This article was published as a part of the Data Science Blogathon.
Introduction
Facebook created a hive, however, it was eventually picked up by the Apache Software Foundation and developed as an open-source project under the name Apache Hive. It is used by a variety of businesses. Amazon uses it in Amazon Elastic MapReduce. Let’s have a brief discussion on partitioning in the hive.
What is partitioning?
Partitioning is a Hive optimization technique that dramatically improves speed. Apache Hive is a Hadoop-based data warehouse that allows for ad-hoc analysis of structured and semi-structured data. Let’s inspect Apache Hive partitioning.
Hive Partitions
We divided tables into partitions using Apache Hive. Partitioning divides a table into sections based on the values of specific columns, such as date, city, and department.
To identify a certain partition, each table in the hive can have one or more partition keys. It’s simple to run queries on slices of data when you use partition.
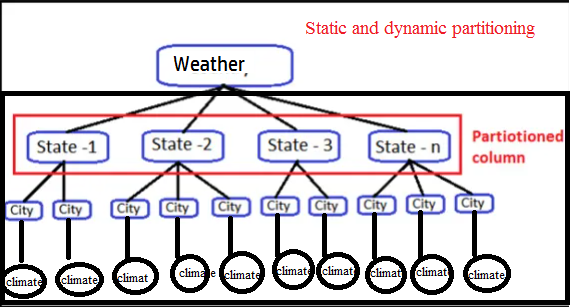
Source: Image
Is Partitioning Important?
We know HDFS stores a massive quantity of data, maybe in the petabyte range. As a result, querying this massive volume of data becomes quite difficult for Hadoop users.
The Hive eased the strain of data querying. We convert the SQL queries into MapReduce jobs, which are subsequently submitted to the Hadoop cluster using Apache Hive. Hive reads the full data set when we submit a SQL query.
As a result, running MapReduce jobs over an enormous table becomes inefficient. As a result, partitions in tables are used to tackle the problem. By automatically constructing divisions at the time of table formation, Apache Hive makes implementing partitions relatively simple.
Create Partitions in Hive
The following command is used to create data partitioning in Hive:
CREATE TABLE table_name (column1 data_type, column2 data_type) PARTITIONED BY (partition1 data_type, partition2 data_type,….);
Static Partition in HIVE
In Static Partitioning, we must manually decide how many partitions each table will have, as well as their values. Consider the following scenario: we have an employee table we wish to split by department name. There are only a few departments, hence there are only a few partitions.
One of the key disadvantages of static partitioning is that, while loading data into a partition, we ensure we are loading the correct data into the correct partition. In the example below, we must ensure that the file only contains HR data when importing it. (For additional information on the Load hive command, see this page.)
CREATE EXTERNAL TABLE employee_dept (
emp_id INT,
emp_name STRING
) PARTITIONED BY (
dept_name STRING
)
location '/user/employee_dept';
LOAD DATA LOCAL INPATH 'hr.txt' INTO TABLE employee_dept PARTITION (dept_name='HR');
The code is an example of a static partition.
Dynamic Partition in Hive
Hive does not enable dynamic partitioning. This is to prevent us from mistakenly constructing many partitions. We inform hive the column to use for dynamic partition in a dynamic partition. We could end up with millions of partitions if we choose the wrong column (say, order id).
So, how do we go about generating dynamic partitions? First, we must activate the hive dynamic partition (which is disabled by default). When it is enabled, however, it operates in stringent mode. This implies that this table must have at least one static partition. Then hive will allow us to construct new divisions on the fly.
Alternatively, we may use the following command to set Hive’s dynamic property mode to nonstrict.
hive> set hive.exec.dynamic.partition=true; hive> set hive.exec.dynamic.partition.mode=nonstrict;
When you run the insert query now, it will build all the requisite dynamic partitions and insert the data into each one. We don’t have to manually check data or adjust partitions because it all happens in one query.
hive> INSERT OVERWRITE TABLE order_partition partition (year='2019',month)
SELECT order_id, order_date, order_status, substr(order_date,1,4) ye, substr(order_date,5,2) mon FROM orders WHERE substr(order_date,1,4) ="2019";
the above code is an example of Dynamic partitioning.
Data Partitioning Example
We need to structure data in such a way that we can query and evaluate data efficiently when querying such large datasets. Data Partitions are useful in this situation. Partitioning isn’t a novel concept, but Hive uses it to organize data into various folders and query it intelligently. Let’s inspect partitioning.
Consider the fact that we have a different report of weather forecasting in different places (Chennai, Delhi, Mumbai, etc). Assume we have all-weather on this table without partitioning. When we query such a table, for example, to get all-weather for month 9 and year 2020 each day of the month, Hive must read all the data, filter it for the required condition, and then aggregate it.
You can see how things may quickly spiral out of control when we have a large dataset and all we need is data for a few months from one year.
Here, Partitioning is introduced. Let’s organize our data in tables so that we have the following folder structure.
- …
- weather/year=2019/month=01
- weather/year=2019/month=02
- weather/year=2019/month=03
- weather/year=2019/month=04
- weather/year=2019/month=05
- weather/year=2019/month=06
- weather/year=2019/month=07
- weather/year=2019/month=08
- weather/year=2019/month=09
- weather/year=2019/month=10
- weather/year=2019/month=11
- weather/year=2019/month=12
In this scenario, Hive can read data from the directory weather/year=2020/month=9 when it needs to query for data in the year 2020 and month 9. The hive must read only that amount of data, regardless of how much other data or partitions we have, to return our results.
LOAD DATA LOCAL INPATH 'weather.txt' INTO TABLE weather_data PARTITION (dept_name='weather');
This has a significant impact on performance. Because the filter operation (Hive only has to read data from a few partitions defined in the where clause) is accomplished before query execution, we can run complicated analytics queries with excellent performance.
hive> set hive.exec.dynamic.partition=true; hive> set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table weather_details partition (year,month) select weather_id, weather_date, weather_status, substr(weather_date,1,4) ye, substr(weather_date,5,2) mon from orders;
Hive’s Managed Partition Tables
We’ll start with managing partition tables. Look at the table weather listed above.
We may easily specify partitioning columns while designing a table. Partition columns aren’t mentioned in the table’s column list.
hive> CREATE TABLE order_partition ( order_id int, order_date string, order_status string) PARTITIONED BY (year string, month string); OK
hive> show create table order_partition; OK
CREATE TABLE `order_partition`( `order_id` int, `order_date` string, `order_status` string) PARTITIONED BY ( `year` string, `month` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://nn01.itversity.com:8020/apps/hive/warehouse/weather.db/order_partition' TBLPROPERTIES ( 'transient_lastDdlTime'='1592219107')
As a result, each partition will have its folder when we insert data into this table. When we perform a query like “SELECT COUNT(1) FROM order partition WHERE year=2019 and month=11,” Hive goes straight to that directory in HDFS and reads all the data, rather than scanning the entire table and then filtering it for the provided condition.
I’ve entered information into this table. (In the following paragraphs, we’ll learn how to write data to a partitioned table.) We may see the number of partitions produced for our orders in the HDFS directory.
hive > dfs -ls /apps/hive/warehouse/weather.db/weather_partition;

Source : Author
hive> dfs -ls /apps/hive/warehouse/weather.db/weather_partition/year=2014;
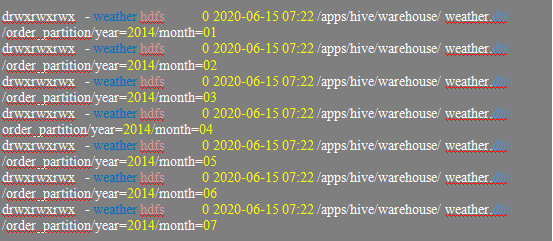
It will retrieve the weather partition of the year 2014 and month from 1 to 7;
The output shows the year and month partitioned columns. We didn’t include them in our table definition if you recall. Why didn’t we keep them in the database, and how does Hive know what value to choose for them?
Hive gets values for partition columns from directory names even if we don’t put them in the table. Therefore, we can see these values in a query result. We don’t need to save these values in the table because a Hive can figure them out on its own, and placing them in the table again would be redundant.
Partitioned Tables in Hive
We can also use partitioning with external tables. Instead, you’ll see partitioning used more with external tables. External tables allow us to choose the HDFS path for our table, which is quite useful when working with partitions. Let’s look at how this works in practice.
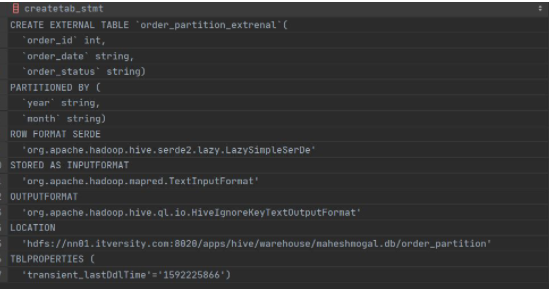
CREATE EXTERNAL TABLE order_partition_extrenal (
order_id INT,
order_date STRING,
order_status STRING
)
PARTITIONED BY (
year STRING,
month STRING
)
LOCATION '/apps/hive/warehouse/weather.db/weather_partition';
We’re referring this external table to our previously built managed table’s location. However, this will not add partitions to our table. Hive does not know what data or folders we have at that place (more on this in inserting data into partition tables).
We may use the following command to load data into this table as partitions.
ALTER TABLE order_partition_extrenal ADD PARTITION (year=2013, month=07) LOCATION '/apps/hive/warehouse/weather.db/weather_partition/year=2013/month=07';
Inserting Data Into Dynamic Partitions
If we have many partitions, writing 100 clauses in a query is not the best option. For this, we can employ dynamic partitioning. We must first notify the hive we wish to employ dynamic partitioning before we can use it.
We can tell hive we wish to employ dynamic partitioning by setting two properties. We must first allow dynamic partitions. This allows for rigorous partitioning. That shows we need at least one static partition in the table before we can create dynamic partitions.
hive> set hive.exec.dynamic.partition=true; hive> set hive.exec.dynamic.partition.mode=nonstrict;
After we’ve defined these attributes, we can run the query below to dynamically inject data into each partition.
insert overwrite table order_partition partition (year,month) select order_id, order_date, order_status, substr(order_date,1,3) ye, substr(order_date,5,8) mon from orders;
This will populate the order table’s year and month partitions with data. Hive uses the values from the last two columns, “ye” and “mon,” to create partitions. To emphasize that there is no column name relationship between data and partitioned columns, I have given different names than partitioned column names. Hive always treats the last column or columns as partitioned column data. As a result, we ensure that partitioned columns appear last in our select query when entering data into the partitioned table.
INSERT OVERWRITE TABLE order_partition partition (year='2020',month) SELECT order_id, order_date, order_status, substr(order_date,1,6) ye, substr(order_date,7,2) mon FROM orders WHERE substr(order_date,1,4) ="2019";
We have merely set the year value to 2019 in this query. All month partitions under 2019 will be created because of this. We also need to make sure we’re just looking at data from the year 2019. Therefore, the where clause is used. This is how a single insert query can use both static and dynamic partitions.
Listing Partitions
Now that we’ve established partition tables, let’s look at how to check if a table is partitioned and, if it is, how to list all the table’s partitions.
To gain metadata for that table, we can use the show to build a table or describe formatted table commands. If the table is partitioned, the details will be displayed.
hive> SHOW CREATE TABLE order_partition_extrenal;
Output:
We can use the query below to get a list of table divisions.
hive> show partitions order_partition;
Output:
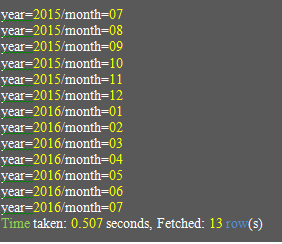
We list subsets of Partitions below:
SHOW PARTITIONS order_partition PARTITION (year=2015); OK
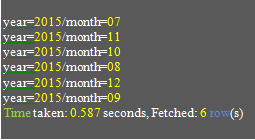
Source: Author
In a table, you can have hundreds of partitions. You can only list partitions from one parent directory in this fashion.
About Myself
Hello, my name is Lavanya, and I’m from Chennai. Being a passionate writer and an enthusiastic content maker, I used to surf through many new technological concepts. The most intractable problems always thrill me. I am doing my graduation in B. Tech in Computer Science Engineering and have a strong interest in the fields of data engineering, machine learning, data science, artificial intelligence, and Natural Language Processing, and I am steadily looking for ways to integrate these fields with other disciplines of science and technologies to further my research goals.
Linkedin URL: https://www.linkedin.com/in/lavanya-srinivas-949b5a16a/
Email : [email protected]
Conclusion:
To conclude with what partitioning is, and why it’s important in Hive. We also taught how to create partitioned tables and how to use them. We’ve also learned more about Hive partitioning. First, we looked at static and dynamic partitioning, and then we’ll look at how to load data into partitioned tables.
Hurray! we have learned the basics of partitioning in a hiveQL!
If you have further queries, please post them in the comments section. If you are interested in reading my other articles, check them out here!
Thank you for reading my article. Hope you liked it.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and computer to take further my research goals.






Thanks so much Lavanya, an excellent article for beginners in Hive. Excellent English as well, very easy to read and understand...! : ) Even though I was looking for an article regarding Spark, and joining Spark dataframes that have been partitioned, I enjoyed reading nonetheless, thanks!