This article was published as a part of the Data Science Blogathon.
Introduction
Web scraping, is an approach to extract content and data from a website. Web Scraping makes use of intelligence automation methods to draw millions of datasets in a comparatively shorter amount of time. There are ample ways to get data from websites. Some of the ways to get data are API’s, online services or creating a python code from scratch. Some large websites like Twitter, Facebook, Google etc have their own API’s that allow you to access their data in a structured format. But there are many sites which don’t allow people to access their data in a structured format. In such a scenario, it is recommended to scrape a large amount of data using web scraping.As of now, when you search for code of web scraping you will come across code which scrapes data only from a single page.
Objective
- The purpose of the article is to take you through the process of python code which will automatically scrape the data from multiple web pages.
- Sentiment analysis on the data scraped from websites. This part will not be discussed. Only the code will be provided at the end of the article.
Let’s dive in!
Steps to Perform Automated Web Scrapping for Amazon.In
In this tutorial I have web scraped reviews of HP 14s 11th Gen Intel Core i3- 8GB RAM/256GB SSD listed on the Amazon website.
Import Necessary Libraries
Beautiful Soup is a Python package for parsing HTML and XML documents. It creates a parse tree for parsed pages that can be used to extract data from HTML, which is useful for web scraping.
randint is a function of the random module in Python3. The random module gives access to various useful functions and one of them is able to generate random numbers.
# Importing necessary libraries for web scrapping import requests from bs4 import BeautifulSoup as bs from random import randint from time import sleep from itertools import repeat
Create List to Collect the Desired Outcomes
name= [] cust_name = [] titles = [] review_title = [] ratings = [] rate = [] reviews =[] review_content = []
Paste the Link of Product Reviews
The code line URLS is the line where you have to paste your reviews page number 2 link. The normal link of page number 2 will be like this :-
Required format :
for URL in URLS:
for page in range(2,11):
pages = requests.get(URL + str(page))
print(URL)
print(URL + str(page))
print(pages)
soup = bs(pages.content,'html.parser')
names = soup.find_all('span',class_='a-profile-name')
name.append(names)
for i in range(0,len(names)):
cust_name.append(names[i].get_text())
title = soup.find_all('a',class_='review-title-content')
titles.append(title)
for i in range(0,len(title)):
review_title.append(title[i].get_text())
review_title[:] = [titles1.lstrip('n') for titles1 in review_title]
review_title[:] = [titles1.rstrip('n') for titles1 in review_title]
rating = soup.find_all('i',class_='review-rating')
ratings.append(rating)
for i in range(0,len(rating)):
rate.append(rating[i].get_text())
review = soup.find_all("span",{"data-hook":"review-body"})
#print("***************************************************")
#print(review)
reviews.append(review)
for i in range(0,len(review)):
review_content.append(review[i].get_text())
review_content[:] = [reviews.lstrip('n') for reviews in review_content]
review_content[:] = [reviews.rstrip('n') for reviews in review_content]
#print("Customer names are ",cust_name)
print(len(cust_name))
#print("Review Title is ",review_title)
print(len(review_title))
#print("Number Ratings are ",rate)
print(len(rate))
#print("Actual reviews are ",review_content)
print(len(review_content))
In the image below you can see the list of urls of different review pages. — The HTTP 200 OK success status response code indicates that the request has succeeded. A 503 Service Unavailable Error is an HTTP response status code indicating that a server is temporarily unable to handle the request. Sometimes you won’t be able to scrape the content from all the urls or pages. So, you have to continue with the data collected from the URLs whose request succeeded or run the above code block multiple times or from different systems.
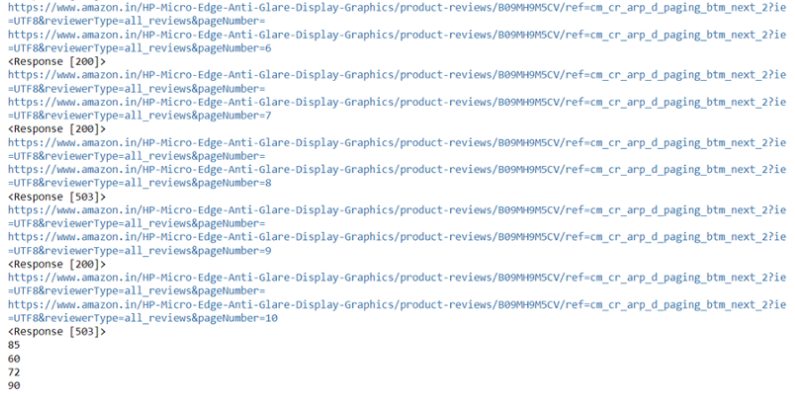
The values 85,60,72,90 in above figure indicate successful web scrape of:-
Customer Names — 85
Review Titles — 60
Reviews — 72
Ratings — 90
Import Libraries Required to Create the Dataframe
The bcode below shows the libraries required to create a data frame and how the list of outcomes were converted to 4 different dataframes and later merged to form a dataframe with columns viz Customer Name, Review title, Ratings, Reviews.
The result.shape shows that there are 90 rows and 4 columns in the dataframe.
#Importing libraries required to create the dataframe. import pandas as pd df1 = pd.DataFrame() df1['Customer Name']=cust_name df2 = pd.DataFrame() df2['Review title']=review_title df3 = pd.DataFrame() df3['Ratings']=rate df4 = pd.DataFrame() df4['Reviews']=review_content #df['Review title']=review_title #df['Ratings']=rate #df['Reviews']=review_content #df['Mobile Model']=modellist
frames = [df1, df2, df3, df4] result = pd.concat(frames,axis=1)
result.shape
(90, 4)
Review of Structured Data in Form of Dataframe
result.tail(10)
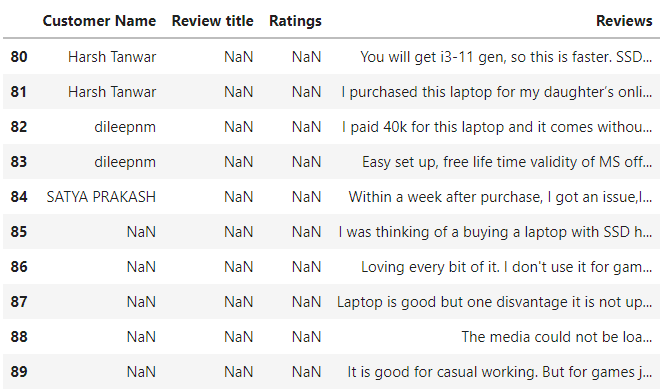
Wherever the code was not able to gain the data for reviews, you will observe NaN written.
e.g for the 83rd data point, the code gained a customer name and review but was not able to gain a review title and rating as it might be absent on the website itself or the code failed to fetch it.
Data Pre-processing
To analyze the data using Natural Language Processing techniques, you need the data to be more structured. Therefore, clean the rows with invalid entries.
Earlier in step 3, you can see the shape of the dataframe was 90,4 and after pre-processing, the shape of the dataframe is 72,4. This means there were 18 rows with a null value in the rating column.
# Finding the count of reviews for each rating result['Ratings'].value_counts()
#checking the null values in Rating Column result['Ratings'].isnull().sum()
18 result.isnull().sum() Customer Name 5 Review title 30 Ratings 18 Reviews 0 dtype: int64 #dropping the rows where rating value is null (NAN) result = result.dropna(axis=0, subset=['Ratings']) result.isnull().sum() Customer Name 0 Review title 12 Ratings 0 Reviews 0 dtype: int64 result.shape (72, 4)
Conclusion
In this way, automated web scraping is performed to scrape the data from multiple pages of a website.
The following are the major key takeaways: –
- You will be able to web scrape all the reviews of products listed on Amazon.In website.
- This code will work for any product available on the website. There are many codes available in market which enable you to scrape the reviews only from one single page.
- The speciality of the code below is it will enable user to web scrape the reviews for any product and for all its pages. (e.g If the user searches Samsung S20 FE 5G and finds that there are a total of 400 reviews available and are distributed on 10 pages, then this code will scrape all the reviews from all the 10 pages).
I hope this tutorial has helped you understand the concept of web scraping and how to perform it to gain the desired data without repeating the same thing for multiple pages. You can share your feedback in the comments below and connect with me on Linkedin.
Read my other articles here.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





