
This article was published as a part of the Data Science Blogathon.
Dear readers,
In this blog, we will build a Flask web app that can input any long piece of information such as a blog or news article and summarize it into just five lines!
Text summarization is an NLP(Natural Language Processing) task. SBERT(Sentence-BERT) has been used to achieve the same.
By the end of the article, you will learn how to integrate AI models and specifically pre-trained BERT models with Flask web technology as well! I will be explaining the step-by-step implementation right from the setup.
So, let’s begin…
Agenda
- Why is summarization using NLP essential?
- What is SBERT?
- Step-by-step Implementation
- Results
- Conclusion
Why is Summarization Essential?
Summarization is the process of expressing the most important points from the given piece of content.
There are large volumes of data in the contemporary world. Reading all of them one by one and writing them in precise manually is such a mundane and cumbersome task for us. That’s why we need AI here to help us while we can focus on several important tasks demanding our attention.

Image 1
Automatic summarization helps medical researchers find health disparities between racial and ethnic groups and thus find their susceptibility and resistibility to different diseases and treatments. It helps question-answering bots collect the most relevant information and thus summarize all of it for a given question thereby providing the optimal and the most helpful answer. It also helps in social media marketing where companies can summarize enormous content from ebooks, blogs, etc., and post a short and sweet summary on their Twitter or LinkedIn pages.
You can read more applications of automatic text summarization from here.
What is SBERT?
Sentence BERT(SBERT), a modification of the pre-trained BERT network, gives semantically meaningful sentence embeddings which can be compared using cosine-similarity.
This feature allows SBERT to be used for new tasks such as semantic similarity comparison. Hence, it is a good methodology for text summarization in which similarity between sentences of the given information must be observed to return a valuable summary having crucial points as well as without changing the meaning of the original text.
Coming to the architecture, it adds a pooling operation to the output of BERT to derive a sentence embedding of constant size.
SBERT can find the most-similar pair in just 5 seconds! Moreover, its accuracy is on par with BERT. It was developed by Nils Reimers and Iryna Gurevych of the Ubiquitous Knowledge Processing Lab in the research paper here, published in August 2019.
Step-by-Step Implementation
Now, it’s time to kickstart the most awaited part of the blog-the coding part!!!
NOTE: If you are comfortable working with VScode and handling virtual environments there itself, proceed with your approach and follow along from step-3.I have used VSCode for the HTML coding and the usual Python IDLE for all the Flask and AI coding.
The steps included are as follows:
Step-1:Create a virtual environment
Step-2:Activate the virtual environment created in step-1
Step-3:Install the necessary packages
Step-4:Front-end coding-Just an overview
Step-5:Back-end Python coding in detail
Step-6: Launch the application!
Step 1 Create a Virtual Environment
We use a virtual environment in order to install all the packages necessary for a project all together in one place. If you go with the base environment itself without creating a virtual environment, it will be worse while doing too many projects for the base environment will get overloaded. That’s why it is a good practice to organize packages in different virtual environments for different projects and let’s adhere to the same here.
Open Anaconda Prompt terminal and cd to the directory where you wish to create the project. Suppose your directory is D:/Project then type cd /d D:Project to get here.
Now, create the virtual environment named nlpSummarizerProject.You can name it whatever you want but ensure that you remember it. I would suggest to prefer nlpSummarizer project itself if you aren’t much familiar with virtual environments; also, it will be easier to catch me along.
Use the following command:
python -m venv nlpSumamrizerProject
For the next few seconds, the cursor will be blinking which will stop as soon as the virtual environment is successfully installed.
Step 2 Activate the Virtual Environment Created in Step 1
Use the following command:
nlpSummarizerProjectScriptsactivate.bat
After executing the above command, you should see nlpSummarizerProject within brackets preceding the (base) environment.
Step 3 Install the Necessary Packages
The packages necessary for the demo include:
- sentence-transformers
- Bert-extractive-summarizer
- Flask
Stay in the virtual environment created and install the above with the following commands:
|
|
|
|
|
|
|
|
|
|
|
|
NOTE:Stay in nlpSummarizerProject-the virtual environment created while installing the packages otherwise there would be no point creating the virtual environment!
Step-4 Front-End Coding
The front-end coding has been accomplished using the conventional technologies: HTML, CSS, and Bootstrap.
Create a folder called ‘templates’ inside the project folder or any working directory as applicable in your case. Open the folder in Visual Studio Code(VSCode). Create two files-‘index. html’ and ‘summary.html’.Get the codes of both of these HTML files from my Github repository here.
The file, ‘index.html’ has the code for the home page which displays a textarea for the user to input a huge chunk of text to be summarized. The page looks like this:
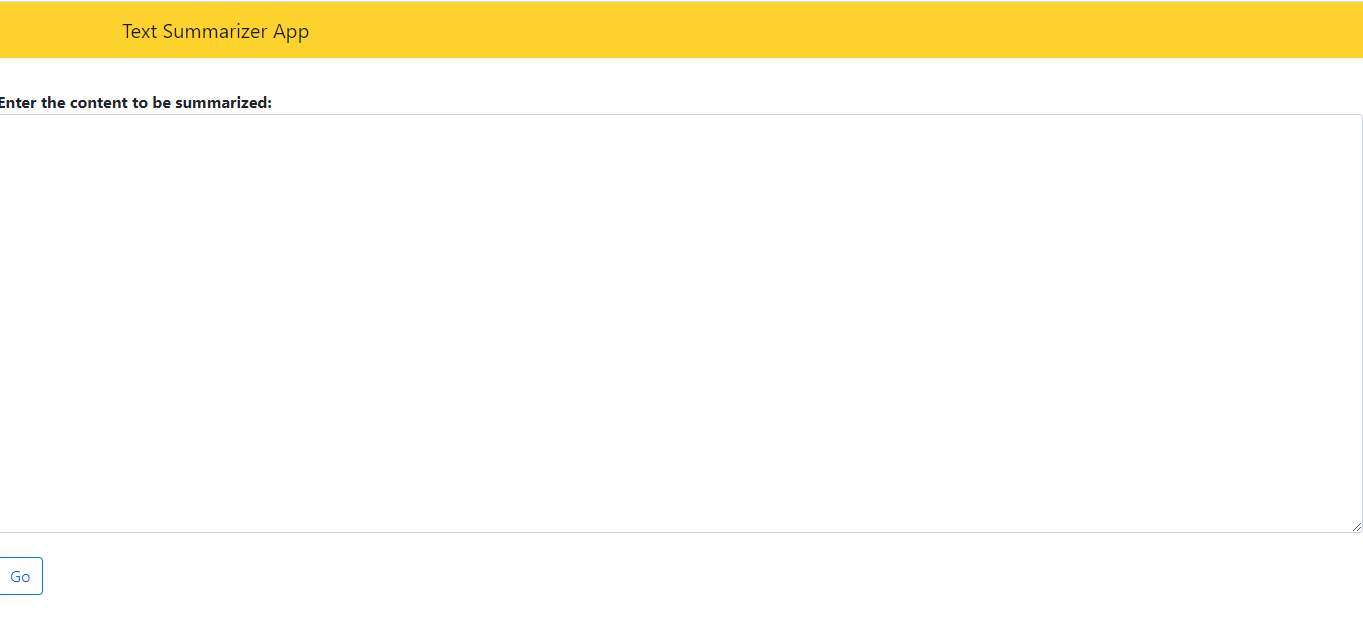
The other file,’ summary.html’ contains the code to render the summary outputted by SBERT on passing the input text from ‘index.html’.The page uses templating to render content sent from the Python backend dynamically.
Step 5 Back-End Python Coding in Detail
Firstly, import SBERT as follows:
#download the summarizer from summarizer import Summarizer #import for SBERT summarizer from summarizer.sbert import SBertSummarizer
Create an SBERT model by declaring an instance of SBERT summarizer as follows:
#create an instance of the SBERT
model = SBertSummarizer('paraphrase-MiniLM-L6-v2')
Finally, summarize the required text by passing it to the above SBERT model:
result = model(body, num_sentences=5)
The text input in the form of ‘index.html’ is obtained by tapping into the form using request.form[‘data’] which in turn is saved in the variable, body. The variable ‘result’ holds the summary of the text in the body, as returned by SBERT.
The model’s parameter num_sentences=5 indicates that the enormous amount of the given text needs to be summarized in just 5 sentences!!! You can change this value to 10,20 or even 3,4 etc., according to your needs.
The above is thus the core code used to perform automatic text summarization.
The entire Flask code(backend code) goes here:
#imports required for flask part
from flask import Flask, render_template,request
#download the summarizer
from summarizer import Summarizer
#import for SBERT summarizer
from summarizer.sbert import SBertSummarizer
#create an instance of the SBERT
model = SBertSummarizer('paraphrase-MiniLM-L6-v2')
app = Flask(__name__)
@app.route("/")
def msg():
return render_template('index.html')
@app.route("/summarize",methods=['POST','GET'])
def getSummary():
body=request.form['data']
result = model(body, num_sentences=5)
return render_template('summary.html',result=result)
if __name__ =="__main__":
app.run(debug=True,port=8000)
Type the above code in a file named ‘app.py’ and save it in your project folder.
Your directory structure in D:/Project should now look like this:
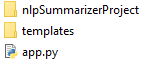
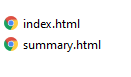
The first folder here contains the files installed while creating the virtual environment(don’t care to even open this folder and bother at those files for it isn’t necessary at least here!) and further installing packages inside it. The ‘app.py’ is the above Python code integrating SBERT and Flask. The templates folder consists of:
If you have come here, then congrats! We are all set to finally launch the application in our very next step.
Step 6 Launch the Application!
Open the Anaconda terminal. Get into your project directory and then activate the virtual environment created which in my case is nlpSummarizerProject.
Run the app using the following command:
python app.py
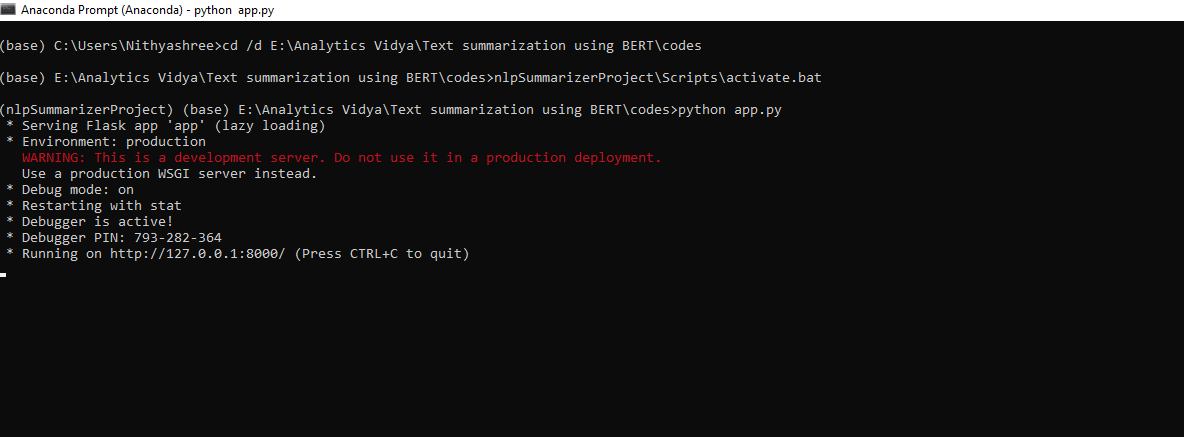
You should see something like the above in your terminal.
NOTE: My path is different from D:/Project.
Now, type localhost:8000/ in your Chrome browser and you should see the empty ‘index.html’.
Results

Feel free to paste any large piece of text that you intend to summarize. I inputted the above information under the ‘Phases of clinical trials in the blog here.

The above is the required summary for my input information. You may need to open the above screenshot in a new tab for better clarity, I recommend. If you read the main content from the website and the summary provided by the application we have just developed, you will notice that the summary by SBERT is quite fair enough and that the most important points have been covered.
Press Ctrl+C in the Anaconda terminal to stop the website and then close the Anaconda terminal. It’s all done!
Conclusion
Hence, in this blog, we successfully developed a Flask web app having SBERT to summarize a given piece of content. The future scope of the work may include inputting the number of sentences the user wants to summarize the entire information or even trying some other summarization technique and a comprehensive comparison of the results.
You can find the entire code from here.
Thank you for reading!
Hope you liked reading my article.
References
Application of automatic text summarization
About Me:
I am Nithyashree V, a final year BTech Computer Science and Engineering student. I love learning such cool and cutting-edge technologies and putting them into practice, especially to observe how they help us solve society’s challenging problems. My areas of interest include Artificial Intelligence, Data Science, and Natural Language Processing.
You can connect with me on LinkedIn here.
You can find my other articles on Analytics Vidhya from here.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Free Courses





