This article was published as a part of the Data Science Blogathon.
Introduction
Text Mining is also known as Text Data Mining or Text Analytics or is an artificial intelligence (AI) technology that uses natural language processing (NLP) to extract essential data from standard language text. It is a process to transform the unstructured data (text in emails, reviews, documents, databases) into structured data to derive critical insights and perform different machine learning algorithms.
Text mining is gaining more attraction because it’s essential to understand the unstructured data received or collected from employees, customers, and stakeholders to devise strategies or policies.

Why Use the No-code Tool Orange?
Earlier, it was necessary to use coding tools to derive practical insights from such textual data and thus needed a strong background and knowledge of coding techniques. But now, you can do the same quickly without any code line, which makes your work easier and eliminates the need to know the coding languages. Although to work on such no-code tools, you need to have sound knowledge of the required statistical techniques.
One such no-code tool is Orange, enabling you to visualise data and perform data mining and machine learning.
This article will show how to perform sentiment analysis on the dataset of boat headphone reviews having almost 10,000 data records using this no-code tool.
What is Sentiment Analysis?
Sentiment analysis, also known as opinion mining, is a natural language processing (NLP) technique used to identify whether data is positive, negative or neutral. It is often done on structured and unstructured textual data to derive critical business insights and track the brand and product sentiment. This enables organizations to understand and provide products/services as per the current customer’s needs.
Few Applications of Sentiment Analysis
- Customer review analysis – Brand sentiment or Product sentiment analysis
- Market analysis
- Social media monitoring
- Market research
Types of Sentiment Analysis Algorithms
A. Rule-based – This is a practical approach where the system automatically analyzes the text without using machine learning models. The output of this is different rules based on which the textual content is labelled as positive, negative or neutral. To apply these rules, NLP techniques are leveraged. These techniques include part-of-speech tagging, parsing, stemming, lexicons, and tokenization. These rules are also known as lexicons. Therefore, the Rule-based approach is also called as Lexicon based approach.
Generally used lexicon-based approaches are TextBlob, VADER, and SentiWordNet.
B. Automatic – Here, the systems depend on machine learning models to learn from data. A classification machine learning model is implemented in this type of sentiment analysis to determine whether the input text falls into different sentiments, such as positive, negative, or neutral.
At first, the input data is fed into a model where features are extracted and associated with a particular tag. The feature extraction process includes techniques such as a bag of words or bag-of-n-grams, text vectorisation, word embeddings, and word frequencies. After that, the training data is classified with different sentiments (or tags) to attain a trained, supervised model.
In the next step, predictions of classes (or tags) are generated on unseen data points, using the learned model from the training step. Standard classification models used are Naive Bayes, logistic regression, support vector machines, linear regression, and deep learning for classification problems.
Steps to Perform Sentiment Analysis
To perform the Sentiment Analysis, you need to install the “Text Mining” widget, an Add-On feature in Orange. Add-On
Before we move further, you need to understand the two basic terms of this platform.
- A widget is the primary processing point of any data manipulation.
- A workflow is the sequence of steps or actions you take on your platform to accomplish a particular task.
Below is the opening page of Orange.
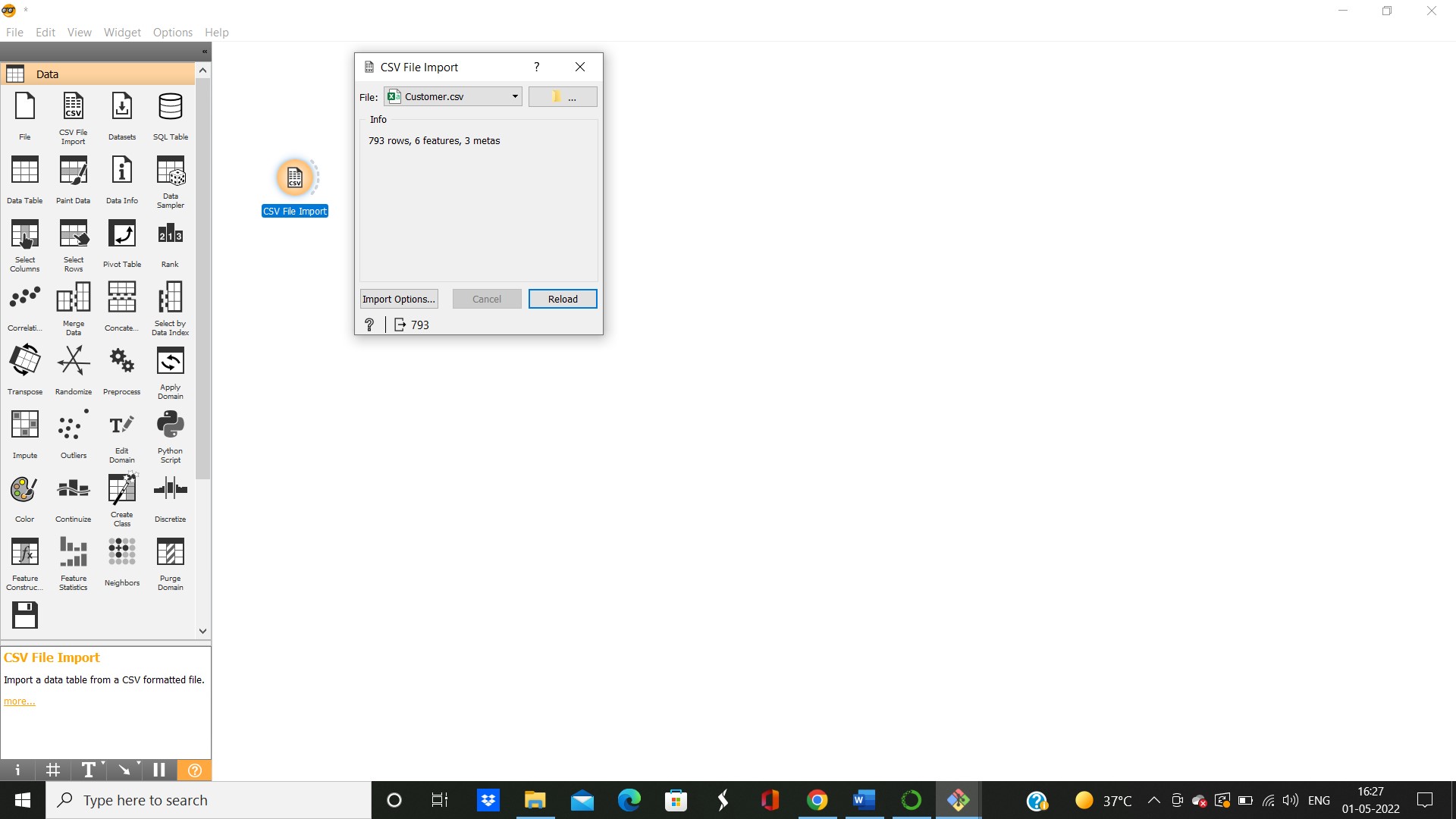
1. Import the csv file
Drag the csv file import icon from the data, drop it on the canvas’s right side, and click on it to import the file.
This is the way to develop the entire workflow. Users only need to drag and drop the correct fields and connect them as per the statistical requirements to perform the necessary tasks.
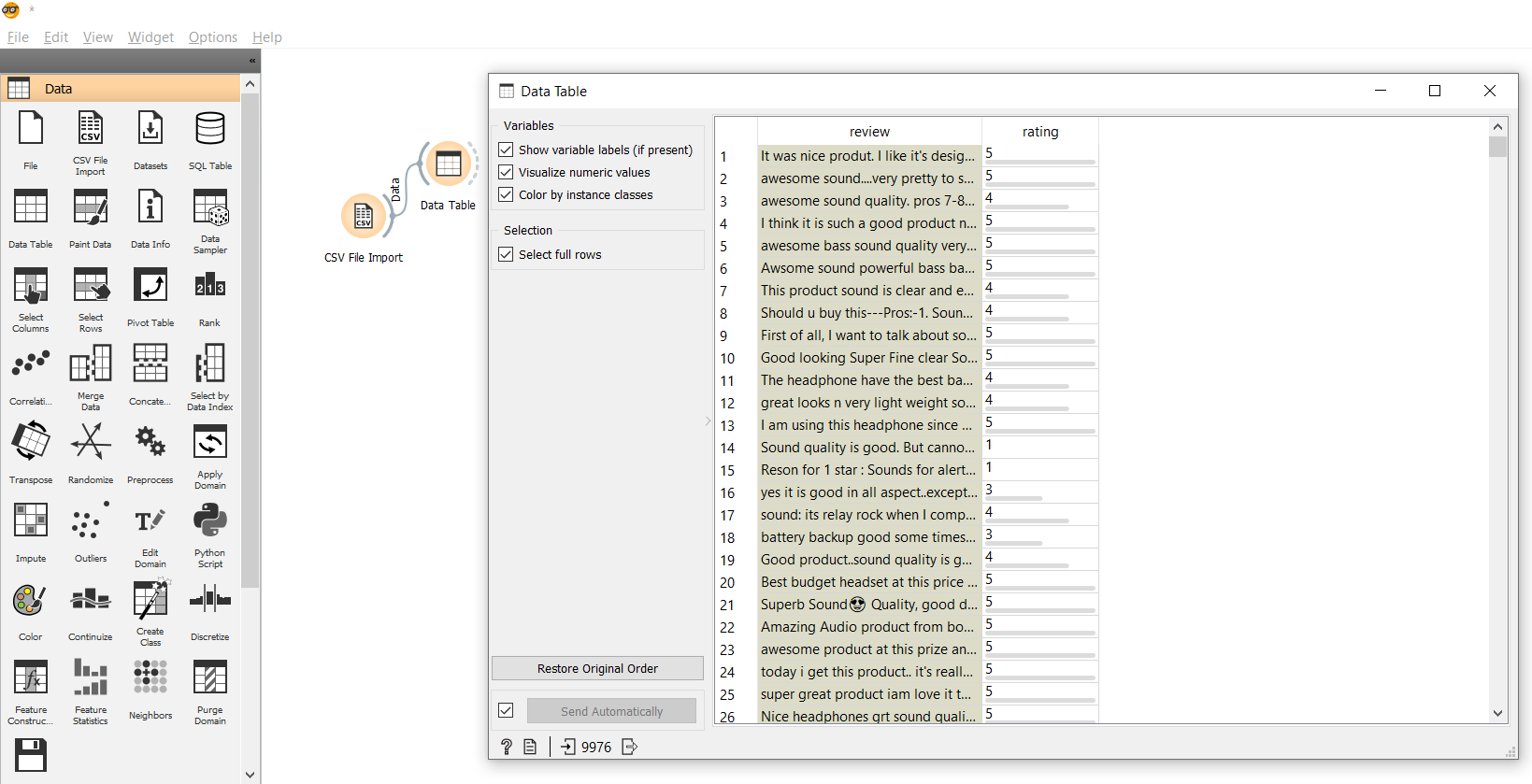
2. Import data table
This is required to view the dataset in a spreadsheet. Here you will be able to see the data in tabular form.
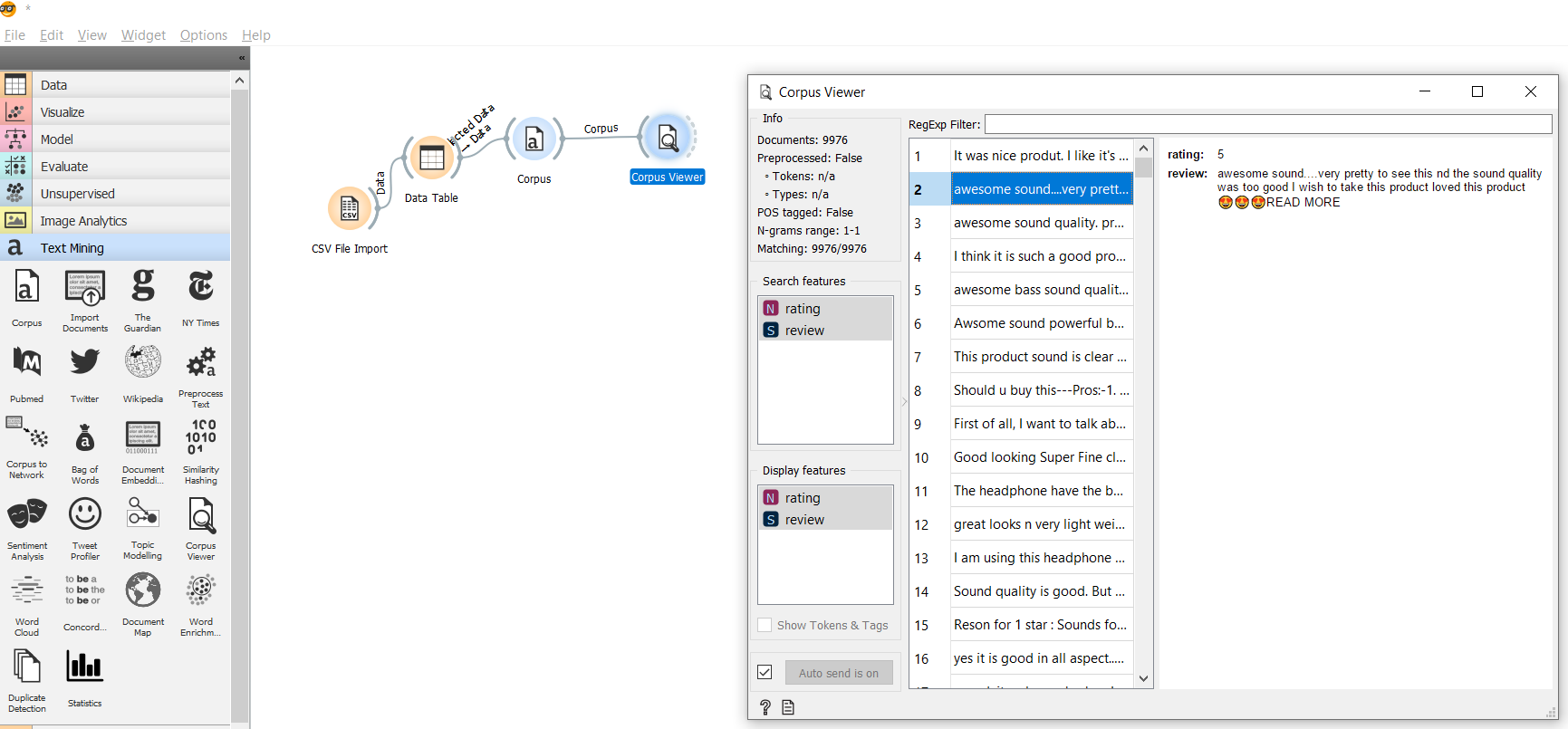
3. Import Corpus and corpus viewer
A text corpus is a large and unstructured set of texts used for statistical analysis and hypothesis testing, checking occurrences or validating linguistic rules within a specific language territory.
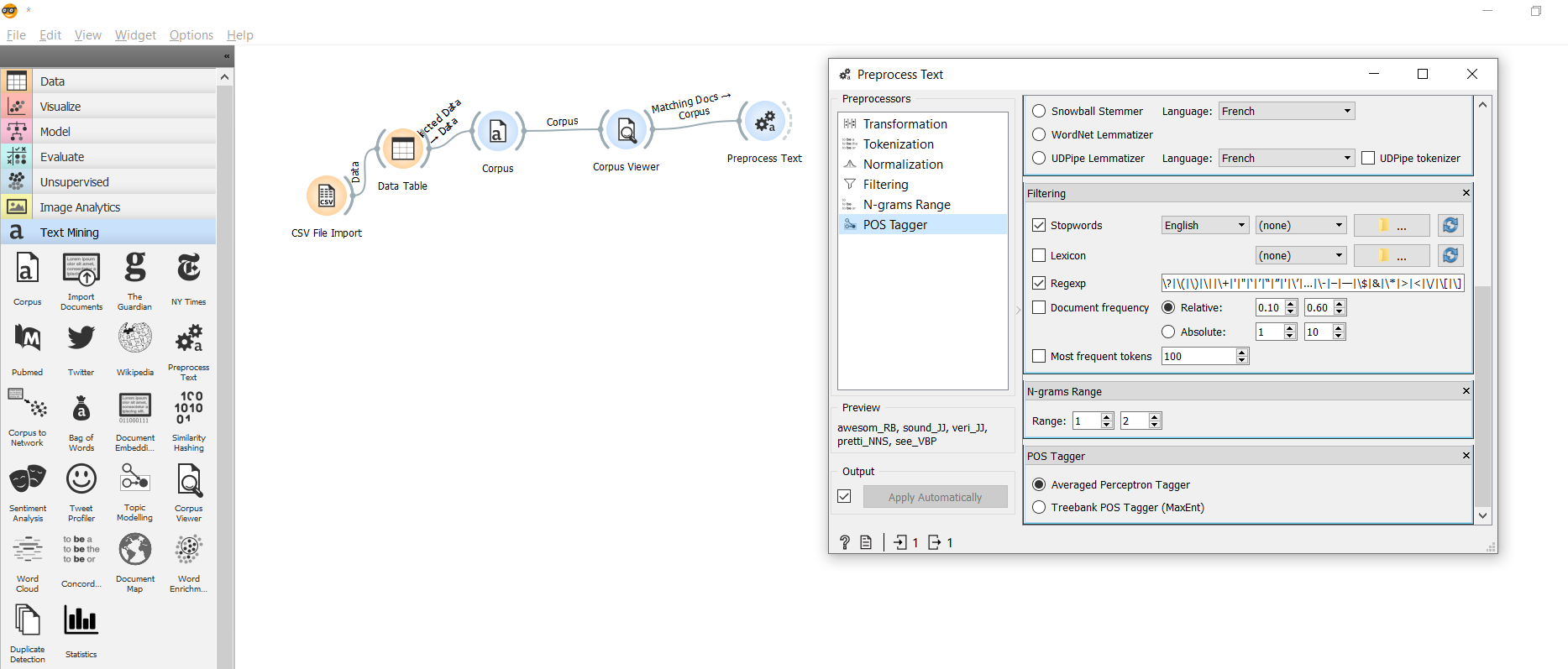
4. Import Process Text
It would help if you imported this to deal with all the data preprocessing parts, and it will enable you to perform.
Transformation (Lower case)
Tokenization (Word punctuation,white spaces, sentence, regex)
Normalization (Porter Stemmer, Snowball Stemmer)
Filtering (Stopwords)
N-grams
POS Tagging
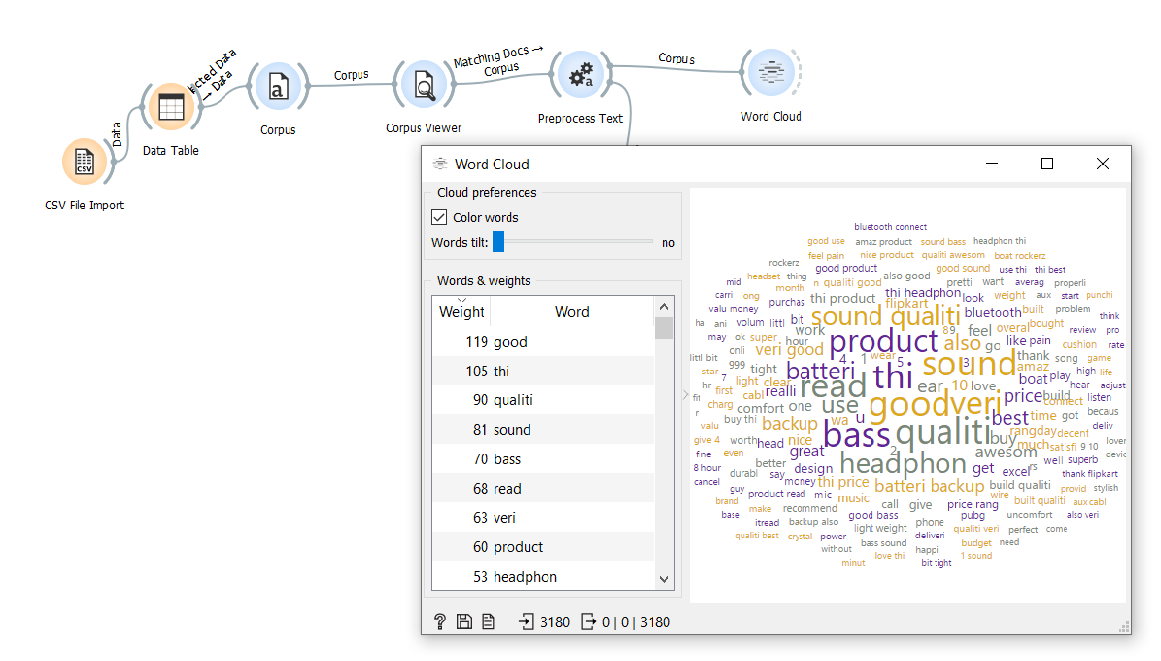
5. Import Wordcloud
Import word clouds, also known as tag clouds, are visual representations of words that give greater prominence to words that appear more frequently.
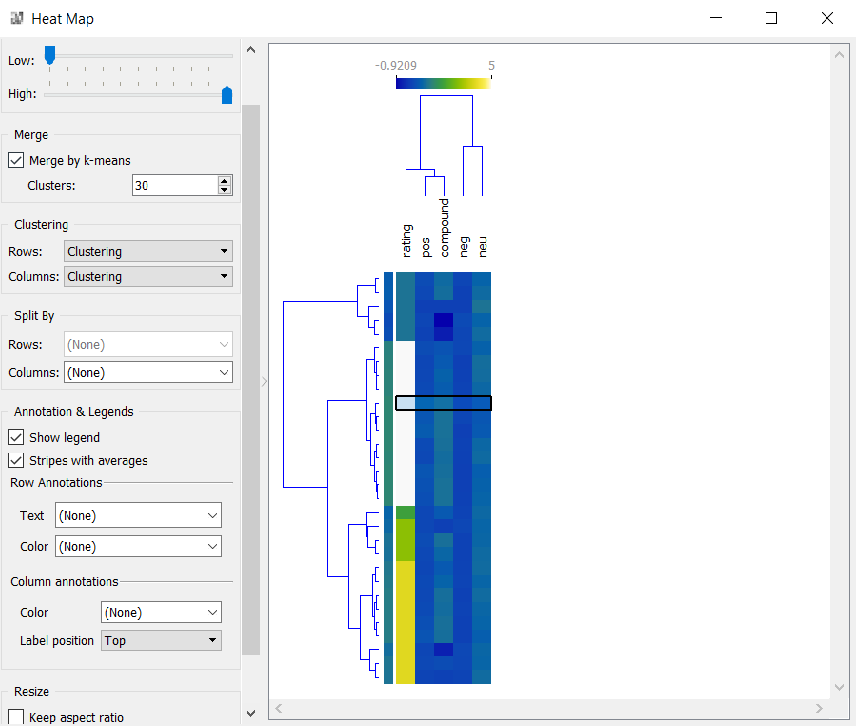
6. Import Sentiment Analysis
This is required to perform the sentiment analysis of the reviews and understand the tone of the customers (i.e. Positive, Negative and Neutral).
The figure below shows the heat map of clusters of reviews.
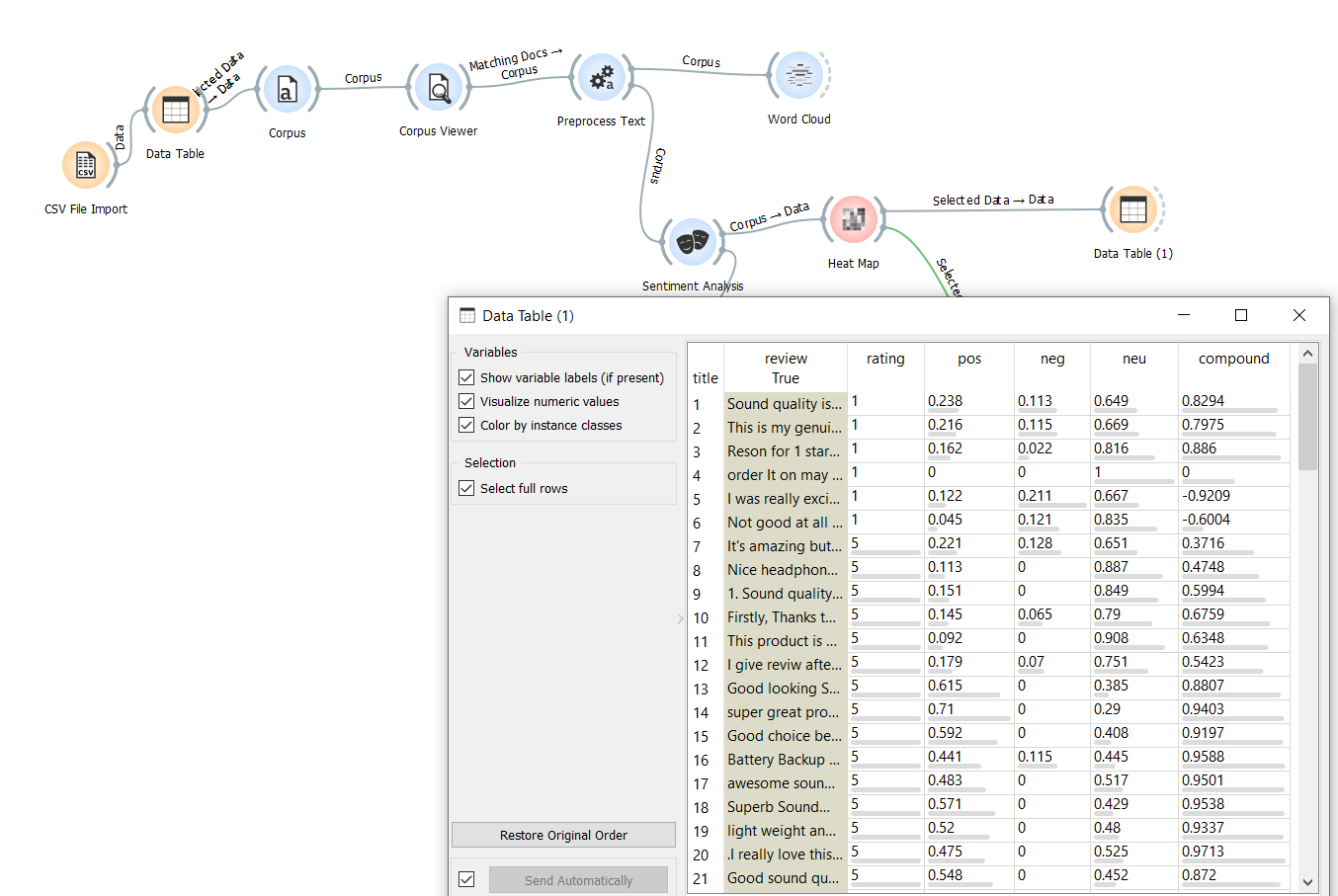
The below table shows the sentiment score in tabular format. Here you can see the score of each review.
The compound score is the sum of negative, positive, neutral scores, normalised between -1(most extreme negative) and +1 (most extreme positive). The more Compound score closer to +1, the higher the positivity of the text.
Entire workflow at a glance
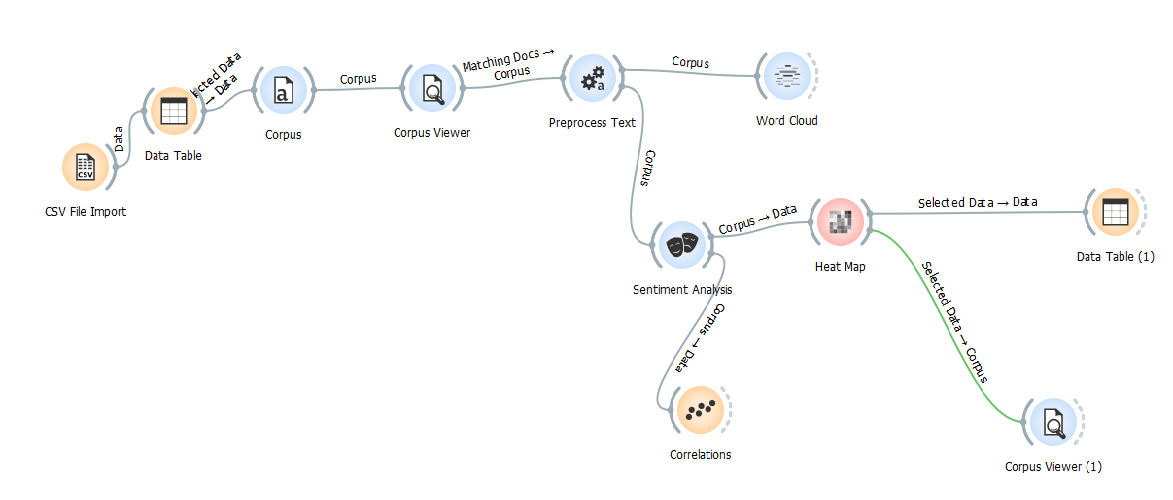
Conclusion
This is how sentiment analysis is done in orange.
Therefore, in this article, you have got acquainted with performing sentiment analysis of unstructured textual content saved in csv file format. Also, you have reached the approach to understanding the text’s tone. At least to use this tool in a better manner, users must develop a sound knowledge of the desired statistical techniques and implement the algorithm by building the incorrect workflow order.
This tool is beneficial for similarly performing different machine learning algorithms without writing a single code. This platform can be used for analysis, is relatively easy, and has beautiful visuals.
I hope this tutorial has helped you understand the process of performing the sentiment analysis without writing a single line of code. It is essential to understand the data science pipeline and the steps we take to train a model, and this should surely help you build better models soon!
Stay tuned for more such articles.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





