This article was published as a part of the Data Science Blogathon.
Introduction on Feature Extraction
In Natural Language Processing, Feature Extraction is one of the most important steps to be followed for a better understanding of the context of what we are dealing with. After the initial text is cleaned, we need to transform it into its features to be used for modeling. Document data is not computable so it must be transformed into numerical data such as a vector space model. This transformation task is generally called feature extraction of document data. Feature Extraction is also called Text Representation, Text Extraction, or Text Vectorization.
In this article, we will explore different types of Feature Extraction Techniques like Bag of words, Tf-Idf, n-gram, word2vec, etc. Without wasting our time let’s start our article.
First, let us understand the answer to some questions:
1. What is Feature Extraction from the text?
2. Why do we need it?
3. Why is it difficult?
4. What are the techniques?
1. What is Feature Extraction from the text?
If we have textual data, that data we can not feed to any machine learning algorithm because the Machine Learning algorithm doesn’t understand text data.
It understands only numerical data. The process of converting text data into numbers is called Feature Extraction from the text. It is also called text vectorization.
2. Why do we Need it?
So we know that machines can only understand numbers and to make machines able to identify language we need to convert it into numeric form.
3. Why is it Difficult?
If we ask any NLP practitioner or data scientist then the answer will be yes, somewhat it is difficult.
Now let us compare text feature extraction with feature extraction in other types of data.
So in an image dataset, image feature extraction is easy because images are already present in form of numbers(Pixels).
If we talk about audio data, suppose emotion prediction from speech recognition so, in this, we have data in form of waveform signals where features can be extracted over some time Interval.
But when we have a sentence and we want to predict its sentiment, How will you represent it in numbers? In this article, we are going to study these techniques.
4. What are the Techniques?
1. One Hot Encoding
2. Bag of Word (BOW)
3. n-grams
4. Tf-Idf
5. Custom features
6. Word2Vec(Word Embedding)
Common Terms Used
Corpus(c) — The total number of words present in the whole dataset is known as Corpus.
Vocabulary (V) — Total number of unique words available in the corpus.
Document (D) — There are multiple records in a dataset so a single record or review is referred to as a document.
Word (w) — Words that are used in a document are known as Word.
Techniques for Feature Extraction
1. One Hot Encoding
One hot encoding means converting the words of your document into a V-dimension vector.
This technique is very intuitive means it is simple and you can code it yourself. This is only the advantage of One-Hot Encoding.
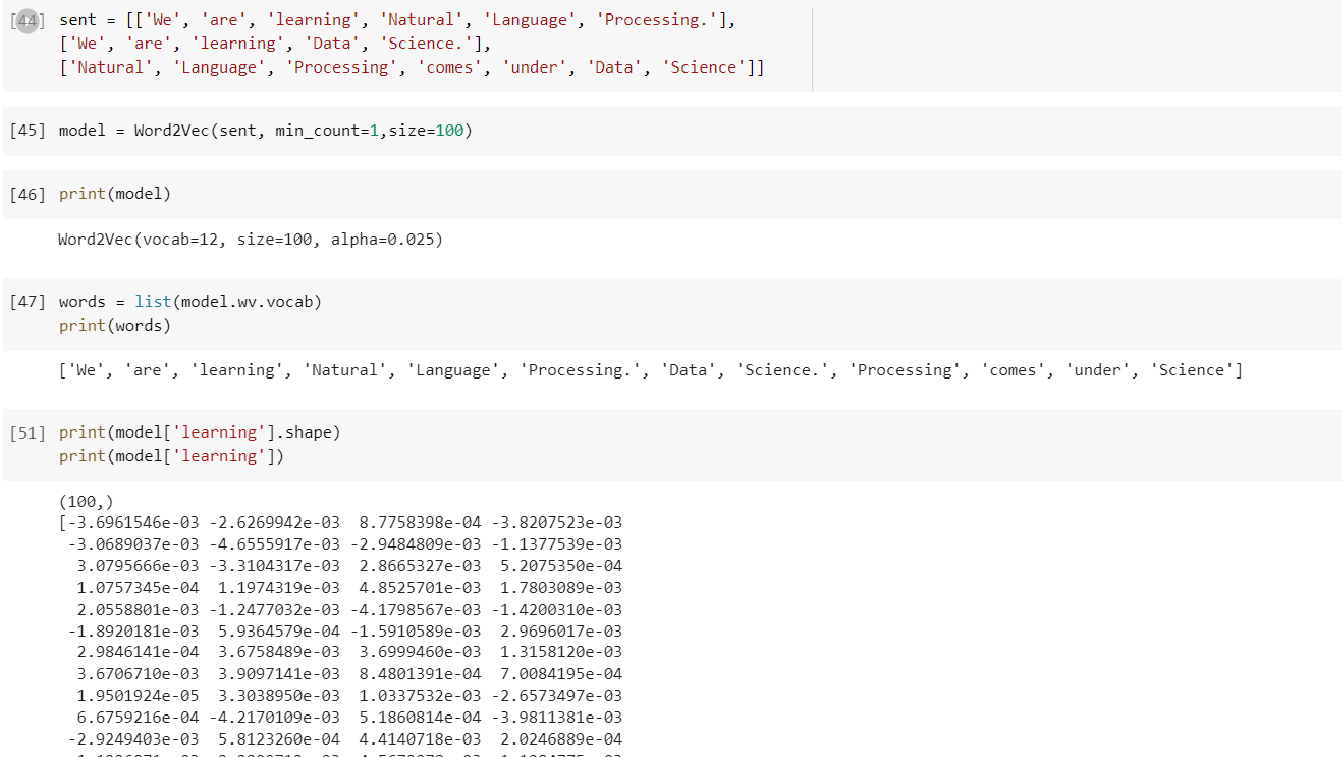
Let’s say we have documents “We are learning Natural Language Processing”, “We are learning Data Science”, and “Natural Language Processing comes under Data Science”.
corpus – We are learning Natural Language Processing, We are learning Data Science, Natural Language Processing comes under Data Science
Vocabulary(Unique words) – We are learning Natural Language Processing Data Science comes under – V – 10
Document1 — We are learning Natural Language Processing
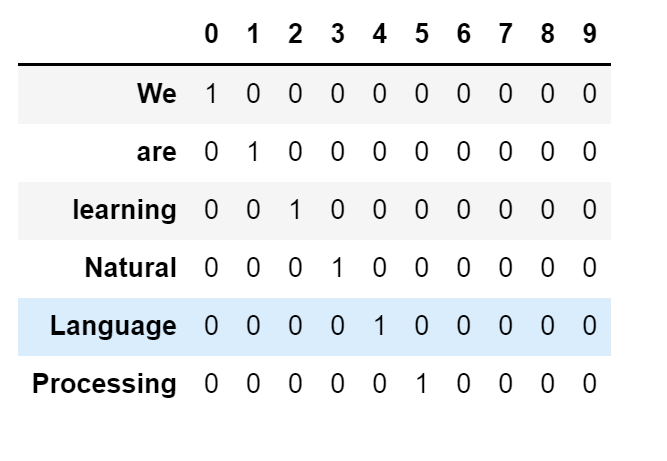
Advantage
1. It is Intuitive
2. Easy to implement
One hot encoding is not used in the industry because it has flaws.
Disadvantage
1. It creates Sparsity.
2. Size of each document after one hot encoding may be different. The machine learning model doesn’t work.
3. Out of Vocabulary (OOV) problem. At the time of prediction new word come which is not available in the vocabulary.
4. No capturing of semantic meaning.
2. Bag of Words
It is one of the most used text vectorization techniques. A bag-of-words is a representation of text that describes the occurrence of words within a document.
Specially used in the Text Classification task.
We can directly use CountVectorizer class by Scikit-learn.
code example
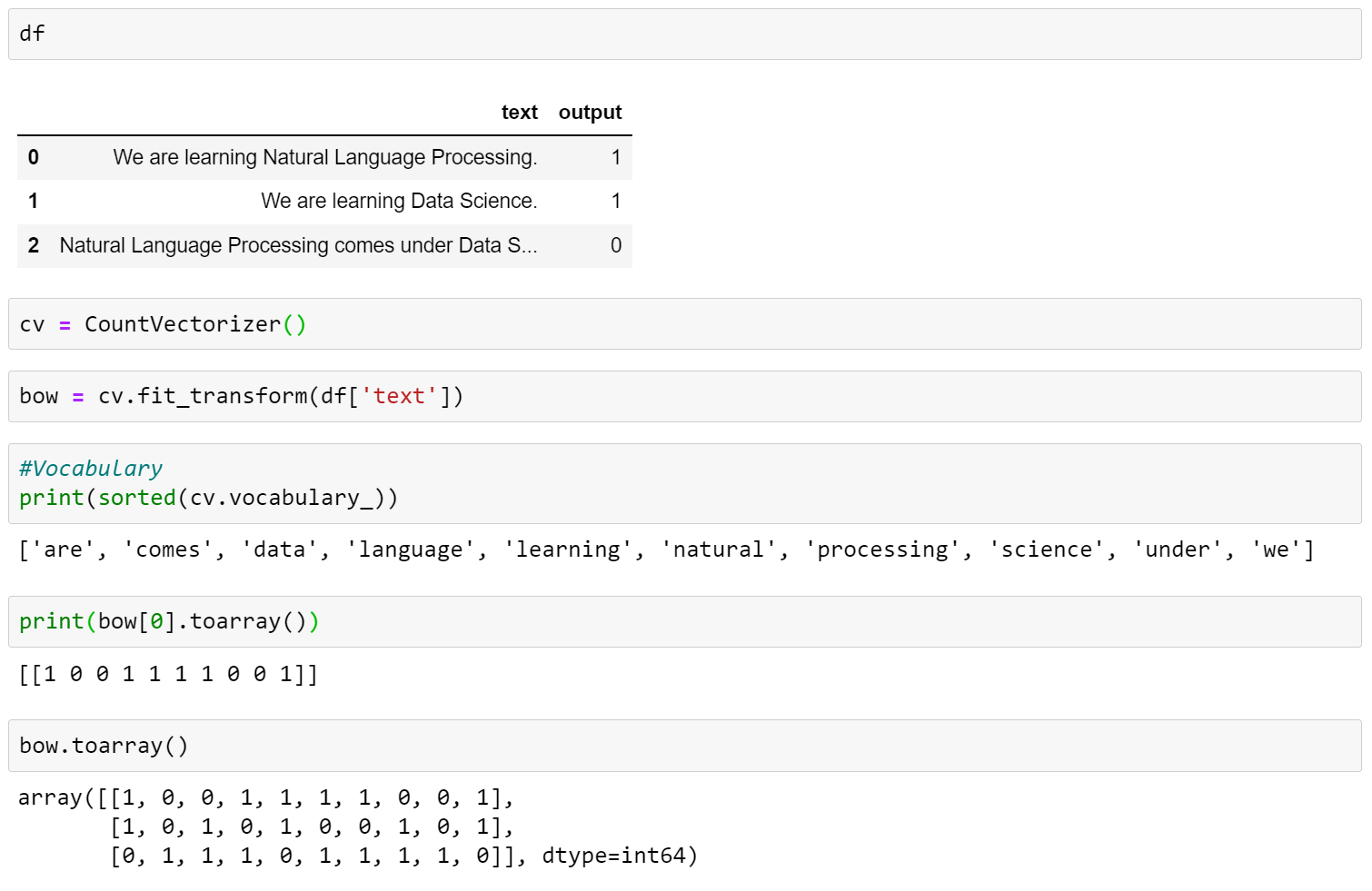
Advantage
1. Simple and intuitive.
2. Size of each document after BOW same.
3. Out of Vocabulary (OOV) problem does not occur, which means the model does not give an error.
Disadvantage
1. BOW also creates Sparsity.
2. OOV, Ignoring the new word.
3. Not consider sentence ordering issues.
3. Bag of n-grams
A bag-of-n -grams model represents a text document as an unordered collection of its n-grams.
bi-gram — using two words of the document
tri-gram — using three words of the document
n-gram — using n number of words of the document
code example
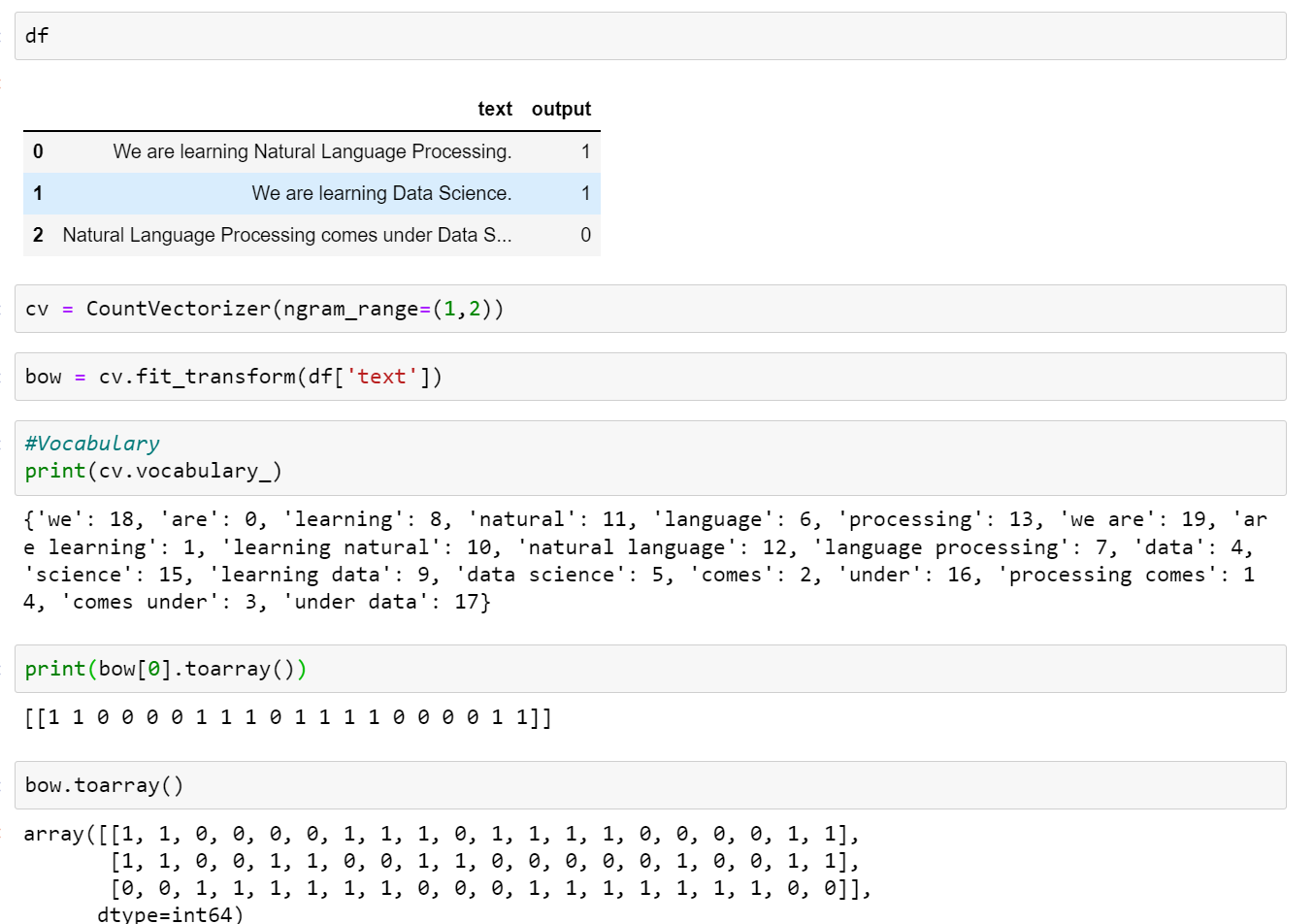
Advantage
1. Simple and easy to implement.
2. Able to capture the semantic meaning of the sentence.
Disadvantage
1. As we move from unigram to N-Gram then the dimension of vector formation increases and slows down the algorithm.
2. OOV, Ignoring the new word.
4. Tf-Idf — Term Frequency and Inverse Document Frequency
TF-IDF (term frequency-inverse document frequency) is a statistical measure that evaluates how relevant a word is to a document in a collection of documents.
- Term Frequency (TF):
The number of times a word appears in a document is divided by the total number of words in that document. 0 < Tf< 1

- Inverse Document Frequency (IDF):
The logarithm of the number of documents in the corpus is divided by the number of documents where the specific term appears. In Scikit-learn use log(N/ni) + 1 formula.

code example
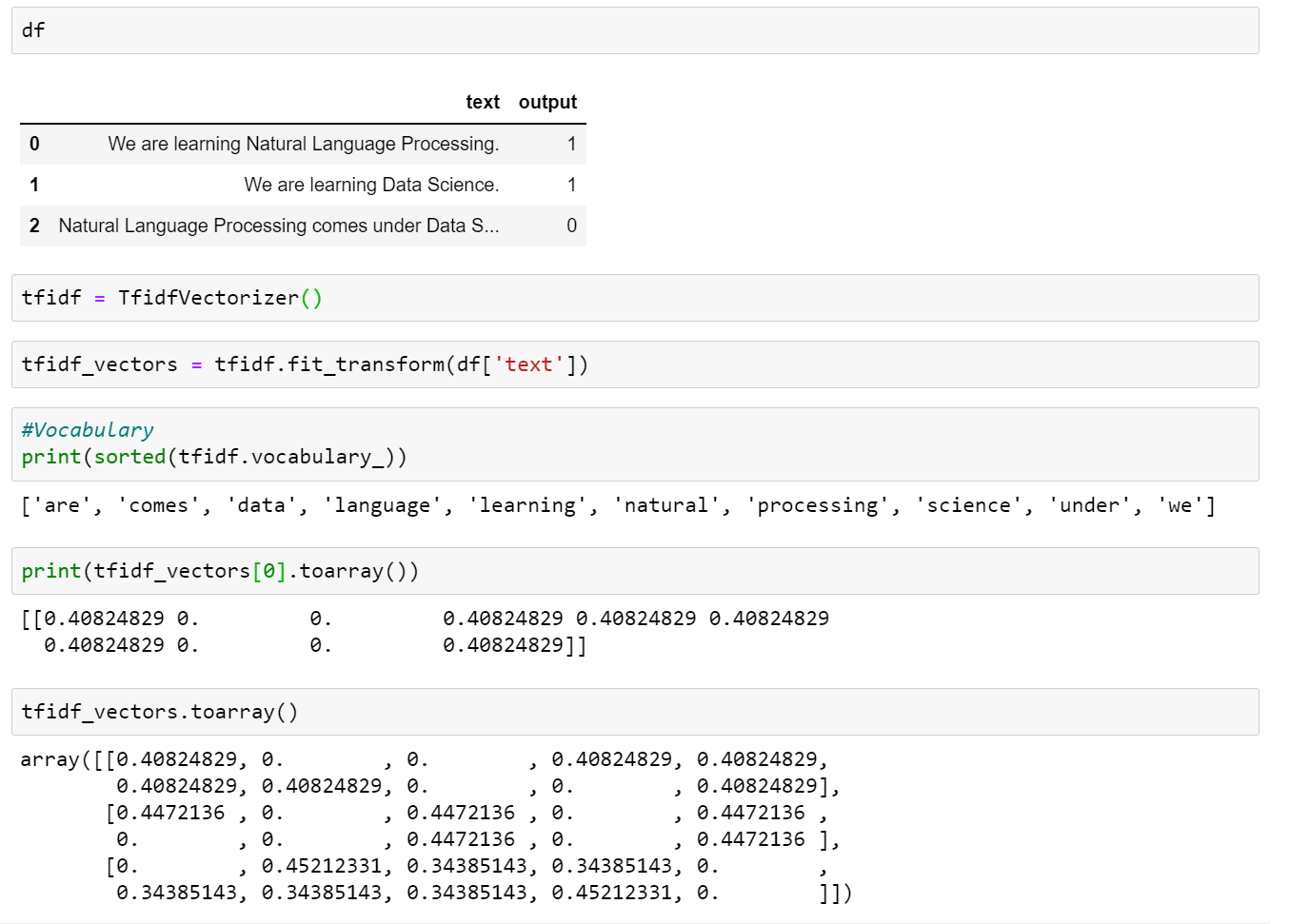
Q. Why do we take a log to calculate IDF?
If we have a very rare word, the IDF value without a log is very high. And then we have to calculate Tf * If at that time Idf value will dominate the Tf value because the Tf value lies from 0 to 1. That means we normalize the IDF value using a log.
Advantage
1. This technique is widely used in Information retrieval like a search engine.
Disadvantage
1. Sparsity
2. If we have a large dataset then dimensionality increases, slowing down algos.
3. OOV, Ignoring the new word.
4. Semantic meaning does not capture.
5. Custom Features
Creating new custom features using domain knowledge.
examples
1. Number of a word in the document.
2. Number of negative words in the document.
3. Ratio of +ve review to -ve review.
4. Word count.
5. Character count.
6. Word2vec
Word Embeddings
Wikipedia says “In natural language processing, word embedding is a term used for the representation of words for text analysis, typically in the form of a real-valued vector that encodes the meaning of the word such that the words that are closer in the vector space are expected to be similar in meaning.”
let’s consider one example boy-man vs boy-table, Can you tell which of the pair has more similar words to each other?
For a human, it’s easy to understand the associations between words in a language. We know that boy and man have more similar meanings than boy and table but what if we want machines to understand this kind of relation automatically in our languages as well? That is what word embeddings come into the picture.
Types of Word Embedding
1. Frequency-based – Count frequency of word
- BOW
- Tf-idf
- Glove(based on Matric Factorization)
2. Prediction based
- Word2Vec
What is Word2Vec?
Word2Vec is somewhat different than other techniques which we discussed earlier because it is a Deep learning-based technique.
Word2Vec is a word embedding technique, that converts a given word into a vector as a collection of numbers.
As we have other techniques then why do we need word2vec?
- Word2vec capture semantic meaning like happiness and joy have the same meaning.
- Word2vec create low dimension vector(each word is a collection of a range of 200 to 300.
- Word2vec creates a Dense vector(non-zeros)
How to Use It?
We have two approaches to use Word2Vec
1. Use a pre-trained model
2. Self-Trained model
Conclusion
In this article, we learned about different types of feature extraction techniques. The key takeaways from the article are,
- We learned different types of feature extraction techniques such as one-hot encoding, bag of words, TF-IDF, word2vec, etc.
- One Hot Encoding is a simple technique giving each unique word zero or one.
- A bag-of-words is a representation of text that describes the occurrence of words within a document.
- TF-IDF is a statistical measure that evaluates how relevant a word is to a document in a collection of documents.
- and at the last we have seenWord2Vec. Word2Vec is a word embedding technique, that converts a given word into a vector as a collection of numbers.
- Each technique has its pros and cons.
So, this was all about feature extraction techniques. Hope you liked the article.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi, I am shankar working as data engineer, I love to play with data.
My passion for data science and my expertise as a data engineer make me a valuable asset in driving data-centric projects and leveraging the power of data to solve real-world problems.






Great article, thank you!