Introduction
In the realm of data science and machine learning, working with imbalanced datasets is a common challenge, particularly in binary classification tasks. Imbalanced data refers to datasets where the distribution of classes is skewed, with one class significantly outnumbering the others. This scenario is prevalent across various domains, including fraud detection, medical diagnosis, and anomaly detection. Handling imbalanced data effectively is crucial as traditional machine learning algorithms tend to perform poorly on such datasets, favoring the majority class while neglecting the minority class. In this article, we learn about the two classes techniques for handling imbalanced data using the Imbalance-Learn library in Python, along with decision trees and cross-validation strategies to enhance model robustness and generalization.
Learning Objectives
- Understand the concept of imbalanced datasets and their implications, including the challenges posed by class imbalance, true distribution, and the importance of appropriate sampling import SMOTE.
- Explore the Imbalance-Learn library in Python, its capabilities for handling class imbalance, and its integration with training data (x_train) and corresponding labels (y_train).
- Implement various resampling techniques, algorithmic approaches, and hybrid methods offered by Imbalance-Learn to address imbalanced data, ensuring effective model training and evaluation on skewed datasets.
This article was published as a part of the Data Science Blogathon.
Table of contents
Understanding Imbalanced Data
Imbalanced datasets pose several challenges in machine learning tasks, particularly in addressing the imbalance problem inherent in the data. The scarcity of data in the minority class can lead to biased models that fail to generalize well to real-world scenarios. Moreover, conventional evaluation metrics such as accuracy can be misleading, as they need to account for class imbalance.
It is essential to address these challenges using techniques like Imbalance-Learn, which provides tools to handle imbalanced datasets effectively by adjusting class weights, resampling methods, and algorithmic approaches. Data scientists can ensure fair and accurate model predictions by carefully managing the imbalance problem and considering the number of samples in the training set.
Introduction to Imbalanced-learn
Imbalanced-Learn, along with scikit-learn (sklearn), is a Python library specifically designed to tackle class imbalance in machine learning tasks. It provides a comprehensive suite of techniques for resampling, algorithmic approaches, and hybrid methods to handle imbalanced datasets effectively.
With Imbalance-Learn, data scientists can adjust parameters to rebalance datasets, apply algorithmic approaches to mitigate overfitting, train models with balanced data, and evaluate model performance using appropriate metrics. Whether you’re a beginner or an experienced practitioner, Imbalance-Learn offers a helpful tutorial to guide you through addressing class imbalance in your machine-learning projects.
Techniques for Handling Imbalanced Data
- Resampling Methods:
- Over-sampling techniques such as SMOTE (Synthetic Minority Over-sampling Technique) and ADASYN (Adaptive Synthetic Sampling) generate synthetic samples for the minority class to balance the dataset.
- Under-sampling techniques randomly remove samples from the majority class to achieve class balance.
- Algorithmic Approaches:
- Cost-sensitive learning adjusts the misclassification costs to account for class imbalance during model training.
- Ensemble methods such as Random Forest and XGBoost inherently handle class imbalance by aggregating predictions from multiple models.
- Hybrid Methods:
- Hybrid methods combine over-sampling and under-sampling techniques to achieve a balanced dataset while preserving the information in the original data.
Implementation with Imbalance-Learn
In this section, we demonstrate how to implement various techniques for handling imbalanced data using the Imbalance-Learn library. We walk through loading and exploring an imbalanced dataset, applying resampling techniques, training machine learning models, and evaluating their performance using appropriate evaluation metrics.
- Loading and exploring an imbalanced dataset : Before diving into handling imbalanced data, it’s crucial to understand the dataset’s structure and class distribution. In this section, we’ll load an imbalanced dataset using Python and Pandas and then explore its characteristics to gain insights into the class distribution.
- Preprocessing and data preparation: Once the dataset is loaded, preprocessing is necessary to ensure data readiness for model training. This includes handling missing values, encoding categorical variables, and scaling numerical features. Splitting the dataset into training and testing sets is also essential for model evaluation.
- Applying resampling techniques with Imbalance-Learn: With Imbalance-Learn, we have access to various resampling techniques to address class imbalance effectively. We’ll demonstrate how to apply Over Sampling methods such as SMOTE and ADASYN and Under Sampling techniques like RandomUnderSampler and NearMiss.
- Training and evaluating models using balanced datasets: After resampling the dataset to achieve balance, we train machine learning models using the balanced data. We’ll use popular algorithms such as Logistic Regression, Random Forest, and Support Vector Machines (SVM) from the Scikit-learn library. Finally, we’ll evaluate the models’ performance using appropriate evaluation metrics such as F1 score, AUC-ROC curve, and confusion matrix on the test set.
What is Sampling?
The idea behind sampling is to create new samples or choose some records from the whole data set.
At first, we will load the imbalanced dataset using Python and Pandas. For this task, we are using the AID362_train from Bioassay datasets available on Kaggle.
Let’s create a new anaconda environment (optional but recommended) and open our Jupyter Notebook or any IDE you want to use, go for it.
Then import the necessary libraries as shown in the code snippet.
import pandas as pd import numpy as np import imblearn import matplotlib.pyplot as plt import seaborn as sns
Now read the CSV file into the notebook using pandas and check the first five rows of the data frame.
train = pd.read_csv('AID362red_train.csv')
train.head()
Then check the class frequency using value_counts and find the class distribution ratio.
train['Outcome'].value_counts() inactive = len(train[train['Outcome'] == 'Inactive']) active = len(train[train['Outcome'] == 'Active']) class_distribution_ratio = inactive/active
The data is highly imbalanced, with a ratio of 70:1 for the majority to the minority class. Now, let’s tackle this imbalanced data using various Under Sampling techniques first.
What is Under Sampling?
Under Sampling techniques helps in balancing the class distribution for skewed class distribution. Imbalanced class distribution has more examples from one or more classes (majority class) and few examples belonging to minority classes.
Under Sampling techniques eliminate some examples from the training data set belonging to the majority class. It is to better balance the class distribution by reducing the skewness of 1:80 to 1:5 or 1:1. Under-sampling is used along with the conjunction of an Over-sampling method. These techniques’ combination often gives better results than using any of these alone.
The basic Under Sampling technique removes the examples randomly from the majority class, referred to as ‘randomundersampling.’ Although this is simple and sometimes effective too, there is a risk of losing useful or important information that could determine the decision boundary between the classes.
Therefore, there is a need for a more heuristic approach that can choose examples for non-deletion and redundant examples for deletion.
Fortunately, some Under Sampling techniques do use such heuristics. These we will discuss in the upcoming sections.
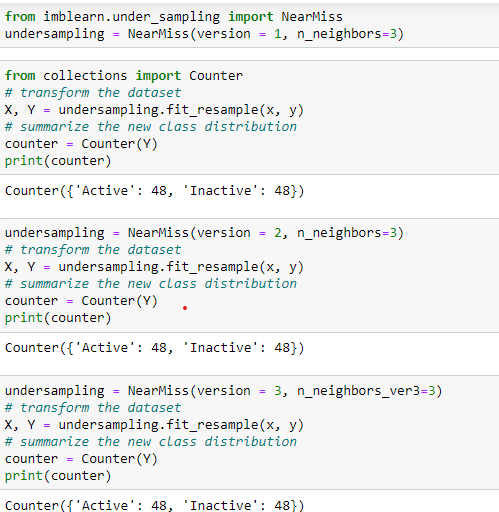
Near Miss Under Sampling
This technique selects the data points based on the distance between majority and minority class examples. It has three versions of itself, and each of these considers the different neighbors from the majority class.
- Version 1 keeps examples with a minimum average distance to the nearest records of the minority class.
- Version 2 selects rows with a minimum average distance to the furthest records of the minority class.
- Version 3 keeps examples from the majority class for each closest record in the minority class.
Among these, version 3 is more accurate since it considers examples of the majority class that are on the decision boundary.
Let’s implement each of these with Imblearn and Python.
Condensed Nearest Neighbor (CNN) Under Sampling
This technique aspires to a subset of a collection of samples that minimizes the model loss. These examples are stores in a store that then consists of examples from the minority class and incorrectly classified examples from the majority class.

Tomek Links Under Sampling
This technique is the modified version of CNN in which the redundant examples get selected randomly for deletion from the majority class. These examples are rather internal than near the decision boundary.
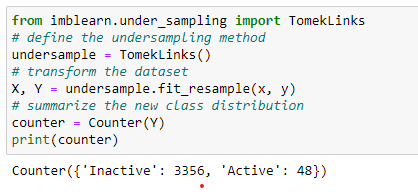
Since it uses redundant examples, it barely balances the data.
Edited Nearest Neighbors Under Sampling
This technique uses the nearest neighbors approach and deletes according to the misclassification of the samples. It computes three nearest neighbors for each instance. If the example of a majority class and misclassified by these three neighbors. Then it removes that instance.
If the instance is of the minority class and misclassified by the three nearest neighbors, then its neighbors from the majority class are removed.
One-Sided Selection Under Sampling
This technique combines Tomek Links and the CNN rule. Tomek links remove the noisy and borderline examples, whereas CNN removes the distant examples from the majority class.
 Neighborhood Cleaning Under Sampling
Neighborhood Cleaning Under Sampling
This approach is a combination of CNN and ENN techniques. Initially, it selects all the minority class examples. Then ENN identifies the ambiguous samples to remove from the majority class. Then CNN deletes the misclassified examples against the store if the majority class has more than half of the minority class examples.
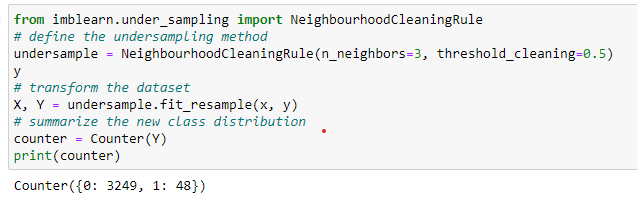
We have seen some Under Sampling techniques. Let’s dive into Over Sampling techniques to handle the imbalanced data.
Over Sampling
Unlike Under Sampling, which focuses on removing the majority class examples, Over Sampling focuses on increasing minority class samples.
We can also duplicate the examples to increase the minority class samples. Although it balances the data, it does not provide additional information to the classification model.
Therefore synthesizing new examples using an appropriate technique is necessary. Here SMOTE comes into the picture.
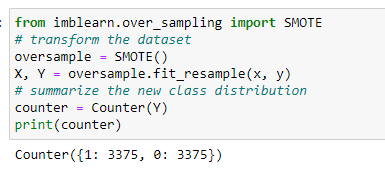
SMOTE
SMOTE stands for Synthetic Minority Over Sampling Technique.
It selects the nearest examples in the feature space, then draws a line between them, and at a point along the line, it creates a new sample.
“First of all, SMOTE picks an instance randomly from the minority class. Then it finds its k nearest neighbors from the minority class itself. Then one of the neighbors gets chosen randomly and draws the line between these two instances. Then new synthetic examples are generated using a convex combination of these two instances.”
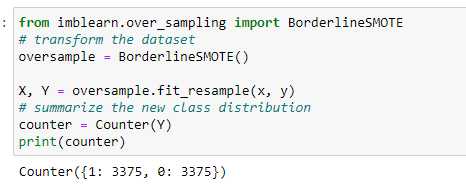
Borderline-SMOTE
This SMOTE extension selects the minority class instance that is misclassified with a k-nearest neighbor (KNN) classifier. Since borderline or distant examples are more tend to misclassified.
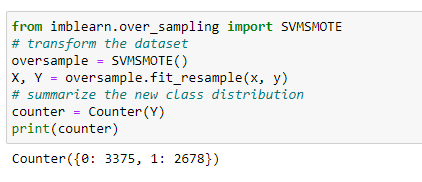
Borderline-SMOTE SVM
This method selects the misclassified instances of Support Vector Machine (SVM) instead of KNN.
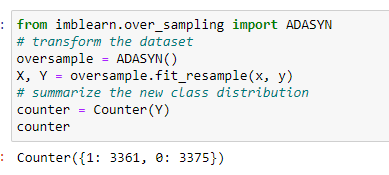
Adaptive Synthetic Sampling (ADASYN)
This approach works according to the density of the minority class instances. Generating new samples is inversely proportional to the density of the minority class samples.
It generates more samples in the feature space region where minority class examples density is low or none and fewer samples in the high-density space.
Case Studies and Examples
Real-world examples demonstrating the effectiveness of Imbalance-Learn
To illustrate the practical application of Imbalance-Learn, let’s explore real-world case studies where handling imbalanced data was crucial for model performance. For instance, imbalanced datasets are common in credit card fraud detection, with fraudulent transactions being the minority class. By employing resampling techniques provided by Imbalance-Learn, financial institutions can improve fraud detection accuracy and reduce false positives, ultimately saving millions of dollars.
Another example is in medical diagnosis, where detecting rare diseases from patient data poses a significant challenge due to class imbalance. Imbalance-Learn enables healthcare providers to rebalance datasets and train models that accurately identify rare conditions, leading to early intervention and improved patient outcomes.
Comparison of different resampling techniques
In this section, we’ll compare the performance of various resampling techniques offered by Imbalance-Learn. We’ll evaluate oversampling methods like SMOTE, ADASYN, and Borderline-SMOTE against undersampling techniques such as RandomUnderSampler and Tomek Links. By analyzing factors such as model accuracy, precision, recall, and computational efficiency, we can determine the most suitable resampling technique for specific datasets and classification problems.
Visualization of results and performance metrics
Visualizing the results and performance metrics is essential for gaining insights into model behavior and effectiveness. We’ll generate visualizations such as ROC curves, precision-recall curves, and confusion matrices to assess model performance before and after applying resampling techniques. By visually comparing the performance of models trained on imbalanced versus balanced datasets, we can demonstrate the impact of Imbalance-Learn on improving classification accuracy and mitigating the effects of class imbalance.
Conclusion
Thus all the techniques, to handle imbalanced data, along with their implementation are covered. After analyzing all the outputs we can say that Over Sampling tends to work better in handling the imbalanced data. However, it is always recommended to use both, Under Sampling and Over Sampling to balance the skewness of the imbalanced data.
Key Takeaways
- Imbalanced data affects the performance of the classification model.
- Thus to handle the imbalanced data, Sampling techniques are used.
- There are two types of sampling techniques available: Under Sampling and Over Sampling.
- Under Sampling selects the instances from the majority class to keep and delete.
- Over Sampling generates the new synthesis examples from the minority class using neighbors and density distribution criteria.
- It is recommended to use both techniques altogether to get better results for the model performance.
Dataset Link: https://www.kaggle.com/code/stevenkoenemann/aid-362-red-neural-network/data?select=AID362red_train.csv
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





