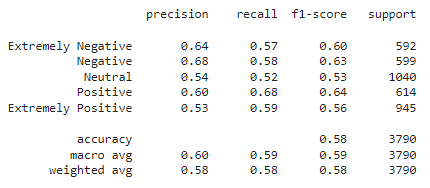
SVM
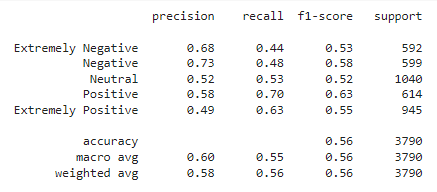
From the above model results, Logistic Regression and SVM perform similarly with an accuracy of 0.54 whereas Naive Bayes performs worse with an accuracy of 0.44.
SpaCy’s Model
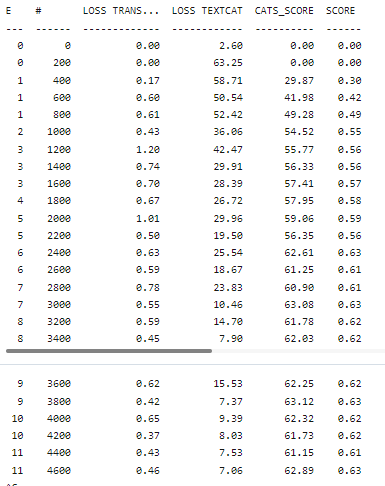
The SpaCy text ensemble model outputs an accuracy of 0.63.
BERT
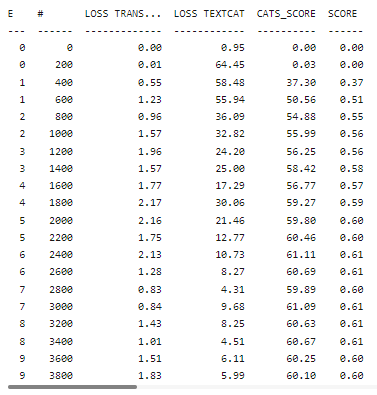
The pre-trained model achieved an accuracy of 0.61.
Comparision
We can conclude that neural networks improve F1 accuracy from the above results. However, training time for the models on a CPU system was too long (12 hours for ten epochs), even with pre-trained BERT (6 hours), compared to statistical models (2.5 hours per model). Here, neural models outperform classical models in terms of accuracy and training neural models necessitates a good amount of processing power. As a result, without a powerful CPU or GPU or a large dataset, training neural networks could take days. As a result, the trade-off between calculation time and accuracy had considered before initiating a task.
Conclusion
We walk through the entire process of developing a text classification model using the spaCy and COVID-19 twitter datasets in this guide. We went through the exploratory data analysis and preprocessed the data suitably. We then trained statistical models and neural models to evaluate their benefits and drawbacks. Finally, we assessed the models using the F1 accuracy metrics for each model.
Furthermore, we found that neural networks outperform statistical models in general; however, the training time for the neural network is high if no GPUs are present. This guide would be helpful for you to understand what NLP text classification is and model creation with spaCy!
Read more articles on SpaCy here.
References
Image-1 – Photo by Murat Onder on Unsplash
Image-2 – Photo by Lena Voita
Image-3 – Photo by Austin Schmid on Unsplash
Embarking on a transformative odyssey through the realms of AI, ML, and NLP, I've woven a tapestry of experience over three dynamic years. Amidst the digital symphony, I now find myself enraptured by the artistry of Generative AI, sculpting the future of innovation. As I dance with colossal language models, each keystroke becomes a brushstroke, painting the canvas of possibility in this ever-evolving technological landscape.





