
This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we will build a machine learning pipeline that is a Car Price Predictor using Spark in Python. We have already learned the basics of Pyspark in the last article. If you haven’t checked it yet, here is the link.
Spark is an in-memory distributed data processing tool that can be taken as a replacement for traditional disk-based map-reduce techniques.
Spark is 100 times faster than Hadoop Map-Reduce due to the in-memory (RAM) computation. It can deal with a massive amount of data in real-time.
Hadoop Ecosystem used to rely on Apache Mahout for machine learning tasks. Still, the case of Sparkark has an advanced version of the ML-lib package designed for faster implementation of machine learning tasks.
Features of ML-lib Package
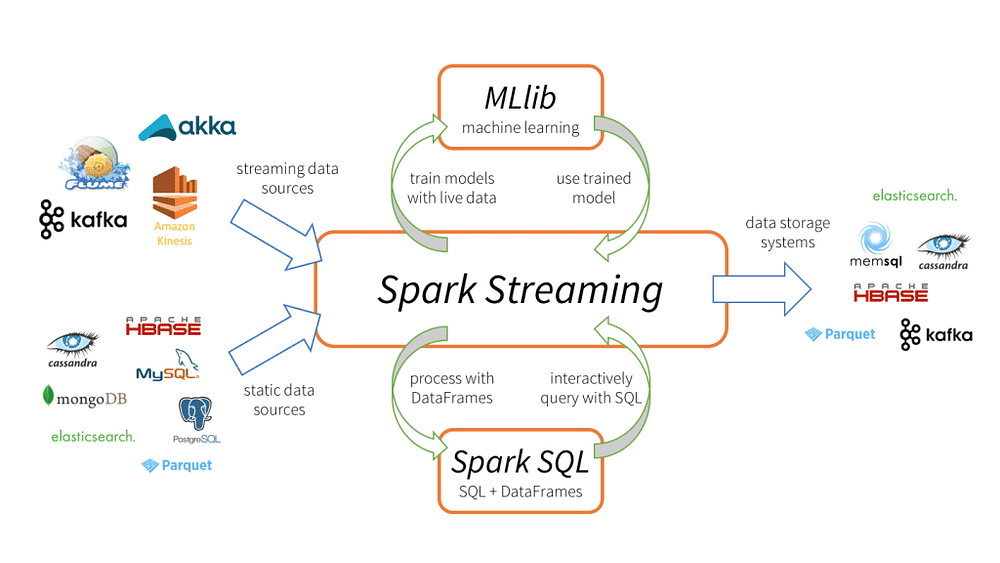
Spark comes with an ML-lib package. For some particular tasks, other packages can be imported inSparkark easily.
- Ml-lib supports Almost all machine learning tasks, including Supervised and unsupervised learning.
- ML-lib supports computer vision and Natural language processing.
- ML-lib APIs are more or less the same as
sklearn’sAPIs, hence easier to work on ML-lib. - It can draw predictions on real-time data as well
Objectives
In this article, we will implement US car price prediction ( a regression task) using Apache Spark in Python.
- Setting up Spark in Cloud Notebook
- Loading the data
- Data Cleaning
- Features Vector in Spark
- Model Training and Testing
- Performance evaluation
Setting up Spark
InstalliSparkark in a Python environment is so easy using the pip package manager. I highly recommend using any cloud notebook, i.e. Google collab, Kaggle, or data bricks notebook.
!pip install pyspark !pip install findspark import findspark findspark.init()
Importing Libraries
import pandas as pd import matplotlib.pyplot as plt from pyspark import SparkContext, SparkConf from pyspark.sql import SparkSession
Creating Spark Context and Session
To load the data Sparkark, we need to create a spark context. Spark context is an entry point to our spark application.
from pyspark import SparkContext, SparkConf
# Creating a spark context class
sc = SparkSession.builder.master("local[*]").getOrCreate()
local[*]→ Create a local session with all available cores.getOrCreate→ If Session is not created, only then create a new session.
You can verify the Session is running by command typing the session name.
Loading the Data
We are using the US car price prediction dataset available on kaggle. You can either download the dataset or create a Kaggle notebook using the dataset.
data = sc.read.csv('../input/cars-data/data.csv', inferSchema = True, header = True)
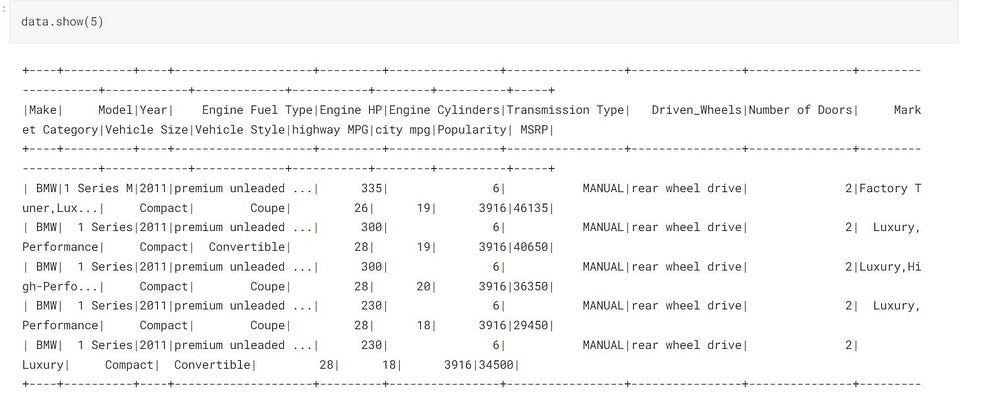
data.show(5)
data.printSchema()
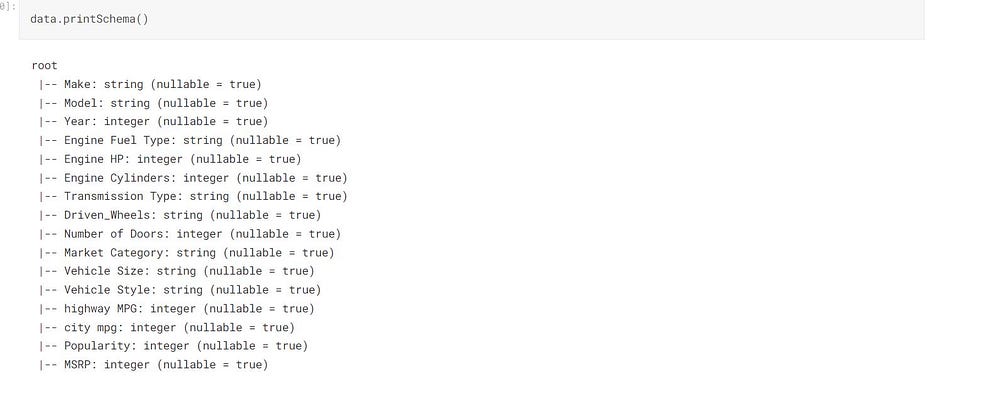
printSchema() Prints all the columns with their data types.
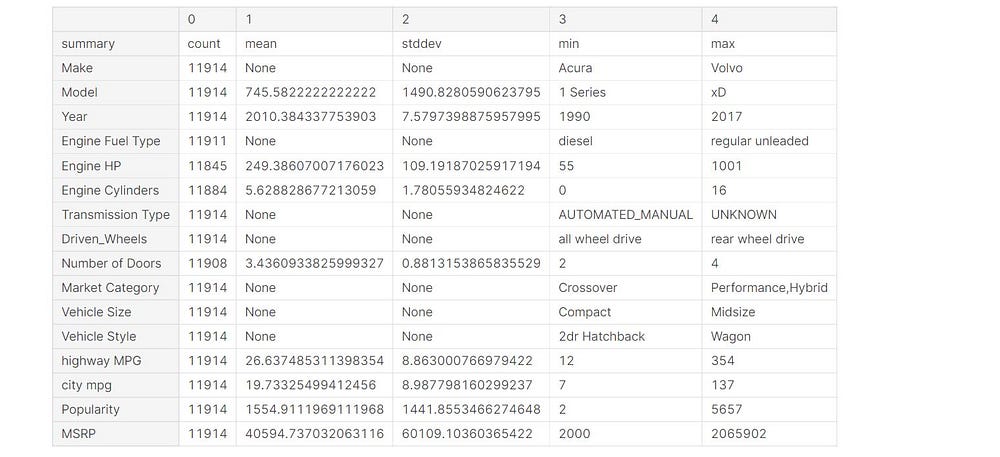
Statics on our Data
data.describe().toPandas().transpose()
Data Cleaning
The data contains some “N/A” values as strings, and we need to replace them with actual NA values.
def replace(column, value):
return when(column!=value,column).otherwise(lit(None))
This function takes a column and values and replaces the matching values with None.
data = data.withColumn("Market Category", replace(col("Market Category"),"N/A"))
Counting all the Null Rows in Every Column
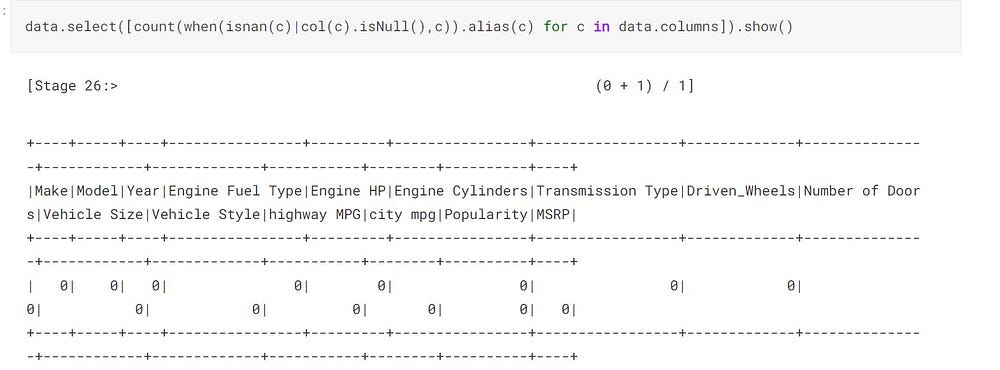
from pyspark.sql.functions import when,lit,count,isnan,col data.select([count(when(isnan(c)|col(c).isNull(),c)).alias(c) for c in data.columns]).show()

As you see that the column Market Category has a maximum number of null or nan values; hence we can safely drop it.
Dropping the NaN values
#deleting the column Market Category
data = data.drop("Market Category")
# deleting the all null values
data = data.na.drop()
So far, we have cleaned all the null values from our data.
print((data.count(), len(data.columns)))

Feature Vectors in Spark ML-lib
To train a model Sparkark, we need to convert our regular columnar data into feature vectors for better convergence. Using VectorAssembler class, we can convert the dataframes columns into feature vectors.
We want to pass “Year”,”Engine HP”,”Engine Cylinders”,these columns as input features in our model. Hence we have to convert these columns into a feature vector.
“Number of Doors”,”highway MPG”,”city mpg”,”Popularity”
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols = ["Year","Engine HP","Engine Cylinders",
"Number of Doors","highway MPG","city mpg","Popularity"],
outputCol = "Input Attributes")
outputCol: It’s the name of the feature vector created.
We are not transforming our Vector Assembler to our data since we will be creating a pipeline to do it all at once.
VectorAssembler combines all the columns into a single feature vector.
Creating the Model and Pipeline
Spark comes with inbuilt machine learning models. We need to import it and train it on our data.
We will use RandomForestRegressor for our task, and later, we will train using cross-validation.
from pyspark.ml.regression import RandomForestRegressor regressor = RandomForestRegressor(featuresCol = 'Input Attributes', labelCol = "MSRP")
RandomForestRegressor : It takes featuresCol = Input attributes and labelCol = Output column.
Pipeline
A pipeline combines multiple steps in one step with a particular sequence. In the Pipeline, we need to list our sequence, and data will enter from the left end, and by going through every process, it comes out.
We can save our Pipeline on disk and load it whenever we want.
from pyspark.ml import Pipeline pipeline = Pipeline(stages = [assembler,regressor])
#--Saving the Pipeline
pipeline.write().overwrite().save("pipeline_save")
Loading the Pipeline
pipelineModel = Pipeline.load('./pipeline_save')
Parameter Tuning and cross-validation
We are defining a hyperparameter space used for hyperparameter tuning during cross-validation.
pyspark.ml.tuning Provides all the classes that can be used for model tuning.
from pyspark.ml.tuning import ParamGridBuilder paramGrid = ParamGridBuilder() .addGrid(regressor.numTrees,[100,500]) .build()
Cross Validator
We are using numFolder = 3 means 66% of the data will be used for training, and the rest, 34%, of the data will be used for testing.
from pyspark.ml.tuning import CrossValidator
crossval = CrossValidator(estimator = pipelineModel,
estimatorParamMaps = paramGrid,
evaluator = RegressionEvaluator(labelCol = "MSRP"),
numFolds = 3)
So far, We have created a cross-validator equipped with a training pipeline but haven’t fitted it with data yet.
Splitting the Data
We will split our data into training and testing parts by 80% for model training, and the rest 20% will be used for prediction.
train_data , test_data = data.randomSplit([0.8,0.2], seed = 123)
Fitting the Model with Data
This process might take some time since it’s the actual training process.
cvModel = crossval.fit(train_data)

Getting the Best Fit Model
bestModel This function returns the best-fitted model.
bestModel = cvModel.bestModel print(bestModel.stages)

The best fit model we have got is having numTree = 500 and numFeatures = 7.
Prediction
The transform method is used for the prediction.
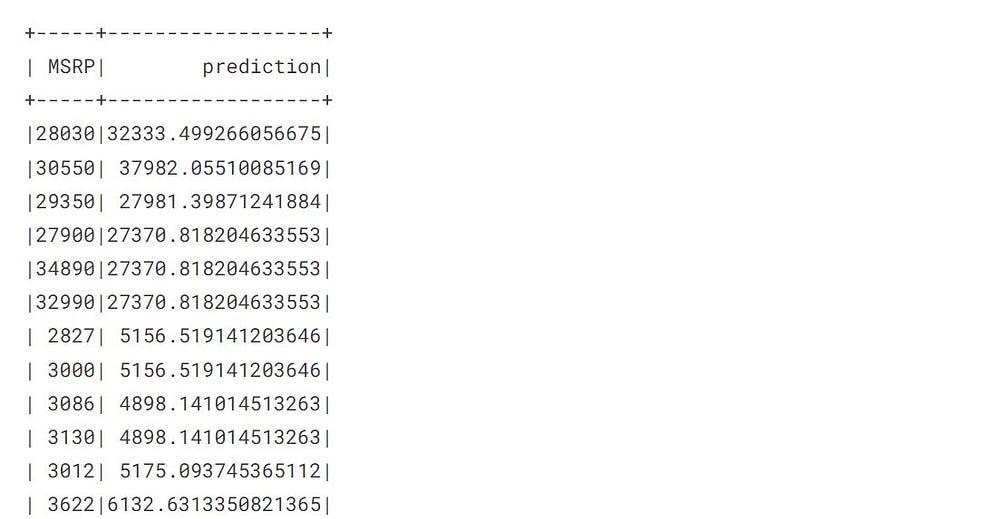
pred = cvModel.transform(test_data)
The transform method will automatically create a prediction column containing all the predictions.
Performance Evaluation
Spark provides an Evaluator class to evaluate how well our model has trained, and it gives a separate evaluator for classification and regression tasks.
from pyspark.ml.evaluation import RegressionEvaluator
eval = RegressionEvaluator(labelCol = 'MSRP')
rmse = eval.evaluate(pred, {eval.metricName:'rmse'})
mae = eval.evaluate(pred, {eval.metricName:"mae"})
r2 =eval.evaluate(pred,{eval.metricName:'r2'})
Printing the metrics
print("RMSE: %.3f" %rmse)
print("MAE: %.3f" %mae)
print("R2: %.3f" %r2)

R2: It measures the proportion of variance that our model can explain. A higher R2 Score means a better-trained model
RMSE: It measures squared mean error in real value and predicted value.
Conclusion
This article discussed how to work with Spark ML-lib and learned the various steps involved in building a machine learning pipeline using Spark in python.
Spark ML-lib also provides inbuilt performance evaluator metrics for classification and regression tasks.
Spark ML-lib can draw predictions on real-time data as well. We have just trained a model in this article and tested it on a static dataframe, and the following article will implement the same model in real-time spark streaming.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A data enthusiast exploring the leading technologies related to the data
Free Courses





